






1.图的基本概念
1.线性表可以是空表,树可以是空树,但图不可以是空图。
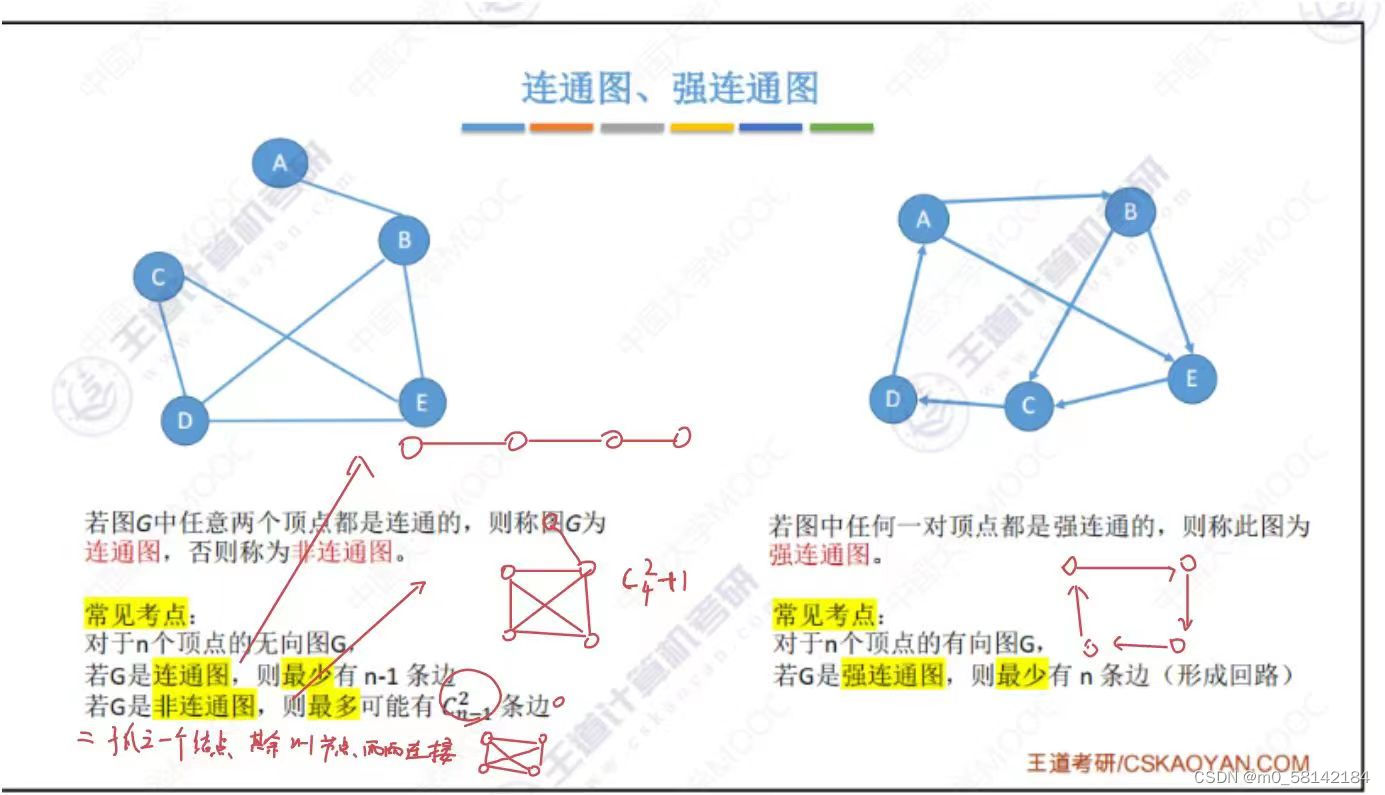
2. 数据结构这门课只探究简单图(无重复边,无顶点到自身的边)
3.图的度=所有结点的 入度+ 所有结点的 出度
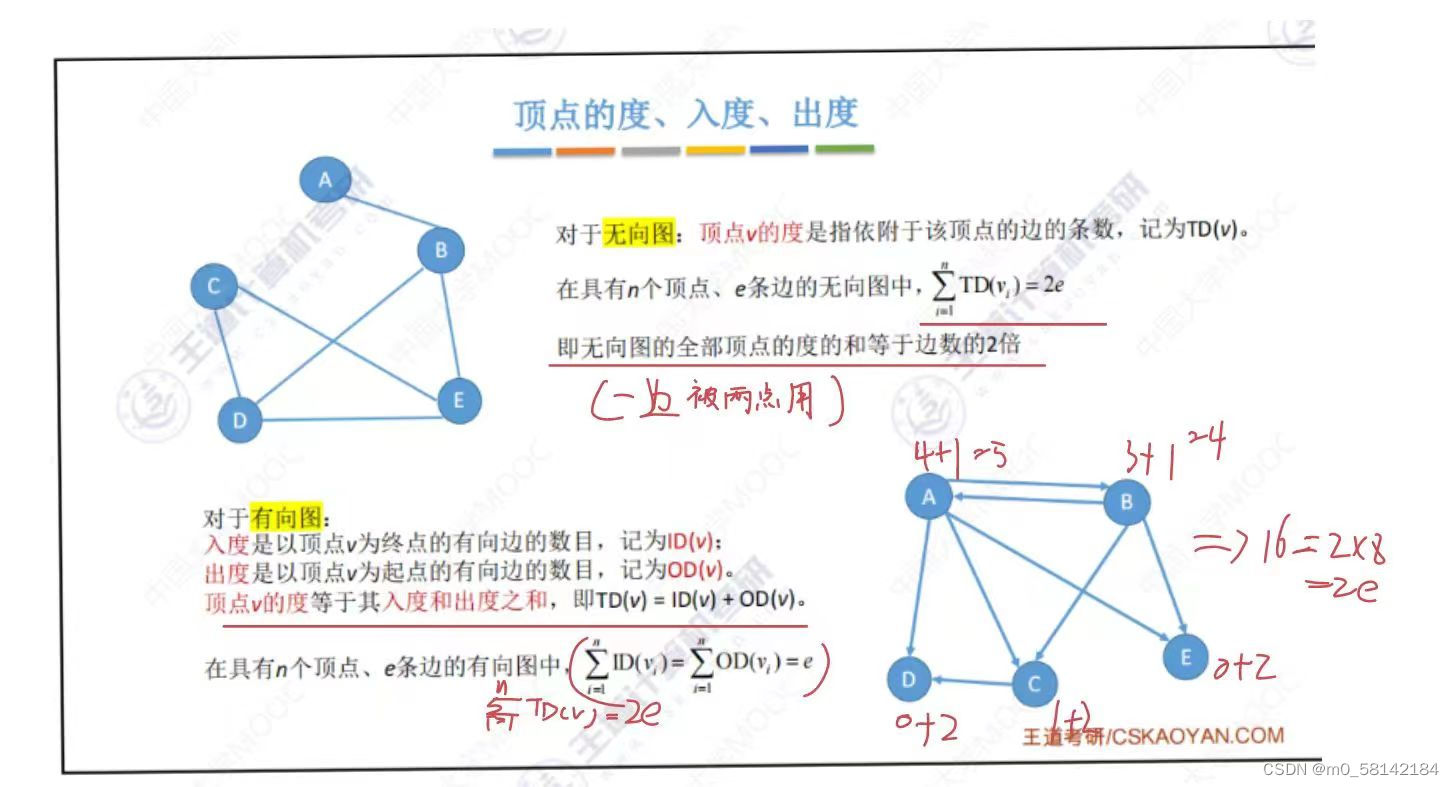
无论是有向图还是无向图 图的度=边x2=ex2
都是一边被两点分别用一次 共用两次

2.图的存储
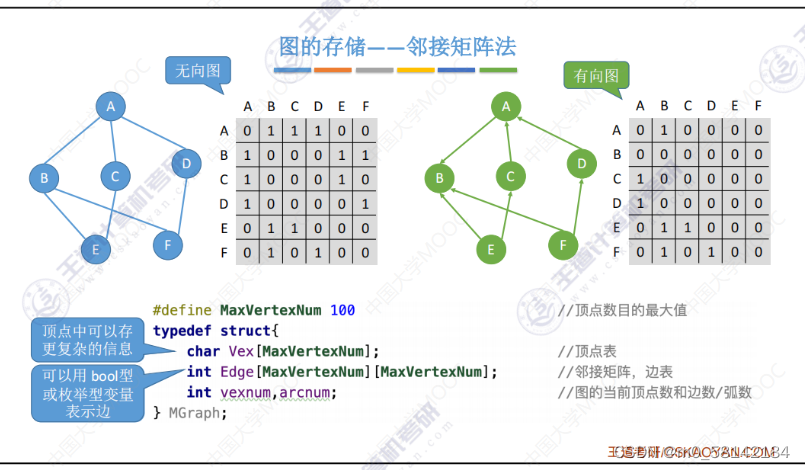
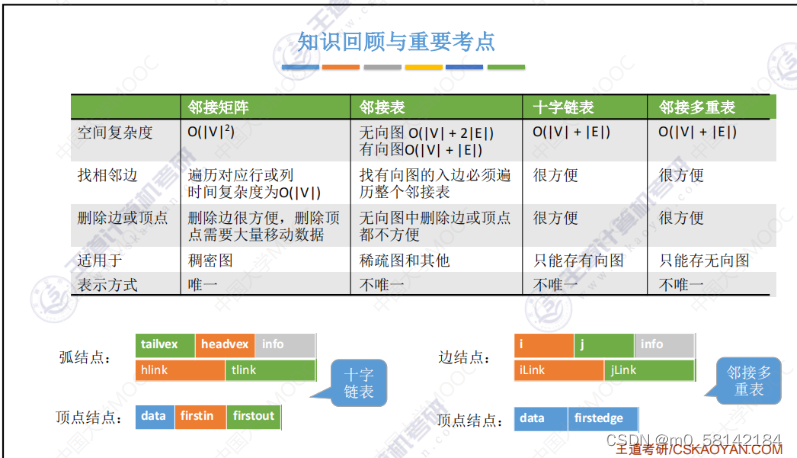
《1》邻接矩阵法



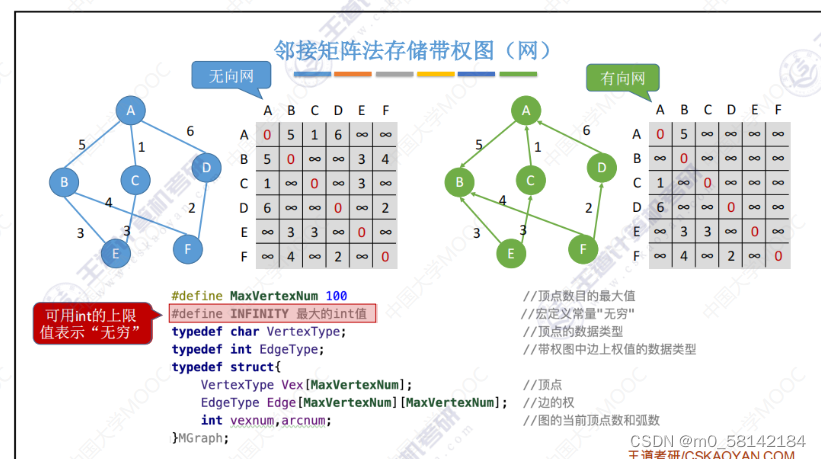
- 带权图邻接矩阵法存储
- 邻接矩阵法的性能分析
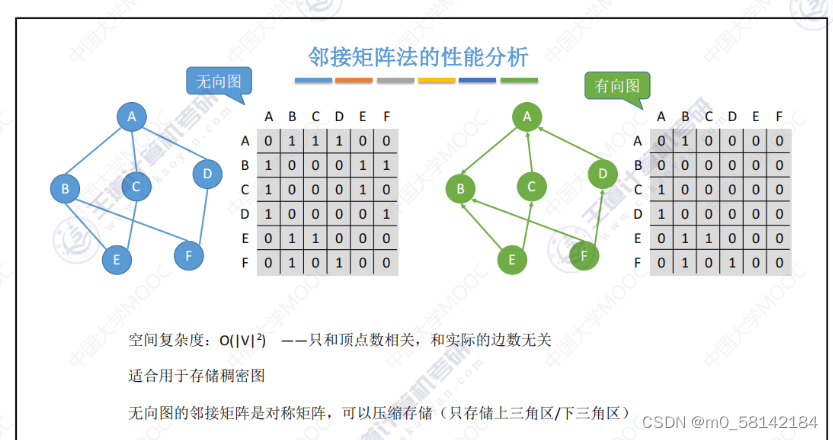
数组实现的顺序存储,空间复杂度较高,不适合存储稀疏图

- 邻接矩阵的性质

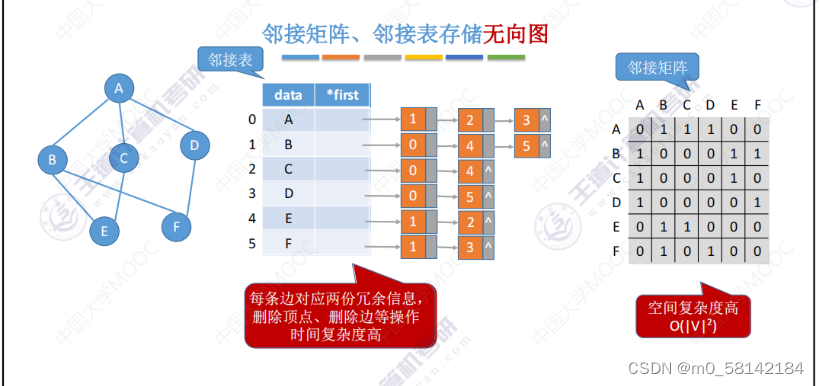
《2》邻接表
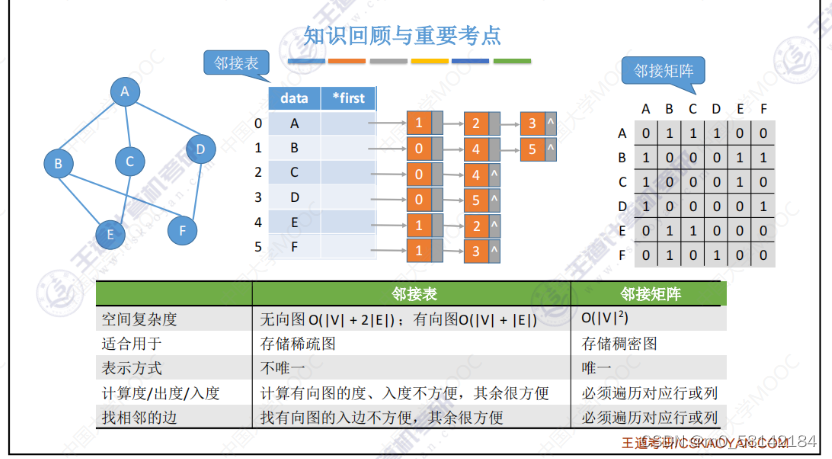



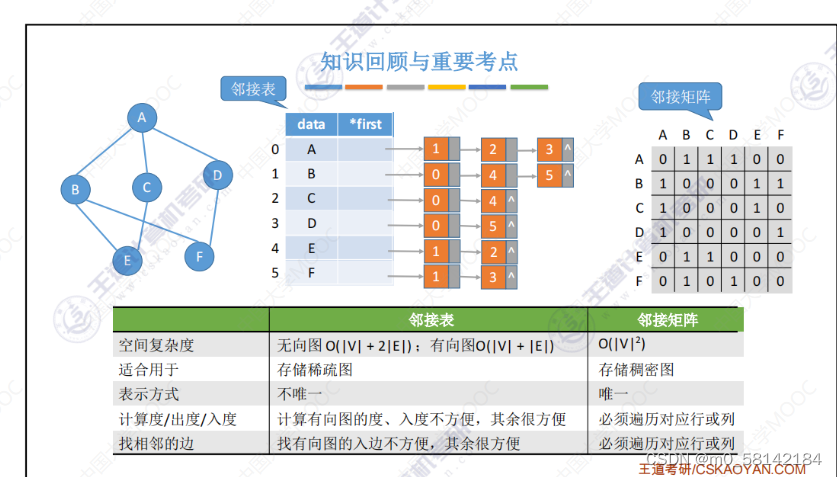
《3》十字链表
存储有向图
解决邻接表找入边/入度不方便的问题
解决邻接矩阵空间浪费的问题


