






目录
7. 将slave1中的JDK安装包分发给slave2、slave3
8.将slave1中配置好的环境变量文件分发给slave2、slave3
一、前期准备
1.配置好jdk的环境
2.配置ssh免密登录
3.配置ip地址和主机名的映射
4.关闭防火墙
二、配置hadoop环境变量
提取码: 1v28
1.解压到当前目录,我的是在/opt目录下
tar zxvf hadoop-2.9.1.tar.gz 2.配置hadoop环境变量,在etc/profile.d目录下
个人习惯把环境变量放在该配置文件
vim my_enc.shexport HADOOP_HOME="/opt/hadoop-2.9.1"
export PATH="$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH" 
3.让配置的环境变量生效
source /etc/profile4.检查是否配置成功
hadoop version出现如下版本号,即成功配置
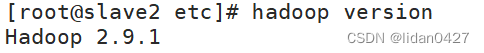
三、搭建hadoop集群(三台为例)
namenode、 datanode、 secondarynamenode、resourcemanager、nodemanager
(名字节点) (数据节点)(备用的名字节点) (资源管理器) (节点管理器)
集群规划
| slave1 | slave2 | slave3 | |
| hdfs | namenode datanode | secondarynamenode datanode | datanode |
| yarn | nodemanager | nodemanager | resourcemanager nodemanager |
建议:namenode、secondarynamenode、resourcemanager都比较耗费系统资源,所以尽量不要部署在同一台服务器上
创建文件夹
#hadoop运行时产生数据的存放路径
mkdir /opt/hadoop-record/tmp
#配置hdfs的namenode存储的路径
mkdir /opt/hadoop-record/name
#配置hdfs的datanode存储的路径
mkdir /opt/hadoop-record/data修改配置文件,我是在以下路径
cd /opt/hadoop/etc/hadoop1.hadoop-env.sh
vim hadoop-env.sh 
2.core-site.xml
vim core-site.xml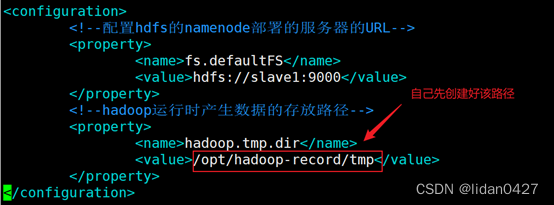
3. hdfs-site.xml
vim hdfs-site.xml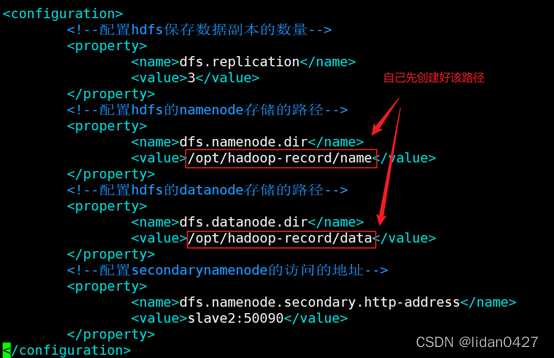
4. mapred-site.xml
vim mapred-site.xml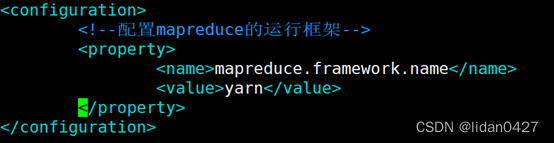
5. yarn-site.xml
vim yarn-site.xml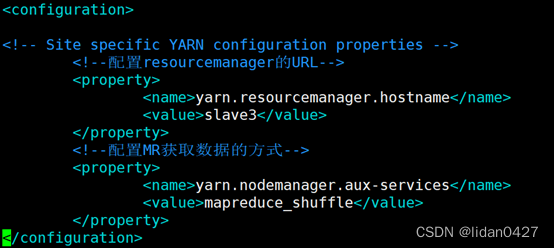
6. 指定datanode存放的服务器
vim slaves
7. 将slave1中的JDK安装包分发给slave2、slave3
#分发到slave2 jdk路径:/opt/jdk1.8.0_212/
scp -r /opt/jdk1.8.0_212/ slave2:/opt/
#分发到slave3
scp -r /opt/jdk1.8.0_212/ slave3:/opt/8.将slave1中配置好的环境变量文件分发给slave2、slave3
#分发到slave2
scp -r /etc/profile.d/my_enc.sh slave2:/etc/profile.d/
#分发到slave3
scp -r /etc/profile.d/my_enc.sh slave3:/etc/profile.d/分发完成,要让slave2、slave3的配置生效,需要在slave2和slave3上分别source /etc/profile文件
source /etc/profile9.分发配置好的hadoop文件
#分发到slave2
scp -r /opt/hadoop-2.9.1/ slave2:/opt
scp -r /opt/hadoop-record/ slave2:/opt
#分发到slave3
scp -r /opt/hadoop-2.9.1/ slave3:/opt
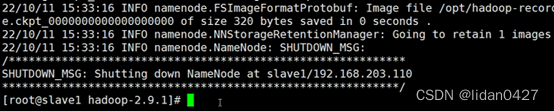
scp -r /opt/hadoop-record/ slave3:/opt10.格式化namenode(slave1)
说明:namenode部署在哪台服务器上,就只需要在该台服务器上格式化namenode即可
/opt/hadoop-2.9.1/bin/hdfs namenode -format ![]()
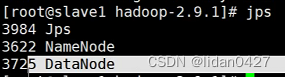
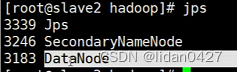
11.启动hdfs(slave1)
说明:hdfs部署在哪台服务器上就在哪台服务器上启动hdfs

此时三台的进程如下
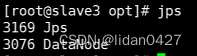
12.启动yarn(slave3)
说明:yarn部署在哪台服务器上就在哪台服务器上启动yarn
./sbin/start-yarn.sh![]()
13.启动完成,每台服务器上的进程情况
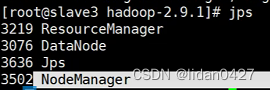
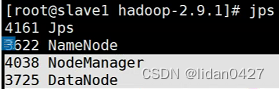
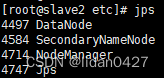
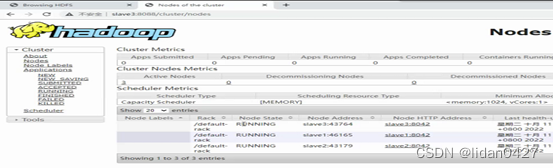
14.web访问
访问hdfs:http://slave1:50070

访问yarn:http://slave3:8088
注意:若在启动过程中,有个别进程或服务器中的进程未正常启动,则修改文件后需要清空datanode数据存放路径、namenode数据存放路径及tmp路径下的文件,然后重新格式化namenode,最后再启动集群
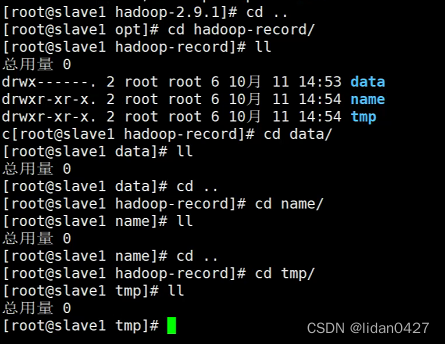
清空之后再启动hdfs和yarn















 3776
3776











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









