







推理是求解问题的一种重要方法。因此,推理方法成为人工智能的一个重要研究课题。目前,人们已经对推理方法进行了比较多的研究,提出了多种可在计算机上实现的推理方法。
本篇文章主要介绍推理的基本概念,然后着重介绍鲁宾孙归结原理及其在机器定理证明和问题求解中的应用。其基本思想是先将要证明的定理表示为谓词公式,并化为字句集,然后再进行归结,如果归结出空句子,则定理得证。鲁宾孙归结原理使定理证明能够在计算机上实现。
第1关推理概述
1、人们在对各种事物进行分析、综合并最后做出决定时,通常是从已知的事实出发,通过运用已掌握的知识,找出其中蕴含的事实,或归纳出新的事实。这一过程通常称为推理,即从初始证据出发,按某种策略不断运用知识库中的已有知识,逐步推出结论的过程称为推理。(A )
A、对
B、错
2、下列有关推理的说法错误的是(D )
A、在人工智能系统中,推理是由程序实现的,称为推理机。
B、已知事实和知识是构成推理的两个基本要素。
C、人工智能作为对人类智能的模拟,相应地也有多种推理方式。
D、已知事实是使推理得以向前推进,并逐步达到最终目的的依据。
3、若按推出结论的途径来分,推理可分为(ABC )
A、演绎推理
B、归纳推理
C、默认推理
D、单调推理
4、下列有关推理的分类正确的是(ABCD )
A、按照推理过程中推出的结论是否越来越接近最终目标来划分,可分为单调推理与非单调推理。
B、归纳推理是从个别到一般的过程,是从足够多的具体事例中归纳出一般性知识的推理过程。
C、在单调推理中,随着推理向前推进及新知识的加入,推出的结论越来越接近最终目标。
D、如果推理过程中运用与推理有关的启发性知识,则称为启发式推理,否则称为非启发式推理。
5、下列有关推理方向说法正确的是( C)
A、正向推理是从假设目标开始往事实方向进行的推理。
B、逆向推理是以事实作为出发点的一种推理。
C、把正向推理和逆向推理结合起来所进行的推理称为混合推理。
D、混合推理是指正向推理和逆向推理同时进行,使推理过程在中间的某一步结合起来。
6、下面哪些是常见的冲突消解策略( ABCD)
A、按针对性排序。
B、按已知事实的新鲜性排序。
C、按匹配度排序。
D、按条件个数排序。
相关知识:
1、推理的定义
人们在对各种事物进行分析、综合并最后做出决定时,通常是从已知的事实出发,通过运用已掌握的知识,找出其中蕴含的事实,或归纳出新的事实。这一过程通常称为推理,即从初始证据出发,按某种策略不断运用知识库中的已有知识,逐步推出结论的过程称为推理。
在人工智能系统中,推理是由程序实现的,称为推理机。已知事实和知识是构成推理的两个基本要素。已知事实又称为证据,用以指出推理的出发点及推理时应该使用的知识;而知识是使推理得以向前推进,并逐步达到最终目的的依据。