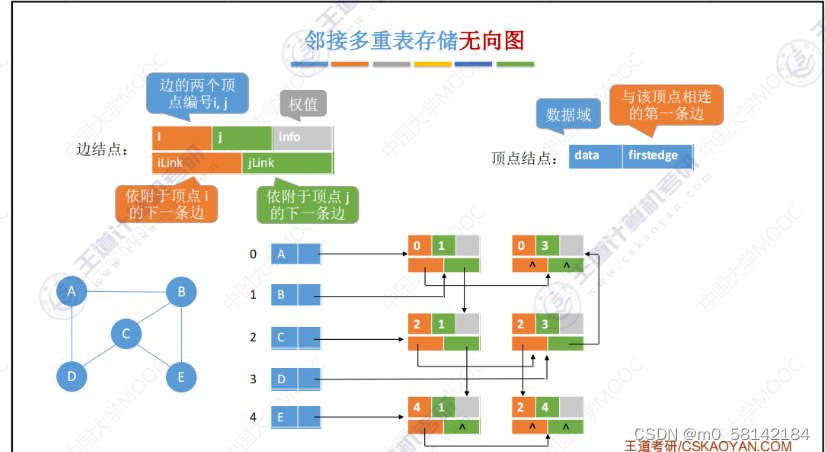
《4》邻接多重表
解决邻接表的冗余信息的问题
邻接矩阵空间复杂度高的问题

《5》基本操作

- Adjacent(G,X,y) 判断是否存在特定的边

- 找点A的邻接边X

- 在图G中插入定点X
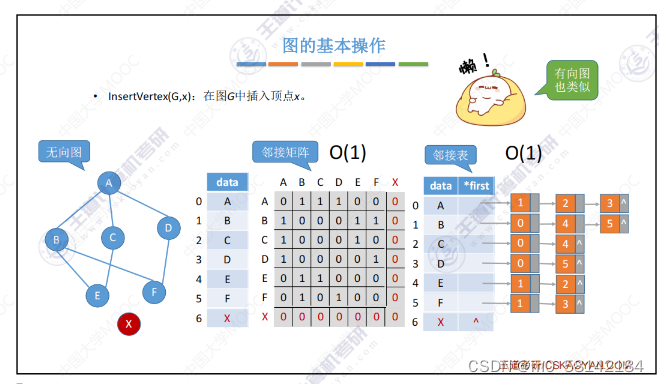
邻接边可用头插法与尾插法 头插法为优
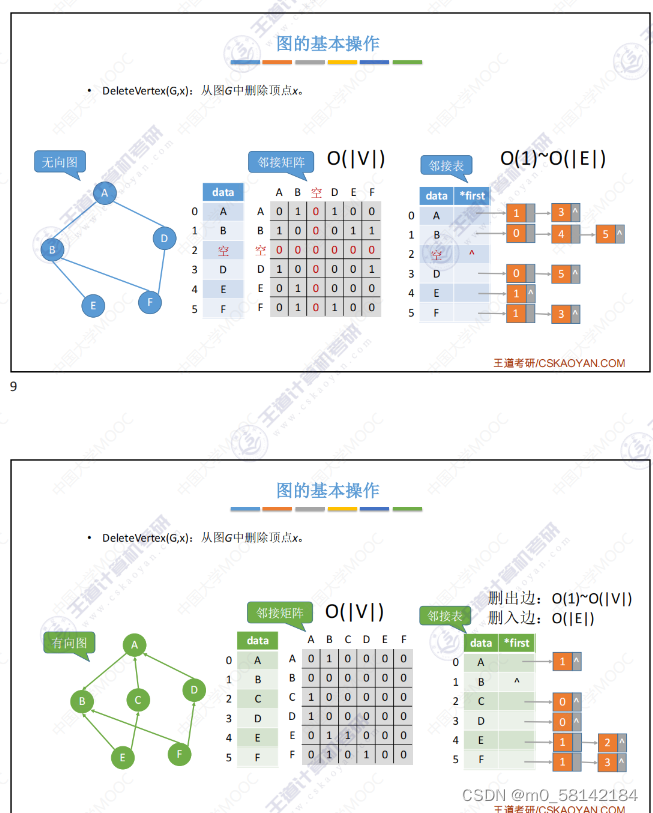
- 删除顶点X
 - 找定点A的第一个邻接点X
- 找定点A的第一个邻接点X
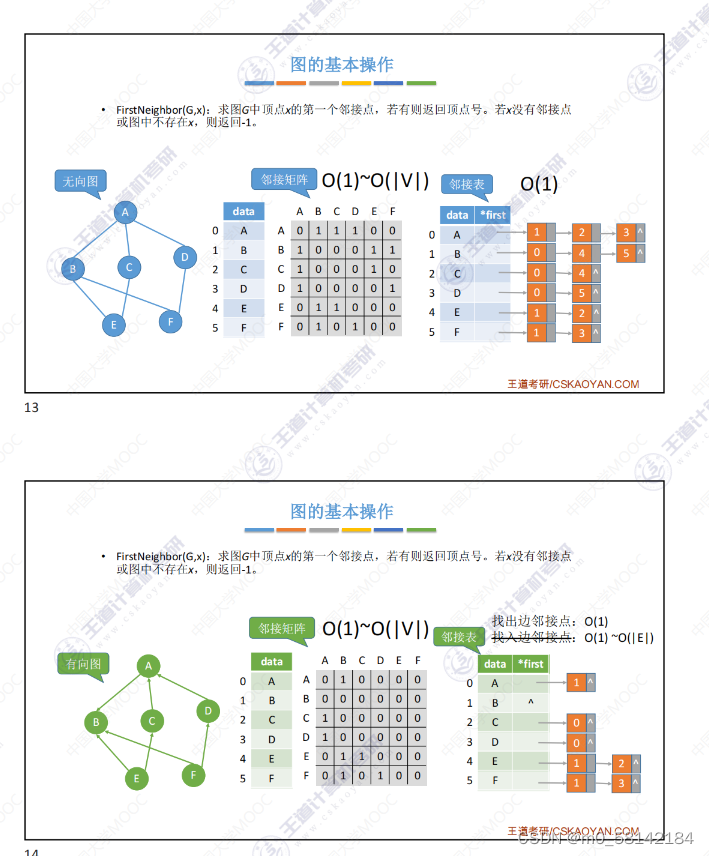
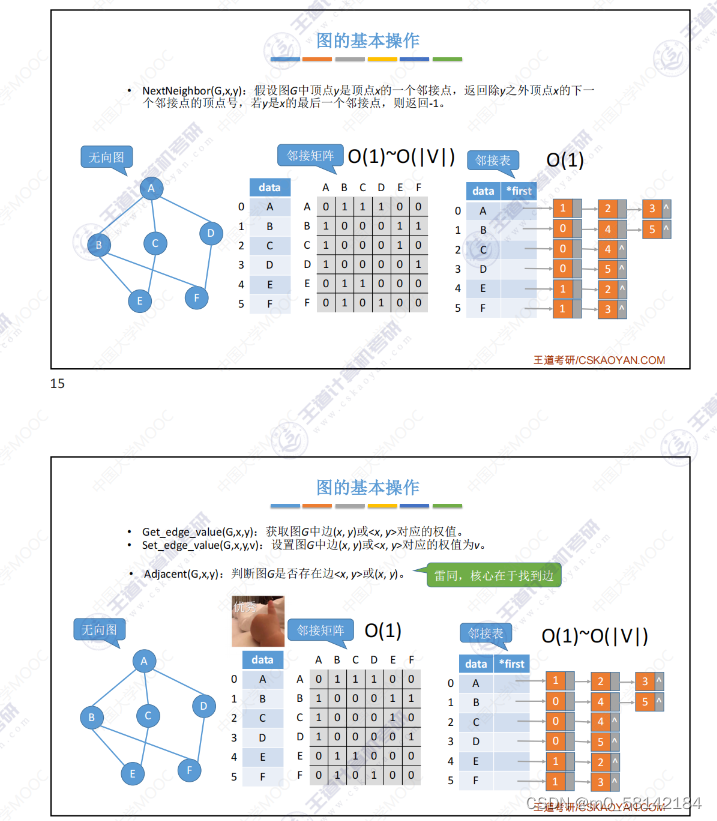
3.图的遍历
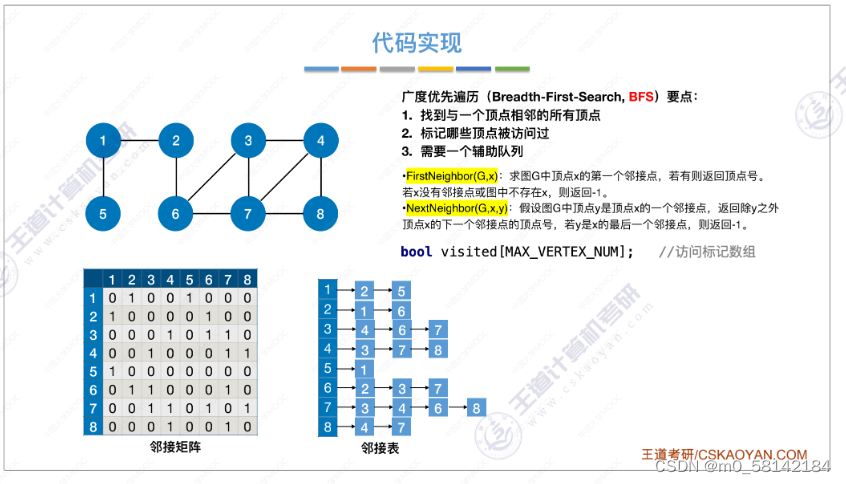
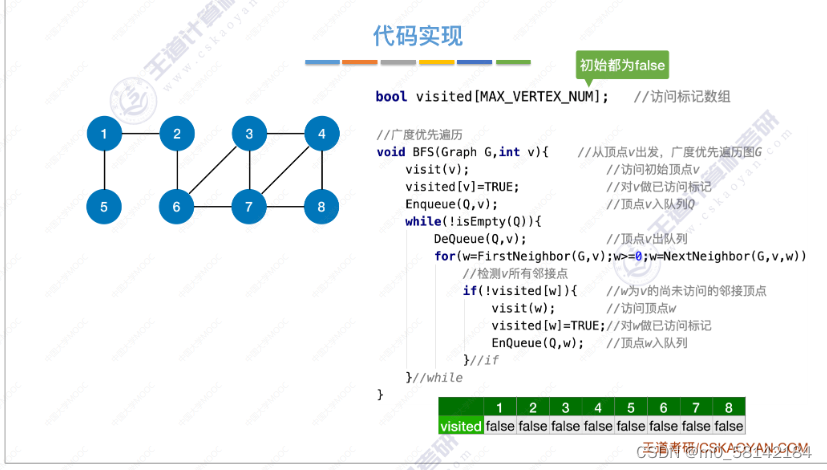
《1》广度优先遍历(BFS)
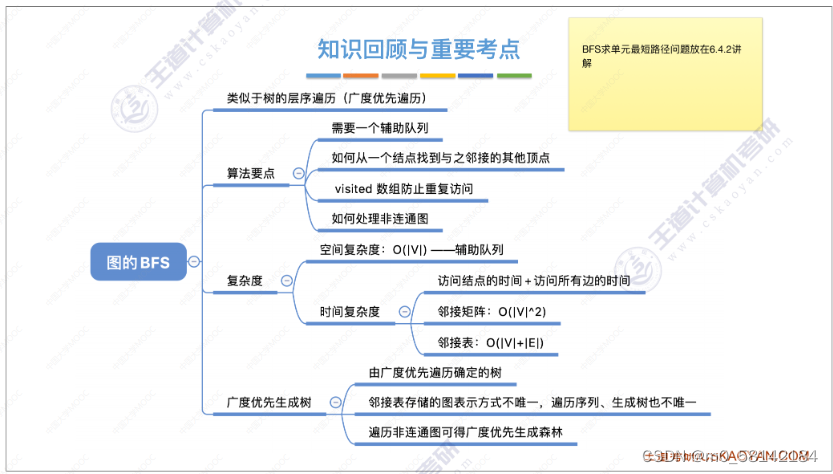
- 思想
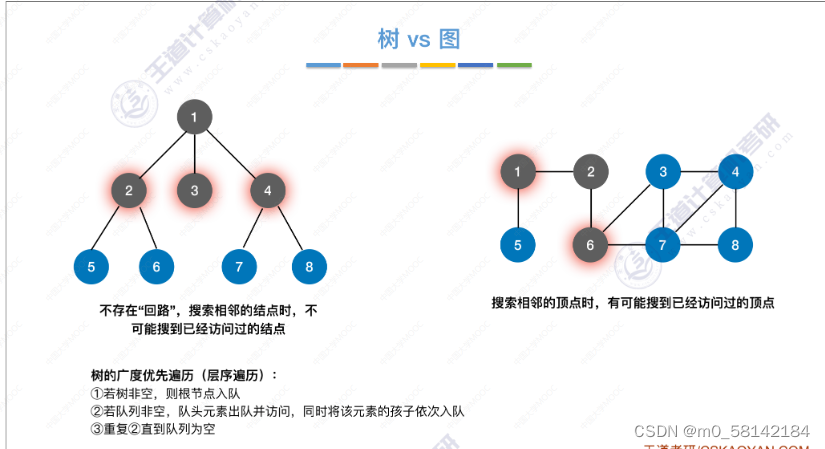
思想:与树的广度优先遍历相似。需要注意的是,在图搜索相邻的顶点时,有可能搜索到自己已经访问过的顶点。
- 代码实现
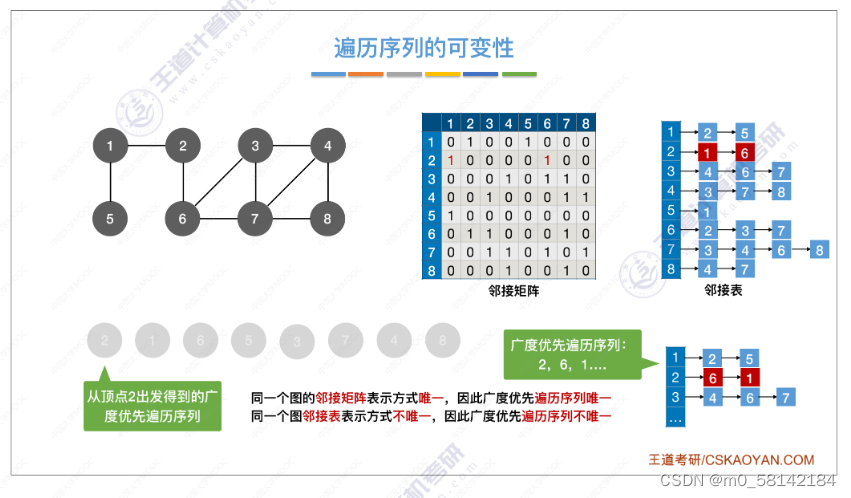
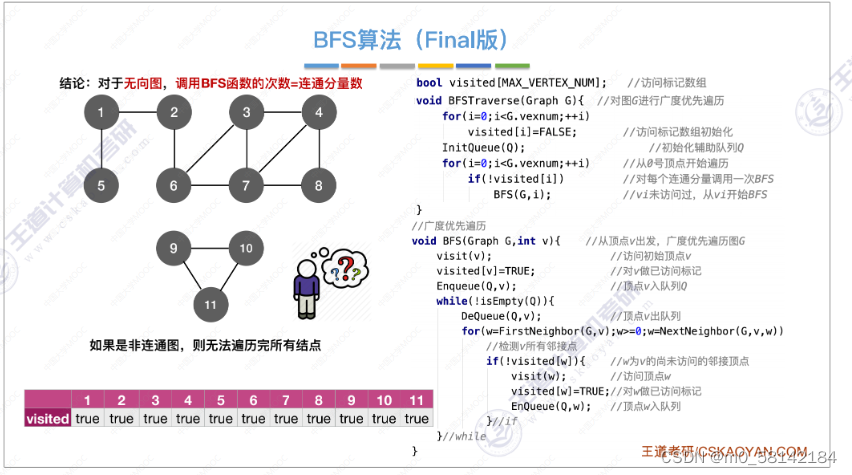
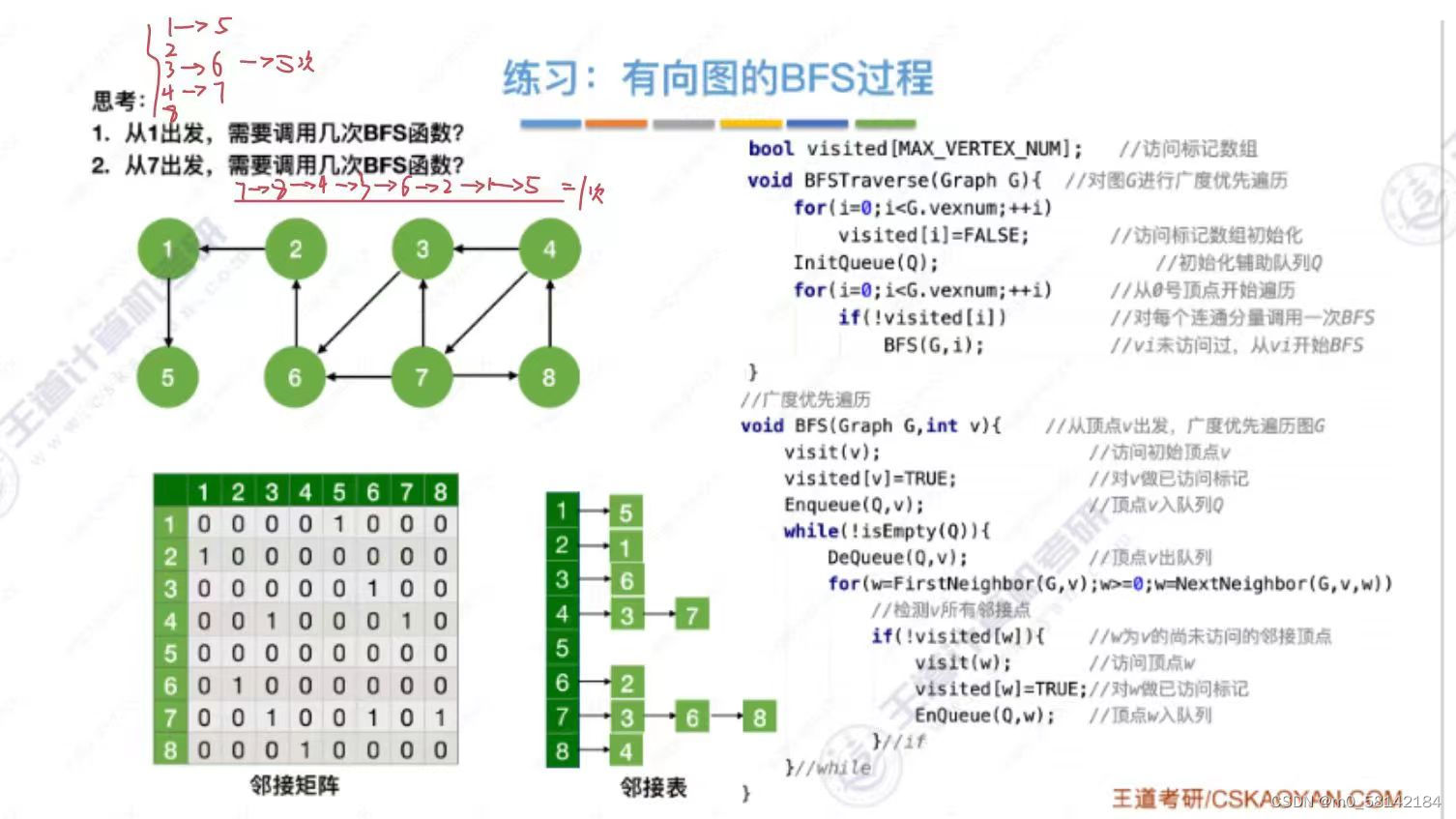
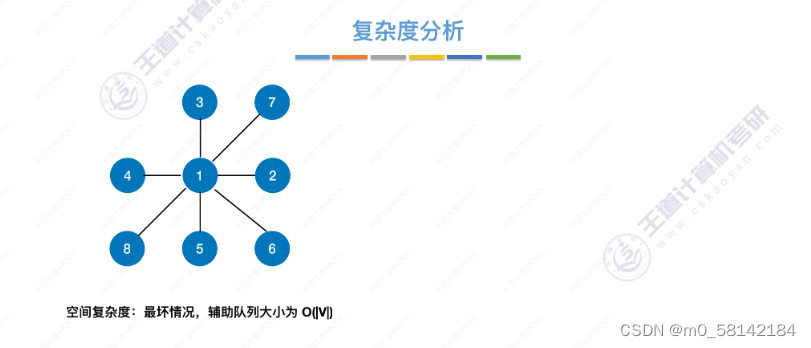
- 复杂度分析
-

