







文章目录
一、Map和Set
在java标准库中,二分搜索树——>TreeMap/TreeSet
在java标准库中,哈希表——>HashMap/HashSet
Set:其实就是披着Set外衣的Map。也是Collection接口的子接口,一次保存一个元素,和List集合最大的区别在于List集合保存的元素不能重复。
一般使用Set集合进行去重处理!!
1.Set接口(元素不重复,使用set集合进行去重处理)
三个核心方法:
| 方法 | 解释 |
|---|---|
| boolean add(E e) | 添加一个元素,若该元素不存在则添加成功,返回true,若该元素已经存在,添加失败,返回false |
| boolean contains(Object o) | 判断一个元素o中是否在当前Set中存在 |
| boolean remove(Object o) | 在Set集合中删除指定元素o,若元素不存在,删除失败返回false,若存在删除元素返回true |
Set没有提供修改的方法,若需要修改元素只能删除要修改的元素再添加
遍历集合使用for—each循环即可
2.Map接口(保存的是一对键值对元素 key = value)
| 方法 | 解释 |
|---|---|
| V get(Object key) | 返回 key 对应的 value |
| V getOrDefault(Object key, V defaultValue) | 返回 key 对应的 value,key 不存在,返回默认值 |
| V put(K key, V value) | 设置 key 对应的 value,若K不存在,就新增一个Map.Entry对象,保存到Map中。若K已经存在,修改原来的value为新的value,返回修改前的value值 |
| V remove(Object key) | 删除 key 对应的映射关系 |
| boolean containsKey(Object key) | 判断是否包含 key |
| boolean containsValue(Object value) | 判断是否包含 value |
| Set keySet() | 返回当前Map接口中所有的Key值集合 |
