







大家好,我是阿爬!这里是讲述阿爬和阿三爬虫故事的爬友圈
继上期潜聊scrapy,本期为续集,做一个实例演示分享,希望能提升大家scrapy的使用技巧
— 1 —
常用命令
1.创建项目
scrapy startproject project_name
2.创建爬虫
cd project_namescrapy genspider spider_name domain
3.运行爬虫
方法一(项目级命令):scrapy crawl spider_name
方法二(全局命令):scrapy runspider spider_name.py
方法二(脚本):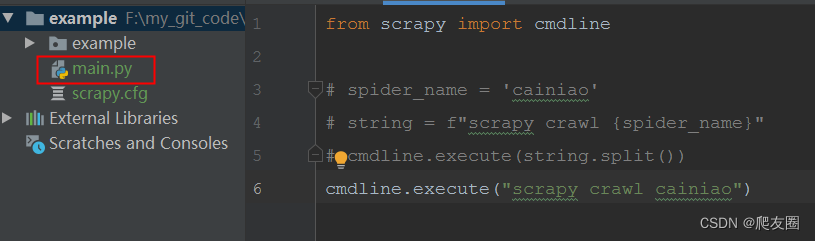
4.输出结果到文件
scrapy crawl spider_name -o output_file.json
5.暂定和恢复爬虫
scrapy crawl spider_name -s JOBDIR=crawls/somespider-1
— 2 —
项目结构和代码编写
1.项目结构

cainiao.py: 项目爬虫文件,爬虫入口
items.py: 定义爬虫中需要的字段
middlewares.py: 写爬虫、请求对象和响应对象的中间件
pipelines.py: 写数据储存相关操作
setting.py: 项目的各种配置
main.py: 项目启动文件,用于配置调试和启动项目
2.编写爬虫文件