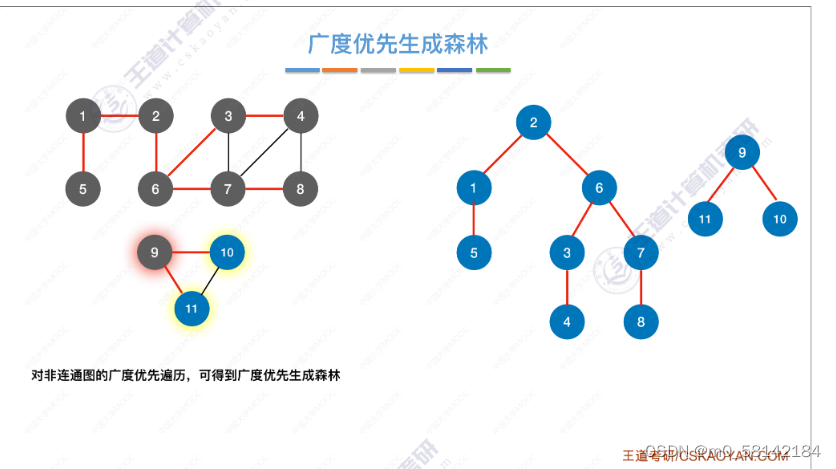
- 广度优先生成树

《2》深度优先遍历(DFS)
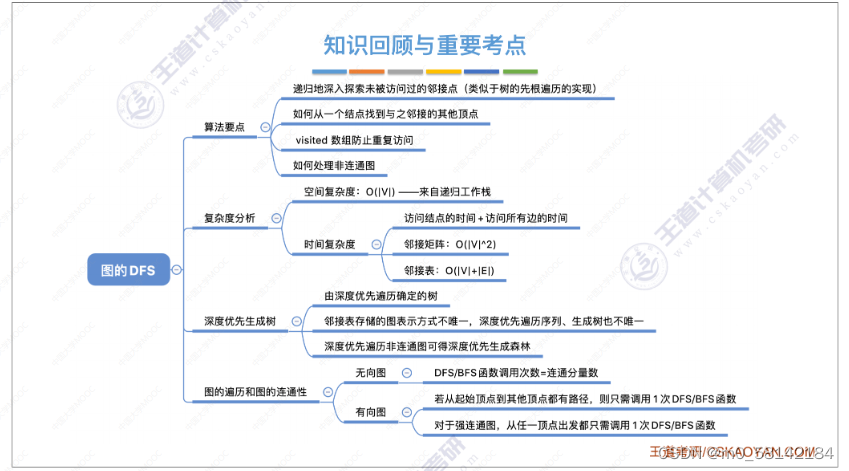
- 思想
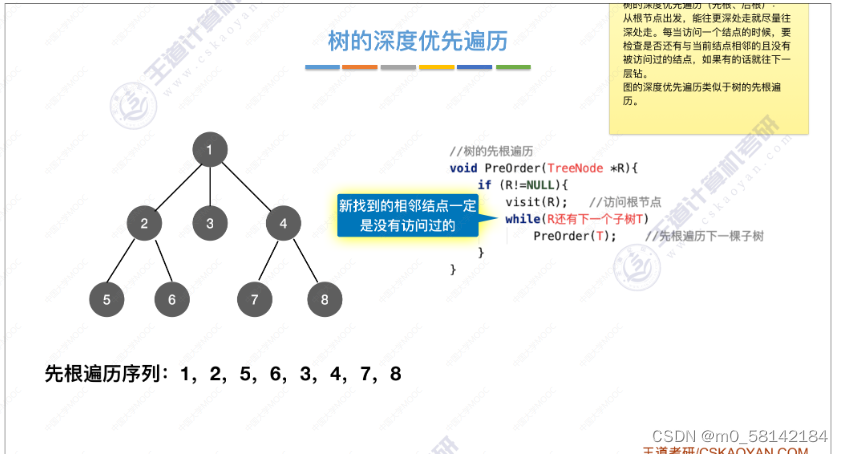
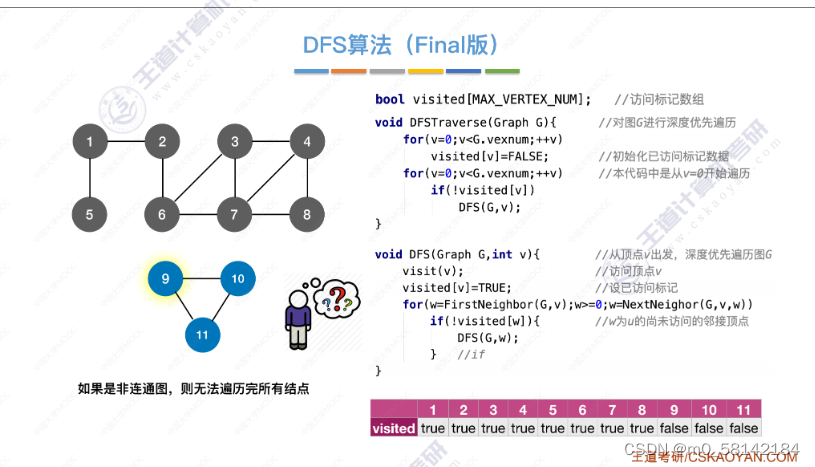
图的深度优先遍历的思想同树的先序遍历,只不过图的深度优先遍历可能会遍历到已经访问的顶点,所以用标记记录那些已经被访问过了。
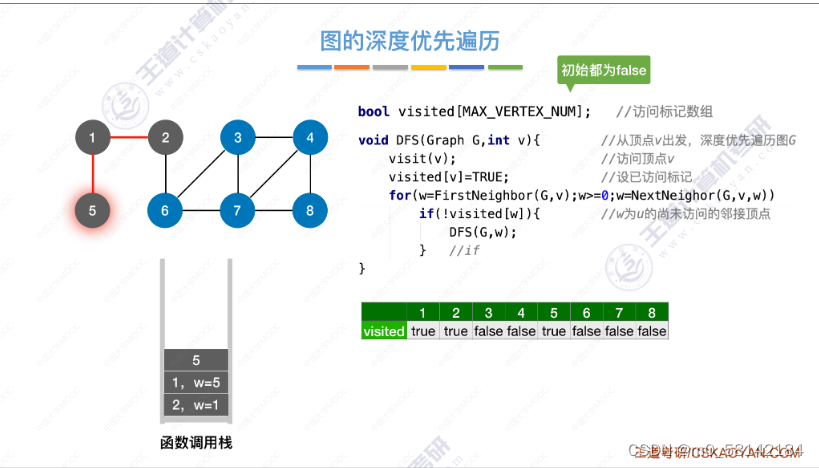
从2顶点出发的深度遍历序列: 2 1 5 6 3 4 7 8
- 代码实现
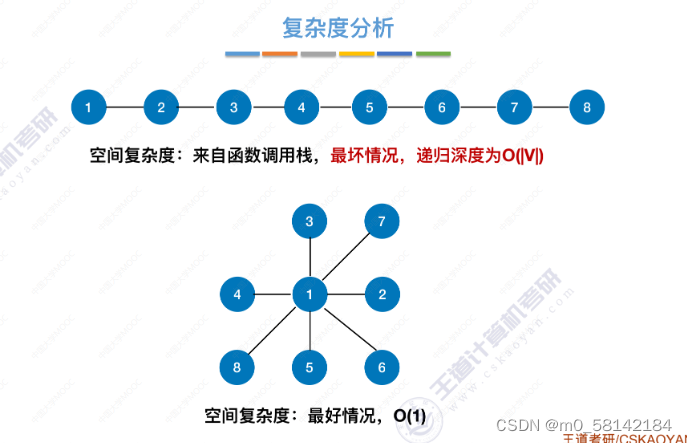
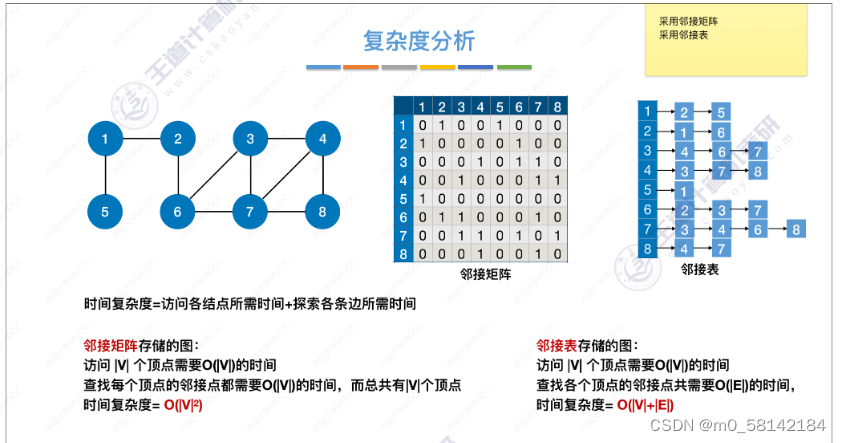
- 复杂度分析
- 手算深度优先遍历序列

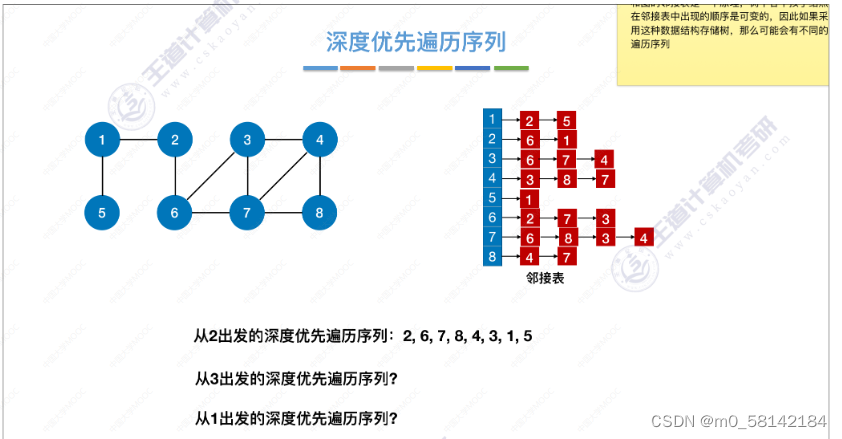
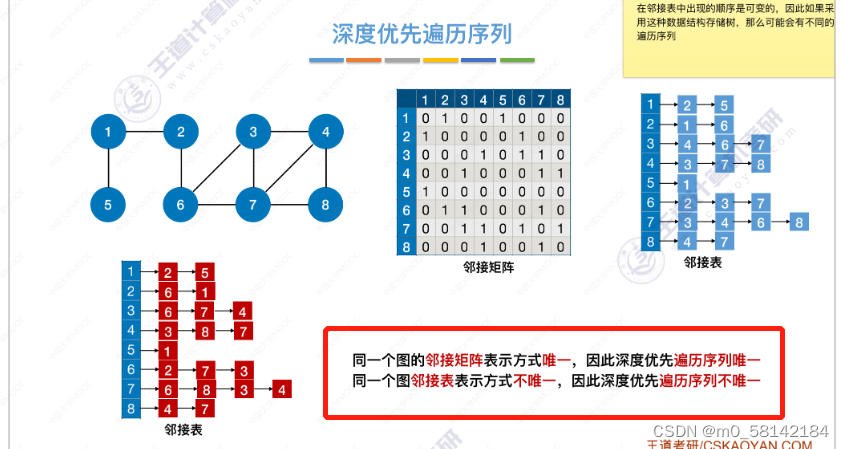
对于不同的存储方式,深度优先遍历序列不同,生成的树或森林也各不相同
- 图的遍历与图的连通性
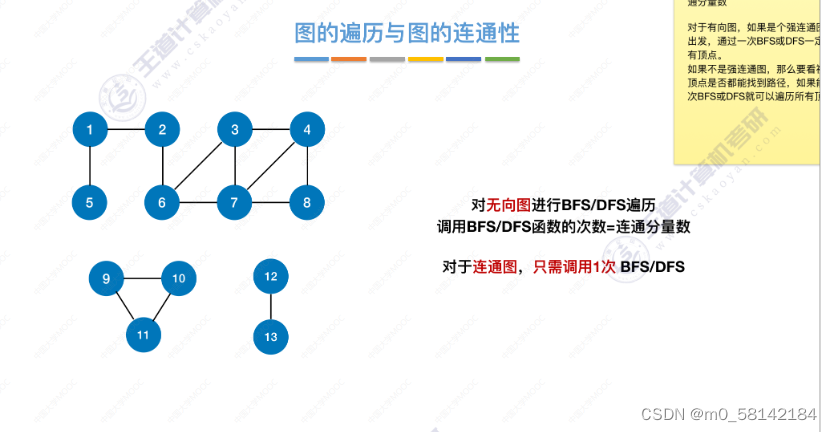
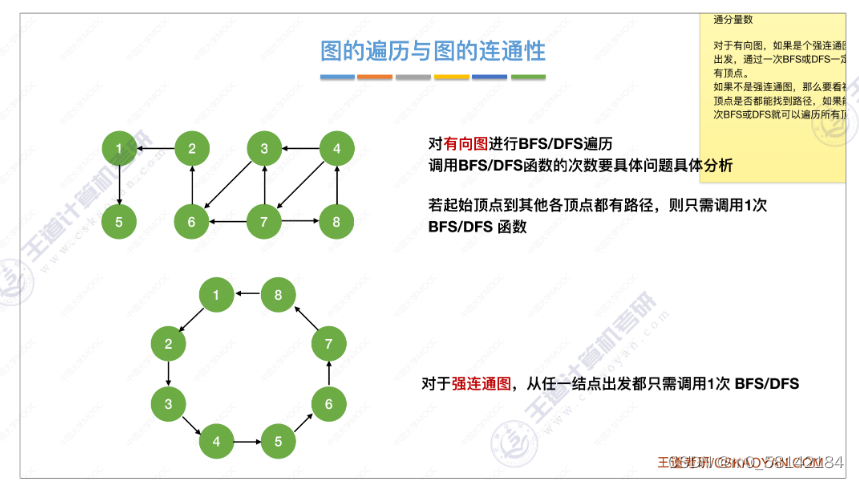
4.最小生成树
- 概念
1.最小生成树:
带权连通无向图,边的权值之和最小
2.最小生成树可能有多个,但边的权值之和总是唯一且最小的
3.最小生成树的边数=顶点数-1.砍掉一条则不连通,增加一条边则会出现回路
4.如果一个连通图本身就是一颗树,则其最小生成树就是它本身
5.只有连通图才有生成树,非连通图只有生成森林
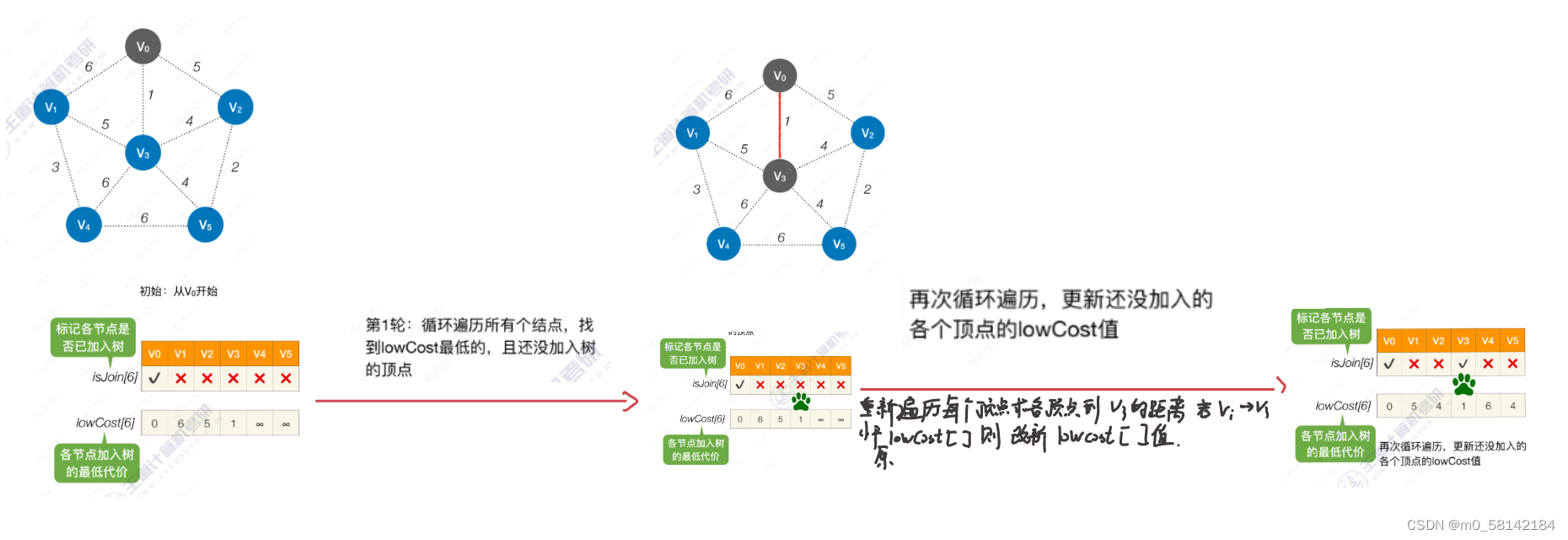
- 算法