| Collection values() | 返回当前Map接口中所有的value值集合 |
| Set<Map.Entry<K, V>> entrySet() | 返回所有的 key-value 映射关系 |
只要是Collection的子类都可以使用for-each进行遍历
Map.Entry<K,V>是Map内部实现的用来存放<key, value>键值对映射关系的内部类,该内部类中主要提供了
<key, value>的获取,value的设置以及Key的比较方式。
| 方法 | 解释 |
|---|---|
| K getKey() | 返回 entry 中的 key |
| V getValue() | 返回 entry 中的 value |
| V setValue(V value) | 设将键值对中的value替换为指定value |
3.关于Map接口常见子类的问题
(1)添加问题
在Map接口中,元素添加的顺序和保存的顺序没有必然联系:
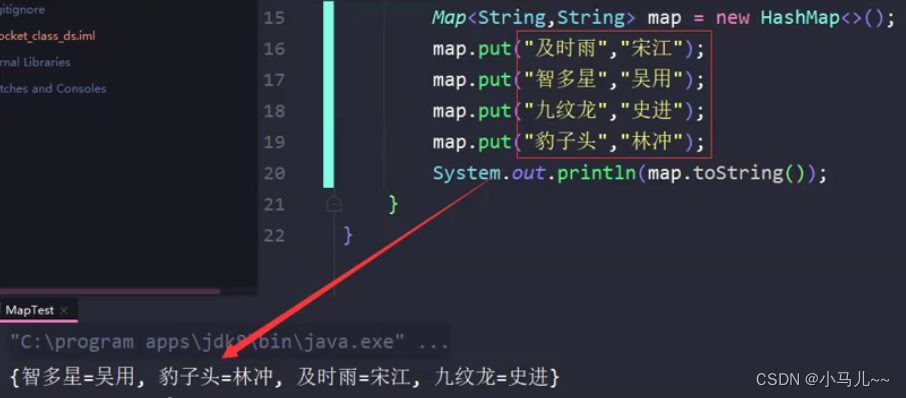
在HashMap中保存的元素顺序由hash函数来决定。
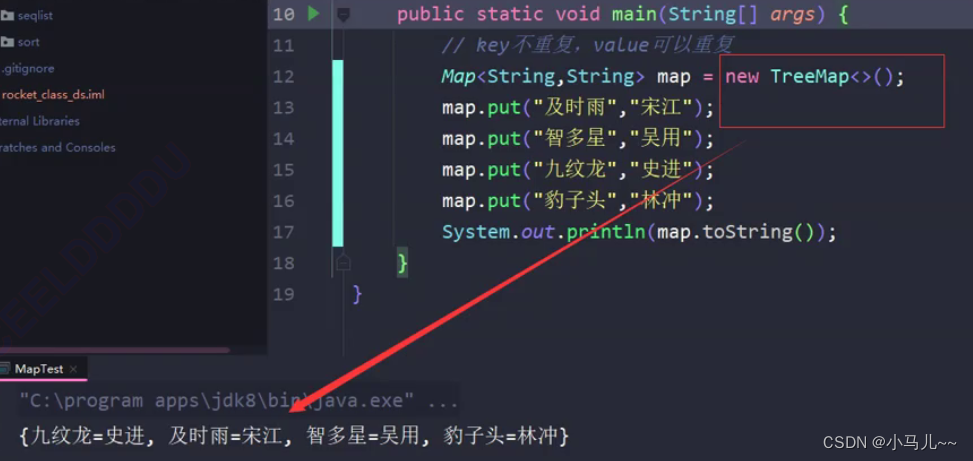
在TreeMap中保存的元素顺序由TreeMap中的compareTo方法决定(要能使用TreeMap保存元素,该类必须要么实现Comparable要么传入一个比较器)。
(2)关于保存null值的说明
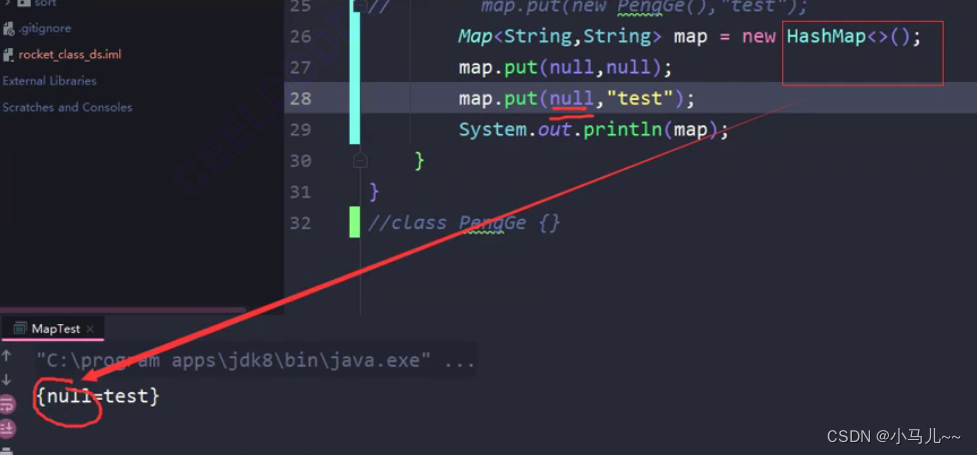
HashMap的key和value都能为null,但key的null值有且只能有一个
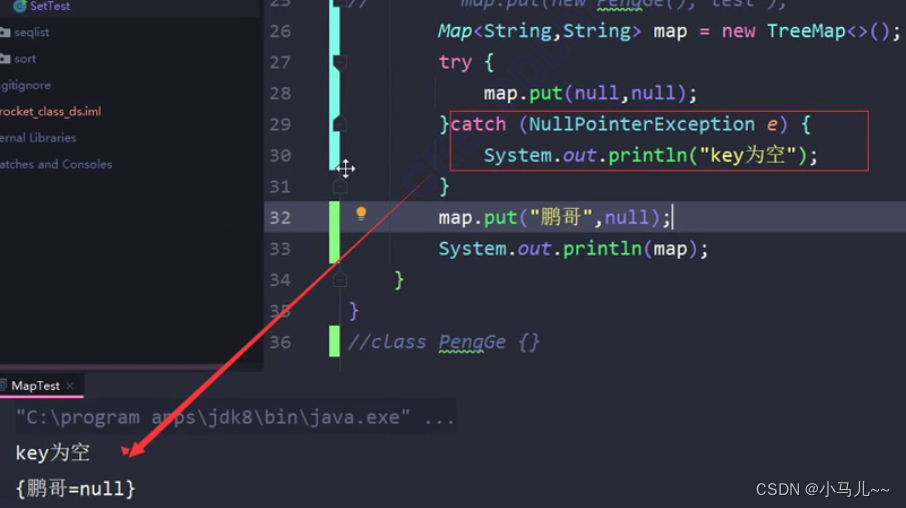
TreeMap中key不能为null,value可以为
二、二分搜索树(BST)
也称二叉搜索树,二叉排序树
1.二分搜索树的特点
-
也是二叉树
-
每个树的左子树的所有节点值 < 树根节点 < 所有右子树的节点值(树中所有子树仍然遵循此规则)
JDK中的BST不存在重复节点
-
存储的节点必须具备可比较能力(要么实现了Comparable接口,要么传入比较器)
2.二分搜索树的操作
(1)向BST中添加一个节点
新插入的元素一定都在树的叶子节点进行插入操作!
