







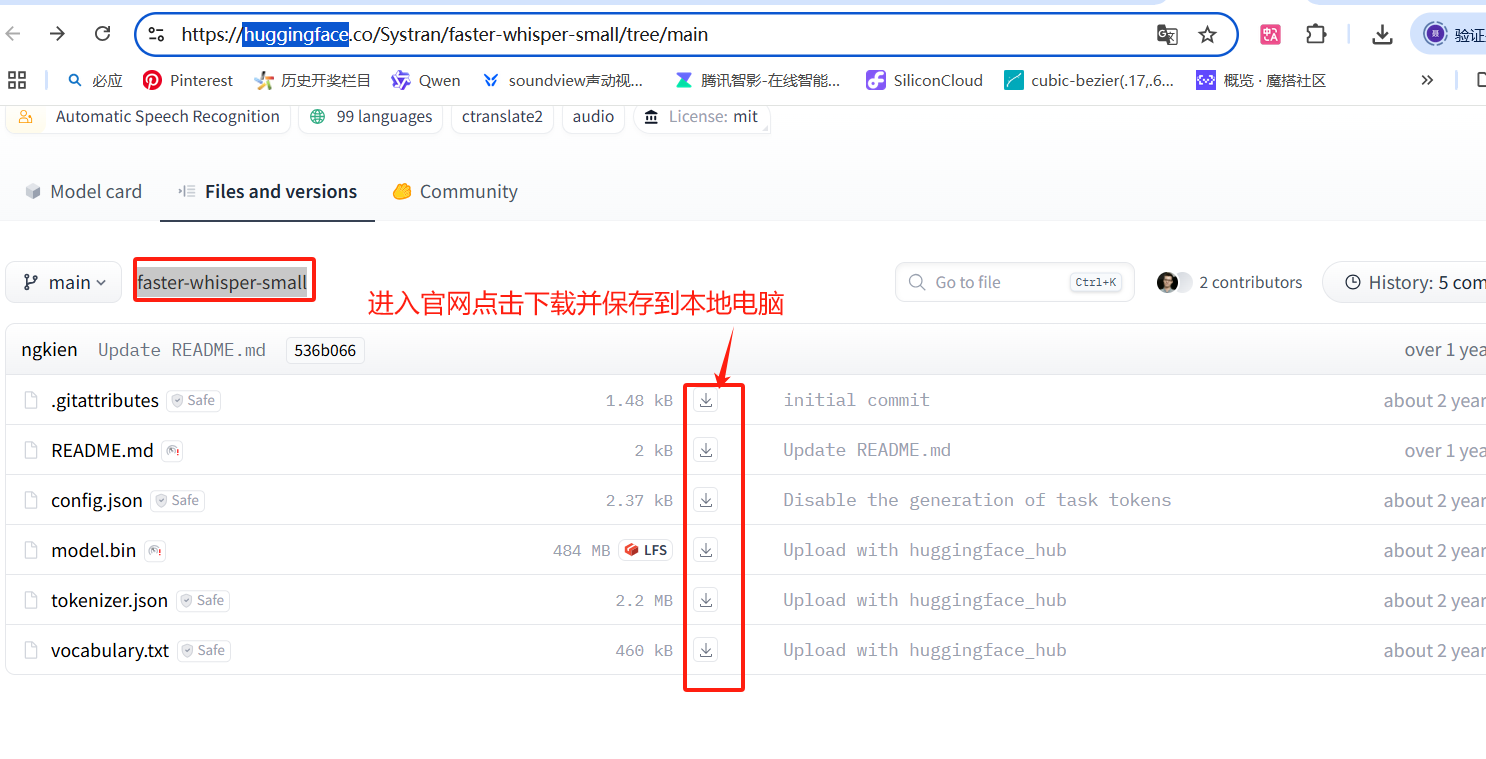
 重点说明,下载模型时需科学上网或者用国内huggingface镜像网站下载。
重点说明,下载模型时需科学上网或者用国内huggingface镜像网站下载。
from faster_whisper import WhisperModel
from pydub import AudioSegment
from zhconv import convert # 简繁转换库
import os
import datetime
import torch
def format_time(seconds):
"""将秒数格式化为SRT时间格式 (HH:MM:SS,mmm)"""
td = datetime.timedelta(seconds=seconds)
hours, remainder = divmod(int(td.total_seconds()), 3600)
minutes, seconds = divmod(remainder, 60)
milliseconds = int((td.microseconds / 1000))
return f"{hours:02d}:{minutes:02d}:{seconds:02d},{milliseconds:03d}"
def audio_to_srt_fast(audio_path, output_srt_path, model_size="small", device="cpu"):
"""
高效本地音频转SRT(强制简体中文输出)
:param audio_path: 音频文件路径
:param output_srt_path: 输出SRT路径
:param model_size: 模型大小 (tiny, base, small, medium, large)
:param device: 运行设备 (cpu 或 cuda)
"""
# 转换为16kHz WAV格式
print("正在预处理音频...")
audio = AudioSegment.from_file(audio_path)
audio = audio.set_frame_rate(16000).set_channels(1)
temp_wav = "temp_16k.wav"
audio.export(temp_wav, format="wav")
# 加载Whisper模型
print(f"正在加载Whisper模型({model_size})...")
try:
model_path = "C:/whisper_models/faster-whisper-small" # 替换为你的实际路径
model = WhisperModel(model_path, device=device, compute_type="int8")
# model = WhisperModel(model_size, device=device, compute_type="int8", local_files_only=False)
except Exception as e:
print(f"模型加载失败: {str(e)}")
return False
# 转录音频(强制指定简体中文)
print("开始语音识别...")
segments, info = model.transcribe(
temp_wav,
beam_size=5,
language="zh",
initial_prompt="请用简体中文转写以下内容" # 重要提示词
)
print(f"检测到语言: {info.language}, 概率: {info.language_probability:.2f}")
# 写入SRT文件(确保简体中文)
with open(output_srt_path, 'w', encoding='utf-8') as srt_file:
for i, segment in enumerate(segments, 1):
start_time = format_time(segment.start)
end_time = format_time(segment.end)
text = convert(segment.text.strip(), 'zh-cn') # 强制转换为简体
srt_file.write(f"{i}\n")
srt_file.write(f"{start_time} --> {end_time}\n")
srt_file.write(f"{text}\n\n")
# 清理临时文件
os.remove(temp_wav)
print(f"简体中文SRT生成完成: {output_srt_path}")
if __name__ == "__main__":
# 测试配置
audio_file = "c.mp3" # 替换为您的音频文件
output_srt = "c.srt"
# 安装简繁转换库(如果尚未安装)
try:
import zhconv
except ImportError:
print("正在安装简繁转换库...")
import subprocess
subprocess.run(["pip", "install", "zhconv"])
import zhconv
# 选择模型大小(中文推荐small或以上)
model_size = "small"
# 选择设备
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"使用设备: {device}")
print("=== 开始生成简体中文字幕 ===")
audio_to_srt_fast(audio_file, output_srt, model_size, device)


















 2566
2566

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