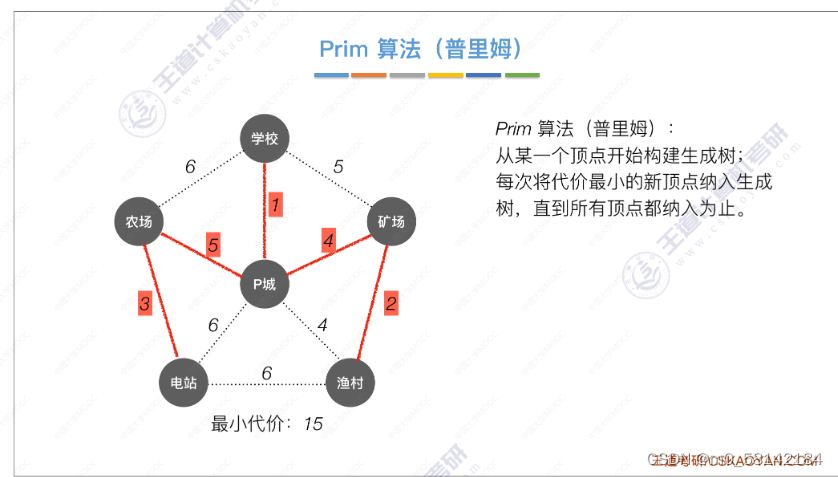
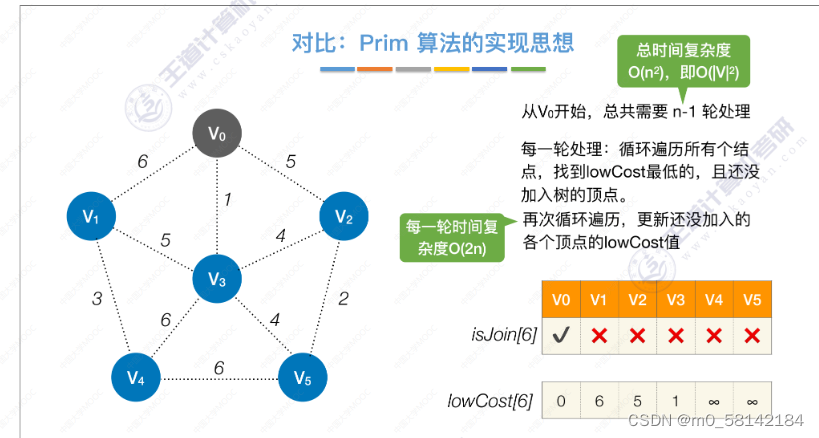
《1》Prim算法(普里姆)
从顶点农场开始
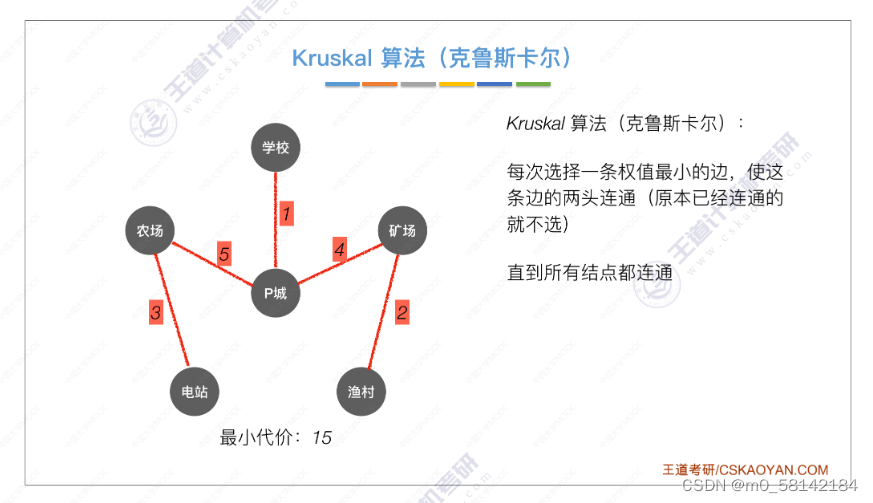
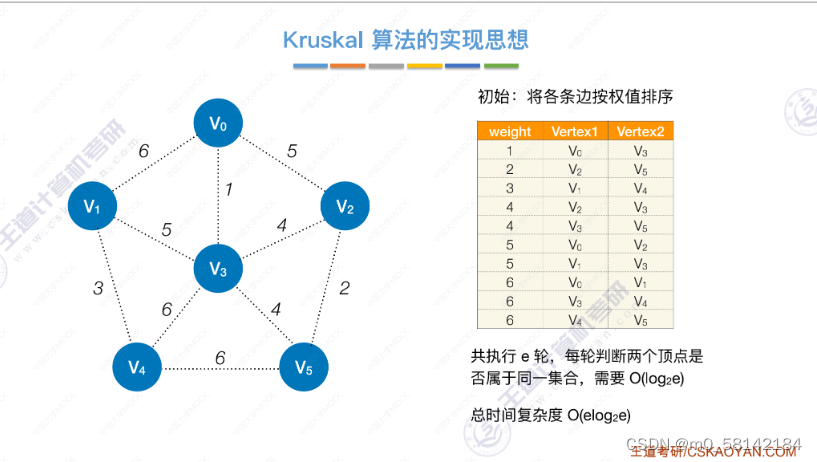
《2》 Kruskal算法(克鲁斯卡尔)
5.最短路径
《1》单源最短路径
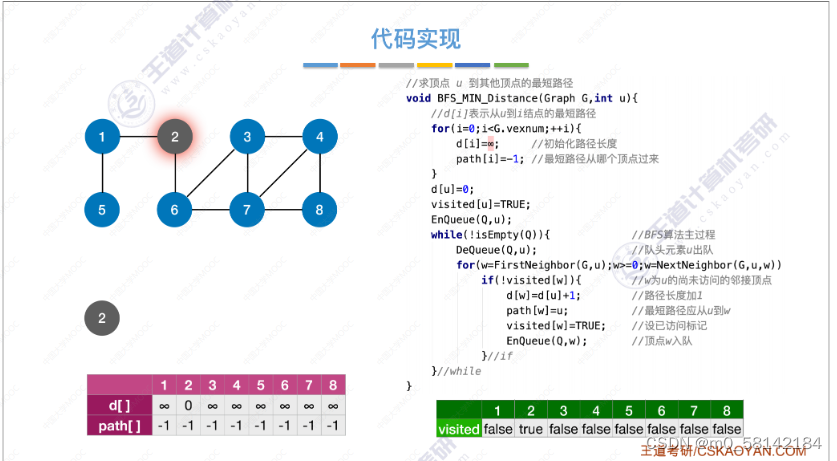
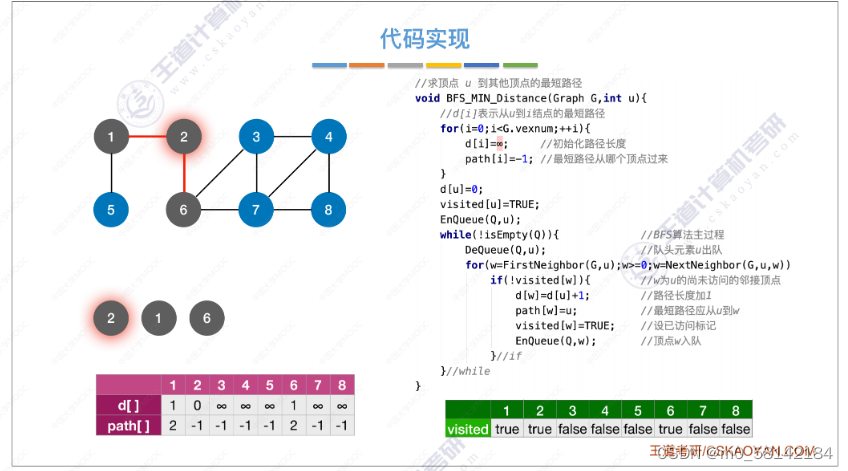
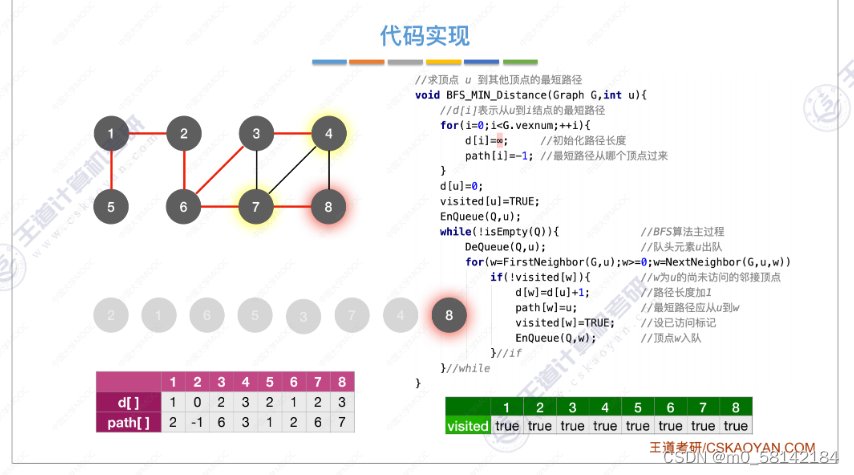
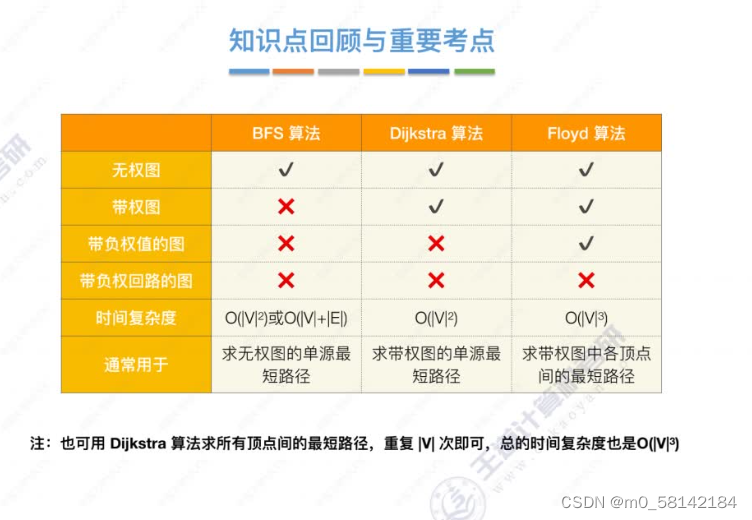
《a》BFS(无权图)
BFS算法求单源最短路径只适合于
无权图或所有边路径相同的图

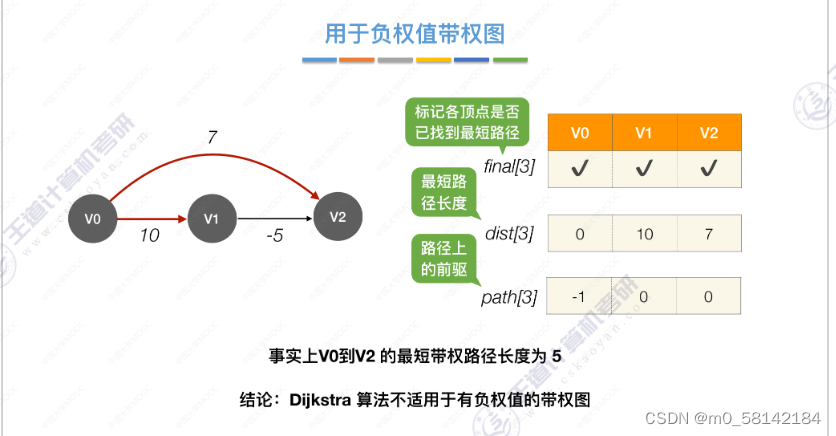
《b》Dijkstra算法(带权图,无权图)
Dijkstra算法可以处理有向图和无向图
Dijkstra算法不适用于有负权值的带权图
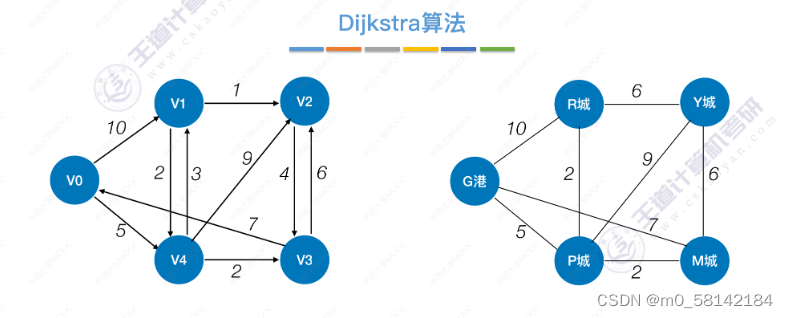
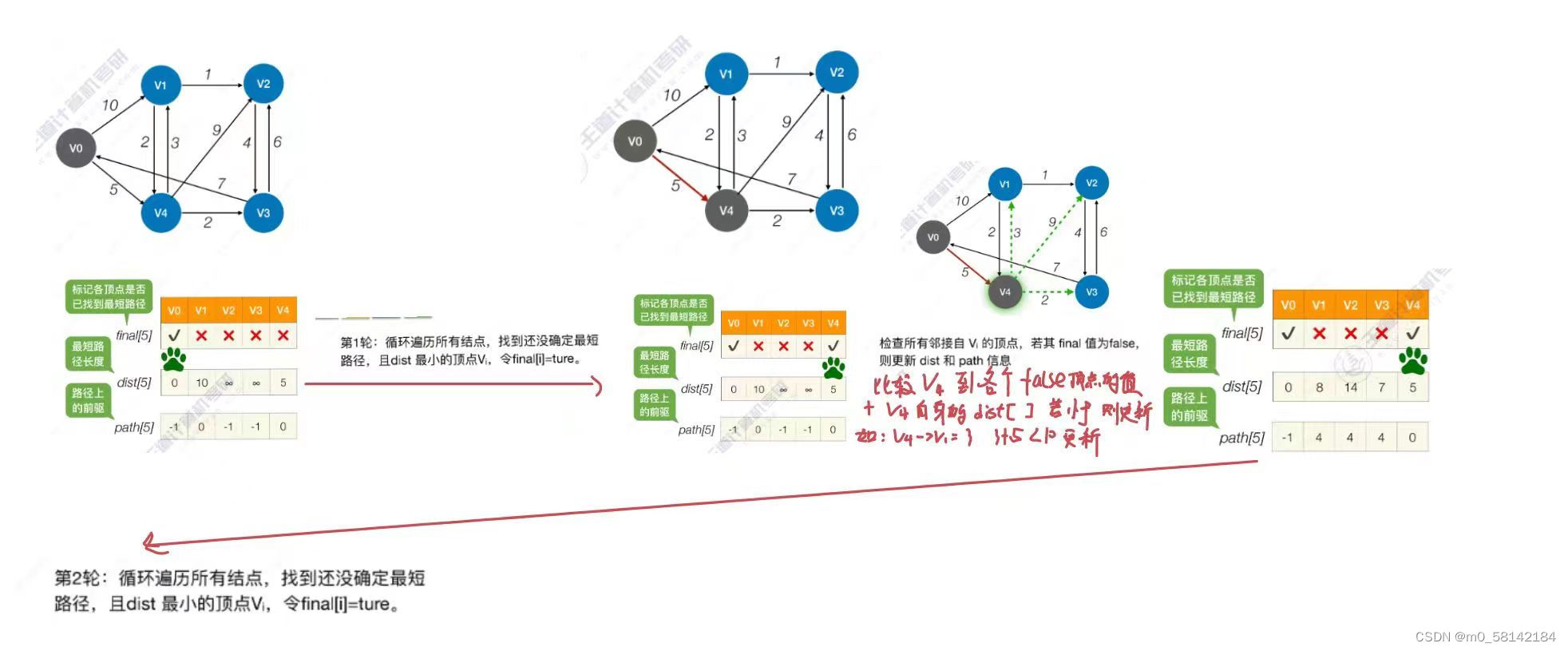
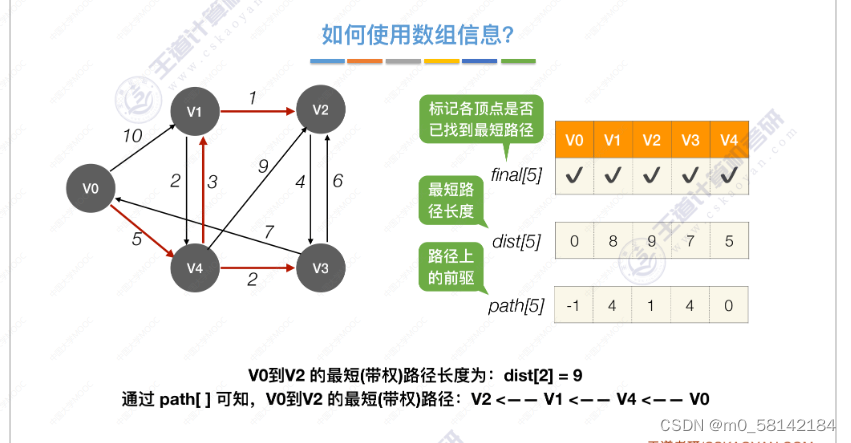
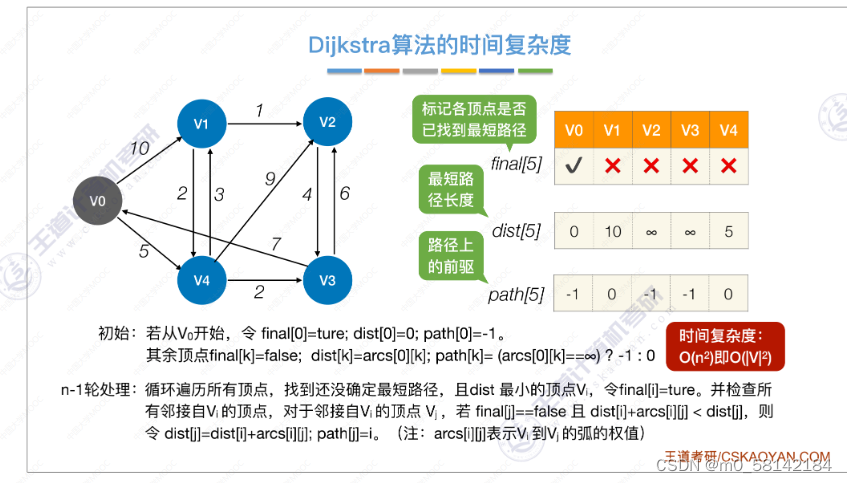
《2》各顶点间最短路径
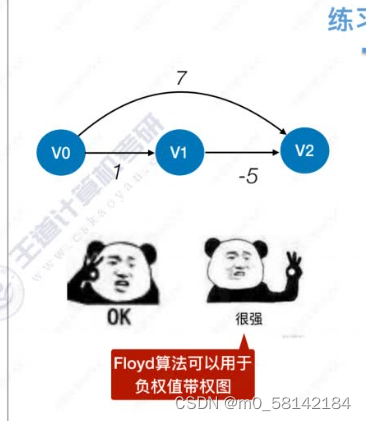
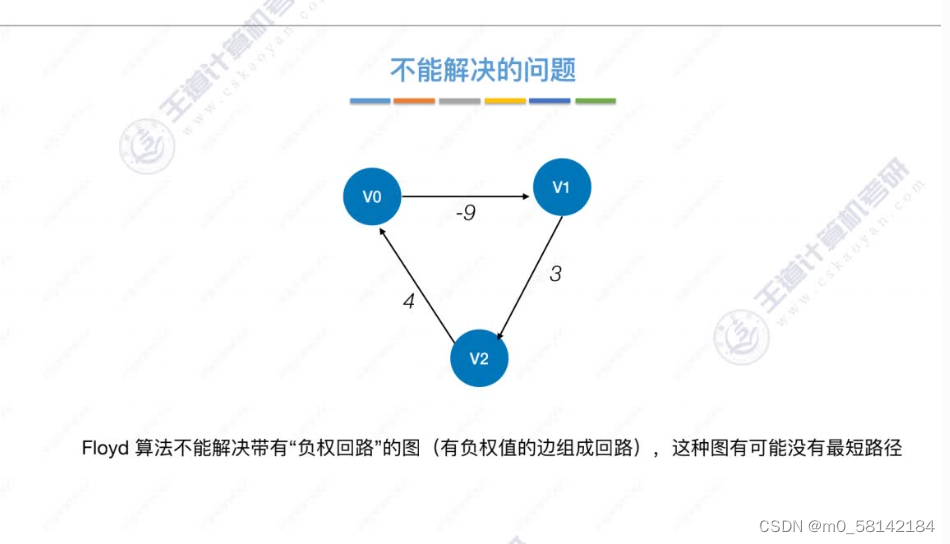
《a》Floyd算法(带权图,无权图)
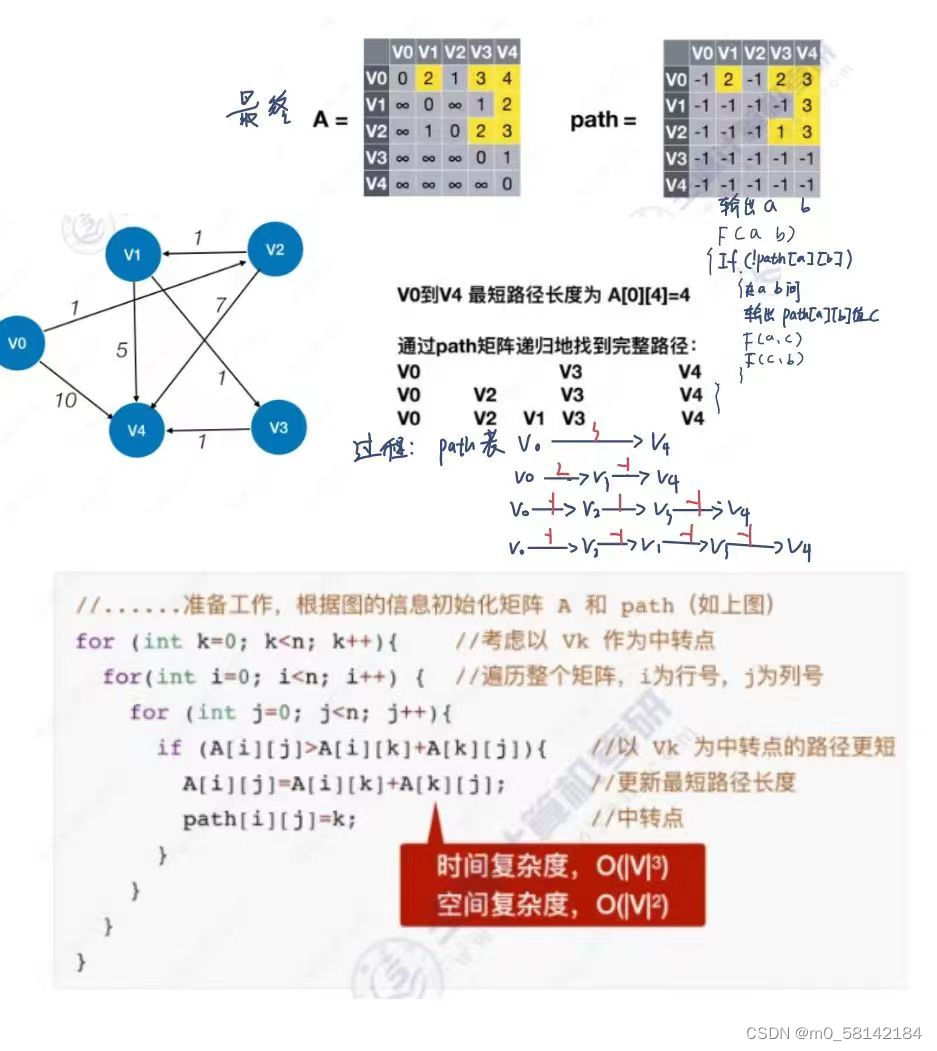
1. 手算
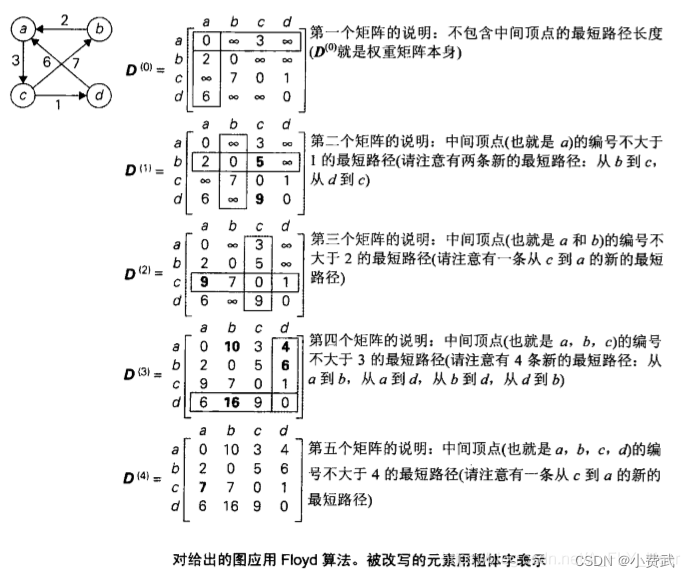

