







文章目录
1.0 Pandas简介

Pandas 是 Python 语言的一个扩展程序库,用于数据分析。
Pandas 是一个开放源码、BSD 许可的库,提供高性能、易于使用的数据结构和数据分析工具。
Pandas 名字衍生自术语 “panel data”(面板数据)和 “Python data analysis”(Python 数据分析)。
Pandas 一个强大的分析结构化数据的工具集,基础是 Numpy(提供高性能的矩阵运算)。
Pandas 可以从各种文件格式比如 CSV、JSON、SQL、Microsoft Excel 导入数据。Pandas 可以对各种数据进行运算操作,比如归并、再成形、选择,还有数据清洗和数据加工特征。
Pandas 广泛应用在学术、金融、统计学等各个数据分析领域。
pandas应用
Pandas 的主要数据结构是 Series (一维数据)与 DataFrame(二维数据),这两种数据结构足以处理金融、统计、社会科学、工程等领域里的大多数典型用例。
数据结构
Series 是一种类似于一维数组的对象,它由一组数据(各种Numpy数据类型)以及一组与之相关的数据标签(即索引)组成。
DataFrame 是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型值)。DataFrame 既有行索引也有列索引,它可以被看做由 Series 组成的字典(共同用一个索引)。
2.0 Pandas安装
使用 pip 安装 pandas:
pip install pandas
安装成功后,我们就可以导入 pandas 包使用:
import pandas
实例 - 查看 pandas 版本
import pandas
pandas.__version__ # 查看版本
'1.1.5'
导入 pandas 一般使用别名 pd 来代替:
import pandas as pd
实例 - 查看 pandas 版本
import pandas as pd
pd.__version__ # 查看版本
'1.1.5'
一个简单的 pandas 实例:
使用测试
import pandas as pd
mydataset = {
'sites': ["Google", "Runoob", "Wiki"],
'number': [1, 2, 3]
}
myvar = pd.DataFrame(mydataset)
print(myvar)
执行以上代码,输出结果为:

2.0数据结构 - Series
Pandas Series 类似表格中的一个列(column),类似于一维数组,可以保存任何数据类型。
Series 由索引(index)和列组成,函数如下:
pandas.Series( data, index, dtype, name, copy)
参数说明:
- data:一组数据(ndarray 类型)。
- index:数据索引标签,如果不指定,默认从 0 开始。
- dtype:数据类型,默认会自己判断。
- name:设置名称。
- copy:拷贝数据,默认为 False。
测试一:创建一个简单的 Series 实例:
import pandas as pd
a = [1, 2, 3]
myvar = pd.Series(a)
print(myvar)

运行结果为:第一列为索引,第二列为数据,最后一行为数据类型
测试二:根据索引输出数据的值
import pandas as pd
a = [1, 2, 3]
myvar = pd.Series(a)
print(myvar[1])

运行结果输出为:2
测试三:指定索引
import pandas as pd
a = ["Google", "Runoob", "Wiki"]
myvar = pd.Series(a, index = ["x", "y", "z"])
print(myvar)

测试四:根据索引值读取数据
import pandas as pd
a = ["Google", "Runoob", "Wiki"]
myvar = pd.Series(a, index = ["x", "y", "z"])
print(myvar["y"])

测试五:使用 key/value 对象,类似字典来创建 Series
import pandas as pd
sites = {1: "Google", 2: "Runoob", 3: "Wiki"}
myvar = pd.Series(sites)
print(myvar)

测试六:只需要字典中的一部分数据,只需要指定需要数据的索引即可
import pandas as pd
sites = {1: "Google", 2: "Runoob", 3: "Wiki"}
myvar = pd.Series(sites, index = [1, 2])
print(myvar)

测试七:设置 Series 名称参数
import pandas as pd
sites = {1: "Google", 2: "Runoob", 3: "Wiki"}
myvar = pd.Series(sites, index = [1, 2], name="RUNOOB-Series-TEST" )
print(myvar)