重写start_requests方法,使用性更灵活,如果不重写直接必须start_urls,因为源码中需要对其进行循环,然后构建Request对象。
我们重写后可以按需定义相关变量,最终也同样构造出Request对象即可,这里我把需要处理的参数通过request的meta属性传递,方便在中间件中处理
3.编写中间件
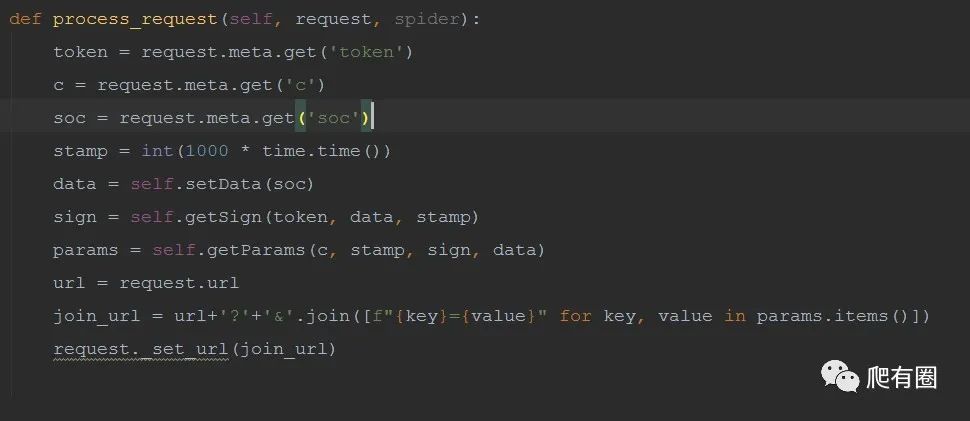
在编写中间件主要关注process_request函数,其次再写一些自己需要的功能,这里处理了sign加密参数的生成和请求参数的构造,将参数拼接到url上,最终构建完整的url。
如果请求头中有变化参数需要处理,此处也可再增加一个处理请求头的函数。
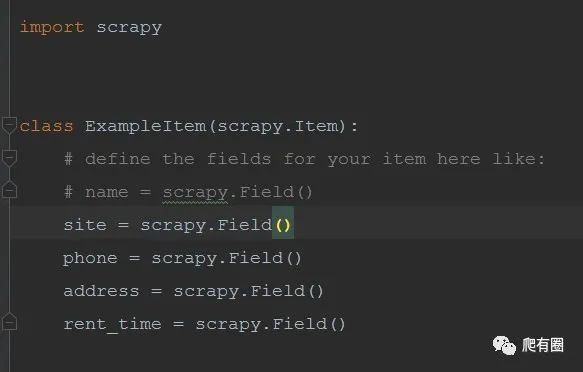
4.编写管道文件
A.在item.py中定义好需要的字段。
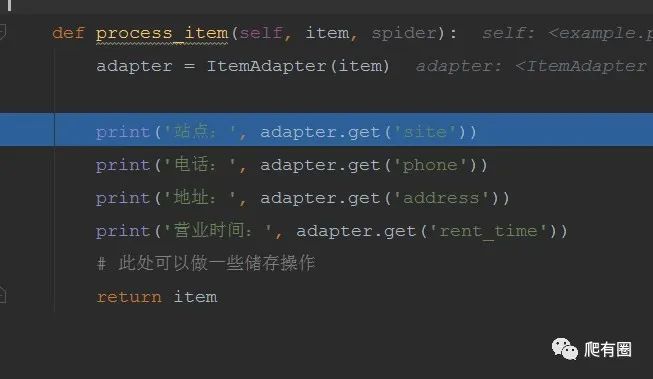
B.在pipeline.py中主要重写process_item函数,编写处理item数据的逻辑。
这里我们有具体些保存的逻辑,可自行处理练习。
5.编写配置文件
以上文件写好后需要打开setting.py文件中的相关设置
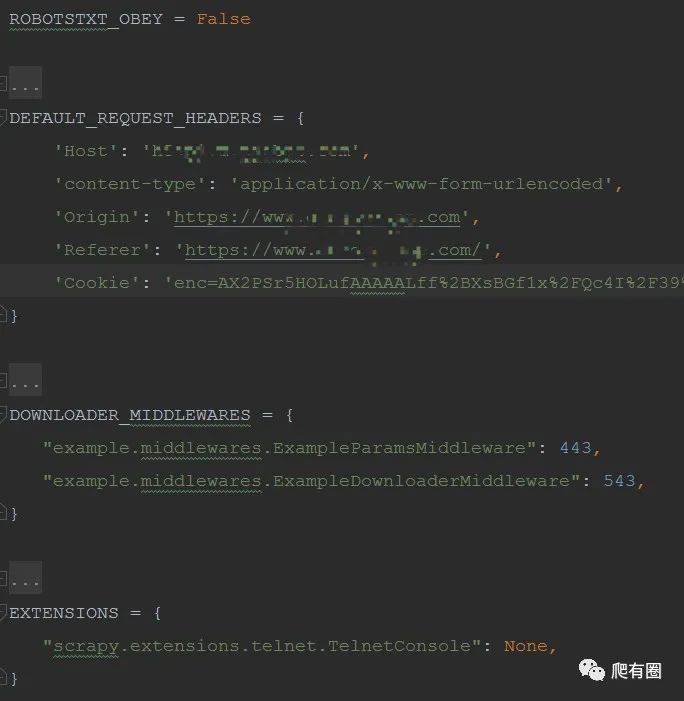
ROBOTSTXT_OBEY设置为False,不遵守机器人协议。
DEFAULT_REQUEST_HEADERS可以在这里写死,也可以在middleware中处理,后者最为合适,我在此处是写死的。