例如,在医疗诊断专家系统中,专家的经验及医学常识以某种表示形式存储于知识库中。为病人诊治疾病时,推理机就是从存储在综合数据库中的病人症状及化验结果等初始证据出发,按某种搜索策略在知识库中搜寻可与之匹配的知识,推出某些中间结论,然后再以这些中间结论为证据,在知识库中搜索与之匹配的知识,推出进一步的中间结论,如此反复进行,直到最终推出结论,即病人的病因与治疗方案为止。
2、推理的方式及其分类
人类的智能活动有多种思维方式。人工智能作为对人类智能的模拟,相应地也有多种推理方式。下面分别从不同的角度对他们进行分类。
a.若按推出结论的途径来分,可分为演绎推理、归纳推理和默认推理
- 演绎推理:演绎推理是从一般知识到具体判断的推理过程。即从问题领域的一般知识和具体问题的已知事实、判断出发,推导出这个具体问题的一个新的判断。
- 归纳推理:归纳推理是从个别到一般的过程,是从足够多的具体事例中归纳出一般性知识的推理过程。
- 默认推理:也叫做缺省推理,指推理时缺少部分前提条件、或部分前提条件没有证据证明为真,在我们假设这部分前提条件为真的情况下,推导出结论的过程。这些缺少的、或没有证据证明为真的部分前提条件,通常是当前推理相关领域的一些常识性知识、事实,并且根据经验其存在、且为真的可能性极大,因此我们有理由默认这部分前提条件存在、且为真。
b.按照推理时所用知识的确定性来划分,可分为确定性推理和不确定性推理
- 确定性推理:推理时所用的知识与证据都是确定的,推出的结论也是确定的,其真值或者为真或者为假。
- 不确定性推理:推理时所用的知识与证据不都是确定的,推出的结论也是不确定的。不确定性推理又可分为下面两种:

c.按照推理过程中推出的结论是否越来越接近最终目标来划分,可分为单调推理与非单调推理
- 单调推理:随着推理向前推进及新知识的加入,推出的结论越来越接近最终目标。
- 非单调推理:由于新知识的加入,不仅没有加强已推出的结论,反而要否定它,使推理退回到前面的某一步,重新开始。
d.若按照推理中是否运用与推理有关的启发性知识来划分,可分为启发式推理和非启发式推理。如果推理过程中运用与推理有关的启发性知识,则称为启发式推理,否则称为非启发式推理。
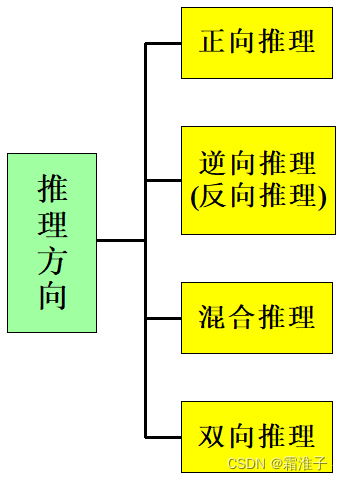
3、推理的方向
推理过程是求解问题的过程。问题求解的质量和效率不仅依赖于所采用的求解方法(如匹配方法、不确定性的传递算法等),而且还依赖于求解问题的策略,即推理的控制策略。推理的控制策略主要包括:
-
正向推理
-