不断和树根节点比较大小,若小就在左树添加,若大就在右子树添加,然后递归上述过程~~
时间复杂度:
平均情况:O(log n)——>树的插入;
最坏情况:O(n)——>假设此时插入的是一个完全有序的集合,此时二分搜索树成为了单只树,类似链表
public void add(int val) {
root = add(root,val);
}
/**
* 向当前以root为根的BST中插入一个新元素val,返回插入后的树根
* @param root
* @param val
* @return
*/
private Node add(Node root, int val) {
if (root == null) {
Node node = new Node(val);
size ++;
return node;
}
if (val < root.val) {
root.left = add(root.left,val);
}
if (val > root.val) {
root.right = add(root.right,val);
}
return root;
}
(2)判断val是否在BST中存在
不断递归的和树的树根节点相比较:
- val == root.val就是找到了
- val < root.val继续在左树中找
- val > root.val继续在右树中找
- 到root == null就是根本不存在这个val
这个查找过程就是一个“二分搜索”
时间复杂度:平均O(log n),最坏O(n)
public boolean contains(int val) {
return contains(root,val);
}
/**
* 判断以当前root为根的BST中是否包含指定值val,存在则返回true,否则返回false
* @param root
* @param val
* @return
*/
private boolean contains(Node root, int val) {
if (root == null) {
return false;
}
if (root.val == val) {
return true;
}else if (root.val > val) {
return contains(root.left,val);
} else {
return contains(root.right,val);
}
}
(3)按照先序遍历的方式打印当前的BST
public String toString() {
StringBuilder sb = new StringBuilder();
generateBSTString(root,0,sb);
return sb.toString();
}
/**
* 按照先序遍历的方式将BST的节点值传入到sb中
* @param root
* @param height
* @param sb
*/
private void generateBSTString(Node root, int height, StringBuilder sb) {
if (root == null) {
sb.append(generateHeightStr(height)).append("NULL\n");
return;
}
sb.append(generateHeightStr(height)).append(root.val).append("\n");
generateBSTString(root.left,height+1,sb);
generateBSTString(root.right,height+1,sb);
}
/**
* 按照当前节点的高度打印--
* root.left => --
* 第二层----
* @param height
* @return
*/
private String generateHeightStr(int height) {
StringBuilder sb = new StringBuilder();
for (int i = 0; i < height; i++) {
sb.append("--");
}
return sb.toString();
}
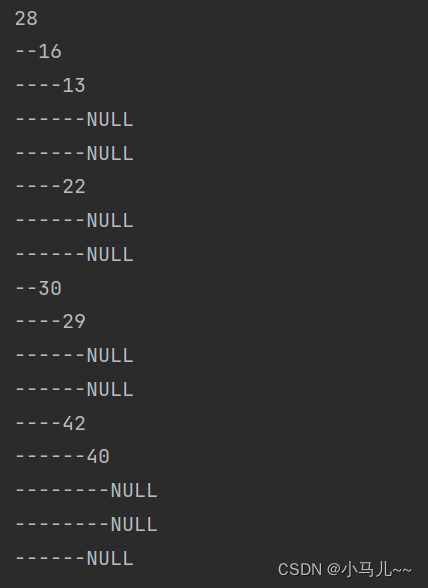
(4)找到一棵BST的最大值和最小值
在BST中最小值节点是先序遍历中第一个左子树为空的节点。
在BST中最大值节点是先序遍历中第一个右子树为空的节点。
public int findMin() {
if (size == 0) {
throw new NoSuchElementException("bst is empty! no element");
}
return min(root).val;
}
/**
* 再以root为根的BST中找到最小值节点
* @param root
* @return
*/
private Node min(Node root) {
if (root.left == null) {
return root;
}
return min(root.left);
}
public int findMax() {
if (size == 0) {
throw new NoSuchElementException("bst is empty! no element");
}
return max(root).val;
}
/**
