







python作业爬取xxx大学排名榜单,python-selenium爬虫解决(本文章仅学习,网站数据也是公开的)
前言
python作业爬取xx大学排行榜数据,老师给你的教程是非常久远的教程,你会发现与现在的网站有所差别,特别是在浏览器开发者工具中抓包xhr文件,已经找不到榜单数据文件了。本文章主要介绍用python-selenium-webdriver 实现对网页榜单数据的抓取。
代码已经上传我的 gitee库 可自行下载使用。
一、分析
进入网页打开开发者工具,元素检查自己需要的数据 ‘清华大学’,查看它的元素代码,如下:
class="name-cn" data-v-b80b4d60="">清华大学 </a>类似检查所有数据的元素,进行对比,发现其相同类的元素头一致,这样后续代码可以用re提取。
为避免每一页的数据对应元素不一致,检查第二页元素 ‘大连理工大学’ ,如下:
href="/institution/dalian-university-of-technology" class="name-cn">大连理工大学 </a>发现与第一页元素头不一致,返回第一页再次查看‘清华大学’,如下:
href="/institution/tsinghua-university" class="name-cn">清华大学 </a>发现数据的元素又一致了 ,后续页面也一致,故在使用python-selenium爬虫时,进入网页先进入第二页,再返回第一页,使其页面数据对应元素一致。
所有数据对应网页代码元素如下:
经过观察发现大学级别有些学校没有,故在爬虫过程中,没有的就更改为无,方便后续写入表。
# 大学名称
<a data-v-b80b4d60="" href="/institution/tsinghua-university" class="name-cn">清华大学 </a>
# 英文名称
<a data-v-f9104fdc="" href="/institution/tsinghua-university" class="name-en">Tsinghua University </a>
# 大学级别
<p data-v-3fe7d390="" class="tags">双一流/985/211</p>
# 学校所在省份
<td data-v-3fe7d390="" class="">
北京
<!----></td>
# 学校类型
<td data-v-3fe7d390="" class="">
综合
<!----></td>
# 总分
<td data-v-3fe7d390="" class="">
999.4
</td>
# 办学层次
<td data-v-3fe7d390="" class="">
37.6
</td>因为需要榜单全部数据,所以要把所有页数里面的数据全部提取出来。需要用python-selenium模拟翻页,后又经发现,在一些页中的 下一页 按钮的xpath地址(xpath是用来定位按钮在页面什么位置)会有所变化,下一页按钮和xpath内容如下:

下一页按钮 xpath 地址变更
1-3: //*[@id="content-box"]/ul/li[9]/a
4: //*[@id="content-box"]/ul/li[10]/a
5-16: //*[@id="content-box"]/ul/li[11]/a
17: //*[@id="content-box"]/ul/li[10]/a
18: //*[@id="content-box"]/ul/li[9]/a
19: //*[@id="content-box"]/ul/li[9]/a
20: //*[@id="content-box"]/ul/li[9]/a二、需要实现过程
图解:
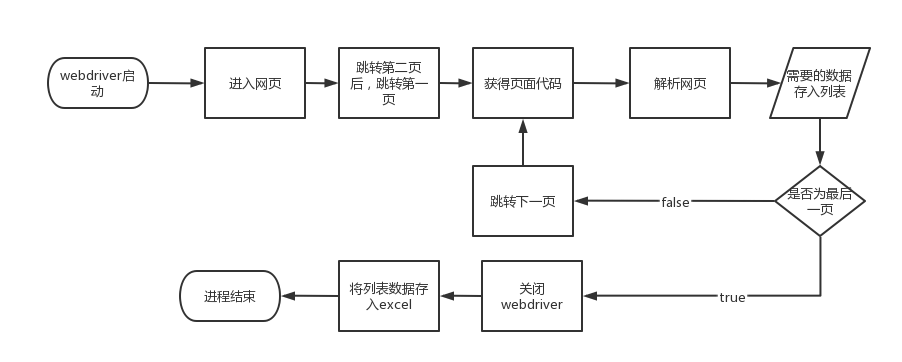
三、代码实现
1.引入库
代码如下:
import time
import re
from selenium.webdriver
import ActionChains from selenium import webdriver
2.全部代码
代码如下:
import time
import re
from selenium.webdriver import ActionChains
from selenium import webdriver
if __name__ == '__main__':
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--no-sandbox') # 给予root执行权限
chrome_options.add_argument('--headless') # 隐藏浏览器运行
driver = webdriver.Chrome(options=chrome_options)
# 地址自行输入
url = ''
driver.get(url)
time.sleep(1)
action = ActionChains(driver)
# 初始化界面元素 可以发现直接进入 第一页 与 后面页的元素格式不一样 但如果进入第一页后点击进入第二页
# 再点击进入第一页,第一页就和后面的页元素一致了
e = driver.find_element('xpath', '//*[@id="content-box"]/ul/li[9]/a')
action.click(e).perform()
e = driver.find_element('xpath', '//*[@id="content-box"]/ul/li[1]/a')
action.click(e).perform()
# 最终存储校园排行榜数据列表
list_information = []
# 20 表示总页数
for j in range(0, 20):
text = driver.page_source
# print(text)
list_yemian = re.findall('<tbody data-v-3fe7d390="">(.*?)</tbody>', text, re.S)[0]
list_total = re.findall('<tr data-v-3fe7d390="">(.*?)</tr>', list_yemian, re.S)
length = len(list_total)
for i in range(0, length):
list0 = list_total[i]
# 大学中文名
name_cn = re.findall('class="name-cn">(.*?) </a>', list0)
# 大学英文名
name_en = re.findall('class="name-en">(.*?) </a>', list0)
# 大学级别
tags = re.findall('class="tags">(.*?)</p>', list0)
# 无级别 比如不是 985/211的学校
# 空列表==false
if not tags:
tags = ['无']
# 大学所在省市 和 大学类型
list_province_category = re.findall(
'<td data-v-3fe7d390="" class="">\n (.*?)\n <!----></td>',
list0)
# 大学总分
score = re.findall('<td data-v-3fe7d390="" class="">\n (.*?)\n </td>', list0)
# 办学层次
School_level = re.findall(
'<td data-v-3fe7d390="" class="">\n (.*?)\n </td>',
list0)
list_0 = name_cn + name_en + tags + list_province_category + score + School_level
list_information.append(list_0)
# print(list_information)
if (0 <= j <= 2) or (17 <= j <= 19):
xpath = '//*[@id="content-box"]/ul/li[9]/a'
elif j == 3 or j == 16:
xpath = '//*[@id="content-box"]/ul/li[10]/a'
else:
xpath = '//*[@id="content-box"]/ul/li[11]/a'
e = driver.find_element('xpath', xpath)
action.click(e).perform()
# print(len(list_information))
driver.quit()
result = open('data.xls', 'w', encoding='utf-8')
result.write('大学名称\t英文名\t大学级别\t所在省市\t大学类型\t总分\t办学层次\n')
for m in range(0, len(list_information)):
for n in range(0, len(list_information[m])):
result.write(str(list_information[m][n]))
result.write('\t')
result.write('\n')
result.close()
print('数据采集完成!!')3.效果呈现

















 5559
5559











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











