






模板层
【一】Djang的准备工作
- 当你只是想测试Django中的某一个py文件内容, 那么你可以不用书写前后端交互的形式而是直接写一个测试脚本就可以了(models.py)。
第一步
配置项就是配置数据库的
# setting.py中
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
# 数据库名字
'NAME': "tian",
# 数据库用户名
"USER": "root",
# 数据库密码
"PASSWORD": "12186",
# 数据库 IP,本地默认是127.0.0.1/localhost
"HOST": "127.0.0.1",
# 数据库端口
"PORT": 3306,
# 数据库编码
"CHARSET": "utf8mb4",
}
}
第二步
-
使用猴子补丁
-
就是在项目下
__init__或者任意的应用名下__init__文件中书写一下代码 -
import pymysql pymysql.install_as_MySQLdb() -
在
models.py文件中定义模型表
DateField
DateTimeField
# 两个重要参数
auto_now: 每次操作数据的时候, 该字段会自动将当前时间更新。
auto_now_add: 在创建数据的时候会自动将当前创建时间记录下来, 之后只要不认为的修改, 那么就一直不变。
from django.db import models
# Create your models here.
class User(models.Model):
name = models.CharField(max_length=32)
age = models.IntegerField()
register_time = models.DateTimeField() # 年月日
第三步
在manage.py文件中复制以下的代码到tests.py文件中
import os
import sys
def main():
"""Run administrative tasks."""
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'Books.settings')
第四步
from django.test import TestCase
import os
def main():
"""Run administrative tasks."""
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'Books.settings')
import django
django.setup()
# 测试脚本代码
from apply02 import models
# 获取User中的所有信息
models.User.objects.all()
from apply02 import models
def main():
# 构建查询对象
res = models.Book.objects.filter(title='红楼梦') # 使用正确的字段名和过滤条件
# SELECT `apply02_book`.`id`, `apply02_book`.`title`, `apply02_book`.`price`, `apply02_book`.`publish_date`, `apply02_book`.`publish_id` FROM `apply02_book` WHERE `apply02_book`.`title` = 红楼梦
# 查看生成的 SQL 语句
print(res.query)
if __name__ == '__main__':
main()
【二】单表操作
先连接数据库

- 建表之后注意迁移数据库。
- 每一次在
models.py修改原本数据的时候就要迁移一遍。 - 在迁移之前也要先确定会。
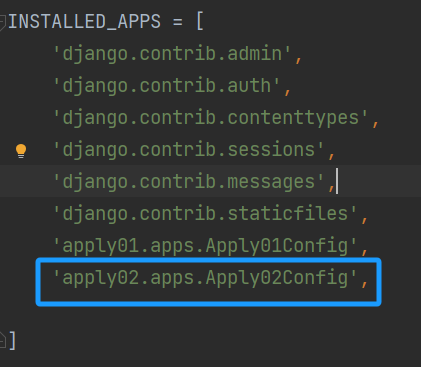
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'apply01.apps.Apply01Config',
'apply02.apps.Apply02Config',
]
数据库迁移
(1)生成迁移文件
- 将操作记录记录在migrations文件夹
- 虽然文件夹内有相关文件,但是此时并没有同步到数据库中,所以数据库是没有数据的
- manage.py 执行相关命令
- 方式有两种
- 一种是 task 任务里面
- 一种是命令行
python manage.py makemigrations
(2)迁移记录生效
- 将操作同步到真正的数据库
python manage.py migrate
查询过滤条件:
在Django的ORM(对象关系映射)中,get() 方法和 filter() 方法都是用于查询数据库的方法,但它们之间有一些区别。
-
get()方法:get()方法用于获取满足指定条件的单个对象。- 如果查询结果为空或符合条件的对象不唯一,
get()方法会引发DoesNotExist或MultipleObjectsReturned异常。 - 通常在使用主键或其他唯一字段进行查询时使用
get()方法。
-
filter()方法:filter()方法用于获取满足指定条件的多个对象,返回一个查询集(QuerySet)对象。- 如果查询结果为空,