* 再以root为根的BST中找到最大值节点
* @param root
* @return
*/
private Node max(Node root) {
if (root.right == null) {
return root;
}
return max(root.right);
}
(5)删除一棵BST的最大值和最小值
public int removeMin() {
if (size == 0) {
throw new NoSuchElementException("bst is empty! vannot remove");
}
Node minNode = min(root);
root = removeMin(root);
return minNode.val;
}
/**
* 传入一棵以root为根的BST,就能删除其中最小值,返回删除后的树根节点
* @param root
* @return
*/
private Node removeMin(Node root) {
if(root.left == null) {
Node right = root.right;
root.left = root.right = null;
size --;
return right;
}
root.left = removeMin(root.left);
return root;
}
public int removeMax() {
if (size == 0) {
throw new NoSuchElementException("bst is empty! vannot remove");
}
Node max = max(root);
root = removeMax(root);
return max.val;
}
/**
* 删除以root为根的BST中的最大值节点,返回删除后的跟节点
* @param root
* @return
*/
private Node removeMax(Node root) {
if (root.right == null) {
Node left = root.left;
root.left = root.right = root = null;
size --;
return left;
}
root.right = removeMax(root.right);
return root;
}
(6)在BST中删除任意值val
找到待删除节点的前驱或者后继:
所谓后继就是待删除节点的右子树的最小值;
所谓前驱就是待删除节点的左子树的最大值。
待删除节点值一定大于所有左子树的节点值,也一定小于所有右子树的节点值。
三、哈希表
先看一道题目:给定一个字符串 s ,找到 它的第一个不重复的字符,并返回它的索引 。如果不存在,则返回-1 。
/**
* 给定一个字符串 s ,找到 它的第一个不重复的字符,并返回它的索引 。
* 如果不存在,则返回 -1
*/
public int firstUniqChar(String s) {
//由于s只包含小写字母,因此将s中的每个字符出现的频次保存到整型数组中
int[] freq = new int[26];
//遍历s这个字符串取出每个字符,出现一次就保存到freq数组
for (int i = 0; i < s.length(); i++) {
char c = s.charAt(i);
//这行代码把字符映射成了int,每个不相同的字符都一定会唯一的映射到int
freq[c - 'a'] ++;
}
//遍历字符串找到freq数组中出现次数唯一的那个字符
int retIndex = -1;
for (int i = 0; i < s.length(); i++) {
char c = s.charAt(i);
if (freq[c - 'a'] == 1) {
retIndex = i;
break;
}
}
return retIndex;
}
题解中的freq就是一个哈希表,每个不重复的字符都和一个整型数字一一对应。
哈希表高效查找的秘诀就在于数组的随机访问能力,在数组中若知道索引,可以再O(1)时间获取到该元素(数组中若知道数组的索引,访问速度为O(1)),哈希表就是典型的用空间换时间。
哈希函数
将数据类型obj=>整型 其实就是哈希函数
哈希函数:哈希表中需要一种方法将任意的数据类型转为数组的索引,这样的一种方法具称为哈希函数。
哈希冲突
哈希冲突:不同的key经过hash函数的计算得到了相同的值

哈希函数的设计
哈希冲突在数学领域理论上一定存在,哈希函数设计的核心原则:尽可能在空间和时间上求平衡,利用最少的空间获取一个较为平均的数字分布
任意数据类型=>索引
eg:
- 字符c => f© = ‘c’ - ‘a’ 作为索引
- 一个班的学号[1…30] => 直接将学号数值作为索引值
- 身份证号 18位数 ,将大整数 => 小正数(取模操作)
- String => int 字符串内部就是字符数组,因此还是按照字符串转为int的方式
- 其他任意类型 => int 任意类型都有toString方法
一般来说将任意正整数映射为小区间数字的最常用方法就是“取模”,为避免哈希冲突,一般要模一个素数
模的数据建议:
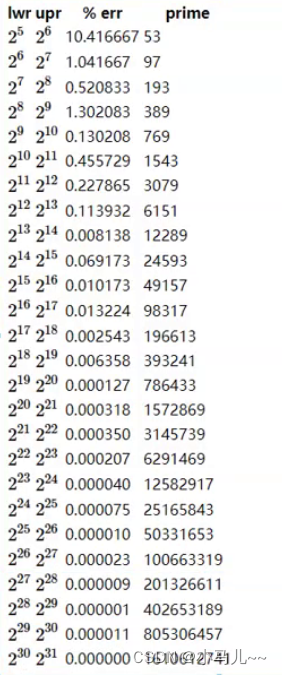
模的数字就是开辟的空间大小
哈希表:哈希函数的设计和哈希冲突的解决
哈希冲突的解决
映射得到的索引按照理论一定会冲突,那么冲突之后如何解决?
