




在学习了scrapy框架之后,有了些许收获,这里将本次小项目写下来。
一 首先进入pycharm终端控制台,(一开始我还在命令行里面,后来发现这样方便一点。)
scrapy startproject 项目名
cd 项目名\ 项目名\spiders
scrapy genspider -t crawl xxx 域名
二 编写xxx.py
(编写xxx.py之前要在items.py里面增加一些值)
items.py
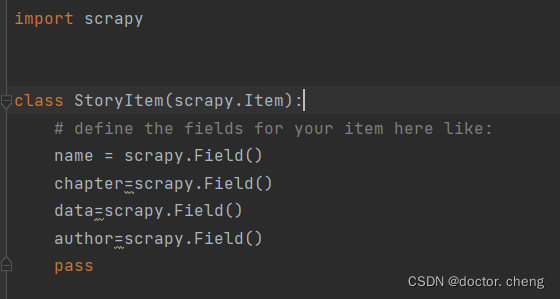
xxx.py
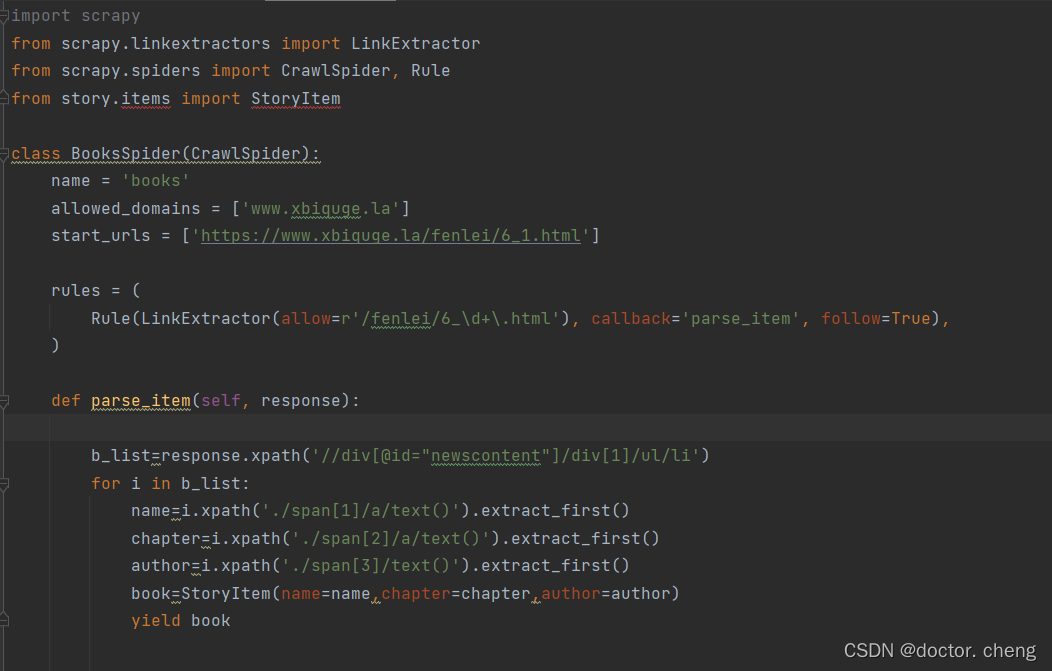
上面导入item那个虽然标红,但不会影响最终爬虫文件,可以置之不理。
现在在终端下面就可以查看运行结果
scrapy crawl xxx
三 将爬虫保存为(json 和 csv 格式)
首先在settings打开管道
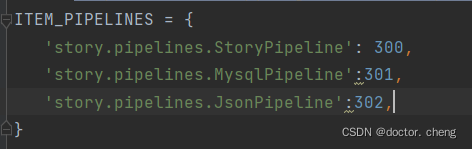
(第一个本来就是有的,后面两个需要在pipelines里面创建新的类,完成保存)
编写pipelines文件
csv格式
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 64万+
64万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