filter()方法返回一个空的查询集。 - 如果查询结果不为空,
filter()方法返回一个包含符合条件的对象的查询集。 - 查询集可以进一步操作,例如链式调用其他过滤器方法(如
exclude()、order_by()等)或对查询结果进行迭代。
下面是使用 get() 和 filter() 方法的示例:
# 使用 get() 方法获取单个对象
user = User.objects.get(id=1) # 获取主键为 1 的用户对象
# 注意:如果找不到符合条件的对象,会引发 DoesNotExist 异常
# 使用 filter() 方法获取多个对象
users = User.objects.filter(age=25) # 获取年龄为 25 的所有用户对象
# 注意:即使没有符合条件的对象,也会返回一个空的查询集
总结来说,get() 方法用于获取单个对象(不建议使用),而 filter() 方法用于获取多个对象。根据具体的查询需求,选择适合的方法来进行数据库查询操作。
常用方法:
-
新增数据:
- 使用
create()方法可以新增一条数据,并将字段名和字段值作为参数传递给该方法。
示例:
User.objects.create(name='mei', age=18, register_time='2002-2-2') - 使用
-
查询全部数据:
- 使用
all()方法可以获取表中的所有数据对象。
示例:
User.objects.all() - 使用
-
带有筛选条件的过滤:
- 使用
filter()方法可以根据指定的筛选条件获取符合条件的数据对象。
示例:
User.objects.filter(name='MD') - 使用
-
获取筛选结果的第一条数据:
- 使用
first()方法可以获取筛选结果中的第一条数据对象。
示例:
User.objects.filter(name='MD').first() - 使用
-
获取筛选结果的最后一条数据:
- 使用
last()方法可以获取筛选结果中的最后一条数据对象。
示例:
User.objects.filter(name='MD').last() - 使用
-
获取筛选后的结果进行修改:
- 使用
update()方法可以对筛选结果中的数据进行修改。
示例:
User.objects.filter(name='MD').update(age=20) - 使用
-
获取筛选后的结果进行删除:
- 使用
delete()方法可以删除筛选结果中的数据。
示例:
User.objects.filter(name='MD').delete() - 使用
-
根据指定条件获取数据对象:
- 使用
get()方法可以根据指定条件获取单个数据对象,如果条件不存在或数据大于2条,则会报错。
示例:
User.objects.get(name='MD') - 使用
-
获取单个字段名所对应的数据:
- 使用
values()方法可以获取指定字段名所对应的数据。
示例:
User.objects.values('name') - 使用
-
获取多个字段名所对应的数据:
- 使用
values_list()方法可以获取多个字段名所对应的数据。
示例:
User.objects.values_list('id', 'name', 'age') - 使用
-
去重:
- 使用
distinct()方法可以对筛选结果进行去重。
示例:
User.objects.values('age').distinct() - 使用
-
排序:
- 使用
order_by()方法可以对查询结果进行排序,默认为升序,使用-可以实现降序。
示例:
User.objects.order_by('id') User.objects.order_by('-id') - 使用
-
反转已经经过排序的数据:
- 使用
reverse()方法可以反转查询结果的顺序。
示例:
User.objects.order_by('age').reverse() - 使用
-
统计当前数据对象的个数:
- 使用
count()方法可以统计查询结果的数量。
示例:
User.objects.count() - 使用
-
排除指定条件的数据:
- 使用
exclude()方法可以剔除符合指定条件的数据。
示例:
User.objects.exclude(name='MD') - 使用
-
判断符合当前条件的数据是否存在:
- 使用
exists()方法可以判断查询结果是否存在。
示例:
User.objects.filter(name='jin').exists() - 使用
补充:查看当前 ORM 语句的 SQL 查询语句:
- 使用
.query可以查看当前 ORM 语句生成的 SQL 查询语句,前提是要使用 QuerySet 对象。
示例:
queryset = User.objects.filter(name='MD')
print(queryset.query)
希望这个总结对您有所帮助。如果您还有其他问题,请随时提问。
- 查询全部:all
user_obj = models.User.objects.all()
print(user_obj)
【1】增加
create
from django.test import TestCase
import os
def main():
"""Run administrative tasks."""