1.闭散列(线性探测法)
当冲突发生时,找到冲突位置的旁边是否存在空闲位置,直到找到第一个空闲位置放入元素(好存难查更难删,工程中很少使用此方案)。
有一组数据[1,2,3,19,120,121] 哈希函数 %101:
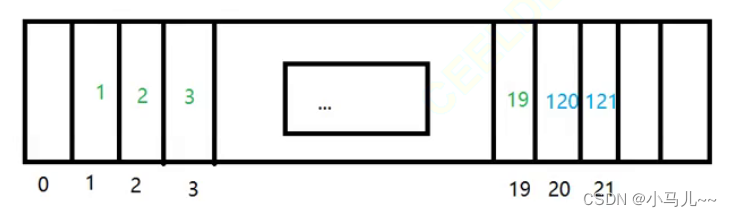
当放入120时,由于120 % 19 = 19,而19这个位置已经保存了元素,则继续向后寻找,发现20这个值为空,则将120放入20这个位置
最坏情况下,整个哈希表冲突非常严重,遍历大链表
2.开散列(链地址法)
若出现哈希冲突,就让这个位置变成链表
开散列方案下的哈希表:数组 + 链表
有一组数据[1,2,3,19,120,121] 哈希函数 %101:
当存入120时,120 % 101 = = 19,就将这个元素120连到19后边(此时和19构成链表)
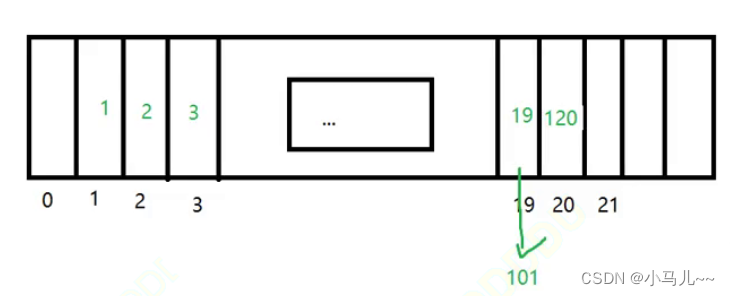
查找任意元素就是取模后若冲突,遍历链表
最坏情况下,开散列方案遍历小链表,相对于闭散列方案,找次数会大大降低,元素删除、查找就是链表的对应操作,相较于闭散列方案来看容易很多。
若当前哈希表中某个位置从图非常严重,恰好每个元素取模都相同,某个数组对应链表过长,查找效率降低,解决方案:
- 针对整个数组进行扩容(比如现在数组长度101,扩容到202,就会,由原先%101=>%202)很多原来同一个链表上的元素就会均分到其他新位置,降低哈希冲突(C++ STL的Map就采用了此方法);
- 将这个冲突严重的链表再次变为新的哈希表或二分搜索树(将O(n)优化至O(log n)),这样就只用处理冲突严重的链表,不用整张表进行处理(JDK就采用了此方法)。
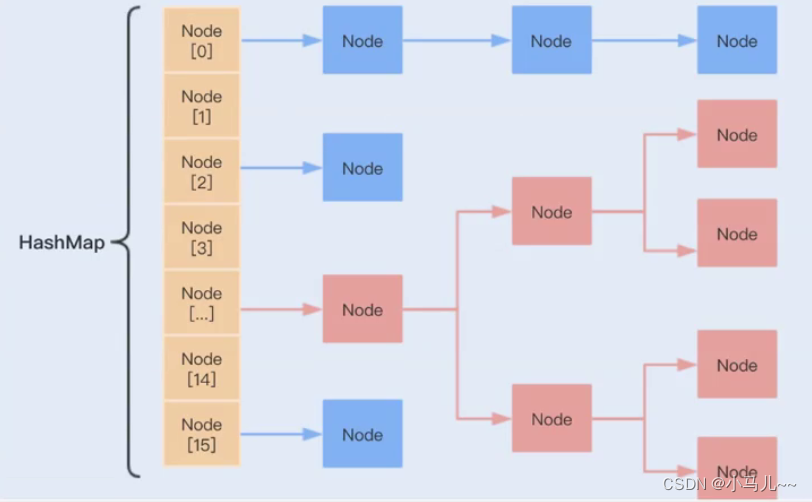
等概率成功查找的平均查找长度:
当前表中的所有元素查找次数 / 表中有效的元素个数
常用哈希函数
对于一般场景下的哈希函数的设计,用现成的就可以:MD5, MD4, MD3, SHA1, SHA256。
MD5
MD5一般用于字符串计算哈希值
MD5的特点:
- 定长,无论输入数据多长,得到的MD5值长度固定;
- 分散,如果输入数据稍有偏差,得到的MD5值相差很大(冲突概率极低,在工程领域忽略不计);
- 不可逆,根据字符串计算MD5很容易,但想通过MD5还原字符串非常困难(基本不可能);
- 根据相同的数据计算的MD5值是稳定的,不会发生变化。(稳定性是所有哈希函数都要满足的特点)
MD5用途实际非常广泛:
- 作为哈希运算;
- 用于加密;
- 对比文件内容(内容即便稍有修改,得到的MD5值天差地别)
基于开散列方式实现的哈希表(很重要)
1.将一对键值对保存到当前hash中
/**
* 将一对键值对保存到当前hash中
* @param key
* @param val
* @return 若key存在,此时修改原来键值对,返回修改前的元素
*/
public int put(int key, int val) {
//1.先对Key值取模
int index = hash(key);
//2.遍历这个index对应的链表,查看key是否存在
for (Node x = hashTable[index]; x != null; x = x.next) {
if (x.key == key) {
int oldVal = x.value;
x.value = val;
return oldVal;
}
}
//3.此时连表中不包含相应的key值节点。头插到当前位置
Node node = new Node(key,val);
node.next = hashTable[index];
hashTable[index] = node;
size ++;
return val;
}
2.扩容
采用整表扩容的方式
冲突严重时需要进行扩容,那么如何知道哈希表冲突是否严重呢?
负载因子
负载因子 loadFactor = 哈希表的有效元素个数 / 哈希表长度

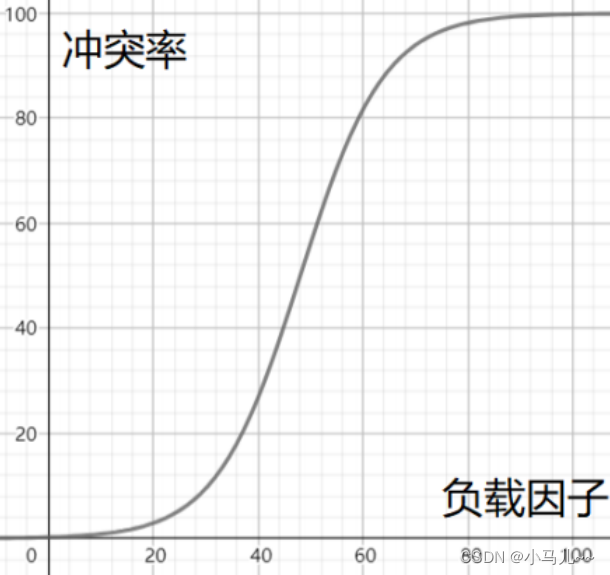
扩容与否就根据负载因子来决定
数组长度 * 负载因子 <= 有效元素个数就需要扩容
负载因子就是在空间和时间之间取平衡,负载因子选择需要根据现实的需求去进行实验
JDKHashMap的默认负载因子是0.75
阿里实验数据所得负载因子为10
/**
* 哈希表的扩容方法,新数组增加一倍
*/
private void resize() {
