






引言
博主之前安装的pytesseractocr,被自己的一次操作中不小心误删了,导致无法识别图像,出现异常报错

# 伪代码
# if error occur then follow step
# finally get result
备注:
测试是否添加至环境变量的指令
如果提示为 不是内部或外部指令,也不是可运行的程序或批处理文件
说明没有安装或者没有添加至环境变量

tesseract -v
1、打开官网链接
1.1. 安装链接
介绍链接
关键字匹配: 安装
快捷键: ctrl + F 全局搜索Windows
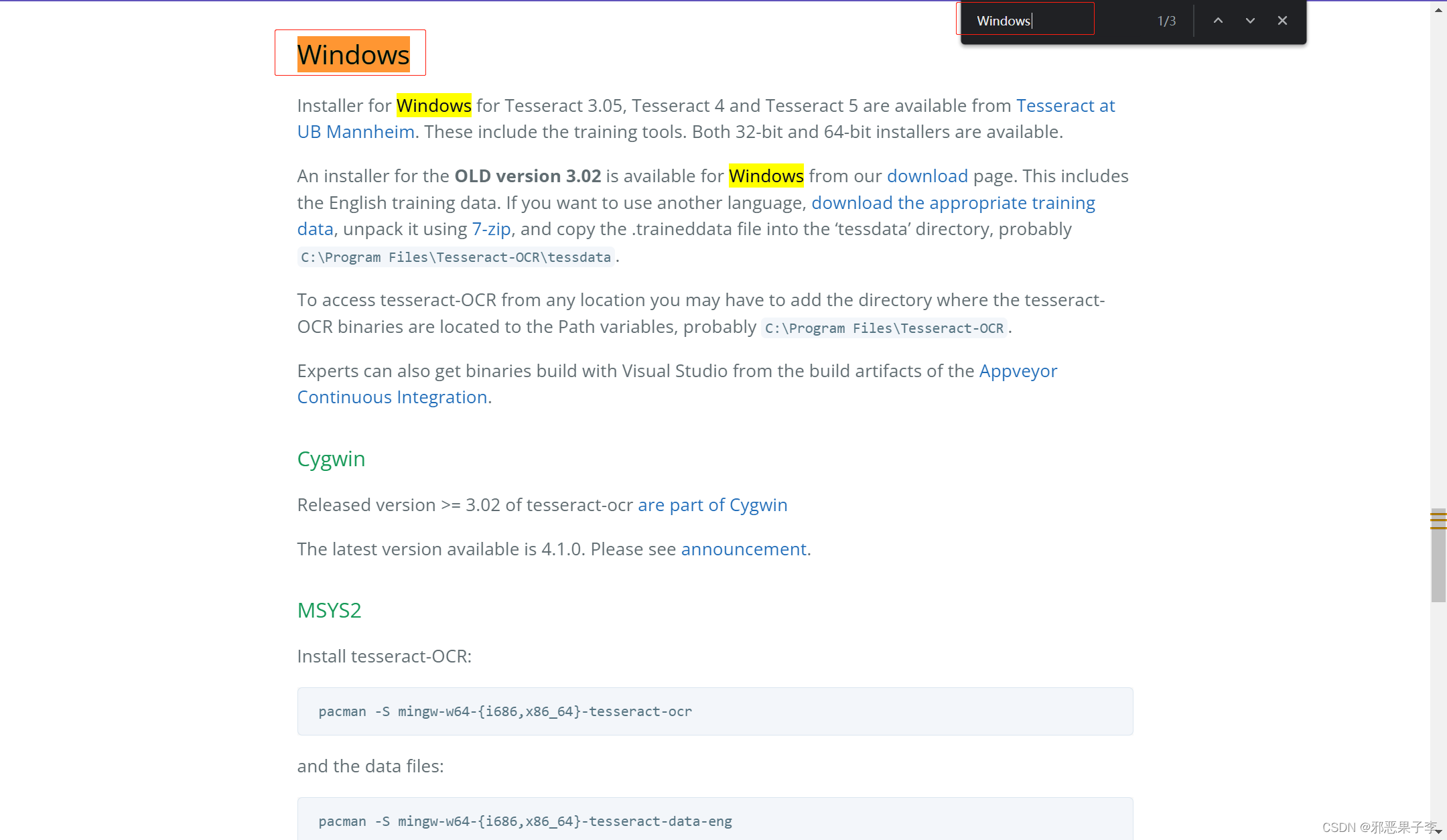
下载额外要识对应的语言,已经训练好的数据文件
tessdata文件下载链接
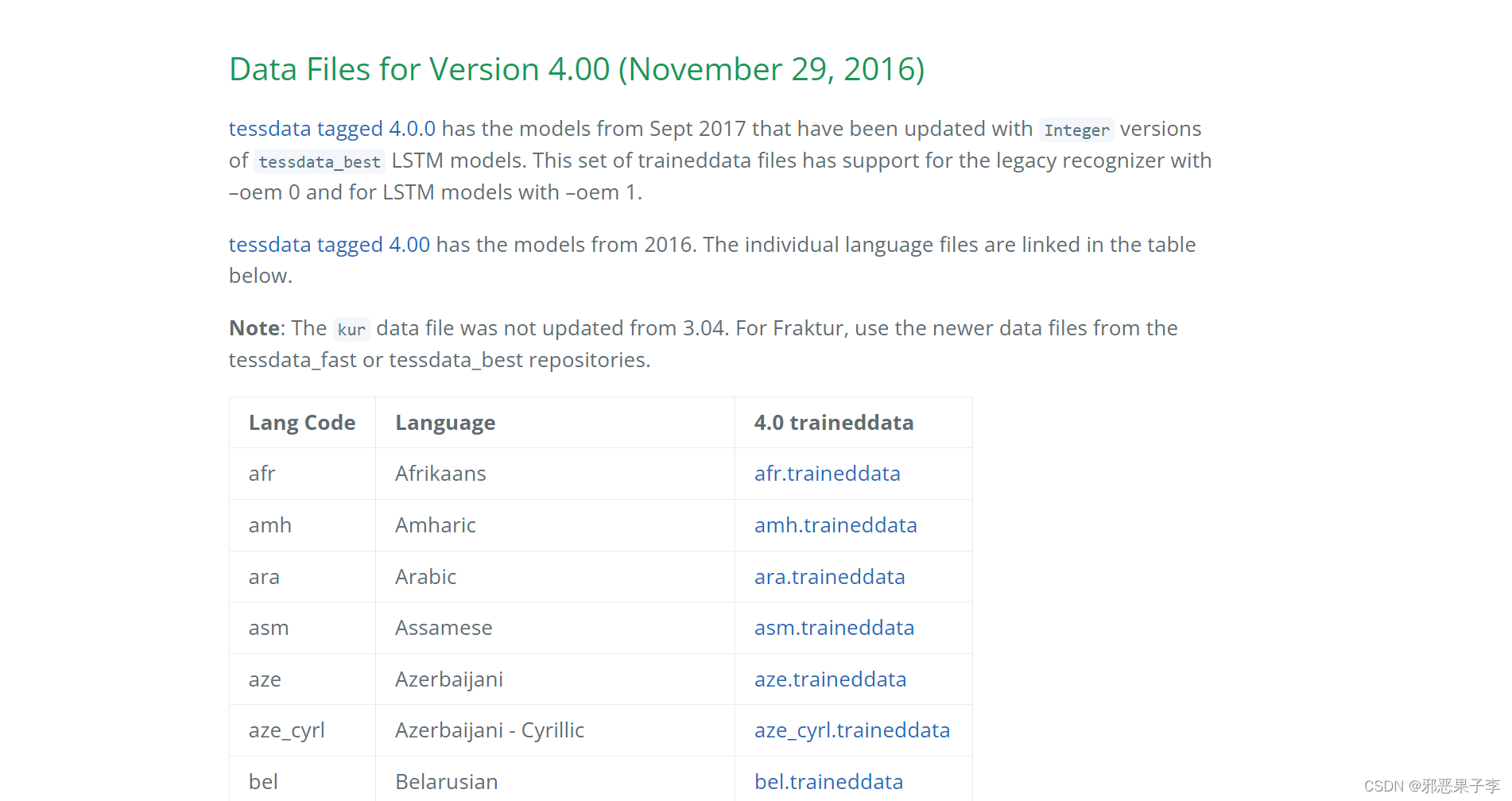
