







单数据源多端输出
我们使用 Flume 监控数据时,有时需要将数据输出到 Kafka 做中间量数据转化。
但是我们有时候也会需要将监控到的数据进行备份,所有就有了多端输出。
文章中的这个示例是通过 Flume 单文件,进行配置 Flume 监控端口数据,输出到 Kafka、HDFS 示例。
直接上代码:
# 创建组件
a1.sources = s1
# 设置两个缓存器,对接两个 Sink
a1.channels = c1 c2
# 输出到两个端,创建两个 Sink
a1.sinks = k1 k2
# 配置数据源接口,监控端口为所以类型为 netcat,我的虚拟机端口 10050
a1.sources.s1.type = netcat
a1.sources.s1.bind = master
a1.sources.s1.port = 10050
# 配置两个缓存器,两个配置一样就好了
# 设置为内存缓存
a1.channels.c1.type = memory
# 内存中存储 Event 的最大数
a1.channels.c1.capacity = 1000
# source 或者 sink 每个事务中存取 Event 的操作数量(不能比 capacity 大)
a1.channels.c1.transactionCapacity = 100
a1.channels.c2.type = memory
a1.channels.c2.capacity = 1000
a1.channels.c2.transactionCapacity = 100
# 设置 Sink 到 Kafka 中
# 设置 Sink 类型,这里为 Kafka sink jar包
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
# 设置存储到的 topic
a1.sinks.k1.topic = order
# 设置 Kafka 服务器地址
a1.sinks.k1.kafka.bootstrap.servers = master:9092,slave1:9092,slave2:9092
# 一批中要处理的消息数。设置较大的值可以提高吞吐量,但是会增加延迟。
a1.sinks.k1.kafka.flumeBatchSize = 20
# 在考虑成功写入之前,要有多少个副本必须确认消息。可选值, 0 :(从不等待确认); 1 :只等待leader确认; -1 :等待所有副本确认。 设置为-1可以避免某些情况 leader 实例失败的情况下丢失数据。
a1.sinks.k1.kafka.producer.acks = 1
# 设置延时时间
a1.sinks.k1.kafka.producer.linger.ms = 1
# 设置压缩器
a1.sinks.k1.kafka.producer.compression.type = snappy
# 上传类型为HDFS
a1.sinks.k2.type = hdfs
# 上传文件的地址(如果这里使用时间配置的话,后面一定要配置:roundValue、roundUnit 、useLocalTimeStamp)
a1.sinks.k2.hdfs.path = hdfs://master:8020/user/test/flumebackup/%{type}/%Y%m%d
# 上传文件前缀
a1.sinks.k2.hdfs.filePrefix = backup
# #设置文件类型,可以是SequenceFile(序列化文件),DataStream(普通文件) or CompressedStream(压缩文件)
a1.sinks.k2.hdfs.fileType = DataStream
# 写入格式
a1.sinks.k2.hdfs.writeFormat = Text
# 向下舍入的值,需要和roundUnit配合使用
a1.sinks.k2.hdfs.roundValue = 1
# 向下舍入的单位,可以是second,minute,hour
a1.sinks.k2.hdfs.roundUnit = hour
#是否使用本地时间戳
a1.sinks.k2.hdfs.useLocalTimeStamp = true
# 根据events达到多少进行滚动
a1.sinks.k2.hdfs.rollCount = 0
# 多少秒滚动一次
a1.sinks.k2.hdfs.rollInterval = 0
#文件大小达到多少会触发roll
a1.sinks.k2.hdfs.rollSize = 10482500
#积攒多少个event才flush到HDFS一次
a1.sinks.k2.hdfs.batchSize = 20
# 开启的线程数
a1.sinks.k2.hdfs.threadPoolSize = 10
# 允许HDFS操作文件的时间,比如:open、write、flush、close。如果HDFS操作超时次数增加,应该适当调高这个这个值。(毫秒)
a1.sinks.k2.hdfs.callTimeOut = 30000
# 源连接缓存
a1.sources.s1.channels = c1 c2
# 每个 Sink 对应一个缓存器
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c2
启动 Flume 监控的格式为:bin/flume-ng agent -n $agent-name -c conf/ -f conf/flume-conf.properties。
- agent:必须指定,启动一个agent 进程;
- -n:agent名称,要和flumeagent配置文件中的名称一致;
- -c:Flume配置文件所在的目录,每个agent启动,都需要读取一些自定义的文件;
- -f:当前agent的配置文件;
- 必须指定agent的名称,配置文件的目录和配置。
启动 Flume 监控端口:bin/flume-ng agent -n a1 -c conf/ -f jobs/flume-netcat-test1.conf。
启动后的结果为:

最后的显示为:
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/software/apache-flume-1.7.0-bin/lib/slf4j-log4j12-1.6.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/software/hadoop-2.7.1/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
说明启动成功。
对端口进行输出数据:telnet master 10050 通过 telnet 命令连接端口服务。
显示为下面的界面就说明连接端口成功,就可以直接输入数据。

启动 Kafka 消费者 bin/kafka-console-consumer.sh --topic order --bootstrap-server master:9092,查看监控结果:

向端口传输数据 telnet master 10050:

Kafka 中成功接收数据:

查看 HDFS 中的结果,这里我们直接进入 web 界面查看:
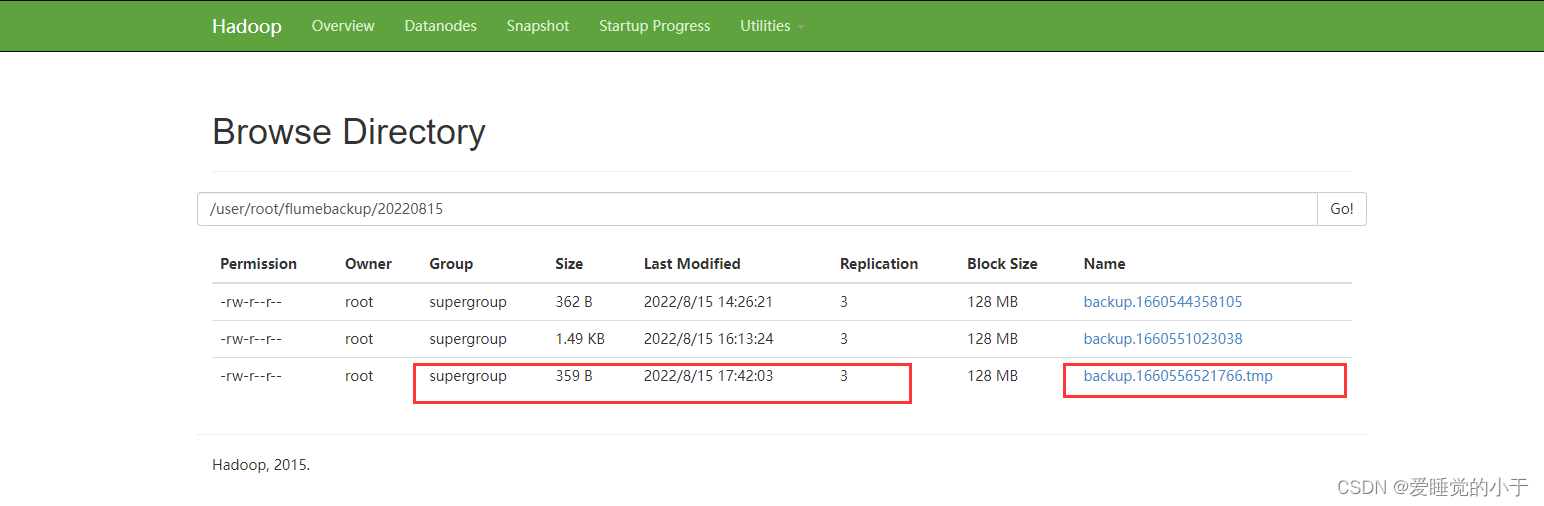
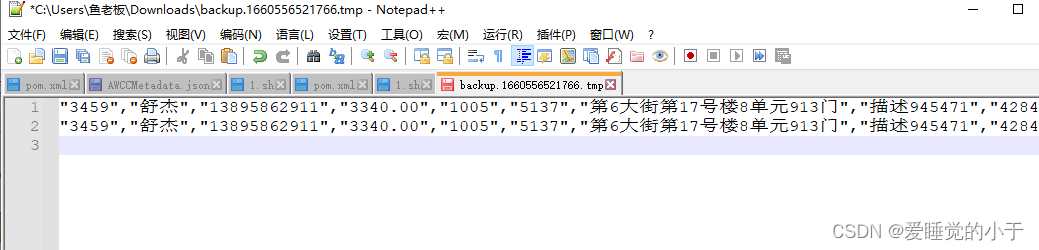
成功!!















 1299
1299











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