*正向推理是以事实作为出发点的一种推理。** 基本思想:从用户给出的问题的事实开始,扫描系统知识库,得到适用于当前事实的所有知识的集合;运用某种冲突消解策略,从得到的知识集合中选择一条知识;将这条知识与当前事实结合进行推理,推导出新的事实或判断;将推导的结论加入原有的事实集合;重复上述过程,直到到达目标、或知识库中再没有知识可用。
-
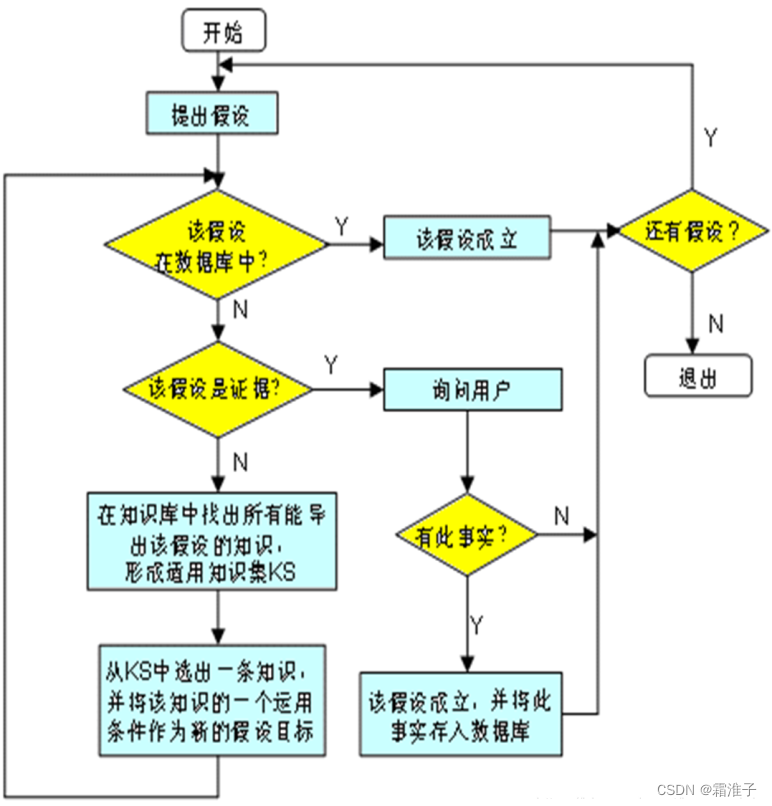
逆向推理
-
从假设目标开始往事实方向进行的推理。基本思想:用户假设一个目标,找寻这个假设目标成立的证据,首先寻找假设目标的事实证据、或用户交互提供的证据;如果找不到事实证据,接着扫描系统知识库,找寻适用于这个假设的所有知识,使用某种冲突消解策略选择一条知识应用于假设目标,产生新的假设,即子目标;对每个子目标重复前面的过程,直到由假设目标产生的所有子目标都得到事实证据、或用户交互提供的证据。
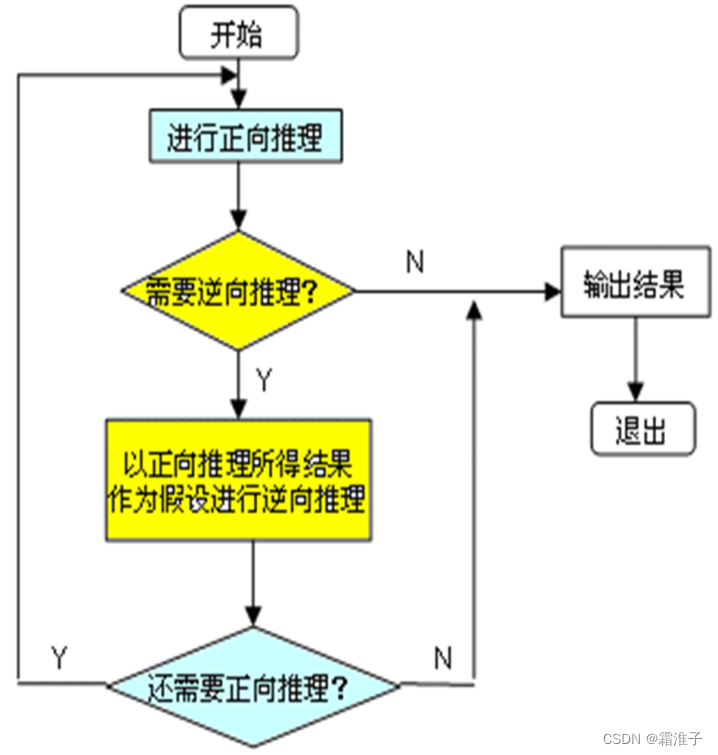
- 混合推理
- 把正向推理和逆向推理结合起来所进行的推理称为混合推理。 先正向后逆向:这种方法先进行正向推理,从已知事实出发推出部分结果,然后再用逆向推理对这些结果进行证实或提高它们的可信度。 先逆向后正向:这种方法先进行逆向推理,从假设目标出发推出一些中间假设,然后再用正向推理对这些中间假设进行证实。
-
双向推理
-
是指正向推理和逆向推理同时进行,使推理过程在中间的某一步结合起来。
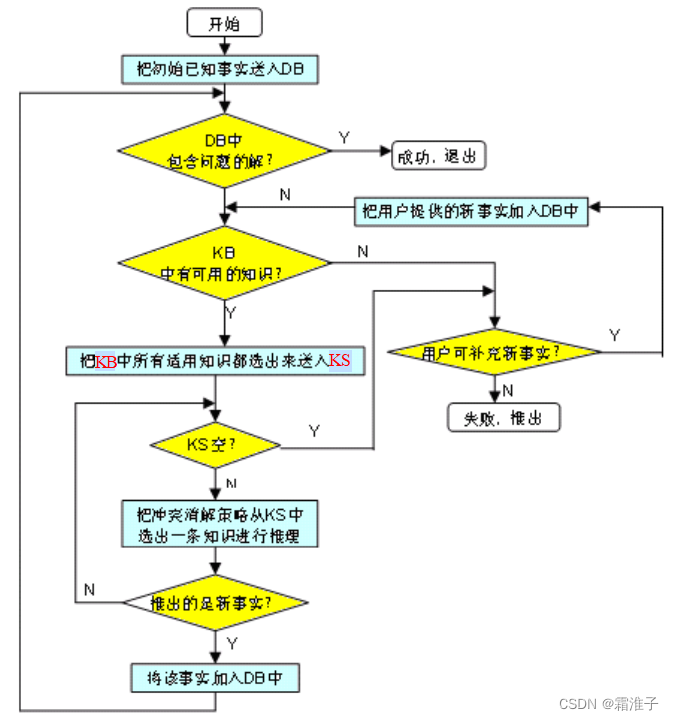
4、冲突消解策略
在推理过程中,系统要不断地运用当前的已知的事实与知识库中的知识进行匹配。此时,可能发生如下三种情况:
- 已知事实恰好只与知识库中的一个知识匹配成功;
- 已知事实不能与与知识库中的任何一个知识匹配成功;
- 已知事实可与知识库中的多个知识匹配成功。或者多个(组)已知事实可与知识库中的某一个知识匹配成功;或者有多个(组)已知事实可与知识库中的多个知识匹配成功。
对于第一种情况,由于匹配成功的知识只有一个,所以它就是可应用的知识,可直接把它应用于当前的推理。 对于第二种情况,由于找不到可与当前已知事实匹配成功的知识,使得推理无法继续进行下去。这或者是由于知识库中缺少某些必要的知识,或者由于要求解的问题超出了系统功能范围等,此时可根据当前的实际情况作相应的处理。 对于第三种情况刚好与第二种情况相反,推理过程中不仅有知识匹配成功,而且有多个知识匹配成功,称为发生了冲突。按一定的策略从匹配成功的多个知识中挑出一个知识用于当前的推理过程称为冲突消解。解决冲突时所用的策略称为冲突消解策略。 目前已有多种冲突消解策略,其基本思想都是对知识进行排序,常见的有如下几种:
(1)按针对性排序:优先选择针对性较强的产生式。
