







目录
Flink on Yarn模式:一般企业使用,资源管理交由Yarn来管理
Flink on Yarn模式:一般企业使用,资源管理交由Yarn来管理
1.会话模式:先在yarn集群上启动Flink集群,后再向Flink集群中提交作业,Flink集群会一直存在,除非用户手动的去关闭Flink集群(同时提交多个任务)
2.单作业模式:Flink不需要提前启动,而是在向Flink提交作业时会自动启动一个Flink集群,一旦作业执行完毕,集群也随之消失
3.应用模式:跟单作业模式类似,也是不需要提前启动Flink集群,而是在向Flink集群提交作业时会自动启动一个Flink集群,一旦作业执行完毕,集群也随之消失
一、使用Flink的前期准备
1.在hadoop的yarn-site.xml配置文件关闭yarn的内存检查
![]()
![]()
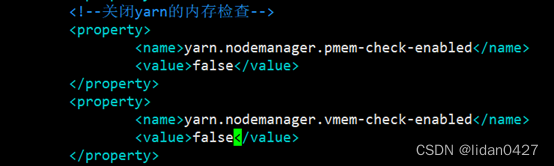
将修改后的yarn-site.xml文件分发到slave2和slave3


2.配置环境变量,在环境变量中添加上yarn的配置信息
![]()
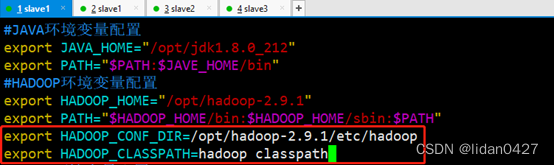
将修改后的环境变量文件分发到集群的slave2和slave3


分别在每台服务器(slave1slave2slave3)中刷新一下环境变量,让配置的环境变量生效



3.安装 Flink
下载并上传至linux系统
可以去官网下载
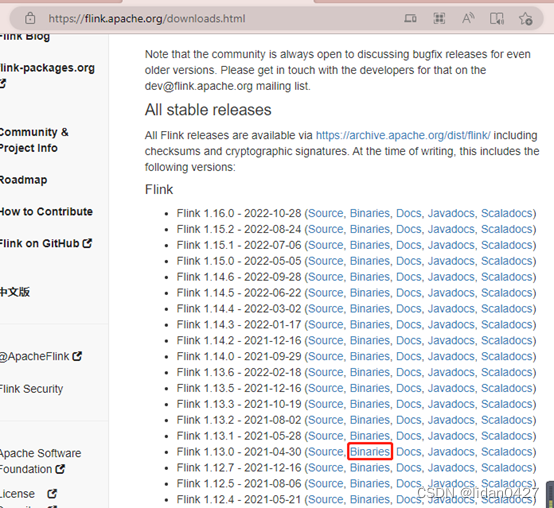
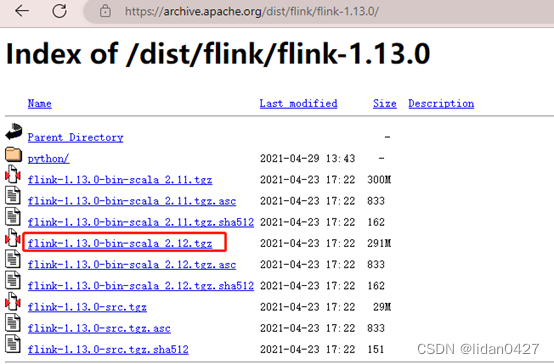
提取码: 8ifw
解压并重命名
![]()

将hadoop依赖的包拷贝到flink的lib目录下


二、使用Flink(即可以向Flink中提交作业)
1.会话模式:
会话模式使用场景:运行执行时间短,规模小的作业
1)启动hadoop集群

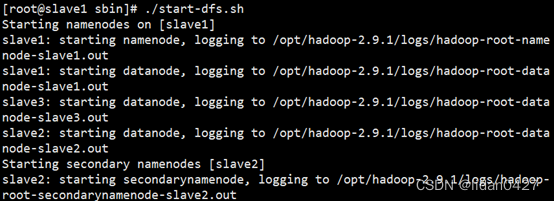

2)启动Flink集群:
前台进程启动:

![]()
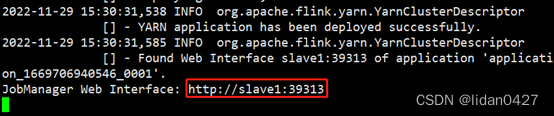
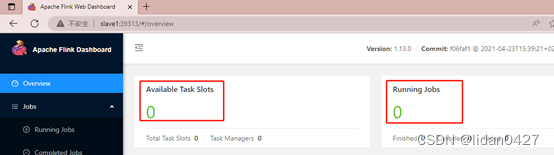
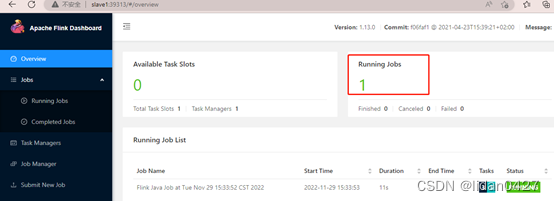
任务槽为0,没有任务所以为0
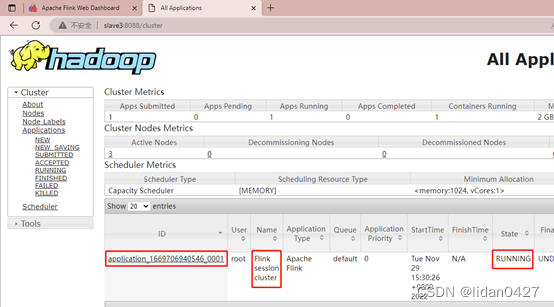
执行计算单词个数的任务
![]()
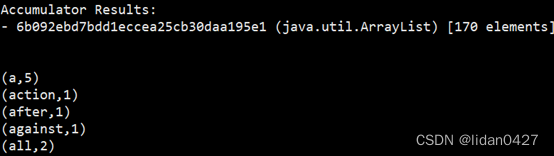
计算结果可见
后台进程挂起:
![]()
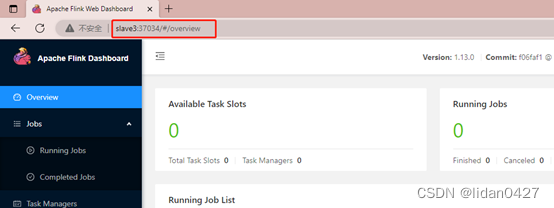
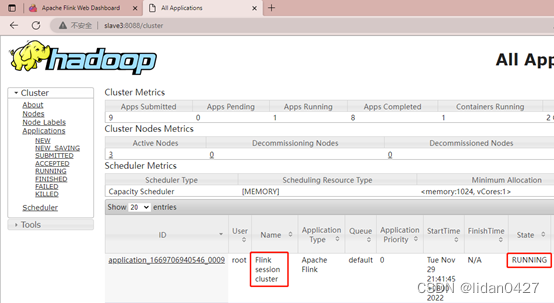
做一个简单的单词计算
![]()

计算结果(没有全部显示)

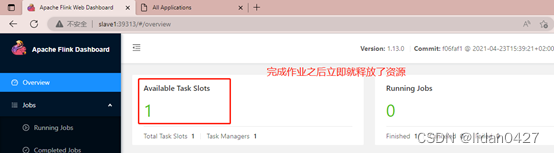
3)关闭某个Flink集群,kill之后内存会马上释放出来
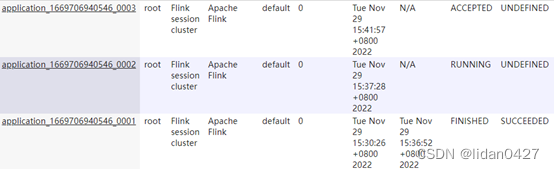

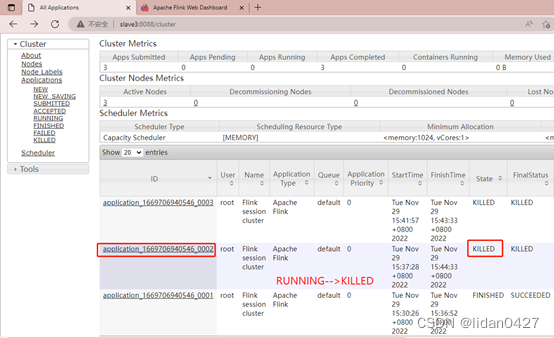
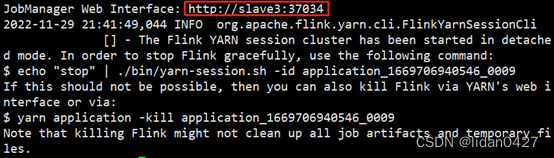
2.单作业模式
一个作业一个集群,任务完成使命终止
-d:后台运行
-t yarn-per-job单作业模式



执行任务时也指定一些参数:
![]()
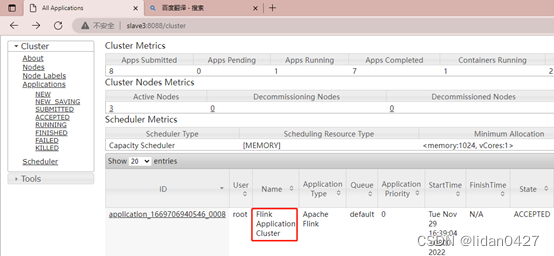
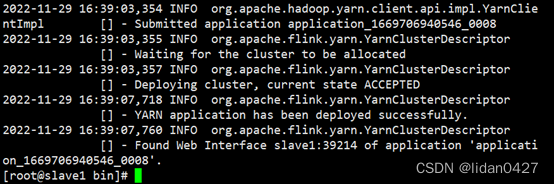
3.应用模式
适用场景:适用大规模、执行时间长的作业(资源回收,释放资源)
![]()















 3888
3888

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