3.0数据结构 - DataFrame
DataFrame 是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型值)。DataFrame 既有行索引也有列索引,它可以被看做由 Series 组成的字典(共同用一个索引)。

DataFrame 构造方法
pandas.DataFrame( data, index, columns, dtype, copy)
参数说明:
- data:一组数据(ndarray、series, map, lists, dict 等类型)。
- index:索引值,或者可以称为行标签。
- columns:列标签,默认为 RangeIndex (0, 1, 2, …, n) 。
- dtype:数据类型。
- copy:拷贝数据,默认为 False。
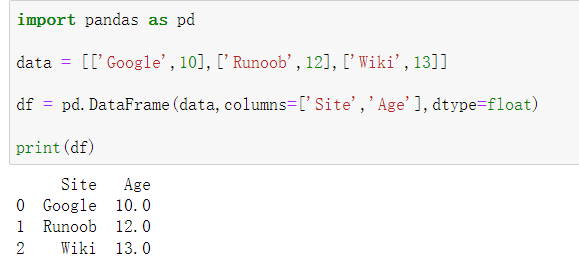
测试一:列表创建
import pandas as pd
data = [['Google',10],['Runoob',12],['Wiki',13]]
df = pd.DataFrame(data,columns=['Site','Age'],dtype=float)
print(df)
测试二:使用ndarrays创建
import pandas as pd
data = {'Site':['Google', 'Runoob', 'Wiki'], 'Age':[10, 12, 13]}
df = pd.DataFrame(data)
print (df)

测试三:使用字典创建
import pandas as pd
data = [{'a': 1, 'b': 2},{'a': 5, 'b': 10, 'c': 20}]
df = pd.DataFrame(data)
print (df)
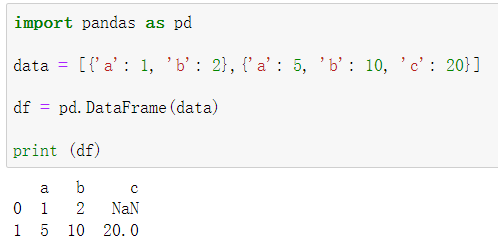
没有对应的部分数据为 NaN。
测试四:使用 loc 属性返回指定行的数据
import pandas as pd
data = {
"calories": [420, 380, 390],
"duration": [50, 40, 45]
}
# 数据载入到 DataFrame 对象
df = pd.DataFrame(data)
# 返回第一行
print(df.loc[0])
# 返回第二行
print(df.loc[1])

测试五:返回多行数据
import pandas as pd
data = {
"calories": [420, 380, 390],
"duration": [50, 40, 45]
}
# 数据载入到 DataFrame 对象
df = pd.DataFrame(data)
# 返回第一行和第二行
print(df.loc[[0, 1]])

测试六:指定索引值
import pandas as pd
data = {
"calories": [420, 380, 390],
"duration": [50, 40, 45]
}
df = pd.DataFrame(data, index = ["day1", "day2", "day3"])
print(df)

测试七:通过索引值返回某一行
import pandas as pd
data = {
"calories": [420, 380, 390],
"duration": [50, 40, 45]
}
df = pd.DataFrame(data, index = ["day1", "day2", "day3"])
# 指定索引
print(df.loc["day2"])