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'Books.settings')
import django
django.setup()
from apply02 import models
# 增 第一种
res = models.User.objects.create(name='mei',age=18,register_time='2002-2-2')
print(res)
# 第二种
import datetime
# 生成一个当前的时间对象
c_time = datetime.datetime.now()
res = models.User.objects.create(name="ming", age=23, register_time=c_time)
print(res)
res.save()
【2】删除
delete
# pk : 自动查找到当前表的主键字段,指代的就是当前表的主键字段
# 使用 pk 后不需要知道当前表的主键字段 , 他会自动帮我们查找并匹配
# 删除
# 查完直接删
res = models.User.objects.filter(pk=10).delete()
print(res)
# 先查询在删除
res = models.User.objects.filter(pk=9).first()
# 利用对象的方法删除
res.delete()
【3】更改
update
# 更改数据
# 查完直接改
res = models.User.objects.filter(pk=4).update(name='ren')
print(res)
# 先查询再修改
user_obj = models.User.objects.get(pk=2)
user_obj.name = 'MD'
print(user_obj)
user_obj.save()
【4】获取指定字段的数据
# 获取到指定字段的数据
# 获取一个字段的数据
res = models.User.objects.values('name')
# <QuerySet [{'name': 'hongloumeng'}, {'name': 'MD'}, {'name': 'bai'}, {'name': 'ren'}, {'name': 'tian'}]>
print(res)
# 获取多个字段的数据
res = models.User.objects.values_list('id','name','age')
# < QuerySet[(1, 'hongloumeng', 26), (2, 'MD', 18), (3, 'bai', 18), (4, 'ren', 23), (5, 'tian', 23)] >
print(res)
【5】去重
# 去重
res = models.User.objects.values('age').distinct()
# < QuerySet[{'age': 26}, {'age': 18}, {'age': 23}] >
print(res)
【6】排序
# 排序
# 默认升序
res = models.User.objects.order_by('id')
# < QuerySet[ < User: User
# object(1) >, < User: User
# object(2) >, < User: User
# object(3) >, < User: User
# object(4) >, < User: User
# object(5) >, < User: User
# object(6) >] >
print(res)
# 降序
res = models.User.objects.order_by('-id')
# < QuerySet[ < User: User
# object(6) >, < User: User
# object(5) >, < User: User
# object(4) >, < User: User
# object(3) >, < User: User
# object(2) >, < User: User
# object(1) >] >
print(res)
【7】反转
# 反转
res = models.User.objects.order_by('age').reverse()
# <QuerySet [<User: User object (1)>, <User: User object (6)>, <User: User object (4)>, <User: User object (5)>, <User: User object (2)>, <User: User object (3)>]>
print(res)
【8】统计个数
user_obj = models.User.objects.count()
print(user_obj)
# 6
【9】剔除结果
# 剔除结果
# 排出在外
# 将某个数据排出在结果之外
res = models.User.objects.exclude(name='MD')
# <QuerySet [<User: User object (1)>, <User: User object (3)>, <User: User object (4)>, <User: User object (5)>]>
print(res)
【10】是否存在
# 是否存在
res = models.User.objects.filter(name='jin').exists()
res1 = models.User.objects.filter(name='MD').exists()
print(res)
# False
print(res1)
# True
【三】双下划线查询
大于
- 年龄大于20岁的数据
# 双下划线查询
res = models.User.objects.filter(age__gt=20)
# <QuerySet [<User: User object (1)>, <User: User object (4)>, <User: User object (5)>, <User: User object (6)>]>
print(res)
小于
- 年龄小于20岁的数据
res = models.User.objects.filter(age__lt=20)
# <QuerySet [<User: User object (2)>, <User: User object (3)>]>
print(res)
大于等于
- 年龄大于等于20岁的
res = models.User.objects.filter(age__gte=23)
# <QuerySet [<User: User object (1)>, <User: User object (4)>, <User: User object (5)>, <User: User object (6)>]>
print(res)
小于等于
- 年龄小于23岁的
res = models.User.objects.filter(age__lte=23)