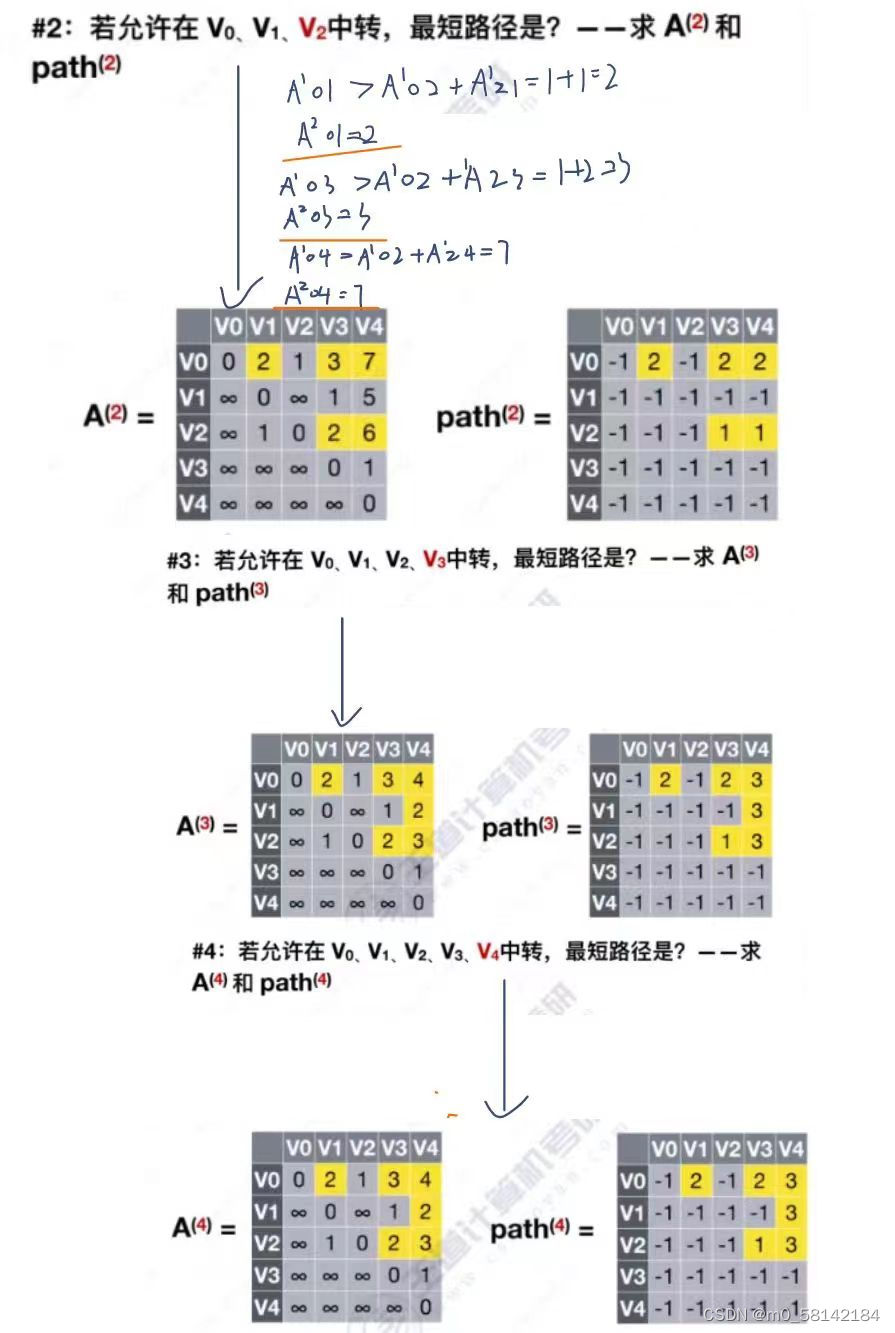
2.计算过程
Floyd算法思想:动态规划思想,将问题的求解分为多个阶段。每个阶段呈现递进关系。

// 输出最短路径
void getPath(int u, int v, int path[][maxSize], int A[][maxSize])
{
if (A[u][v] == INF)//没有路径
cout << "NO Road";
else
{
if (path[u][v] == -1)
cout << "<" << u << "," << v << ">";
else
{
int mid = path[u][v];
getPath(u, mid, path, A);
getPath(mid, v, path, A);
}
}
}
void Floyd(MGraph g, int path[][maxSize], int A[][maxSize])
{
int i, j, k;
// 初始化 path矩阵表和A矩阵表
for (i = 0; i < g.n; ++i)
for (j = 0; j < g.n; ++j)
{
path[i][j] = -1;
A[i][j] = g.edgeW[i][j];
}
// 递归
for (k = 0; k < g.n; ++k)
for (i = 0; i < g.n; ++i)
for (j = 0; j < g.n; ++j)
if (A[i][j] > A[i][k] + A[k][j])
{
A[i][j] = A[i][k] + A[k][j];
path[i][j] = k;
}
}

