







贝叶斯分类器:以贝叶斯理论为基础,在这个理论中有三个非常重要的概念
先验概率:每类样本的出现的概率 P(wi)
类条件概率:每类中的样本取得某个具体特征向量的概率 P(x,wi)
后验概率:样本取得某个具体特征向量时属于每类的概率 P(wi,x)
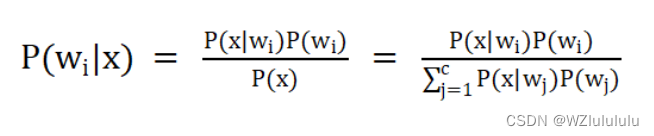
在手写数字识别中,0-9出现的先验概率为1/10,每张图片大小为32x32,转换为一个包含784个特征向量的一纬向量,计算每类中,784个特征向量出现的概率即为类条件概率。
后验概率是在测试样本时使用。已知样本的先验概率,特征向量的类条件概率。就可以测试出测试集中的样本处于被归为某类的概率。
具体python代码实现如下,计算类条件概率时需要将图像进行二值化,数据集在模板匹配算法中给出
import numpy as np
import scipy.io as sio
from tqdm import tqdm
#cal the train and test datasets
train_path = './课程数据集/mat格式的MNIST数据/train_images.mat'
train_data = sio.loadmat(train_path)
key_train = list(train_data.keys())[-1]
train = train_data[key_train]
train_label_path = './课程数据集/mat格式的MNIST数据/train_labels.mat'
train_lab = sio.loadmat(train_label_path)
key_train_label = list(train_lab.keys())[-1]
train_label = train_lab[key_train_label]
test_path = './课程数据集/mat格式的MNIST数据/test_images.mat'
test_data = sio.loadmat(test_path)
key_test = list(test_data.keys())[-1]
test = test_data[key_test]
test_label_path = './课程数据集/mat格式的MNIST数据/test_labels.mat'
test_lab = sio.loadmat(test_label_path)
key_test_label = list(test_lab.keys())[-1]
test_label = test_lab[key_test_label]
#cal the binaryzation (二值化)
def binaryzation(img):
h,w = img.shape
img_data = np.zeros((h,w))
for i in range(h):
for j in range(w):
if img[i,j] != 0:
img_data[i,j] = 1
else:
img_data[i,j] = 0
return img_data
#cal the prior_pro and conditional_pro (先验概率和条件概率)
def pro(train_data,train_label):
# prior_pro(先验概率)
prior_pro =np.zeros(10)
# conditional_pro(条件概率)
conditional_pro = np.zeros((10,784))
for i in tqdm(range(len(train_label.flatten()))):
img = binaryzation(train_data[:,:,i]).flatten()
label = train_label[:,i]
prior_pro[label] +=1
for j in range(784):
conditional_pro[label,j] +=img[j]
#转化为概率
for w in tqdm(range(10)):
for n in range(784):
conditional_pro[w,n] = (conditional_pro[w,n] +1) / (prior_pro[w] + 2)
prior_pro = prior_pro / 60000
return prior_pro,conditional_pro
#cal the pridict
def pridict(test,test_label,prior_pro,conditional_pro):
acc = 0
for i in tqdm(range(10000)):
img_in = test[:,:,i]
img = binaryzation(img_in).flatten()
label = test_label[:,i]
result = 0
pro = 0
for j in range(10):
pro_y = 1
for m in range(784):
pix_img = img[m]
if (pix_img==1):
pro_y *=conditional_pro[j][m]
else:
pro_y *=(1-conditional_pro[j][m])
#后验概率
pro_out = prior_pro[j] * pro_y
if pro < pro_out:
pro = pro_out
result = j
if label == result:
acc += 1
return acc
prior_pro,conditional_pro = pro(train,train_label)
test_out = pridict(test,test_label,prior_pro,conditional_pro)
print("测试集的准确率为:{}".format(test_out/10000))















 6372
6372











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