//1.产生一个新数组长度为二倍
Node[] newTable = new Node[hashTable.length << 1];
//2.进行原数组的搬移工作,将原数组中的所有元素搬移到新数组中
//此时取模应为新数组长度
this.M = newTable.length;
//3.进行元素搬移
for (int i = 0; i < hashTable.length; i++) {
for (Node x = hashTable[i]; x != null;) {
Node next = x.next;
//将x搬移到新数组的位置
int index = hash(x.key);
//新数组头插
x.next = newTable[index];
newTable[index] = x;
//继续搬移原数组的后继节点
x = next;
}
}
hashTable = newTable;
}
3.哈希表的实现
public class MyHashMap {
//有效节点个数
private int size;
//实际存储元素的Node数组
private Node[] hashTable;
//取模数
private int M;
//负载因子
private static final double LOAD_FACTOR = 0.75;
public MyHashMap() {
this(16);
}
public MyHashMap(int init) {
this.hashTable = new Node[init];
this.M = init;
}
/**
* 对Key值求哈希
* @param key
* @return
*/
public int hash(int key) {
return Math.abs(key) % M;
}
/**
* 将一对键值对保存到当前hash中
* @param key
* @param val
* @return 若key存在,此时修改原来键值对,返回修改前的元素
*/
public int put(int key, int val) {
//1.先对Key值取模
int index = hash(key);
//2.遍历这个index对应的链表,查看key是否存在
for (Node x = hashTable[index]; x != null; x = x.next) {
if (x.key == key) {
int oldVal = x.value;
x.value = val;
return oldVal;
}
}
//3.此时连表中不包含相应的key值节点。头插到当前位置
Node node = new Node(key,val);
node.next = hashTable[index];
hashTable[index] = node;
size ++;
//判断是否需要扩容
if (size >= hashTable.length * LOAD_FACTOR) {
resize();
}
return val;
}
/**
* 判断key值是否存在
* @param key
* @return
*/
public boolean containsKey(int key) {
int index = hash(key);
for (Node x = hashTable[index]; x != null; x = x.next) {
if (x.key == key) {
return true;
}
}
return false;
}
/**
* 判断value是否存在
* @param value
* @return
*/
public boolean containsValue(int value) {
//全表扫描
for (int i = 0; i < hashTable.length; i++) {
for (Node x = hashTable[i]; x != null; x = x.next){
if (x.value == value) {
return true;
}
}
}
return false;
}
/**
* 判断(key,value)是否存在
* @param key
* @param value
* @return
*/
public boolean contains(int key, int value) {
if (!containsKey(key)) {
return false;