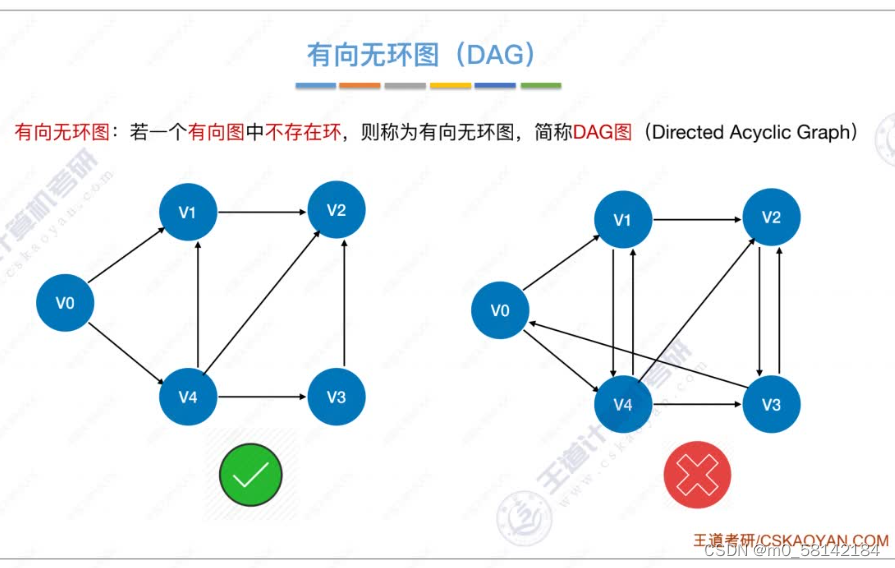
6.有向无环图(DAG)-描述表达式
表达式可以由二叉树表示,也可以由有向无环图表示。
有向无环图的优点在于,可以实现对相同表达式的共享,从而节省空间
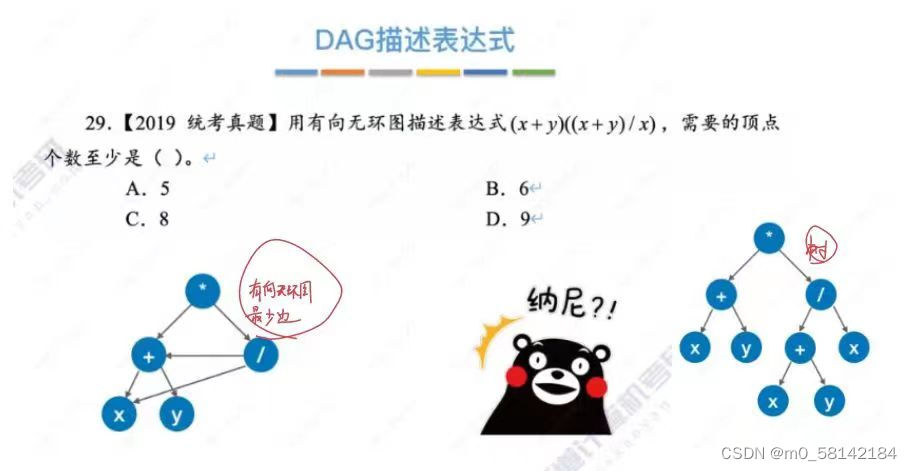
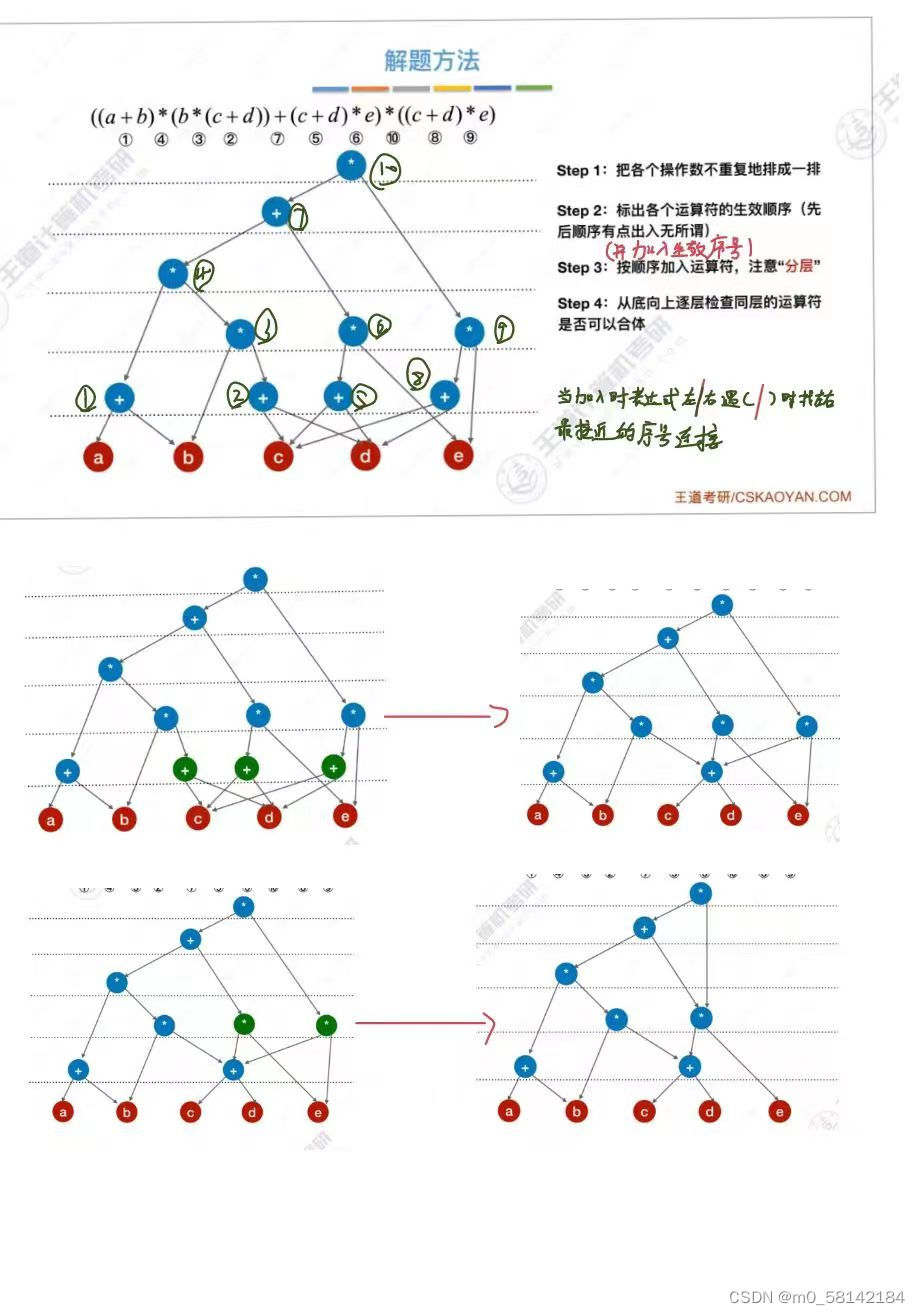
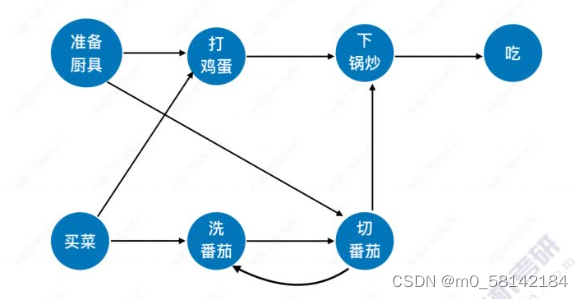
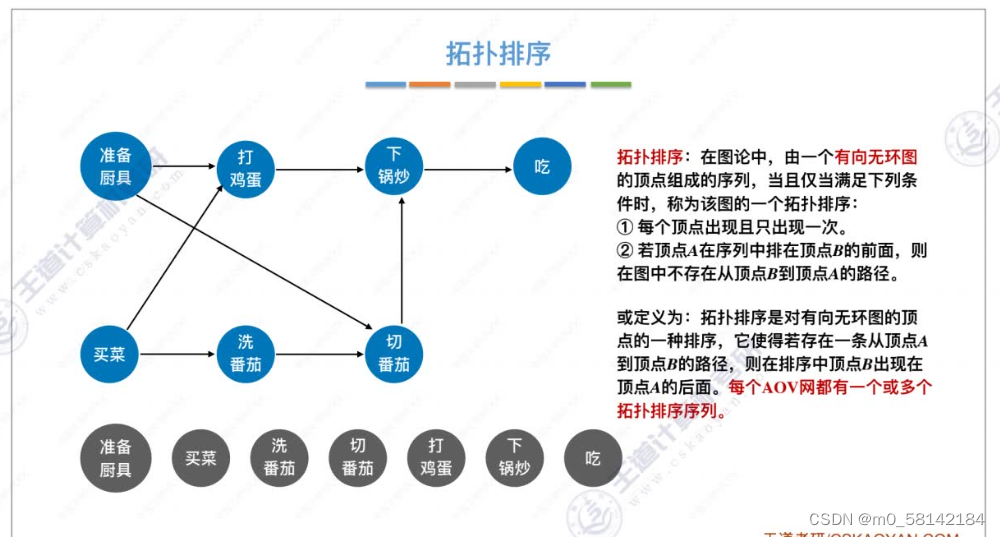
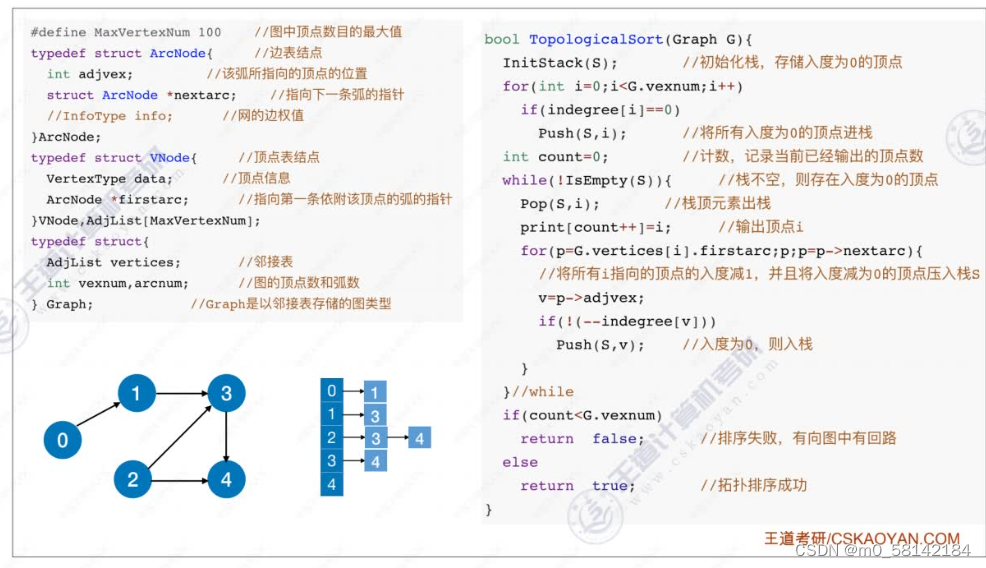
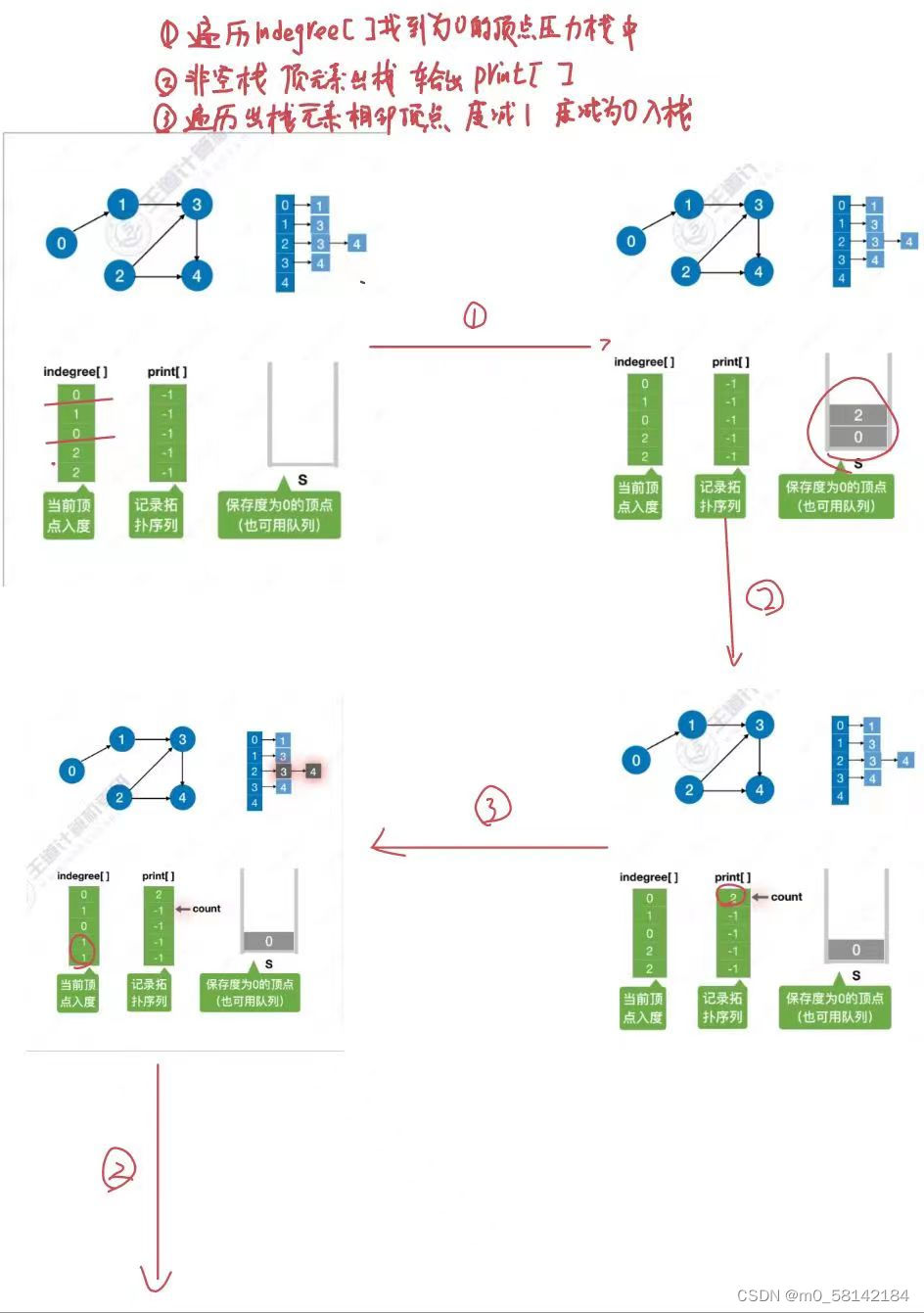
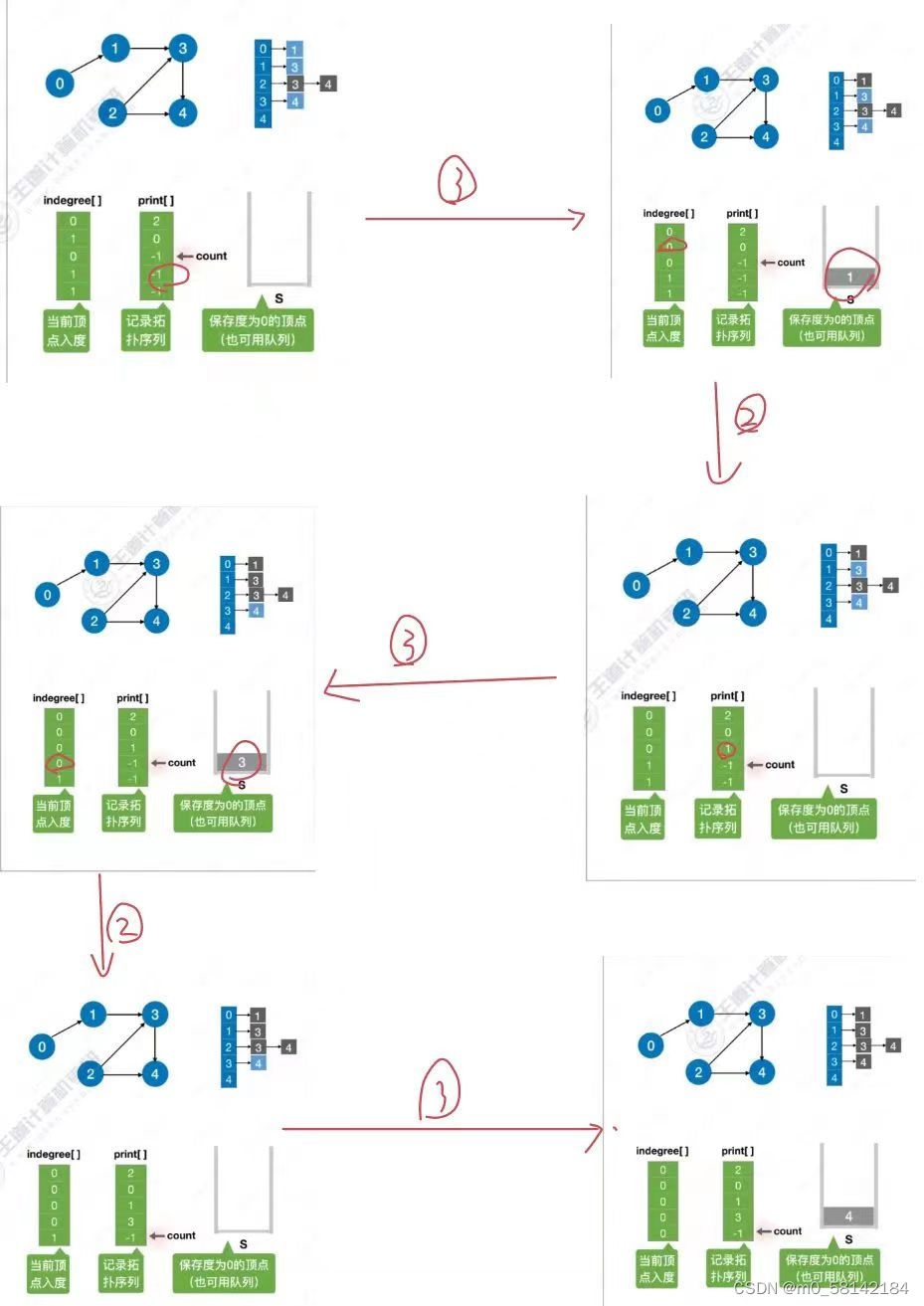
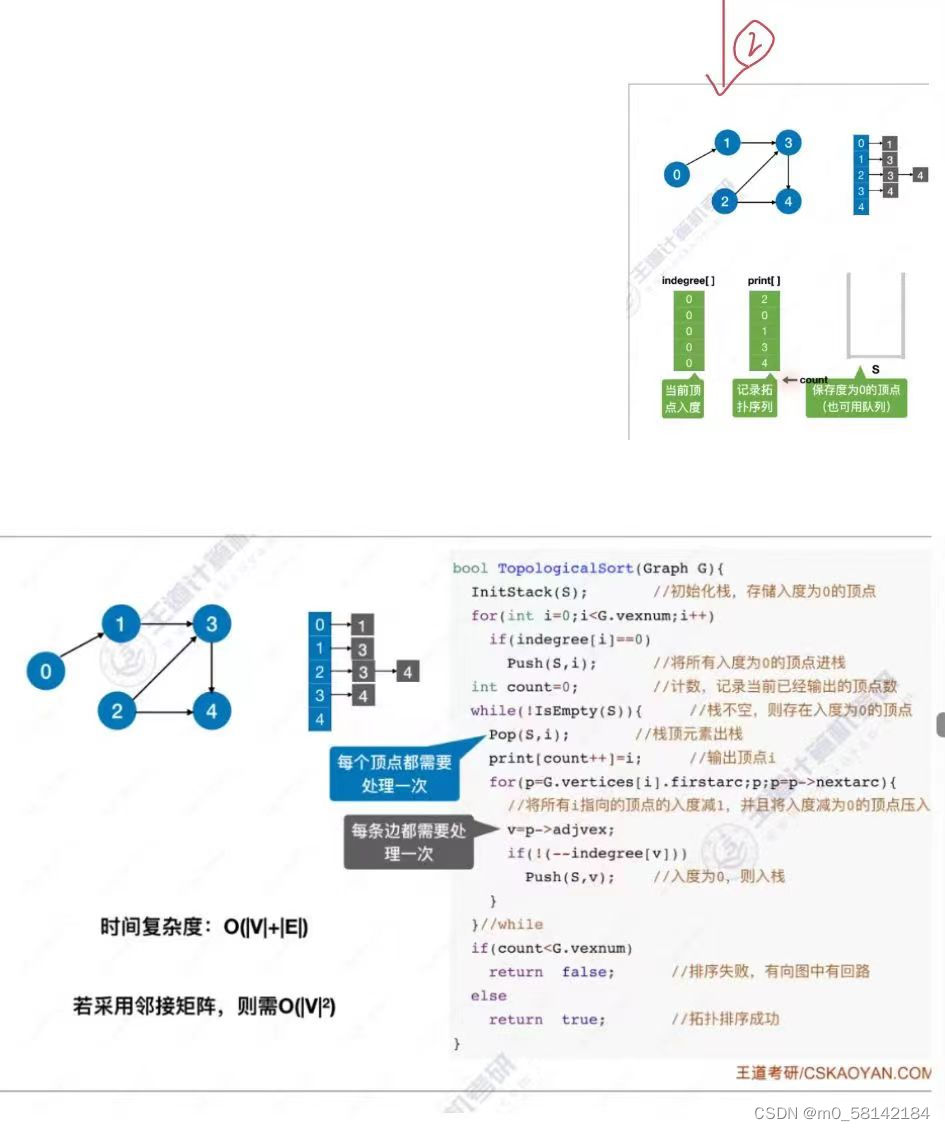
7.拓扑排序
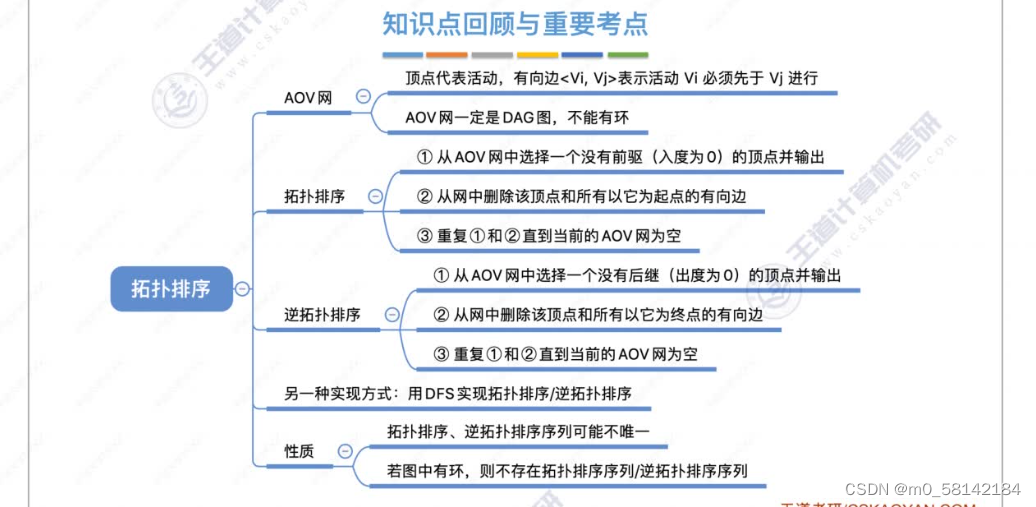
《1》正拓扑排序
AOV必须是 有向无循环图(DAG)
拓扑排序是找到做事的先后顺序