# <QuerySet [<User: User object (2)>, <User: User object (3)>, <User: User object (4)>, <User: User object (5)>]>
print(res)
或者条件
- 名字是MD或者是bai
# 或
res = models.User.objects.filter(name__in=('MD', "bai",'tian'))
# <QuerySet [<User: User object (2)>, <User: User object (3)>, <User: User object (5)>, <User: User object (6)>]>
print(res)
两个条件之间
- 年龄是18-26之间
- 首尾都要
res = models.User.objects.filter(age__range=(18,26))
# <QuerySet [<User: User object (1)>, <User: User object (2)>, <User: User object (3)>, <User: User object (4)>, <User: User object (5)>, <User: User object (6)>]>
print(res)
模糊查询
- 查询出名字中含有 D的数据 – 模糊查询
res = models.User.objects.filter(name__contains='D')
# <QuerySet [<User: User object (2)>, <User: User object (6)>]>
print(res)
以指定条件开头/结尾
- 以什么开头
# res = models.User.objects.filter(register_time__startswith='2018')
# # <QuerySet [<User: User object (1)>, <User: User object (4)>]>
# print(res)
- 以什么结尾
res = models.User.objects.filter(register_time__endswith='22')
# <QuerySet [<User: User object (5)>, <User: User object (6)>]>
print(res)
查询时间日期
- 查询出注册时间是xxxx年x月份的数据/年/月/日
# 查询是三月
res = models.User.objects.filter(register_time__month='3')
# <QuerySet [<User: User object (1)>, <User: User object (4)>, <User: User object (6)>]>
print(res)
# 查询是2018年
res = models.User.objects.filter(register_time__year='2018')
# <QuerySet [<User: User object (1)>, <User: User object (4)>]>
print(res)
# 查询是每个月的第二天
res = models.User.objects.filter(register_time__day='02')
# <QuerySet [<User: User object (2)>, <User: User object (3)>]>
print(res)
【四】多表查询
数据准备
# models.py文件中
class Book(models.Model):
title = models.CharField(max_length=32)
price = models.DecimalField(max_digits=8, decimal_places=2)
publish_date = models.DateField(auto_now_add=True)
# 一对多
# 注意在在Django 2.0及以后的版本中,
# ForeignKey字段需要指定on_delete参数,
# 用于指定在关联对象被删除时的行为。
publish = models.ForeignKey(to='Publish',on_delete=models.SET_NULL, null=True)
# 多对多
authors = models.ManyToManyField(to='Author')
class Publish(models.Model):
name = models.CharField(max_length=32)
addr = models.CharField(max_length=64)
# 该字段不是给models看的,而是给校验行组件使用的
email = models.EmailField()
class Author(models.Model):
name = models.CharField(max_length=32)
age = models.IntegerField()
# 一对一
author_detail = models.OneToOneField(to='AuthorDetail',on_delete=models.SET_NULL, null=True)
class AuthorDetail(models.Model):
# 电话号码用于BigIntegerField或者CharField
phone = models.BigIntegerField()
addr = models.CharField(max_length=64)
- 注意数据迁移
python manage.py makemigrationspython manage.py migrate
一对多关系(ForeignKey)的操作:
-
创建外键关联的记录:
- 通过指定外键字段的实际字段名进行创建:
models.Book.objects.create(title="三国演义", price=100.25, publish_id=1) - 通过指定外键字段的虚拟字段名进行创建:
res = models.Publish.objects.filter(pk=3).first() models.Book.objects.create(title="水浒传", price=98.65, publish=res)
- 通过指定外键字段的实际字段名进行创建:
-
删除外键关联的记录:
models.Publish.objects.filter(pk=1).delete() -
修改外键关联的记录:
- 通过指定外键字段的实际字段名进行修改:
models.Book.objects.filter(pk=3).update(publish_id=1) - 通过指定外键字段的虚拟字段名进行修改:
res = models.Publish.objects.filter(pk=2).first() models.Book.objects.filter(pk=1).update(publish=res)
- 通过指定外键字段的实际字段名进行修改:
多对多关系(ManyToManyField)的操作:
-
添加多对多关联的记录:
- 通过使用
