







😃😃😃😃😃
更多资源链接,欢迎访问作者gitee仓库:https://gitee.com/fanggaolei/learning-notes-warehouse/tree/master
1.0⚽数据准备
数据直链下载(免登录): https://www.123pan.com/s/T1n0Vv-YTc3d
2.0😎分区表练习
🏈当Hive表对应的数据量大、文件多时,为了避免查询时全表扫描数据,Hive支持根据用户指定的字段进行分区,分区的字段可以是日期、地域、种类等具有标识意义的字段。
2.1数据说明
现有6份数据文件,分别记录了《王者荣耀》中6种位置的英雄相关信息。现要求通过建立一张表t_all_hero,把6份文件同时映射加载。
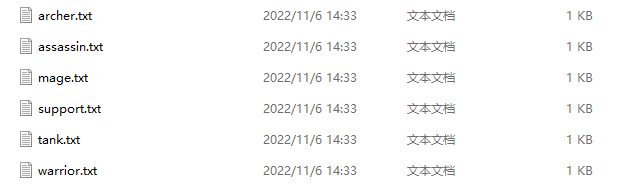

需求:以role角色作为分区字段创建静态分区表和动态分区表
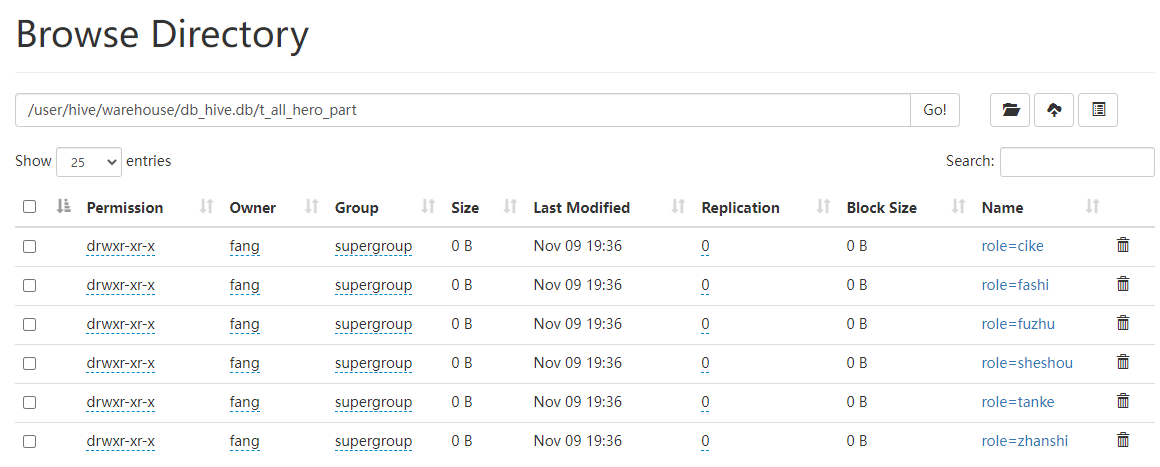
2.2静态分区表
😎所谓静态分区指的是分区的字段值是由用户在加载数据的时候手动指定的。
1.创建一个静态分区表
create table t_all_hero_part(
id int,
name string,
hp_max int,
mp_max int,
attack_max int,
defense_max int,
attack_range string,
role_main string,
role_assist string
) partitioned by (role string)
row format delimited
fields terminated by "\t";
2.将数据上传到静态分区中
load data local inpath '/opt/module/hive/data/hero/archer.txt' into table t_all_hero_part partition(role='sheshou');
load data local inpath '/opt/module/hive/data/hero/assassin.txt' into table t_all_hero_part partition(role='cike');
load data local inpath '/opt/module/hive/data/hero/mage.txt' into table t_all_hero_part partition(role='fashi');
load data local inpath '/opt/module/hive/data/hero/support.txt' into table t_all_hero_part partition(role='fuzhu');
load data local inpath '/opt/module/hive/data/hero/tank.txt' into table t_all_hero_part partition(role='tanke');
load data local inpath '/opt/module/hive/data/hero/warrior.txt' into table t_all_hero_part partition(role='zhanshi');
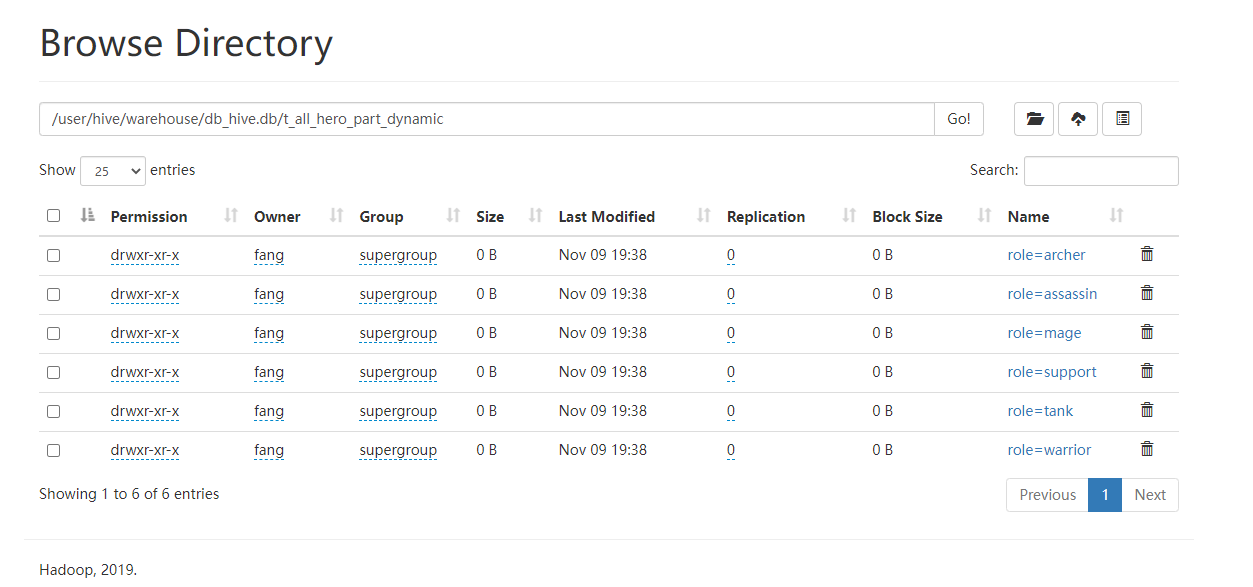
2.3动态分区表
👀所谓动态分区指的是分区的字段值是基于查询结果自动推断出来的。核心语法就是insert+select
1.创建一个原始数据表
create table t_all_hero(
id int,
name string,
hp_max int,