然后按照官网的教程走下去,解压至对应Programe files路径下
1.2. 筛选版本
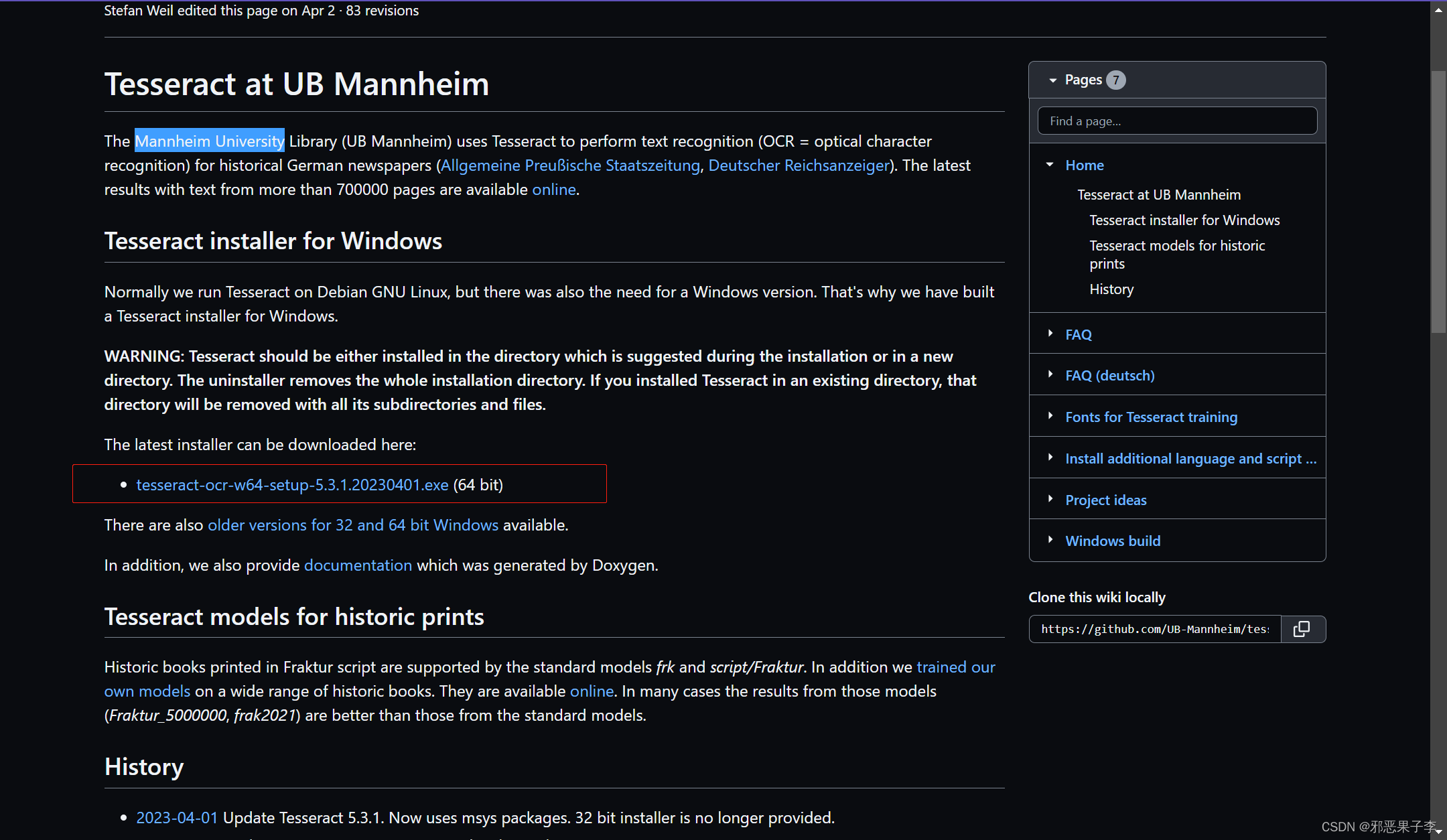
1.3. 点击链接
github下载链接:
2、安装软件
2.1 定位路径
D:\Download
tesseract-ocr-w64-setup-5.3.1.20230401.exe文件