DOWNLOADER_MIDDLEWARES中间件调用,将写好的中间件名称添加到字典中,数值越小优先级越高,即优先执行。
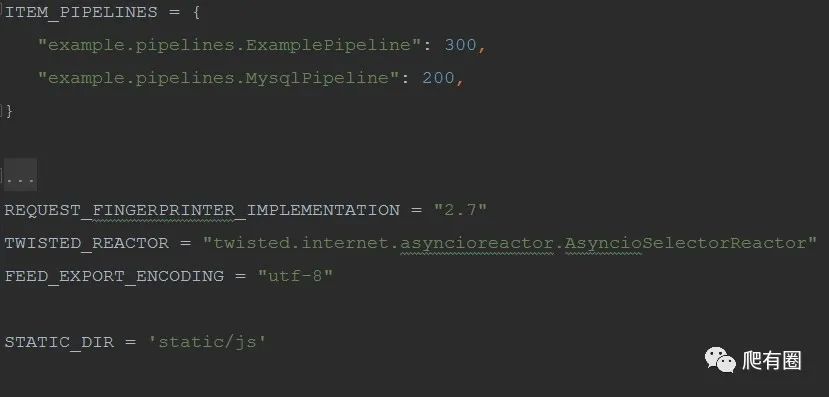
ITEM_PIPELINES同中间件一样,数值越小优先级越高,将我们写好的管道文件添加到此字典中
STATIC_DIR是静态文件路径,创建在项目根目录下,为了存放需要执行的js文件,如果不配置此变量,会导致执行js文件时找不到文件。
— 3 —
运行调试
1.调试设置
我使用的是pycharm调试项目,来看一看配置步骤,非常简单,如图所示:
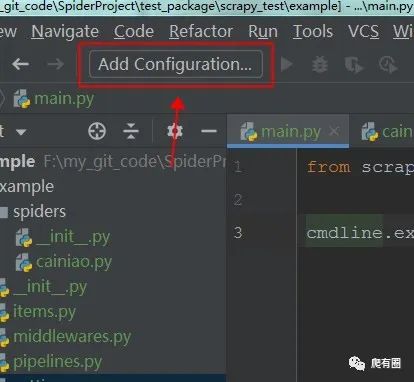
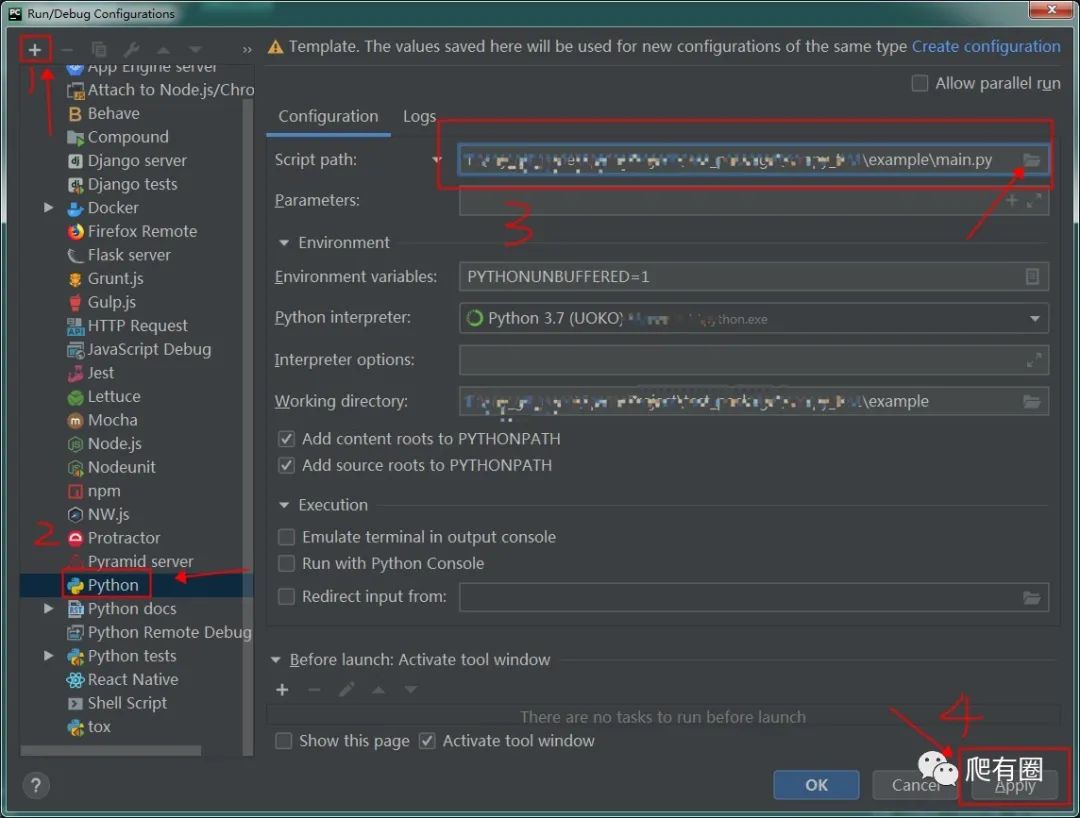
配置好点击debug运行项目就可以愉快的调试项目,了解项目执行流程和运行结果。
2.结果展示
最后展示一下运行成功的结果
至此本文的干货分享完毕,希望通过本文介绍和实践帮助大家学会scrapy框架。
本文只介绍了一种get请求+参数加密的形式,还有post请求+formdata参数加密/json参数加密的情况,大家可以自行尝试。从源码看scrapy.http.request提供了form_request和json_request两种请求类供我们处理以上两种情况。最后欢迎大家多多留言讨论。
特别声明:本文章只作为学术研究,不作为其他不法用途,如有侵权请联系作者删除。















 68
68











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