《2》逆拓扑排序
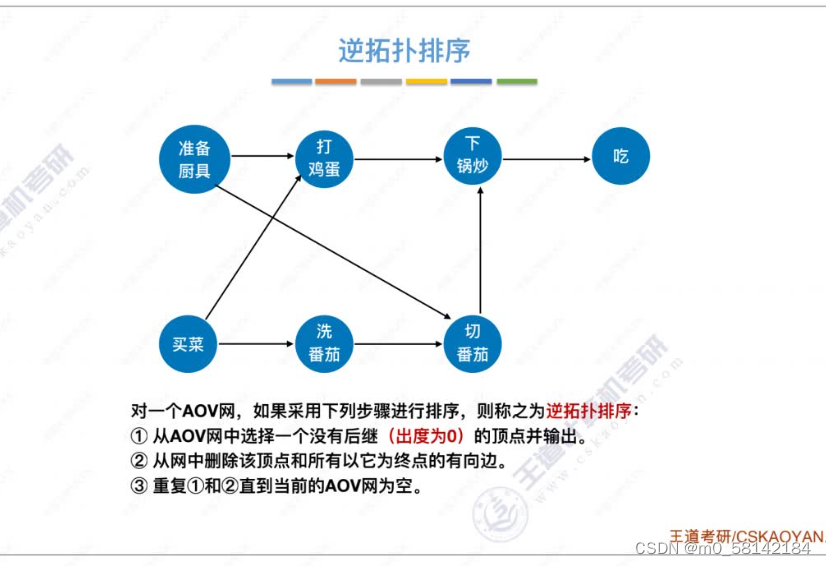

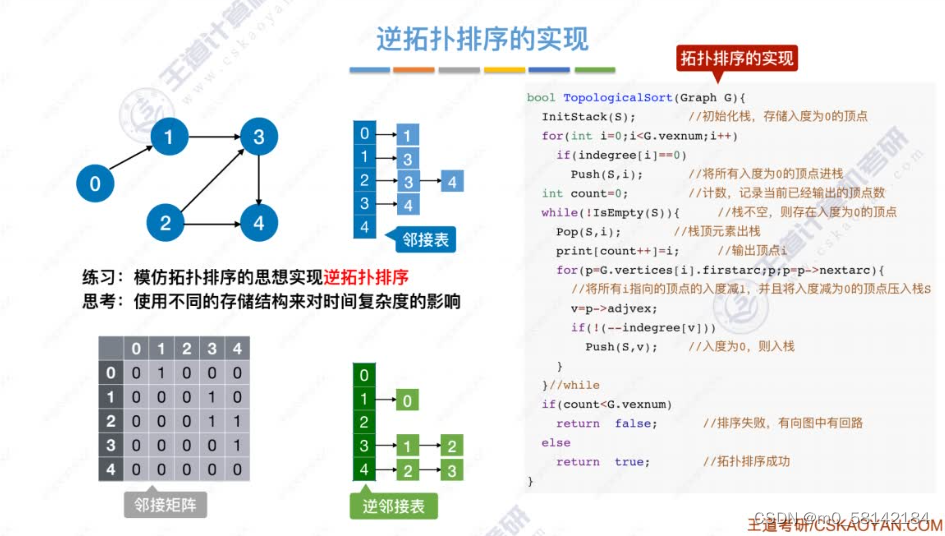
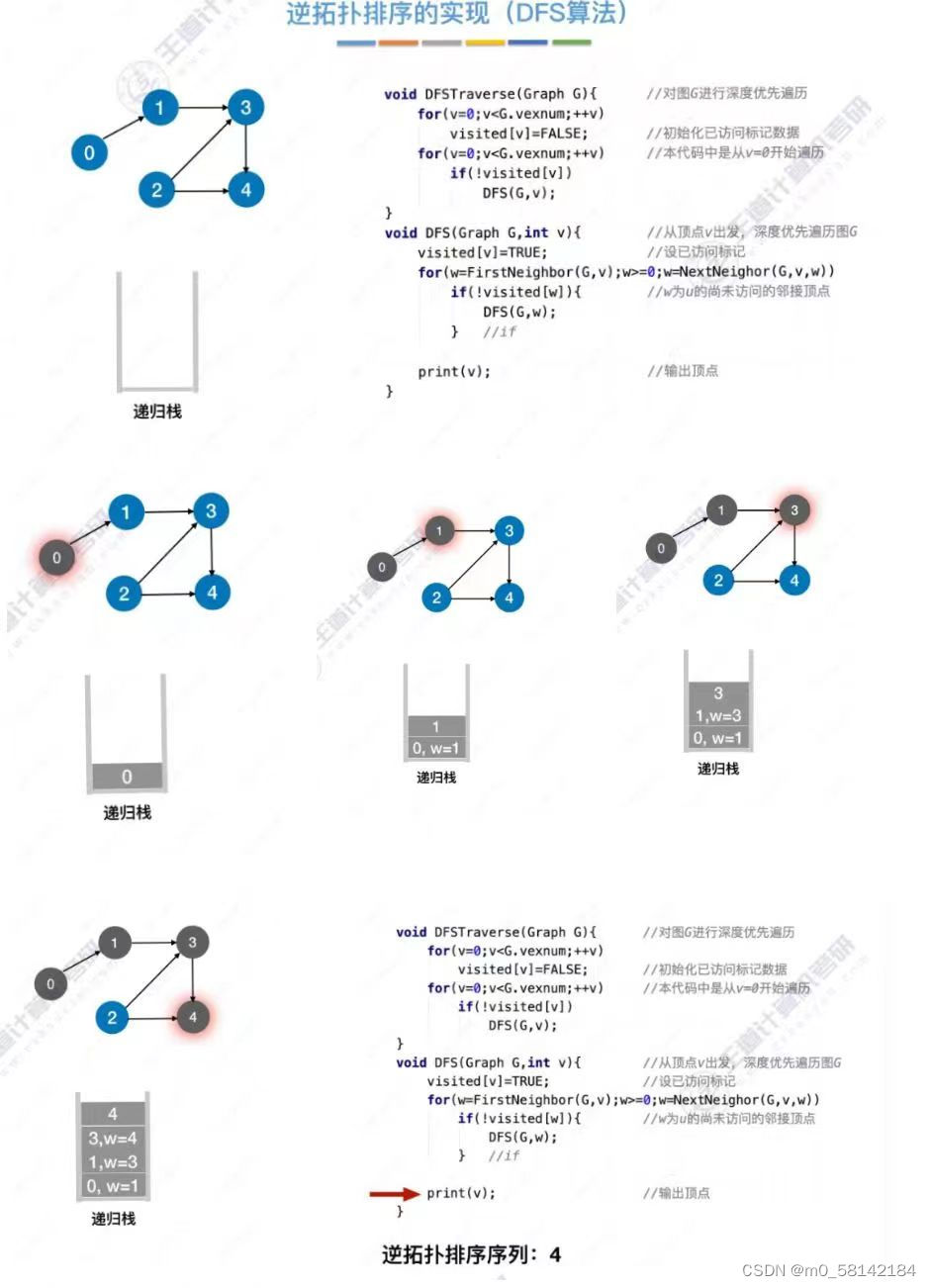