add()方法添加单个关联对象:book_obj = models.Book.objects.filter(pk=1).first() book_obj.authors.add(1) - 通过使用
add()方法添加多个关联对象:book_obj.authors.add(2, 3, 4) - 通过使用
set()方法设置多个关联对象:author_obj1 = models.Author.objects.get(pk=1) author_obj2 = models.Author.objects.get(pk=2) author_obj3 = models.Author.objects.get(pk=3) author_obj4 = models.Author.objects.get(pk=4) book_obj.authors.set([author_obj1, author_obj2, author_obj3, author_obj4])
- 通过使用
-
删除多对多关联的记录:
- 通过使用
remove()方法移除单个关联对象:res = models.Book.objects.filter(pk=1).first() res.authors.remove(2) - 通过使用
clear()方法清空所有关联对象:res.authors.clear()
- 通过使用
-
修改多对多关联的记录:
- 通过使用
set()方法替换关联对象:book_obj = models.Book.objects.filter(pk=1).first() book_obj.authors.set([1, 2]) # 将1和2替换为新的关联对象
- 通过使用
总代码
# 外键的增加 - 写入实际字段
models.Book.objects.create(title="三国演义", price=100.25, publish_id=1)
models.Book.objects.create(title="红楼梦", price=99.65, publish_id=2)
# 外键的增加 - 虚拟字段
res = models.Publish.objects.filter(pk=3).first()
models.Book.objects.create(title="水浒传", price=98.65, publish=res)
res = models.Publish.objects.filter(pk=4).first()
models.Book.objects.create(title="西游记", price=101.11, publish=res)
# 外键的删除
# 一对多外键的删除
models.Publish.objects.filter(pk=1).delete()
# 外键的修改
# 实际字段
models.Book.objects.filter(pk=3).update(publish_id=1)
# 虚拟字段
res = models.Publish.objects.filter(pk = 2).first()
models.Book.objects.filter(pk=1).update(publish=res)
# 多对多外键的增删改查
# 多对多外键的增删改查 - 就是在操作第三张表
# 增加
# (1)如何给书籍添加作者
book_obj = models.Book.objects.filter(pk=1).first()
# book_obj.authors - 这样我们就已经能操作第三张关系表了
# 书籍ID为1的书籍绑定了一个主键为1的作者
book_obj.authors.add(1)
# 可以传多个参数
book_obj.authors.add(2, 3, 4)
# 支持参数传对象 - 且支持多个对象
author_obj1 = models.Author.objects.get(pk=1)
author_obj2 = models.Author.objects.get(pk=2)
author_obj3 = models.Author.objects.get(pk=3)
author_obj4 = models.Author.objects.get(pk=4)
book_obj.authors.set([author_obj1,author_obj2,author_obj3,author_obj4])
# 删除
res = models.Book.objects.filter(pk=1).first()
res.authors.remove(2)
# 改
book_obj = models.Book.objects.filter(pk=1).first()
# 括号内必须给一个可迭代对象
# 把 1 删掉 替换成 2
book_obj.authors.set([1, 2])
# 把原来都删掉 , 替换成 3
book_obj.authors.set([3])
# 支持多放对象
# 获取作者对象
author_obj1 = models.Author.objects.get(pk=1)
author_obj2 = models.Author.objects.get(pk=2)
book_obj.authors.set([author_obj1,author_obj2])
# 删除
res = models.Book.objects.filter(pk=1).first()
res.authors.clear()
【补充】正反向的概念
(1)正向
- 外键字段在我手上,那么我查你就是正向
- book >>>> 外键字段在书这边(正向) >>>> 出版社
(2)反向
- 外键字段不在我手上,那么我查你就是反向
- 出版社>>>> 外键字段在书这边(反向) >>>> book
- 一对一和一对多的判断也是这样
(3)查询方法
- 正向查询按字段
- 反向查询按表名(小写),
__set
书写orm语句跟书sql语句也要,不要试图一次性写完,可以分布书写。
【五】多表查询案例
【1】子查询(基于对象的跨表查询)
(1)查询书籍主键为3的出版社
# 查询书籍主键为3的出版社
res = models.Book.objects.filter(pk=3).first()
res = res.publish
print(res)
# Publish object (1)
print(res.name)
# 人民日报
print(res.addr)
# 金陵
(2)查询跟出版社的书籍
res = models.Publish.objects.filter(book__title= '西游记').first()
# CCTV
books = res.book_set.all()
for i in books:
print(i.title)
(3)查询作者的电话号码
res = models.Author.objects.filter(name="yun").first()
res1 = res.author_detail
# 作者的年龄 26
print('作者的年龄',+ res.age)
# 119
print(res1.phone)
# 金陵
print(res1.addr)
'''
当查询返回的结果是多个的时候就需要用 .all()
'''
(4)查询出版社是CCTV社出版的书