}
int index = hash(key);
for (Node x = hashTable[index]; x != null; x = x.next){
if (x.value == value) {
return true;
}
}
return false;
}
/**
* 在哈希表中删除指定的键值对(key。value)
* @param key
* @param value
* @return
*/
public boolean remove(int key, int value) {
int index = hash(key);
//判断头结点是否是待删除节点
Node head = hashTable[index];
if (head.key == key && head.value == value) {
//此时头结点就是带删除节点
hashTable[index] = head.next;
head = head.next = null;
size --;
return true;
}
Node prev = head;
while (prev.next != null) {
if (prev.next.key == key && prev.next.value == value){
Node cur = prev.next;
prev.next = cur.next;
cur = cur.next = null;
size --;
return true;
}else {
prev = prev.next;
}
}
//没有要删除的节点
throw new NoSuchElementException("no such node! remove error");
}
/**
* 哈希表的扩容方法,新数组增加一倍
*/
private void resize() {
//1.产生一个新数组长度为二倍
Node[] newTable = new Node[hashTable.length << 1];
//2.进行原数组的搬移工作,将原数组中的所有元素搬移到新数组中
//此时取模应为新数组长度
this.M = newTable.length;
//3.进行元素搬移
for (int i = 0; i < hashTable.length; i++) {
for (Node x = hashTable[i]; x != null;) {
Node next = x.next;
//将x搬移到新数组的位置
int index = hash(x.key);
//新数组头插
x.next = newTable[index];
newTable[index] = x;
//继续搬移原数组的后继节点
x = next;
}
}
hashTable = newTable;
}
}
//当前哈希表保存的节点,key = value的键值对对象
class Node {
//对key进行哈希运算
int key;
int value;
//下一个节点地址
Node next;
public Node(int key, int val) {
this.key = key;
this.value = val;
}
}
is.M = newTable.length;
//3.进行元素搬移
for (int i = 0; i < hashTable.length; i++) {
for (Node x = hashTable[i]; x != null;) {
Node next = x.next;
//将x搬移到新数组的位置
int index = hash(x.key);
//新数组头插
x.next = newTable[index];
newTable[index] = x;
//继续搬移原数组的后继节点
x = next;
}
}
hashTable = newTable;
}
}
//当前哈希表保存的节点,key = value的键值对对象
class Node {
//对key进行哈希运算
int key;
int value;
//下一个节点地址
Node next;
public Node(int key, int val) {
this.key = key;
this.value = val;
}
}














 1521
1521











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