mp_max int,
attack_max int,
defense_max int,
attack_range string,
role_main string,
role_assist string
)
row format delimited
fields terminated by "\t";
2.向原始表中上传数据
hadoop dfs -put data/hero/* /user/hive/warehouse/db_hive.db/t_all_hero
3.开启动态分区
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
4.创建一个动态分区表
create table t_all_hero_part_dynamic(
id int,
name string,
hp_max int,
mp_max int,
attack_max int,
defense_max int,
attack_range string,
role_main string,
role_assist string
) partitioned by (role string)
row format delimited
fields terminated by "\t";
5.向动态分区表中插入数据
insert into table t_all_hero_part_dynamic partition(role)
select tmp.*,tmp.role_main from t_all_hero tmp;
3.0🍔分桶表
🐘分桶表也叫做桶表,源自建表语法中bucket单词。是一种用于优化查询而设计的表类型。该功能可以让数据分解为若干个部分易于管理。
3.1数据说明
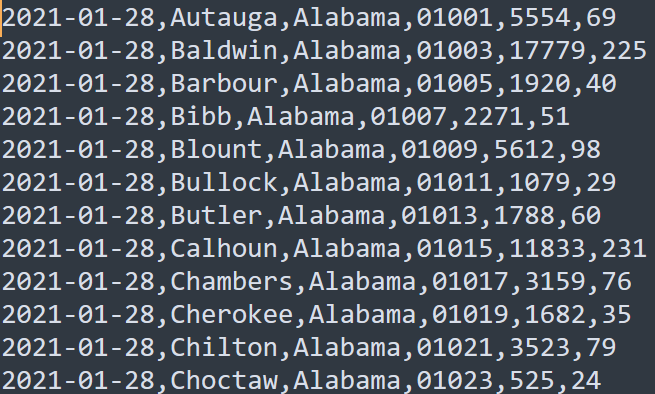
现有美国2021-1-28号,各个县county的新冠疫情累计案例信息,包括确诊病例和死亡病例,数据格式如下所
示字段含义如下:count_date(统计日期),county(县),state(州),fips(县编码code),cases(累计确诊病
例),deaths(累计死亡病例)。
需求:根据state州把数据分为5桶
3.2分桶表创建练习
1.原始数据准备
CREATE TABLE t_usa_covid19(
count_date string,
county string,
state string,
fips int,
cases int,
deaths int)
row format delimited fields terminated by ",";
2.向原始表中插入数据
hadoop fs -put data/us-covid19-counties.dat /user/hive/warehouse/db_hive.db/t_usa_covid19
3.创建分桶表
CREATE TABLE t_usa_covid19_bucket_sort(
count_date string,
county string,
state string,
fips int,
cases int,
deaths int)
CLUSTERED BY(state) sorted by (cases desc) INTO 5 BUCKETS;
4.向分桶表中插入数据
insert into t_usa_covid19_bucket_sort select * from t_usa_covid19;

















 441
441











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