双击运行
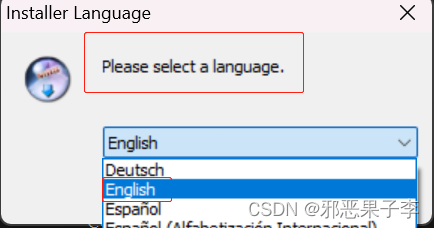
弹出对话框,匹配关键字 Please select a language
下拉框选择默认安装语言English
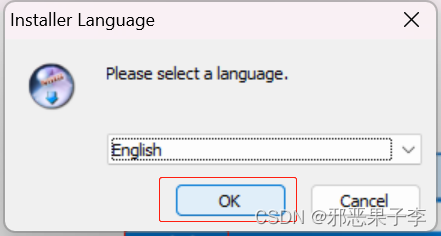
点击ok
3、配置环境变量
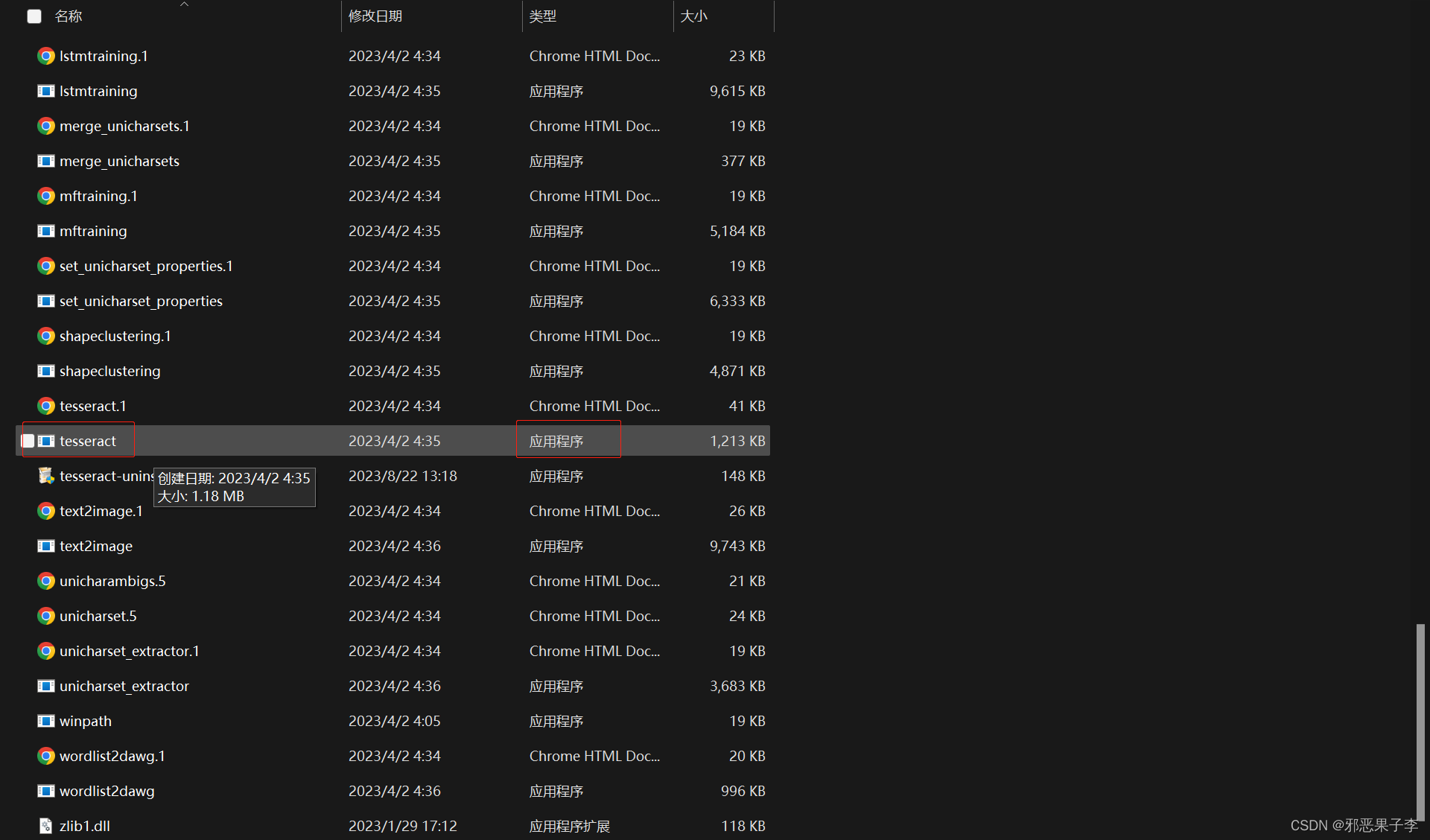
首先,先找到tesseract.exe文件所在的路径
D:\Program Files\Tesseract-OCR
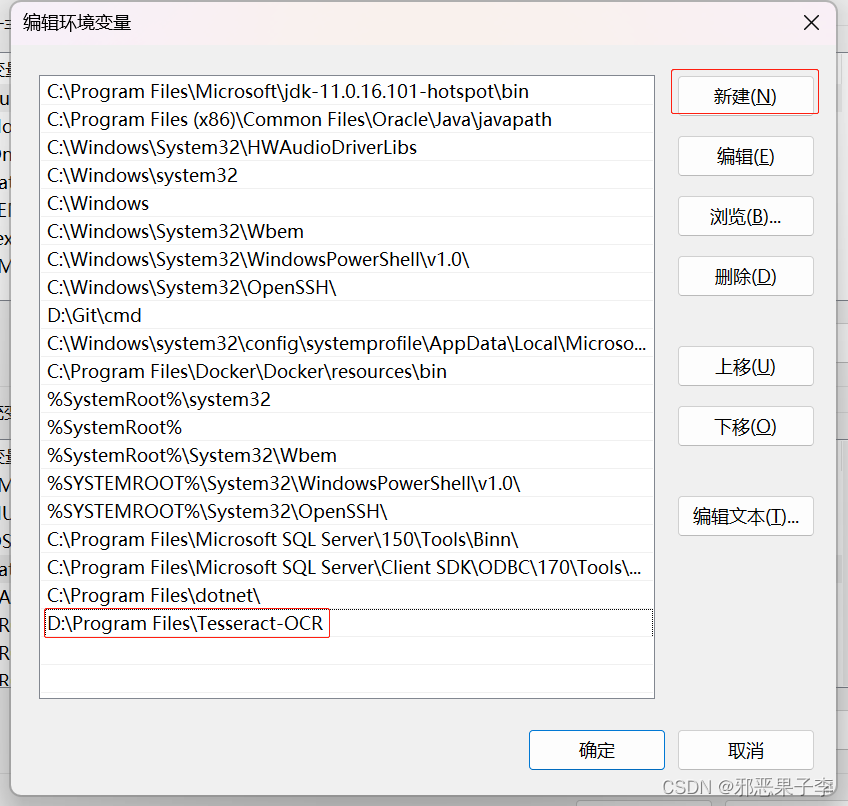
win + R 键快速打开sysdm.cpl窗口
弹出对话框:
配置环境变量
4、验收成果
版本信息验证:
tesseract -v