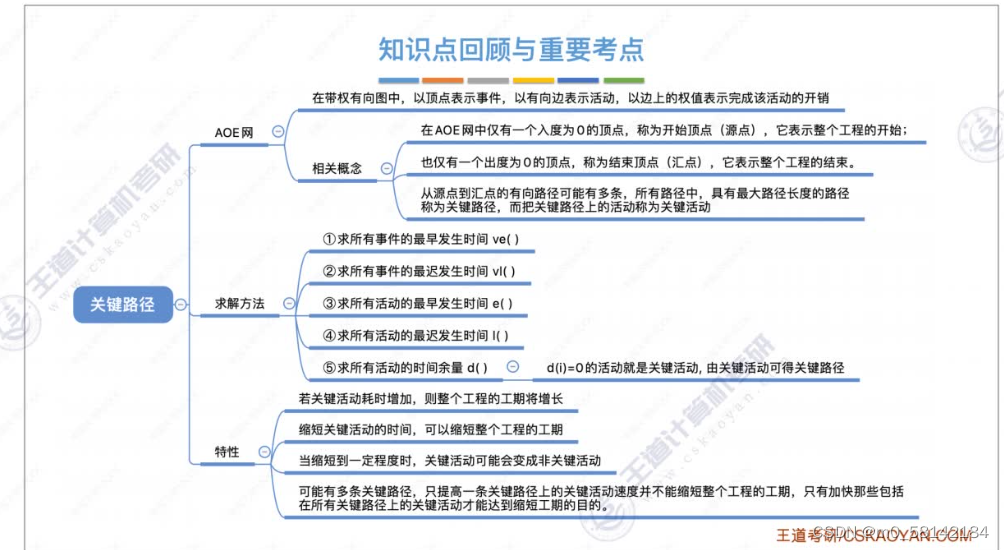
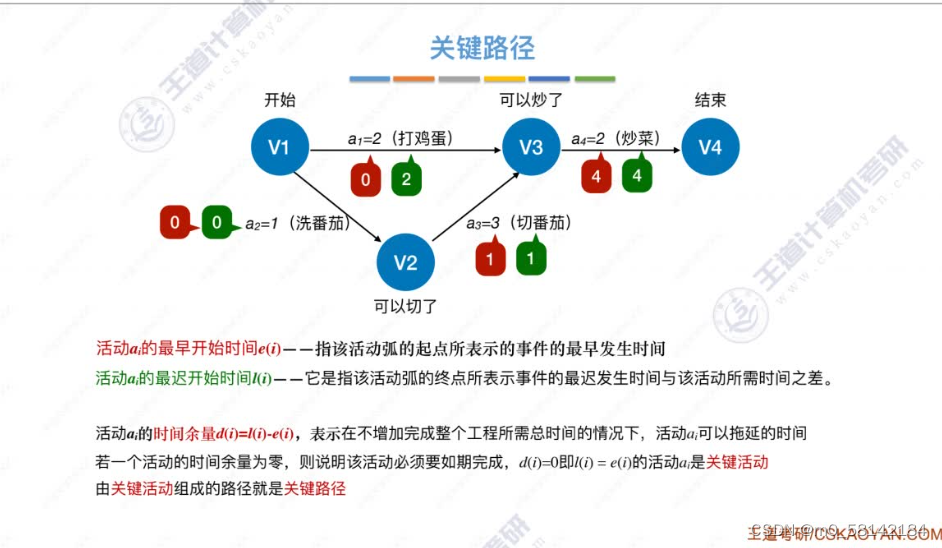
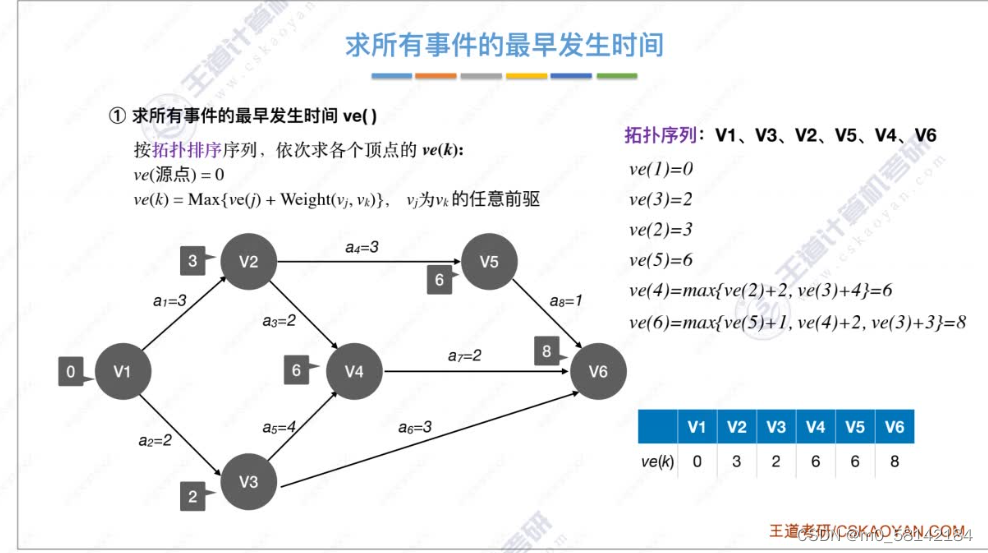
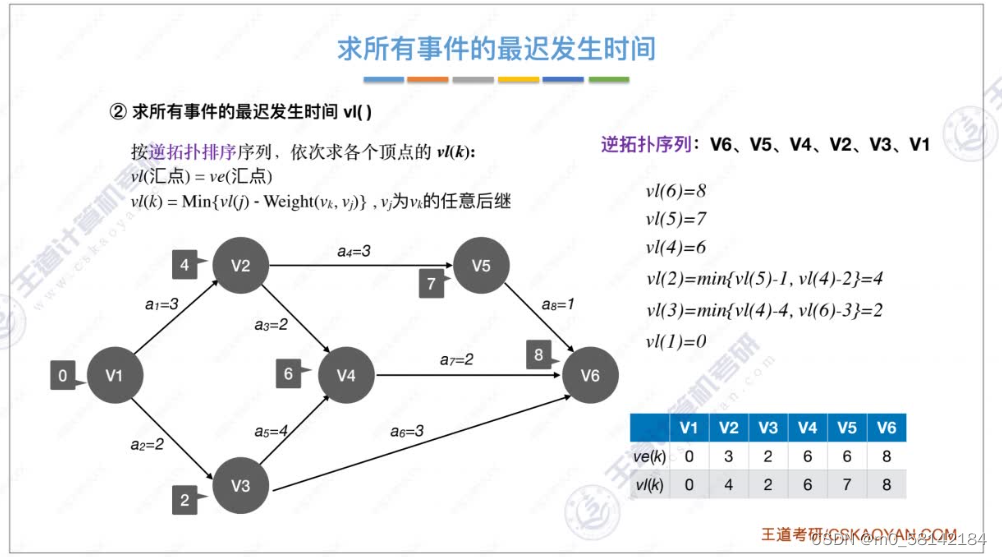
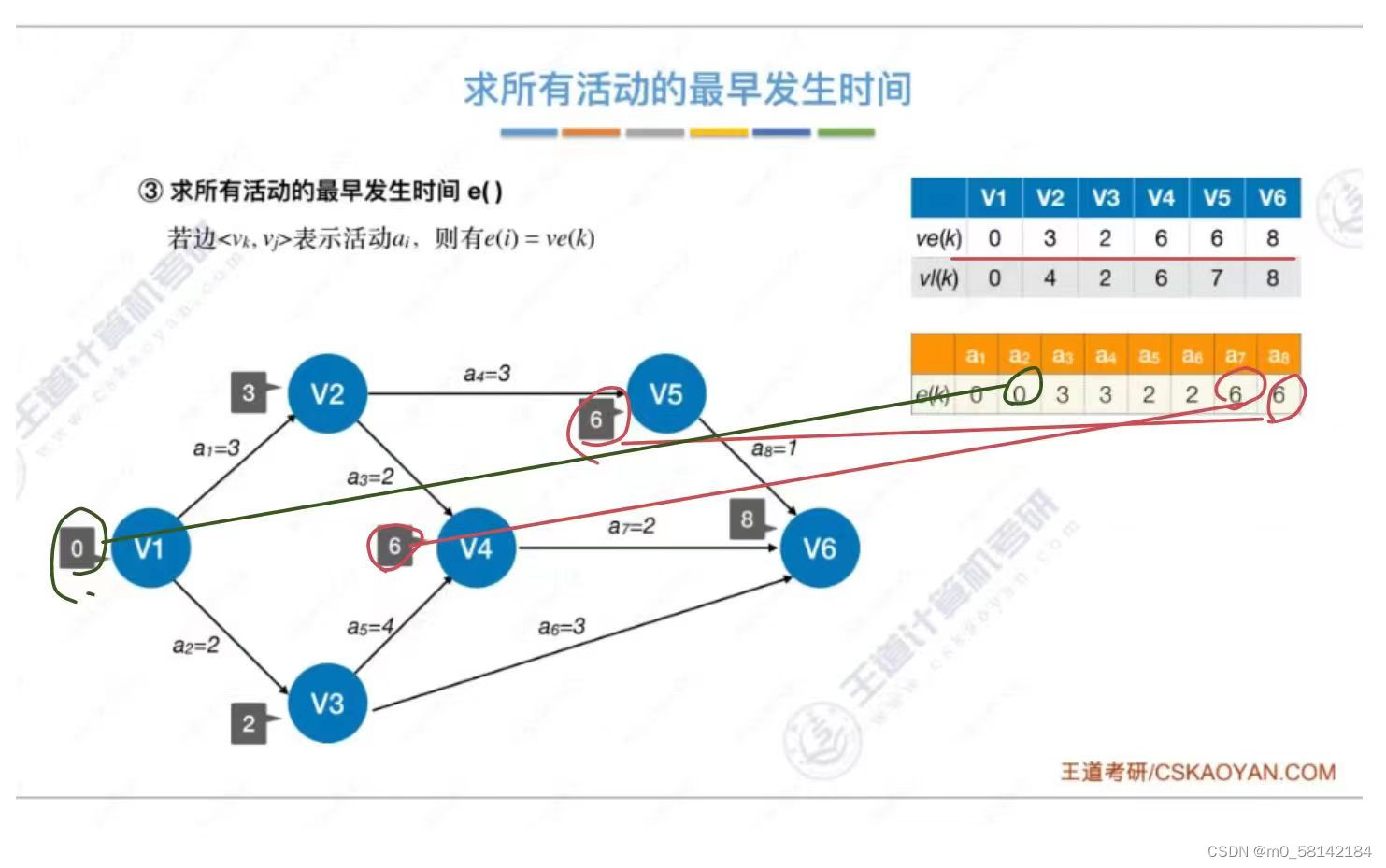
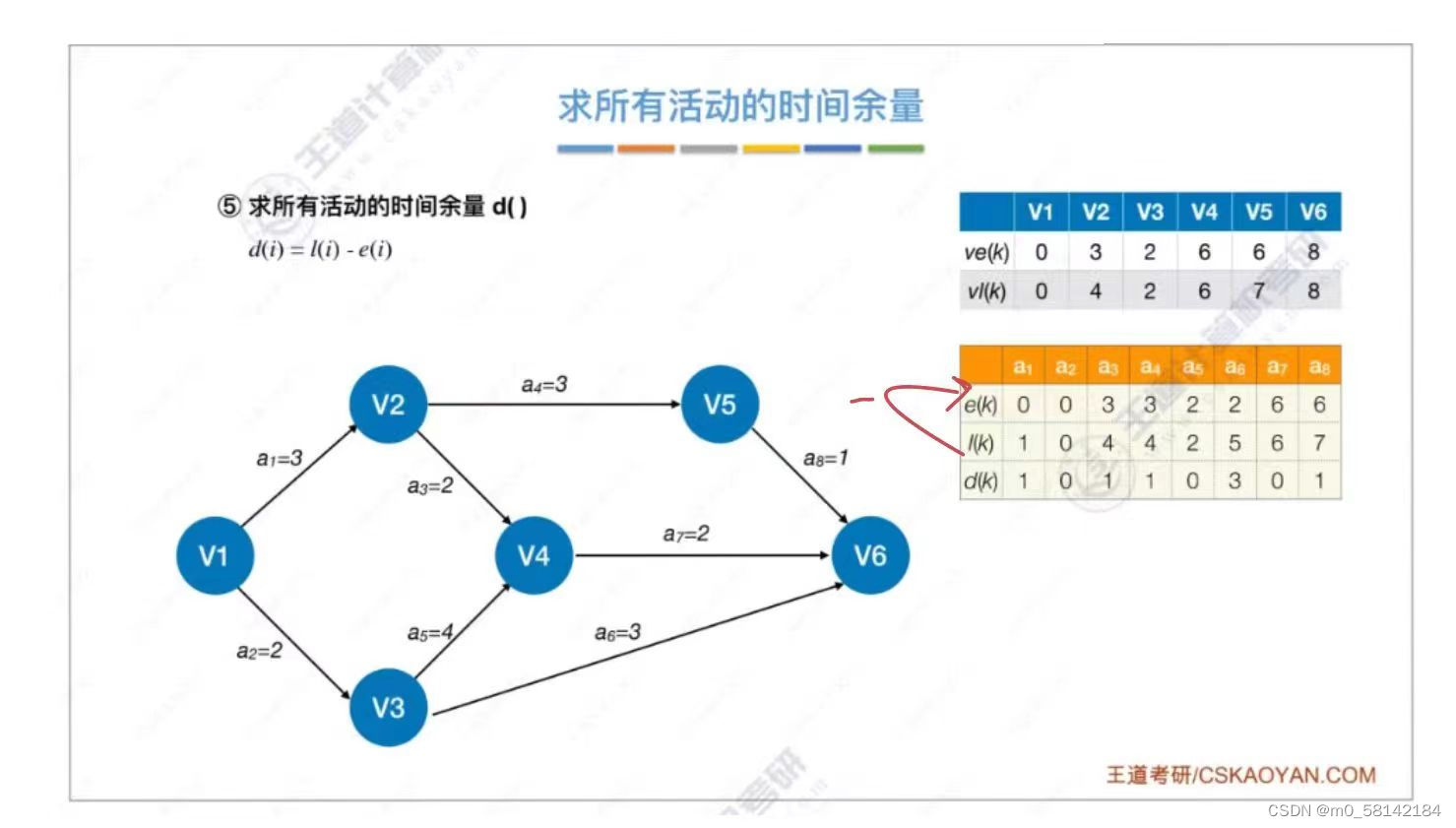
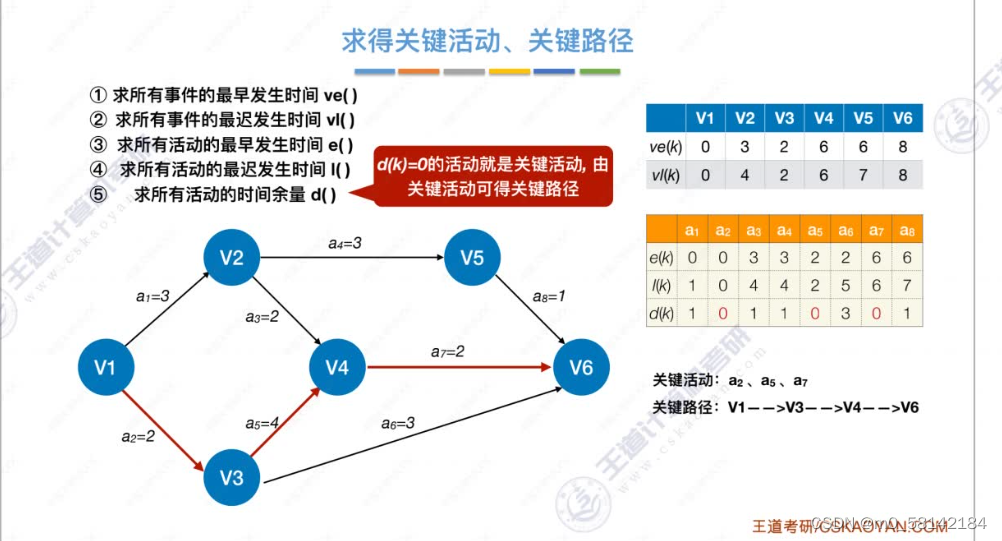
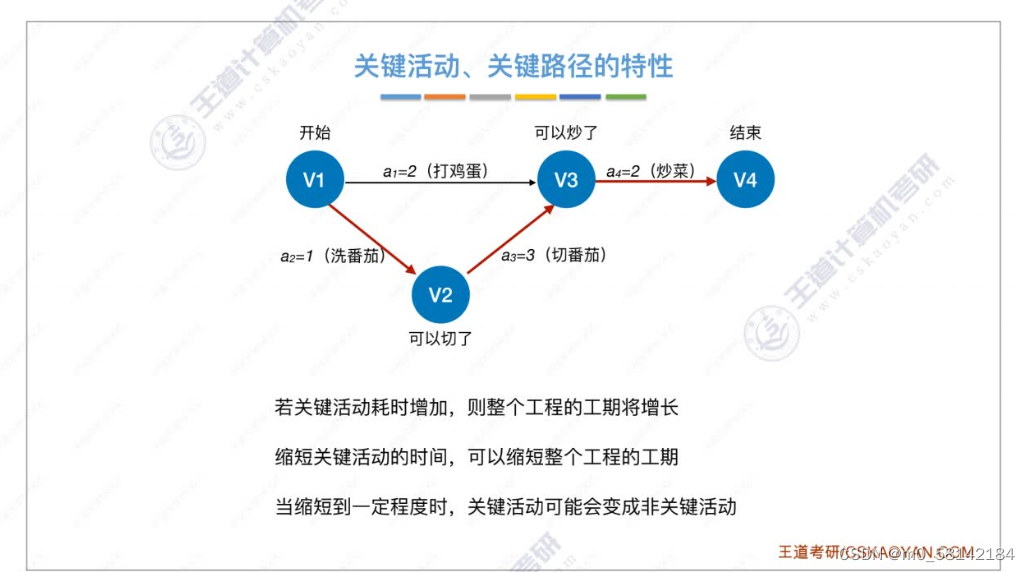
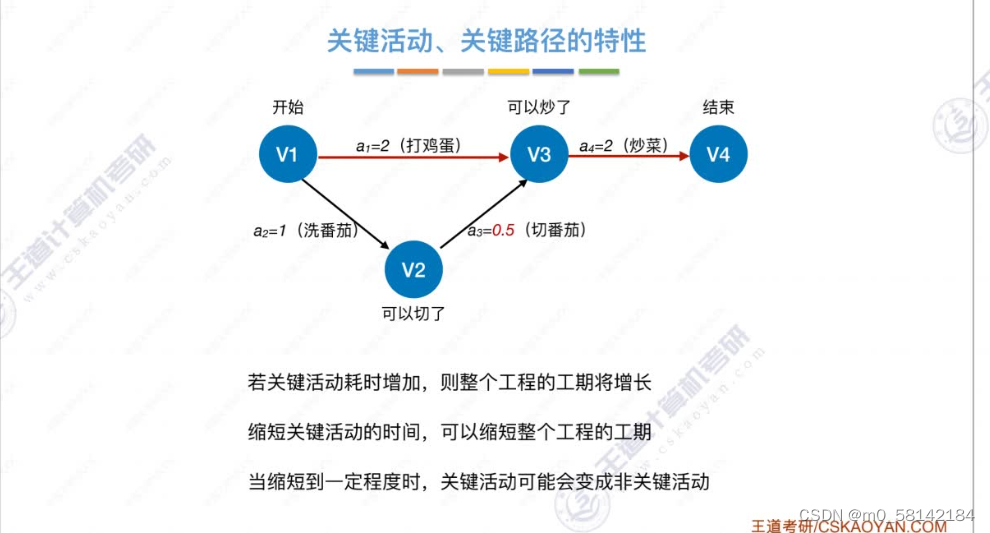
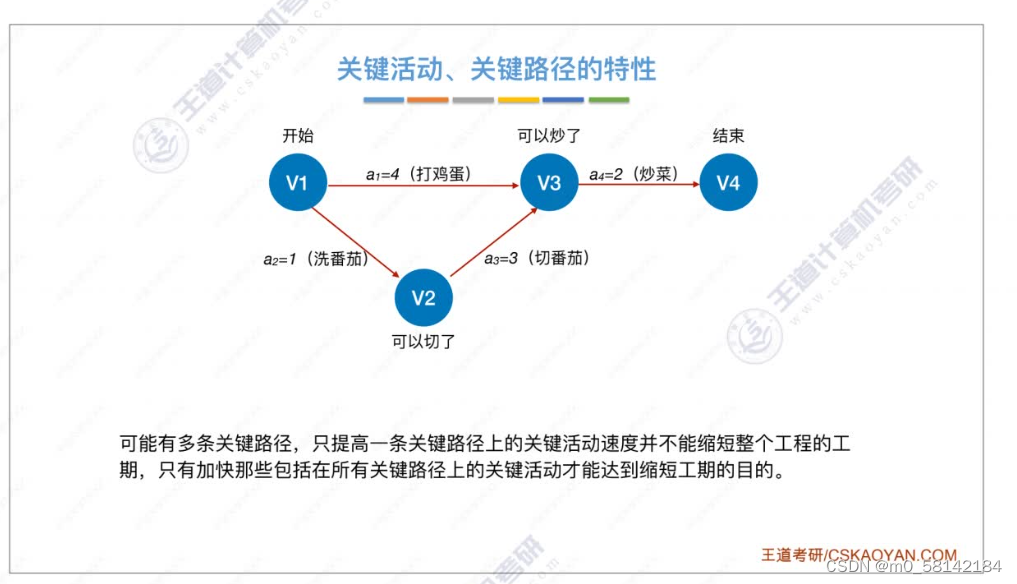
8.关键路径
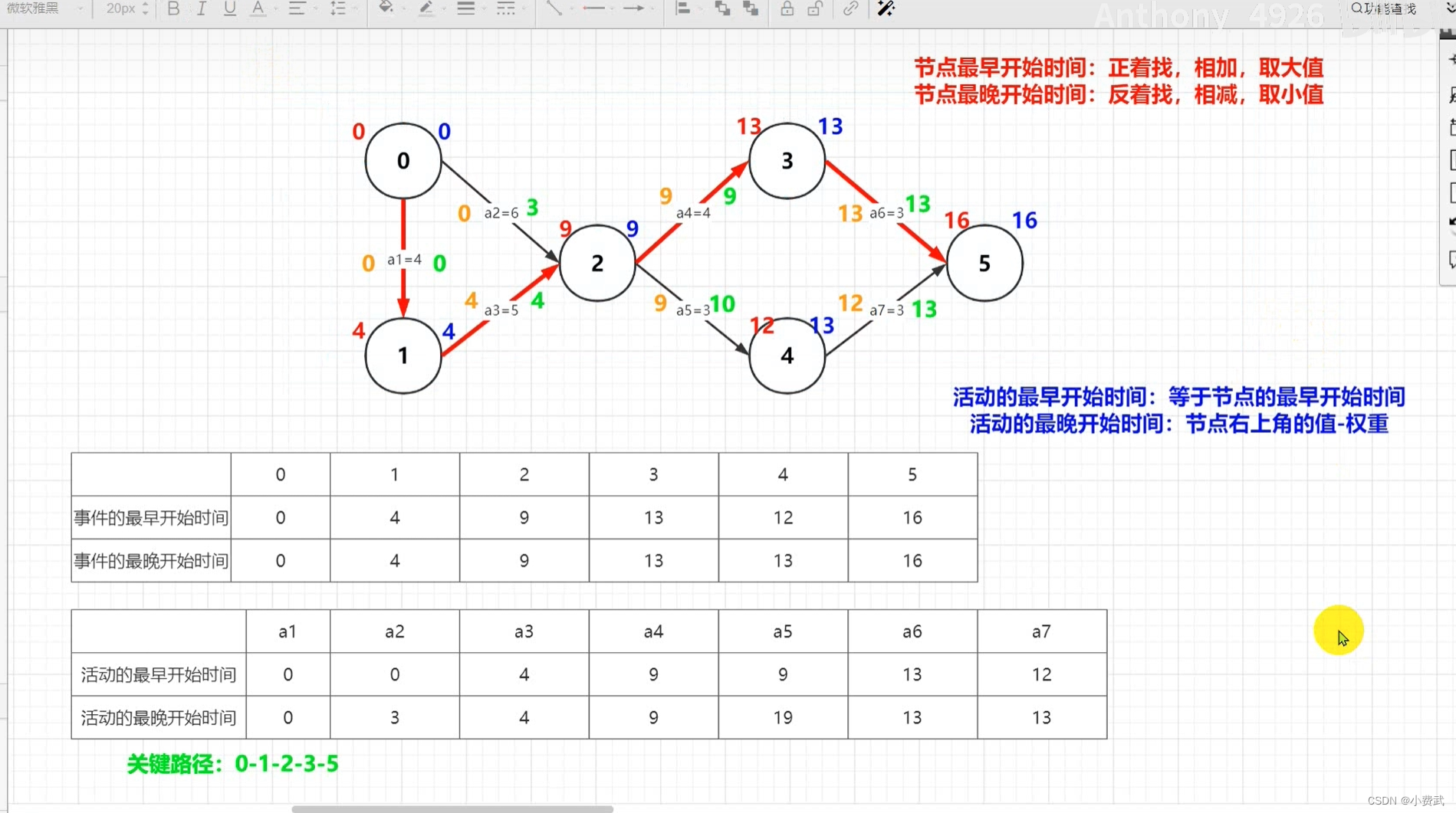
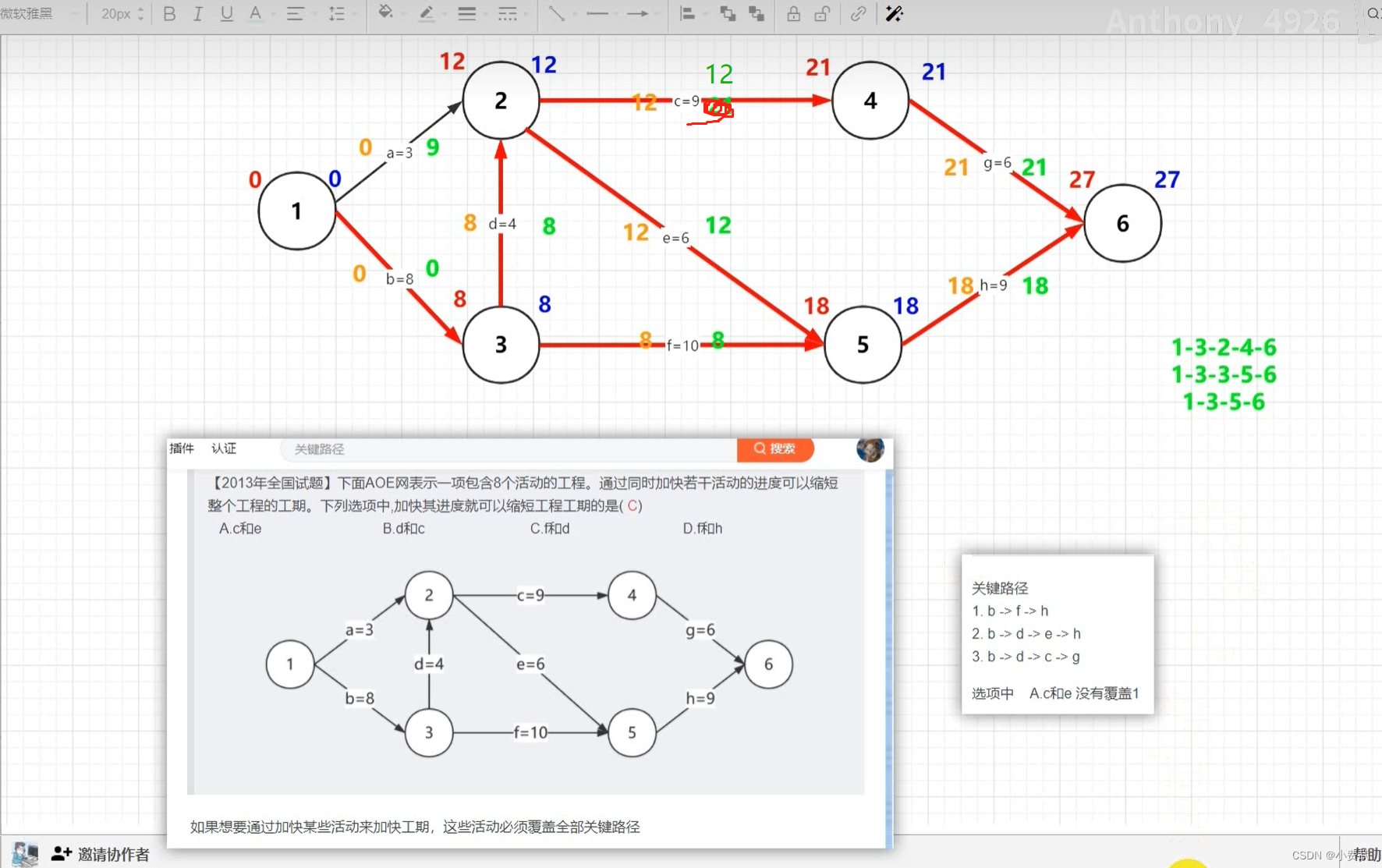
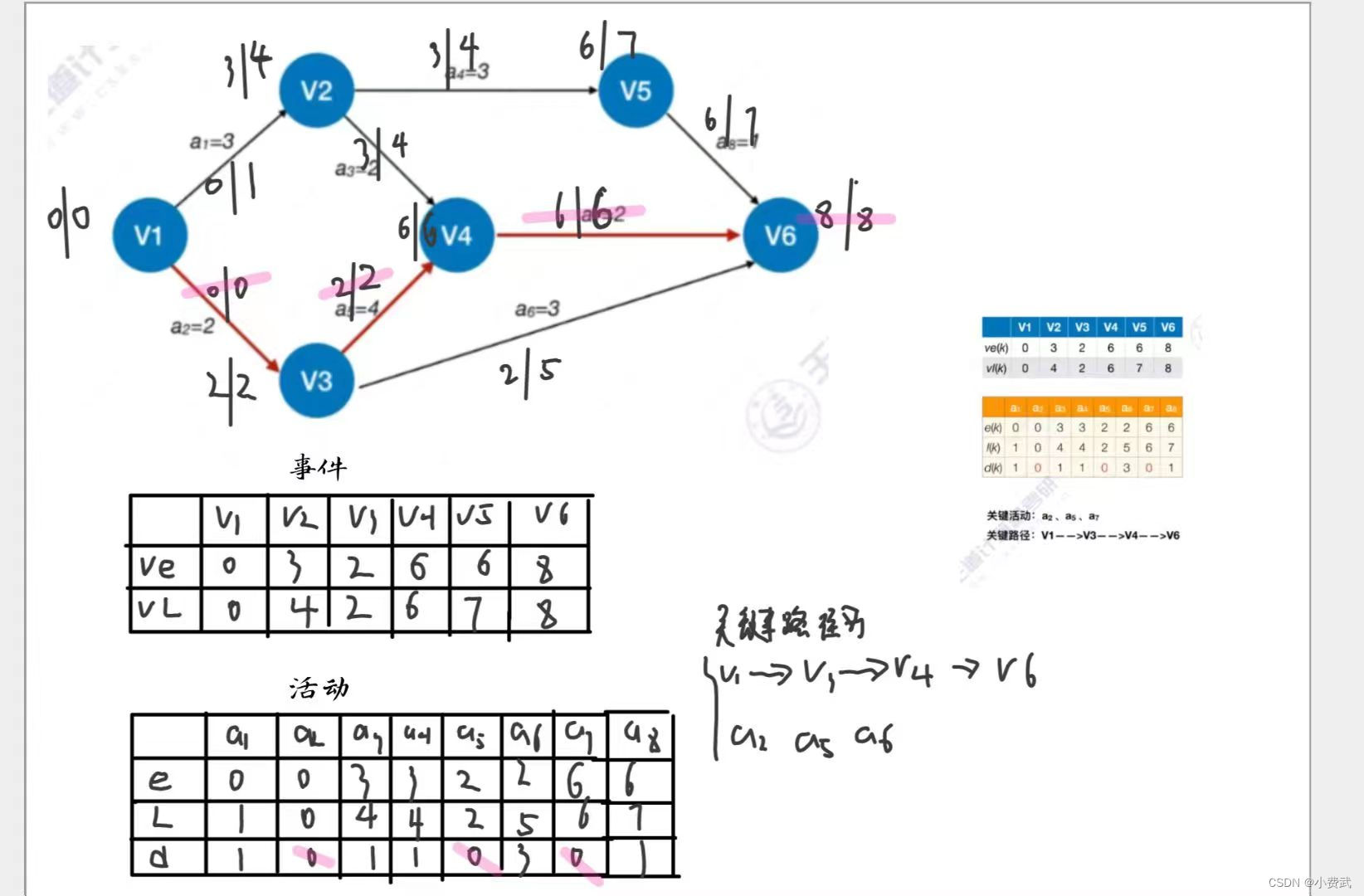


















 714
714











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