(2)按已知事实的新鲜性排序:在产生式系统推理的过程中,每应用一条产生式规则就会得到一个或多个结论或者执行某个操作,数据库就会增加新的事实。另外,在推理时还会向用户询问有关的信息,也会使数据库的内容发生变化。一般把数据库中后生成的事实称为新鲜的事实,即后生成的事实比先生成的事实有较大的新鲜性。若一条规则被应用后生成了多个结论,则即可认为这些结论有相同的新鲜度,也可以认为排在前面(或后面)的结论有较大的新鲜性,根据情况决定。
(3)按匹配度排序:在不确定推理中,需计算机已知事实与知识的匹配度,当匹配度达到某个预先规定的值时就认为它们是匹配的。若产生式r1与r2都匹配成功,则优先选择匹配度较大的产生式规则。
(4)按条件个数排序(少的更接近充要):如果有多条产生式规则生成的结论相同,则优先应用条件少的产生式规则,因为条件少的规则匹配时花费的时间较少。
第2关:自然演绎推理
1、下列说法正确的是( C)
A、任何文字的合取式称为字句。
B、空字句是可以满足的。
C、原子谓词公式是一个不能再分解的命题。
D、原子谓词公式及其否定统称为字句。
2、将下列谓词公式转化为字句集: (∀x){[﹁P(x)∨﹁Q(x)]→(∃y)[S(x,y)∧Q(x)]}∧(∀x)[P(x)∨B(x)] 下列步骤中哪些是错误的( F)
A、消去蕴含符号:( ∀ x ){ ¬ [ ¬ P ( x ) ∨ ¬ Q ( x ) ] ∨ ( ∃ y )[ S ( x ,y ) ∧ Q ( x ) ] } ∧ ( ∀ x ) [ P ( x ) ∨ B ( x ) ]
B、把否定符号转移到谓词前面:( ∀ x ){ [ P ( x ) ∧ Q ( x ) ] ∨ ( ∃ y )[ S ( x ,y ) ∧ Q ( x ) ] } ∧ ( ∀ x ) [ P ( x ) ∨ B ( x ) ]
C、变量标准化:( ∀ x ){ [ P ( x ) ∧ Q ( x ) ] ∨ ( ∃ y )[ S ( x ,y ) ∧ Q ( x ) ] } ∧ ( ∀ w ) [ P ( w ) ∨ B ( w ) ]
D、消去存在量词,设 y 的 Skolem 函数是 f( x ):( ∀ x ){ [ P ( x ) ∧ Q ( x ) ] ∨[ S ( x ,f ( x ) ) ∧ Q ( x ) ] } ∧ ( ∀ w ) [ P ( w ) ∨ B ( w ) ]
E、化为前束形:( ∀ x )( ∀ w ){ [ P ( x ) ∧ Q ( x ) ] ∨[ S ( x ,f ( x ) ) ∧ Q ( x ) ] } ∧ ( ∀ w ) [ P ( w ) ∨ B ( w ) ]