# 查询是出版社是CCTV出版的书籍
res_pub = models.Publish.objects.filter(name='CCTV').first()
# 出版社查书 - 主键字段在书 - 反向查询
res = res_pub.book_set.all()
# <QuerySet [<Book: Book object (8)>, <Book: Book object (9)>]>
print(res)
(5)查询作者是yun写过的书
# 先拿到作者对象
res_author= models.Author.objects.filter(name="yun").first()
res = res_author.book_set.all()
# <QuerySet [<Book: Book object (1)>]>
print(res)
(6)查询手机号是 122的作者姓名
# 先拿到作者详情的对象
res_author_detail = models.AuthorDetail.objects.filter(phone=122).first()
res = res_author_detail.author
print(res)
# Author object (3)
print(res.name)
# xiao
(7)小结
-
基于对象 - 反向查询
-
什么时候需要加
_set.all()- 查询结果是多个的时候需要加
- 查询结果是多个的时候需要加
【补充】_set.all()(反向查询)
- 查询结果是多个的时候需要加
- 查询结果是多个的时候需要加
【2】联表查询(基于双下划线的跨表查询)
【1】双下划线有什么用
双下划线语法用于进行跨表查询和过滤。它允许你在查询中访问模型之间的关联关系和字段。
作用:
- 跨表查询:通过使用双下划线语法,你可以在查询中访问与当前模型关联的其他模型。例如,通过
publish__name,你可以访问与当前模型关联的Publish模型的name字段。 - 过滤:双下划线语法还可以用于过滤查询结果。你可以在查询中使用双下划线来指定过滤条件,例如
name__startswith='A',表示过滤以’A’开头的名称。
具体示例:
- 查询某个出版社的所有书籍的标题:
books = Book.objects.filter(publish__name='出版社名称')
for book in books:
print(book.title)
- 查询某个作者的所有书籍的标题:
books = Book.objects.filter(authors__name='作者名称')
for book in books:
print(book.title)
- 查询某本书的出版社名称:
book = Book.objects.get(title='书籍标题')
publish_name = book.publish.name
print(publish_name)
- 查询某个作者的详细信息:
author = Author.objects.get(name='作者名称')
author_detail = author.author_detail
print(author_detail.addr)
【六】聚合函数
from django.db.models import Max, Min, Sum, Count, Avg
res = models.Book.objects.aggregate(avg_price=Avg('price'))
print(res['avg_price'])
# {'price__avg': Decimal('99.972857')}
books = models.Book.objects.all()
for book in books:
# 100.25
# 98.65
# 101.11
# 100.25
# 99.65
# 99.65
# 100.25
print(book.price)
result = models.Author.objects.aggregate(avg_age=Avg('age'))
# 31.5
print(result['avg_age'])
res = models.Book.objects.aggregate(Max('price'),Min('price'),Count('price'),Avg('price'),)
# {'price__max': Decimal('101.11'), 'price__min': Decimal('98.65'), 'price__count': 7, 'price__avg': Decimal('99.972857')}
print(res)
【七】分组查询
res = models.Publish.objects.annotate(book_count=Count('book'))
for publish in res:
# 人民日报 2
# 德云社 3
# CCTV 2
print(publish.name, publish.book_count)
res = models.Author.objects.annotate(book_count = Count('book')).order_by('-book_count').first()
# xiao 1
print(res.name, res.book_count)
result = models.Author.objects.annotate(avg_age=Avg('age'))
# xiao 22.0
# yun 26.0
# xian 33.0
# pin 45.0
for author in result:
print(author.name, author.avg_age)
写在models.py文件中
def __str__(self):
return self.title
# 用于在对象被打印或在管理界面中显示对象时作为对象的字符串表示
【八】F() 和 Q()
F()表达式:
F()表达式用于在查询中引用数据库字段的值,可以在查询中比较字段之间的值或将字段的值与常量进行运算。使用F()表达式可以在数据库层面执行比较和计算,而不需要将数据检索到 Python 中进行处理。
F() 表达式的示例:
from django.db.models import F
res = models.Book.objects.filter(sell__gt=F('kucun'))
# < QuerySet[ < Book: 水浒传 >] >
print(res)
- 所有价格+500
from django.db.models import F
res = from django.db.models import Fmodels.Book.objects.update(price=F('price') + 500)
# 7
print(res)
res = models.Publish.objects.update(addr=Concat( F('addr'),Value('China')))
# 3
print(res)
or
res = models.Book.objects.update(title=Concat(F('title'), Value('爆款')))
print(res)