4.0Pandas CSV
下载数据集:点击获取
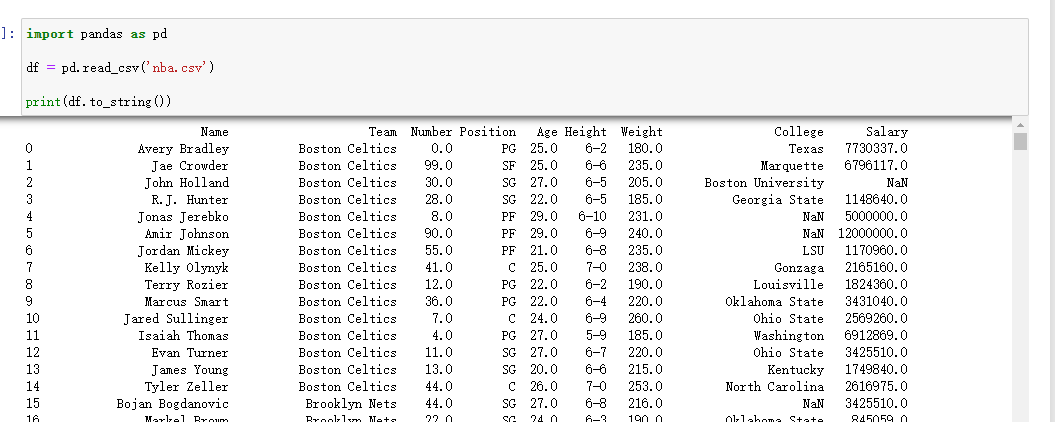
测试一:数据查看
import pandas as pd
df = pd.read_csv('nba.csv')
print(df.to_string())
to_string() 用于返回 DataFrame 类型的数据,如果不使用该函数,则输出结果为数据的前面 5 行和末尾 5 行,中间部分以 … 代替。

测试二:将数据存储为csv文件
import pandas as pd
# 三个字段 name, site, age
nme = ["Google", "Runoob", "Taobao", "Wiki"]
st = ["www.google.com", "www.runoob.com", "www.taobao.com", "www.wikipedia.org"]
ag = [90, 40, 80, 98]
# 字典
dict = {'name': nme, 'site': st, 'age': ag}
df = pd.DataFrame(dict)
# 保存 dataframe
df.to_csv('site.csv')

测试三:head( n ) 方法用于读取前面的 n 行,如果不填参数 n ,默认返回 5 行。
import pandas as pd
df = pd.read_csv('nba.csv')
print(df.head())

测试四:tail读取尾部的 n 行
import pandas as pd
df = pd.read_csv('nba.csv')
print(df.tail())

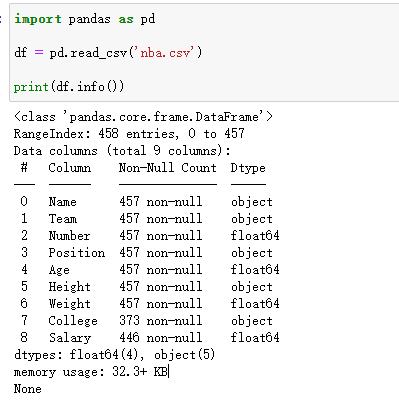
测试五:info() 方法返回表格的一些基本信息
import pandas as pd
df = pd.read_csv('nba.csv')
print(df.info())
5.0Pandas JSON
JSON(JavaScript Object Notation,JavaScript 对象表示法),是存储和交换文本信息的语法,类似XML。
JSON 比 XML 更小、更快,更易解析,更多 JSON 内容可以参考 JSON 教程。
Pandas 可以很方便的处理 JSON 数据,本文以 sites.json 为例,内容如下:
测试一:返回 DataFrame 类型的数据,我们也可以直接处理 JSON 字符串
import pandas as pd
data =[
{
"id": "A001",
"name": "菜鸟教程",
"url": "www.runoob.com",
"likes": 61
},
{
"id": "A002",
"name": "Google",
"url": "www.google.com",
"likes": 124
},
{
"id": "A003",
"name": "淘宝",
"url": "www.taobao.com",
"likes": 45
}
]
df = pd.DataFrame(data)
print(df)