F、化为 Skolem 标准形: ( ∀ x )( ∀ w ){ Q ( x ) ∧ [ P ( x ) ∨ S ( x ,f ( x ) ) ∧Q ( x ) ] ∧ [ P ( w ) ∨ B ( w ) ] }
G、略去全称量词:Q ( x ) ∧ [ P ( x ) ∨ S ( x ,f ( x ) ) ] ∧ [ P ( w ) ∨ B ( w ) ]
H、取消合取词,把母式用字句表示:{Q ( x ) , [ P ( x ) ∨ S ( x ,f ( x ) ) , P ( w ) ∨ B ( w ) }
I、字句变量标准化,即使每个字句中的变量符号不同:{Q ( x ) , P ( y ) ∨ S ( y ,f ( y ) ) ∧ Q ( y ) , P ( w ) ∨ B ( w ) }
相关知识:
1、自然演绎推理
从一组已知为真的事实出发,运用经典逻辑的推理规则推出结论的过程称为自然演绎推理。其中,基本推理是 P 规则、T 规则、假言推理、拒取式推理。
假言推理的一般形式是: P,P→Q⇒Q
它表示:由P→Q及P为真,可推出Q为真。
例如:由“如果x是金属,则x能导电”及“铜是金属”可推出“铜能导电”的结论。
拒取式推理的一般形式是: P→Q,﹁Q⇒﹁P
它表示:由P→Q为真及Q为假,可推出P为假。
例如:由“如果下雨,则地面就湿”及“地面不湿”可推出“没有下雨”的结论。
下面举例自然演绎推理方法:
设已知如下事实:
(1)凡是容易的课程,小王( Wang )都喜欢。
(2) C 班的课程都是容易的。
(3) ds 是 C 班的一门课程。 求证:小王喜欢 ds 这门课程。
 一般来说,由已知事实推出的结论可能有多个,只要其中包含待证明的结论,就认为问题得到了解决。
一般来说,由已知事实推出的结论可能有多个,只要其中包含待证明的结论,就认为问题得到了解决。
2、谓词转化为字句集的方式
刚刚我们利用谓词公式构造了问题,现在我们详细地学习一下谓词逻辑构造字句集的方法,在谓词逻辑中,有下述定义:
原子( atom )谓词公式: 一个不能再分解的命题。
原子谓词公式及其否定统称为文字( literal )。 P 称为正文字,﹁P 称为负文字。 P 与 ﹁P 为互补文字。
任何文字的析取式称为字句( clause )。任何文字本身也是字句。
由子句构成的集合称为字句集。
不包含任何文字的子句称为空字句,表示为 NL 。
由于空字句不含任何文字,它不能被任何解释满足,所以空字句是永假的、不可满足的。
在谓词逻辑中,任何一个谓词公式都可以应用等价关系及推理规则化成相应的字句集,从而能够比较容易地判定谓词公式的不可满足性。下面结合一个具体的例子,说明把谓词公式化为字句集的步骤。
例:将下列谓词公式转化为字句集: (∀x)((∀y)P(x,y)→﹁(∀y)(Q(x,y)→R(x,y))).