检查语言信息:
tesseract --list-langs
这里看到只有两种语言

由于博主爱好做图像识别的研究,经常会碰到一些文本类图片识别,所以会用到其他语言包,这里以简体中文以及繁体中文做为安装示例
把1.1章节内提到的 下载额外要识对应的语言,已经训练好的数据文件
把下载好的额外数据文件解压缩至
D:\Program Files\Tesseract-OCR\tessdata
路径下
win + R cmd窗口出来 键入
move chi_sim.traineddata "..\..\Program Files\Tesseract-OCR\tessdata"


5、测试DEMO

import pytesseract
from PIL import Image
import pytesseract
import cv2
class scanner:
def __init__(self,image):
self.image = image
@property
def pil_convert_text(self):
image = Image.open(self.image)
imgry = image.convert('L')
threshold = 150
table = []
for j in range(256):
if j < threshold:
table.append(0)
else:
table.append(1)
temp = imgry.point(table, '1')
# text = pytesseract.image_to_string(temp, lang="chi_sim+eng", config='--psm 6')
text = pytesseract.image_to_string(temp, lang="eng", config='--psm 6')
return text
@property
def cv2_convert_text(self):
print('请注意,识别略微有些误差')
'''
识别准确性不高
'''
'''
png识别率比jpg高
'''
image = cv2.imread(self.image)
text = pytesseract.image_to_string(image,lang='chi_sim', config='--psm 6')
return text
if __name__ == '__main__':
image = r'D:\Scripts\20230822_153809_CAPTCHA.png'
photo = scanner(image)
value = photo.pil_convert_text
print(value)
这里还有个要注意的点,tesseract模块里面要去改
ctrl + 鼠标左键
改为你自己地路径,不然无法读到模块

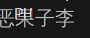
识别出来了,就是准确率不高
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