测试二:将 Python 字典转化为 DataFrame 数据
import pandas as pd
# 字典格式的 JSON
s = {
"col1":{"row1":1,"row2":2,"row3":3},
"col2":{"row1":"x","row2":"y","row3":"z"}
}
# 读取 JSON 转为 DataFrame
df = pd.DataFrame(s)
print(df)
6.0Pandas 数据清洗
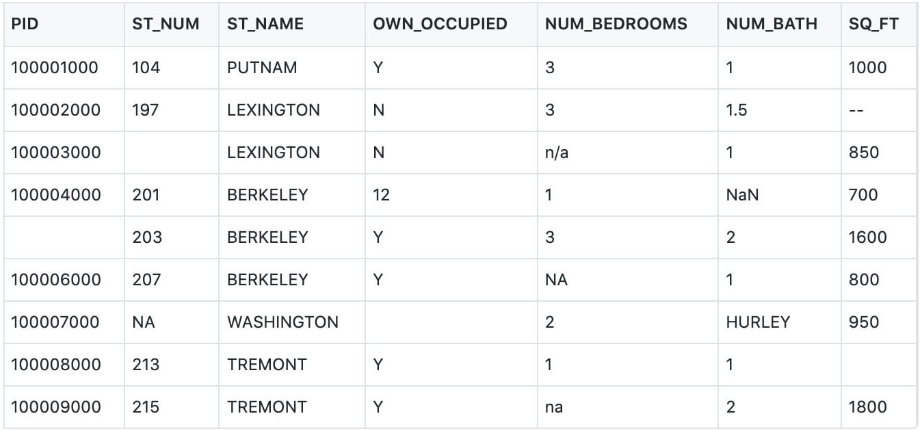
数据集快速下载: property-data.csv
数据清洗是对一些没有用的数据进行处理的过程。
很多数据集存在数据缺失、数据格式错误、错误数据或重复数据的情况,如果要对使数据分析更加准确,就需要对这些没有用的数据进行处理。
表中包含了四种空数据:
- n/a
- NA
- —
- na
Pandas 清洗空值
如果我们要删除包含空字段的行,可以使用 dropna() 方法,语法格式如下:
DataFrame.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)
参数说明:
- axis:默认为 0,表示逢空值剔除整行,如果设置参数 axis=1 表示逢空值去掉整列。
- how:默认为 ‘any’ 如果一行(或一列)里任何一个数据有出现 NA 就去掉整行,如果设置 how=‘all’ 一行(或列)都是 NA 才去掉这整行。
- thresh:设置需要多少非空值的数据才可以保留下来的。
- subset:设置想要检查的列。如果是多个列,可以使用列名的 list 作为参数。
- inplace:如果设置 True,将计算得到的值直接覆盖之前的值并返回 None,修改的是源数据。
我们可以通过 isnull() 判断各个单元格是否为空。
测试一:判断数据是否为空
import pandas as pd
df = pd.read_csv('property-data.csv')
print(df['NUM_BEDROOMS'])
print(df['NUM_BEDROOMS'].isnull())
以上实例输出结果如下:
以上例子中我们看到 Pandas 把 n/a 和 NA 当作空数据,na 不是空数据,不符合我们要求,我们可以指定空数据类型:
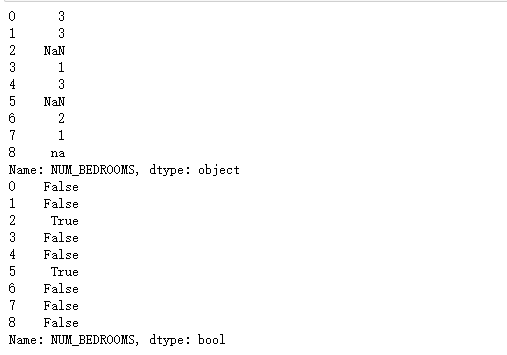
测试二:指定空数据类型
import pandas as pd
missing_values = ["n/a", "na", "--"]
df = pd.read_csv('property-data.csv', na_values = missing_values)
print (df['NUM_BEDROOMS'])
print (df['NUM_BEDROOMS'].isnull())
以上实例输出结果如下:
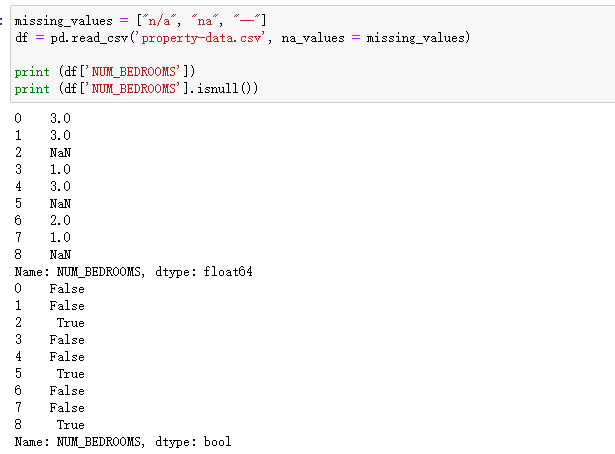
测试三:删除包含空数据的行并对行数据进行输出
import pandas as pd
df = pd.read_csv('property-data.csv')
new_df = df.dropna()
print(new_df.to_string())
以上实例输出结果如下:

注意:默认情况下,dropna() 方法返回一个新的 DataFrame,不会修改源数据。
如果你要修改源数据 DataFrame, 可以使用 inplace = True 参数:
测试四:修改源数据 DataFrame, 可以使用 inplace = True参数:
import pandas as pd
df = pd.read_csv('property-data.csv')
df.dropna(inplace = True)
print(df.to_string())

测试五:我们也可以移除指定列有空值的行
移除 ST_NUM 列中字段值为空的行:
import pandas as pd
df = pd.read_csv('property-data.csv')
df.dropna(subset=['ST_NUM'], inplace = True)
print(df.to_string())
以上实例输出结果如下:

我们也可以 fillna() 方法来替换一些空字段:
测试六:使用 12345 替换空字段:
import pandas as pd
df = pd.read_csv('property-data.csv')
df.fillna(12345, inplace = True)
print(df.to_string())
以上实例输出结果如下:

我们也可以指定某一个列来替换数据:
测试七:使用 12345 替换 PID 为空数据
import pandas as pd
df = pd.read_csv('property-data.csv')
df['PID'].fillna(12345, inplace = True)
print(df.to_string())
以上实例输出结果如下:
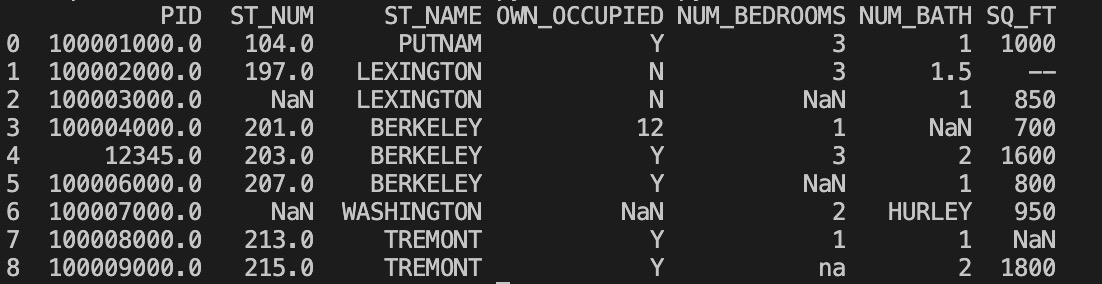
替换空单元格的常用方法是计算列的均值、中位数值或众数。
Pandas使用 mean()、median() 和 mode() 方法计算列的均值(所有值加起来的平均值)、中位数值(排序后排在中间的数)和众数(出现频率最高的数)。
测试八:使用 mean() 方法计算列的均值并替换空单元格
import pandas as pd
df = pd.read_csv('property-data.csv')
x = df["ST_NUM"].mean()
df["ST_NUM"].fillna(x, inplace = True)
print(df.to_string())
以上实例输出结果如下,红框为计算的均值替换来空单元格:

测试九:使用 median() 方法计算列的中位数并替换空单元格:
import pandas as pd
df = pd.read_csv('property-data.csv')
x = df["ST_NUM"].median()
df["ST_NUM"].fillna(x, inplace = True)
print(df.to_string())
以上实例输出结果如下,红框为计算的中位数替换来空单元格:

测试十:使用 mode() 方法计算列的众数并替换空单元格:
import pandas as pd
df = pd.read_csv('property-data.csv')
x = df["ST_NUM"].mode()
df["ST_NUM"].fillna(x, inplace = True)
print(df.to_string())
以上实例输出结果如下,红框为计算的众数替换来空单元格:

Pandas 清洗格式错误数据
数据格式错误的单元格会使数据分析变得困难,甚至不可能。
我们可以通过包含空单元格的行,或者将列中的所有单元格转换为相同格式的数据。
测试十一:格式化日期:
import pandas as pd
# 第三个日期格式错误
data = {
"Date": ['2020/12/01', '2020/12/02' , '20201226'],
"duration": [50, 40, 45]
}
df = pd.DataFrame(data, index = ["day1", "day2", "day3"])
df['Date'] = pd.to_datetime(df['Date'])
print(df.to_string())
以上实例输出结果如下:
Date duration
day1 2020-12-01 50
day2 2020-12-02 40
day3 2020-12-26 45
数据错误也是很常见的情况,我们可以对错误的数据进行替换或移除。
测试十二:替换错误年龄的数据:
import pandas as pd
person = {
"name": ['Google', 'Runoob' , 'Taobao'],
"age": [50, 40, 12345] # 12345 年龄数据是错误的
}
df = pd.DataFrame(person)
df.loc[2, 'age'] = 30 # 修改数据
print(df.to_string())
以上实例输出结果如下:
name age
0 Google 50
1 Runoob 40
2 Taobao 30
也可以设置条件语句:
测试十三:将 age 大于 120 的设置为 120
import pandas as pd
person = {
"name": ['Google', 'Runoob' , 'Taobao'],
"age": [50, 200, 12345]
}
df = pd.DataFrame(person)
for x in df.index:
if df.loc[x, "age"] > 120:
df.loc[x, "age"] = 120
print(df.to_string())
name age
0 Google 50
1 Runoob 120
2 Taobao 120
测试十四:将 age 大于 120 的删除
import pandas as pd
person = {
"name": ['Google', 'Runoob' , 'Taobao'],
"age": [50, 40, 12345] # 12345 年龄数据是错误的
}
df = pd.DataFrame(person)
for x in df.index:
if df.loc[x, "age"] > 120:
df.drop(x, inplace = True)
print(df.to_string())
name age
0 Google 50
1 Runoob 40
Pandas 清洗重复数据
如果我们要清洗重复数据,可以使用 duplicated() 和 drop_duplicates() 方法。
如果对应的数据是重复的,duplicated() 会返回 True,否则返回 False。
测试十五:判断是否有重复值
import pandas as pd
person = {
"name": ['Google', 'Runoob', 'Runoob', 'Taobao'],
"age": [50, 40, 40, 23]
}
df = pd.DataFrame(person)
print(df.duplicated())
0 False
1 False
2 True
3 False
dtype: bool
测试十六:删除重复数据
import pandas as pd
persons = {
"name": ['Google', 'Runoob', 'Runoob', 'Taobao'],
"age": [50, 40, 40, 23]
}
df = pd.DataFrame(persons)
df.drop_duplicates(inplace = True)
print(df)
name age
0 Google 50
1 Runoob 40
3 Taobao 23

















 3543
3543











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