解: (1)消去谓词公式中的→和 ↔ 符号
利用谓词公式的等价关系:
P←Q⇔﹁P∨Q
P↔Q⇔(P∧Q)∨(﹁P∧﹁Q)
上例等价变换为: (∀x)(﹁(∀y)P(x,y)∨﹁(∀y)(﹁Q(x,y)∨R(x,y)))
(2)把否定符号移到紧靠谓词的位置上
利用谓词的等价关系:
双重否定律:﹁(﹁P)⇔P
德摩根律:﹁(P∧Q)⇔﹁P∨﹁Q
﹁(P∨Q)⇔﹁P∧﹁Q
量词转换律:﹁(∀x)P⇔(∃x)﹁P
﹁(∃x)P⇔(∀x)﹁P
把否定符号移到紧靠谓词的位置上,减少了否定符号的辖域。
上例等价转化为: (∀x)((∃y)﹁P(x,y)∨(∃y)(Q(x,y)∧﹁R(x,y)))
(3)变量标准化
所谓变量标准化就是重新命名变元,使每个量词采用不同的变元,从而使不同量词的约束变元有不同的名称。这是因为在任一量词辖域内,受到该量词约束的变元为一哑元(虚构变量),它可以在该辖域内被另一个没有出现过的任意变元同一代替,而不改变谓词公式的值。
(∀x)P(x)≡(∀y)P(y)
(∃x)P(x)≡(∃y)P(y)
上述等价变换为: (∀x)((∃y)﹁P(x,y)∨(∃z)(Q(x,z)∧﹁R(x,z)))
(4)消去存在量词
分为两种情况:
一种情况是存在量词不出现在全称量词的辖域内。此时只要用一个新的个体常量替换受该存在量词约束的变元,就可以消去存在量词。因为如原谓词公式为真,则总能找到一个个体常量,替换后仍然使用谓词公式为真。这里的常量就是不含变量的 Skolem 函数。
另一种情况是存在量词出现在一个或者多个全称量词的辖域内。此时要用 Skolem 函数替换受该存在量词约束的变元,从而消去存在量词。这里认为所存在的 y 依赖于 x 的值,它们的依赖关系由 Skolem 函数所定义。
对于一般情况(∀x1)(∀x2)...(∀xn)(∃y)P(x1,x2,...,xn,y)存在量词 y 的 Skolem 函数记为y=f(x1,x2,...,xn)。可见, Skolem 函数把每个x1,x2,...xn值,映射到存在的那个 y。用 Skolem 函数代替每个存在量词化的变量的过程称为 Skolem 化。Skolem 函数所使用的符号必须是新的。 对于上述的例子,存在量词(∃y)及(∃z)都位于全称量词(∀x)的辖域内,所以都需要用 Skolem 函数代替。设 y 和 z 的 Skolem 函数分别记为f(x)和g(x),则替换后可得到: (∀x)(﹁P(x,f(x))∨(Q(x,g(x))∧﹁R(x,g(x))))
(5)化为前束形
所谓前束形,就是把所有的全程量词都移到公式的前面,使每个量词的辖域都包括公式后的整个部分,即 前束形=(前缀){母式}
其中,(前缀)是全称量词,{母式}是不含量词的谓词公式。
对于上述的例子,因为只有一个全称量词,而且已经位于公式的最左边,所以,这一步不需要做任何工作。
(6)化为 Skolem 标准型
Skolem 标准形的一般形式是: (∀x1)(∀x2)...(∀xn)M
其中,M 是子句的合取式,称为 Skolem 标准形的母式。
一般利用 P∨(Q∧R)⇔(P∨Q)∧(P∨R) 或P∧(Q∨R)⇔(P∧Q)∨(P∧R) 把谓词公式化为标准形。
对于上述例子,有 (∀x)((﹁P(x,f(x))∨Q(x,g(x)))∧(﹁P(x,f(x))∨﹁R(x,g(x))))
(7)略去全称量词
由于公式中的所有变量都是全称量词化的变量,因此,可以省略全称量词。母式中的变量仍然认为是全称量词化的变量。
对于上述的例子有 (﹁P(x,f(x))∨Q(x,g(x)))∧(﹁P(x,f(x))∨﹁R(x,g(x)))
(8)取消合取词,把母式用字句集表示
对于上述的例子有 {﹁P(x,f(x))∨Q(x,g(x))),﹁P(x,f(x))∨﹁R(x,g(x))}
(9)字句集变量标准化,即使每个句子的变量符号不同
谓词公式的性质有: (∀x)[P(x)∧Q(x)]≡(∀x)P(x)∧(∀y)Q(y)
对于上述的例子有 {﹁P(x,f(x))∨Q(x,g(x)),﹁P(y,f(y))∨﹁R(y,g(y))}
