










感谢您抽出
.

阅读本文
01、网络
Playwright 提供 API 来监控和修改网络流量,包括 HTTP 和 HTTPS。该页面所做的任何请求,包括XHR和fetch请求,都可以被跟踪、修改和处理。
02、HTTP 身份验证
我们平常在测试的时候,有时候会发现出于安全考虑,开发将测试环境网站加了HTTP身份认证,当我们打开网站的时候,会弹出输入用户名和密码,才能正常访问,如
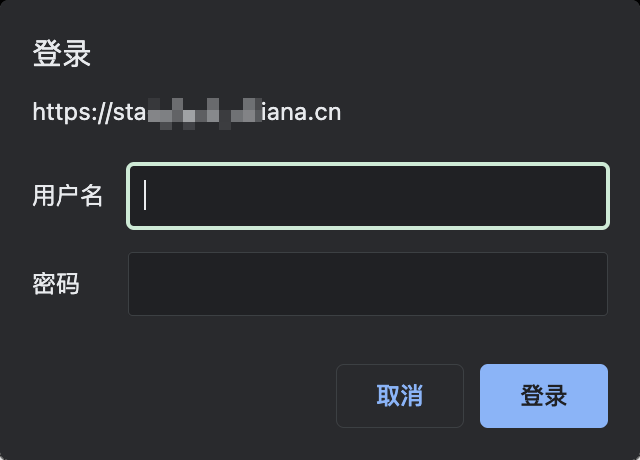
我们在使用Playwright做UI自动化时,如何自动输入上图所示的用户名和密码呢?
我们可以使用以下代码来实现此功能,代码如下
context = browser.new_context(
http_credentials={"username": "bill", "password": "pa55w0rd"}
)
page = context.new_page()
page.goto("https://example.com")
def run(playwright: Playwright):
browser = playwright.chromium.launch(channel="chrome", headless=False)
context = browser.new_context(
http_credentials={"username": "admin", "password": "sitaIkfw*a"}
)
page = context.new_page()
page.goto("https://sit.iana.con/")
page.close()
with sync_playwright() as playwright:
run(playwright)
03、HTTP 代理
Playwright 还可以很方便地设置代理。
# 全局代理
PROXY_HTTP = "127.0.0.1:60002"
browser = playwright.chromium.launch(channel="chrome", headless=False, proxy={
"server": PROXY_HTTP,
"username": "",
"password": ""
})
在为每个上下文单独指定代理时,Windows 上的 Chromium需要提示将设置代理。这是通过将非空代理服务器传递给浏览器本身来完成的。
# 上下文的代理
PROXY_HTTP = "127.0.0.1:60002"
browser = playwright.chromium.launch(proxy={"server": "per-context"})
context = browser.new_context(proxy={"server": PROXY_HTTP})
04、网络事件
Playwright还可以监控所有网络请求和响应。
我们以博客园以例,可以看到所有GET和POST请求以及响应均被打印了出来。
import time
from playwright.sync_api import Playwright, sync_playwright
def run(playwright: Playwright):
browser = playwright.chromium.launch(channel="chrome", headless=False)
context = browser.new_context()
page = context.new_page()
# 获取网络请求
page.on("request", lambda request: print(">>", request.method, request.url))
# 获取网络响应
page.on("response", lambda response: print("<<", response.status, response.url))
page.goto("https://www.cnblogs.com/mrjade")
page.close()
with sync_playwright() as playwright:
run(playwright)
05、页面(page)
我们从以往的例子中会看出,每个脚本都会使用page = context.new_page(),该代码相当于手动创建了一个新的浏览器tab页。如果我们想打开多个浏览器tab页,又该如何操作呢
# create two pages
page_one = context.new_page()
page_two = context.new_page()1.处理新页面
浏览器上下文上的page事件可用于获取在上下文中创建的新页面。如果是由target="_blank"链接打开的新页面,我们又该如何处理呢。
# Get page after a specific action (e.g. clicking a link)
with context.expect_page() as new_page_info:
page.locator('a[target="_blank"]').click() # Opens a new tab
new_page = new_page_info.value
new_page.wait_for_load_state()
print(new_page.title())2.处理弹出窗口
如果页面打开一个弹出窗口(例如通过链接打开的页面),可以通过监听页面上的事件target="_blank"来获得对它的引用,比如注册126邮箱,就用此方法,不知道的小伙伴可以查看下往期文章。
# Get popup after a specific action (e.g., click)
with page.expect_popup() as popup_info:
page.locator("#open").click()
popup = popup_info.value
popup.wait_for_load_state()
print(popup.title())06、截图
当我们自动化脚本在运行中出现错误时,需要对当前操作页面进行截图,以便我们查找问题。
1.当前页面截图
page.screenshot(path="screenshot.png")2.整页截图
page.screenshot(path="screenshot.png", full_page=True)3.截取指定元素的部分
page.locator("#page >> text=2").screenshot(path="screenshot.png")
页码2的截图
//未完待续
最后感谢每一个认真阅读我文章的人,看着粉丝一路的上涨和关注,礼尚往来总是要有的,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走
这些资料,对于做【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴我走过了最艰难的路程,希望也能帮助到你!凡事要趁早,特别是技术行业,一定要提升技术功底。希望对大家有所帮助…….
如果你不想再体验一次自学时找不到资料,没人解答问题,坚持几天便放弃的感受的话,可以加入下方我的qq群大家一起讨论交流,里面也有各种软件测试资料和技术交流。
















 1414
1414











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