res = models.Publish.objects.update(addr=Concat(Value('China'),F('addr')))
# 3
print(res)
# 删除书籍上面的爆款两个字
res = models.Book.objects.filter(title__contains='爆款')
for book in res:
book.title = book.title.replace('爆款','')
book.save()
# QuerySet[ < Book: 三国演义 >, < Book: 水浒传 >, < Book: 西游记 >, < Book: 三国演义 >, < Book: 红楼梦 >, < Book: 红楼梦 >, < Book: 红楼梦 >] >
print(res)
Q()表达式:
Q()表达式用于构建复杂的查询条件,可以使用逻辑运算符(如 AND、OR、NOT)组合多个查询条件。使用Q()表达式可以在查询中实现更灵活的条件组合,例如多个条件的 OR 运算。
以下是一些 Q() 表达式的示例:
- and = & 、not = ~、or = |
from django.db.models import Q
# 查询出书籍价格大于100 或者 库存大于10的书
# | or
res = models.Book.objects.filter(Q(price__gt=100) | Q(kucun__lt=10))
# <QuerySet [<Book: 三国演义爆款>, <Book: 水浒传爆款>, <Book: 西游记爆款>, <Book: 三国演义爆款>, <Book: 红楼梦爆款>, <Book: 红楼梦爆款>, <Book: 红楼梦爆款>]>
print(res)
# $ and
# 查询出名字的是“MD”并且年龄大于等于21岁的人
res = models.User.objects.filter(Q(name='MD') & Q(age__gte=21))
# < QuerySet[ < User: MD, 26 >, < User: MD, 24 >] >
print(res)
# not ~
# 查询出名字不是MD的人并且年龄大于等于21岁
res = models.User.objects.filter(~Q(name='MD') & Q(age__gte=21))
# <QuerySet [<User: hongloumeng,26>, <User: ren,23>, <User: tian,23>, <User: tian,24>]>
print(res)
【九】django中如何开启事务
acid
- 原子性:
- 那么全部执行成功,要么全部重置成刚开始的状态。
- 一致性
- 数据库保持一致。
- 持久性
- 一旦事务提交成功,对数据库的修改将永久保存,即使发生系统故障或重启,修改的数据也不会丢失。
- 隔离性
- 每个事务都有独立的空间,使它们彼此独立运行。
from django.db import transaction
try:
with transaction.atomic():
# 在这个代码块中执行数据库操作
# 如果任何一个操作失败,整个事务将会回滚
# 如果所有操作成功,事务将会提交
# 你可以在这里执行一系列数据库操作,例如保存对象或更新数据
except:
# 如果发生异常,你可以在这里处理异常情况
【十】Django ORM 常用的字段和参数
【Django ORM 和 MySQL 中的对应关系】
常用字段:
charfield:对应 mysql 中的varchar类型。integerfield:对应 mysql 中的int类型。floatfield:对应 mysql 中的float类型。booleanfield:对应 mysql 中的boolean或tinyint(1)类型。datefield:对应 mysql 中的date类型。datetimefield:对应 mysql 中的datetime类型。textfield:对应 mysql 中的text类型。foreignkey:对应 mysql 中的外键关系,通过添加一个指向相关模型的字段来实现。
常用参数:
max_length:对应 mysql 中的字段长度限制,例如在charfield中使用max_length参数。default:对应 mysql 中的默认值设定。null:对应 mysql 中的字段是否允许为空,当设置为true时,对应 mysql 中的null。blank:对应 mysql 中的字段是否允许为空白,即是否可以为空字符串。choices:对应 mysql 中的字段的可选值列表,可以使用choices参数来限制字段的取值范围。verbose_name:对应 mysql 中字段的人类可读名称,用于在管理界面显示。related_name:对应 mysql 中反向关系的名称,用于在模型之间建立关联时指定反向引用的名称。on_delete:对应 mysql 中关联字段的删除行为,用于指定当关联的对象被删除时,数据库中的相应操作。unique:对应 mysql 中的唯一性约束,用于指定字段的值是否必须唯一。db_index:对应 mysql 中是否为字段创建数据库索引,用于提高查询性能。
需要注意的是,Django ORM 是一个抽象层,它可以与多种数据库后端进行交互,包括 MySQL、PostgreSQL、SQLite 等。
【十一】数据库查询优化
【1】ORM语句的特点
- 惰性查询:如果仅仅是书写了ORM语句,在后面没有使用到的话就不会对数据库进行查询,当我们需要用到查询的数据时,ORM会从数据库查询数据并返回数据
【2】惰性查询的优点:
可以减少不必要的数据库访问,提高性能和效率。特别是在涉及到复杂的关联关系和大量数据的情况下,惰性查询可以避免一次性加载所有相关数据,而是根据需要逐步加载。
总结:惰性查询是ORM框架的一种特性,它允许你在需要时才从数据库中获取数据,以提高性能和效率。
【3】only/defer
only(*fields)方法:only()方法允许你指定要加载的字段,只加载这些字段的值,而忽略其他字段。- 通过传递字段名称作为参数,你可以指定要加载的字段。例如,
Model.objects.only('field1', 'field2')将只加载模型对象的field1和field2字段。 - 这对于减少数据库查询的数据量和提高查询性能非常有用。只加载需要的字段可以减少内存消耗和网络传输开销。
defer(*fields)方法:defer()方法与only()方法相反,它允许你指定要延迟加载的字段,而不加载这些字段的值。- 通过传递字段名称作为参数,你可以指定要延迟加载的字段。例如,
Model.objects.defer('field1', 'field2')将延迟加载模型对象的field1和field2字段。 - 这对于在一些场景下避免加载不必要的字段非常有用,例如当你只需要使用模型对象的部分字段时。
# 仅加载指定字段的值
objects = Model.objects.only('field1', 'field2')
res_book = models.Book.objects.only('title', 'price')
for book in res_book:
print(book.price,book.title)
# 延迟加载指定字段的值
objects = Model.objects.defer('field1', 'field2')
res_book = models.Book.objects.defer('title', 'price')
for book in res_book:
print(book.price,book.title)
总结:
- 对于
only()方法,它会选择性地加载指定字段的值,而忽略其他字段 - 对于
defer()方法,它会选择性地延迟加载指定字段的值,而立即加载其他字段的值。
【4】select_related /prefetch_related
select_related:select_related用于在查询关联模型时,通过使用SQL的JOIN操作,将相关的对象一起加载到查询结果中。- 当你使用
select_related时,Django会自动检测关联字段,并在查询时使用JOIN操作来预先加载相关对象的数据。 - 这样可以避免在访问关联对象时进行额外的数据库查询,提高查询性能。
select_related适用于一对一关系(OneToOneField)和多对一关系(ForeignKey)。
prefetch_related:prefetch_related用于在查询关联模型时,通过使用额外的查询来预先加载关联对象的数据。- 当你使用
prefetch_related时,Django会发起额外的查询来获取关联对象的数据,并将其缓存起来以供后续使用。 - 这样可以避免在访问关联对象时进行多次数据库查询,提高查询性能。
prefetch_related适用于多对多关系(ManyToManyField)和一对多关系(Reverse ForeignKey)。
res = models.Book.objects.select_related('publish') # INNER JOIN:联表操作
for book in res:
print(book.publish.name)
# 智慧树
# 德云社
# CCTV
# CCTV
# 智慧树
# 人民日报
# 人民日报
res = models.Book.objects.prefetch_related('authors') # 子查询
for i in res:
print(i.authors.name)
- 在数据库查询中,
select_related和prefetch_related是两个常用的方法 - 用于解决查询中的关联对象性能问题。
【十二】choices参数
- 该gender字段存还是数据, 但是如果存的数字在上面元组列举的范围之内
那么可以非常轻松的获取到数据对应的真正内容。 - 1.gender字段存的数字不在上述元组列举的范围内容
2.如果在 如何获取对应的中文信息。
class User2(models.Model):
username = models.CharField(max_length=32)
age = models.IntegerField(max_length=32)
# 性别
gender_choices = (
(1,'男'),
(2,'女'),
(3,'其他'),
)
gender = models.IntegerField(choices=gender_choices)
- 存的时候,没有列举出来的数据也能进行保存(范围还是按照字段类型决定的)
# choices参数
# 存数据
# models.User2.objects.create(username='ma',age=12,gender=1)
# models.User2.objects.create(username='zhong',age=22,gender=2)
# models.User2.objects.create(username='xian',age=25,gender=3)
# models.User2.objects.create(username='xu',age=38,gender=4)
# 取数据
res_user2 = models.User2.objects.filter(pk=1).first()
# 1
# print(res_user2.gender)
print(res_user2.get_gender_display())
# 男
- 只要是choices参数的字段,如果你想要获取到对应信息。固定写法 get_字段名_display()
R JOIN:联表操作
for book in res:
print(book.publish.name)
# 智慧树
# 德云社
# CCTV
# CCTV
# 智慧树
# 人民日报
# 人民日报
res = models.Book.objects.prefetch_related(‘authors’) # 子查询
for i in res:
print(i.authors.name)
- 在数据库查询中,`select_related`和`prefetch_related`是两个常用的方法
- 用于解决查询中的关联对象性能问题。
## 【十二】choices参数
- 该gender字段存还是数据, 但是如果存的数字在上面元组列举的范围之内
那么可以非常轻松的获取到数据对应的真正内容。
- 1.gender字段存的数字不在上述元组列举的范围内容
2.如果在 如何获取对应的中文信息。
```python
class User2(models.Model):
username = models.CharField(max_length=32)
age = models.IntegerField(max_length=32)
# 性别
gender_choices = (
(1,'男'),
(2,'女'),
(3,'其他'),
)
gender = models.IntegerField(choices=gender_choices)
- 存的时候,没有列举出来的数据也能进行保存(范围还是按照字段类型决定的)
# choices参数
# 存数据
# models.User2.objects.create(username='ma',age=12,gender=1)
# models.User2.objects.create(username='zhong',age=22,gender=2)
# models.User2.objects.create(username='xian',age=25,gender=3)
# models.User2.objects.create(username='xu',age=38,gender=4)
# 取数据
res_user2 = models.User2.objects.filter(pk=1).first()
# 1
# print(res_user2.gender)
print(res_user2.get_gender_display())
# 男
- 只要是choices参数的字段,如果你想要获取到对应信息。固定写法 get_字段名_display()














 237
237











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