至此,我们已经详细地介绍了将谓词公式转化为字句集的步骤。
第3关:鲁宾孙归结原理
1、谓词公式不可满足的充要条件是其字句集不可满足。( )
A、对
B、错
2、为了要证明字句集S的不可满足性,只要对其中可进行字句进行归结,并把归结式加入字句集S,或者用归结式替换它的亲本字句,然后对新字句集(S1或S2)证明不可满足性就可以了。( )
A、对
B、错
3、设C1=¬P∨Q∨R,C2=¬Q∨S,L1=Q,L2=¬Q,通过归结方法可得C12=¬P∨R∨S
A、对
B、错
相关知识:
前面我们已经知道如何把谓词公式转化为字句集的方法。在这里,我们还需要知道一个定理:谓词公式不可满足的充要条件是其字句集不可满足。由这个定理我们可知,要证明一个谓词公式是不可满足的,只要证明相应的字句集是不可满足的就可以了。如何证明一个字句集是不可满足的呢?下面我们介绍鲁宾孙归结原理。
鲁宾孙归结原理又称为消解原理,是鲁宾孙提出的一种证明字句集不可满足性,从而实现定理证明的一种理论及方法。它就是机器定理证明的基础。
由谓词公式转化为字句集的过程可以看出,在字句集中字句之间是合取关系,其中只要有一个字句不可满足,则字句集就不可满足。由于空字句是不可满足的,所以,若一个字句中包含空字句,则这个字句集一定是不可满足的。鲁宾孙归结原理就是基于这个思想提出来的。其基本思想就是检查字句集 S 中是否包含空字句,若包含,则 S 不可满足;若不包含,就在子句中选择合适的子句进行归结,一旦通过归结得到空子句,就说明子句集 S 是不可满足的。
下面对命题逻辑和谓词逻辑分别给出归结的定义。
1、命题逻辑中的归结原理
定义1:设C1与C2是子句集中的任意两个子句,如果C1中的文字L1与C2中的文字L2互补,那么从C1和C2中分别消去L1和L2,并将两个子句中余下的部分析取,构成一个新子句C12。C12称为C1与C2的归结式,C1和C2称为C12的亲本子句。
例如:在字句集中取两个句子C1=P与C2=¬P,可见C1与C2是互补文字,则通过归结可得归结式C12=NIL。这里NIL代表空字句。
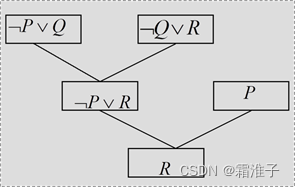
又如:C1=¬P∨Q,C2=¬Q∨R,C3=P,归结过程可用下图表示:
下面我们需要掌握一些定理。
定理:归结式C12是其亲本子句C1与C2的逻辑结论。即如果C1与C2为真,则C12为真。
推论1:设C1与C2是子句集S中的两个子句,C12是它们的归结式,若用C12代替C1与C2后得到新字句集S1,则由S1不可满足性推出原字句集S的不可满足性,即
S1的不可满足性⇔S的不可满足性。
推论2:设C1与C2是子句集S中的两个子句,C12是它们的归结式,若C12 加入原子句集S,得到新子句集S1,则S与S1在不可满足的意义上是等价的,即
S2的不可满足性⇔S的不可满足性。
这两个推论说明:为了要证明字句集S的不可满足性,只要对其中可进行字句进行归结,并把归结式加入字句集S,或者用归结式替换它的亲本字句,然后对新字句集(S1或S2)证明不可满足性就可以了。注意到空字句是不可满足的,因此,如果经过归结能得到空字句,则立即可得到原字句集S是不可满足的结论。这就是用归结原理证明字句集不可满足性的基本思想。
2、谓词逻辑中的归结原理
而在谓词逻辑中,由于字句中含有变元,所以不像命题逻辑那样可以直接消去互补文字,而需要先用最一般合一变元进行替换,然后才能进行归结。
定义2:设C1与C2是两个没有两个相同变元的子句,L1与L2分别是C1与C2中的文字,若σ是L1与¬L2的最一般合一,则称C12=(C1σ−L1σ)∨(C2σ−L2σ)为C1和C2的二元归结式子。
例:设C1=P(a)∨¬Q(x)∨R(x),C2=¬P(y)∨Q(b),求其二元归结式。

第4关:归结反演
S = [] # 以列表形式存储子句集S
""" 读取子句集文件中子句,并存放在S列表中 - 每个子句也是以列表形式存储 - 以析取式分割 - 例如:~p ∨ ~q ∨ r 存储形式为 ['~p', '~q', 'r'] """
def readClauseSet(filePath):
global S
for line in open(filePath, mode='r', encoding='utf-8'):
line = line.replace(' ', '').strip()
line = line.split('∨')
S.append(line)
""" - 为正文字,则返回其负文字 - 为负文字,则返回其正文字 """
def opposite(clause):
if '~' in clause:
return clause.replace('~', '')
else:
return '~' + clause
""" 归结 """
def resolution():
global S
end = False
while True:
if end: break
father = S.pop()
for i in father[:]:
if end: break
for mother in S[:]:
if end: break
j = list(filter(lambda x: x == opposite(i), mother))
if j == []:
continue
else:
print('\n亲本子句:' + ' ∨ '.join(father) + ' 和 ' + ' ∨ '.join(mother))
father.remove(i)
mother.remove(j[0])
#********** Begin **********#
if father == [] and mother == []:
print('归结式:NIL')
end = True
elif father == []:
print('归结式:' + ' ∨ '.join(mother))
elif mother == []:
print('归结式:' + ' ∨ '.join(father))
else:
print('归结式:' + ' ∨ '.join(father) + ' ∨ ' + ' ∨ '.join(mother))
#********** End **********#相关知识:
1、归结反演
归结原理给出了证明字句集不可满足性的方法,根据我们前面学习的知识,我们知道有:欲证明Q是P1,P2,...,Pn的逻辑结论,只需证明 (P1∧P2∧...∧Pn)∧¬Q 是不可满足的。在不可满足的意义上,谓词公式的不可满足性与其字句集的不可满足性是等价的。因此可用归结原理进行自动证明。 应用归结原理证明定理的过程称为归结反演。归结反演的一般步骤是:
(1)将已知前提表示为谓词公式 F;
(2)将待证明的结论表示为谓词公式Q,并否定得到¬Q;
(3)把谓词公式集{F,¬Q}化为子句集 S;
(4)应用归结原理对子句集S中的子句进行归结,并把每次归结得到的归结式都并入到S中。如此反复进行,若出现了空子句,则停止归结,此时就证明了Q为真。
例:某公司招聘工作人员,A ,B ,C 三人应试,经面试后,公司表示如下想法:
(1)三人中至少录取一人; (2)如果录取 A 而不录取 B ,则一定录取 C ; (3)如果录取 B ,则一定录取 C 。 求证:公司一定录取 C 。
证明:设用谓词P(x)表示录取x,则把公司的想法用谓词公式表示如下:
(1)P(A)∨P(B)∨P(C)
(2)P(A)∧P(B)→P(C)
(3)P(B)→P(C)
把要求求证的结论用谓词公式表示出来并否定,得:
(4)¬P(C)
把上述公式化成字句集:
(1)P(A)∨P(B)∨P(C)
(2)¬P(A)∨P(B)¬P(C)
(3)¬P(B)¬P(C)
(4)¬P(C)
应用归结原理进行归结
(5)P(B)∨P(C) (1)与(2)归结
(6)P(C) (3)与(5)归结
(7)NIL (4)与(6)归结
所以公司一定录取 C 。
-END-
















 2628
2628











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











