






有些小伙伴发现了一个问题,那就是根据图片生成出来的视频看着怪怪的:

前半段看着好像还可以,但是后面部分的面部就开始崩坏了。
而今天这篇笔记则是要简单了解一下一些进阶参数以及一些文生图生视频的内容,不然的话我担心内容太少字数都凑不够。

我这里准备了
ComfyUI文字生成视频的工作流,需要的小伙伴可以直接扫码获取

进阶参数
像上篇文章直接关掉界面的话,ComfyUI会自动保存上次的工作流
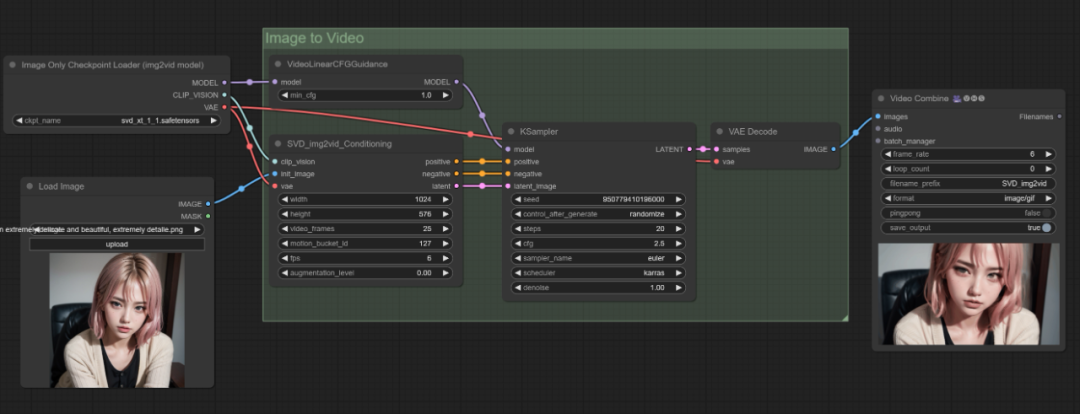
如果是重新打开没有的话,可以直接进入ComfyUI后将图生视频工作流直接拖动进去就好了(工作流文末下载链接)
而在整个页面最需要关注的参数部分就在这里:
而参数部分有三个地方需要重点关注:
**Motion Bucket ID
**
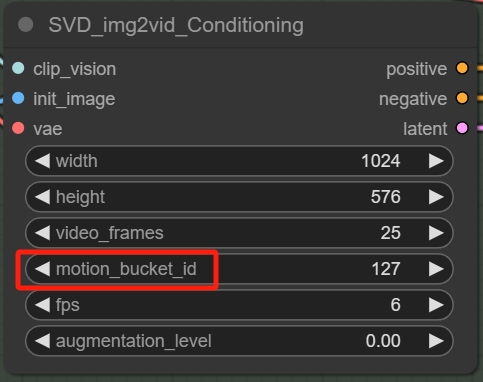
这个运动桶ID是SVD模型里最直观地控制视频运动幅度的参数,默认是127,数值范围从1-255,数值越大其运动幅度就越剧烈。
**运动桶ID:32
**

运动桶ID:255

这样进行对比还是可以看出来差距蛮明显的,如果觉得画面运动太过剧烈就降低这个数值,如果画面没什么变动就拉高这个数值。
**Min CFG & KSampler CFG
**
CFG全称是无分类器指导(Classifier Free Guidance)和图像绘制中的一样,这个CFG控制绘制内容与条件的相关性:
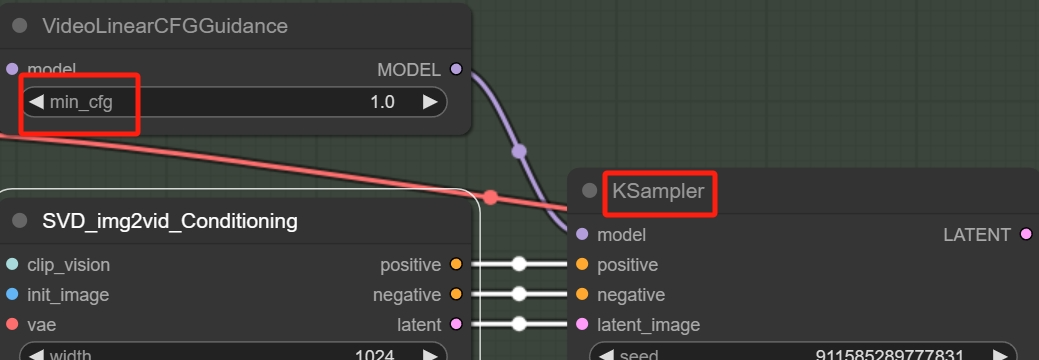
这里会看到有两个数值,是因为SVD采用了随帧数“动态”控制CFG的思路。
在绘制第一帧内容的时候应用最小值,然后逐渐增大,到最后一帧时变成KSampler里的CFG(最终):
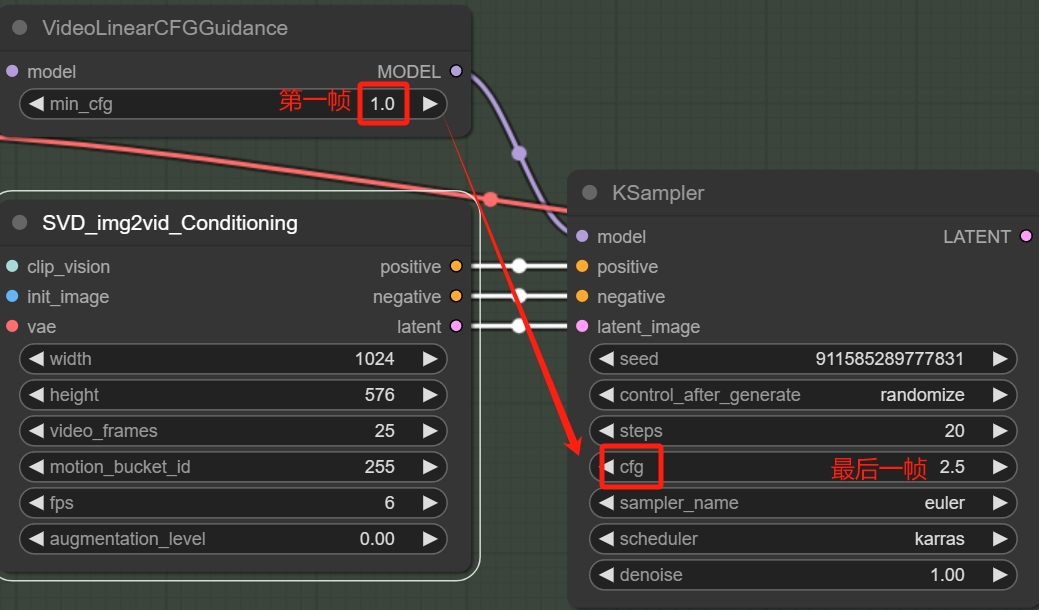
这样的变化可以帮助系统适应不断变化的画面,而官方解释其作用是可以帮助视频保持原始图像的“忠诚度”。这个数值变低了的话画面会更加“自由发挥”,数值高了画面会更加稳定,CFG的正常区间在1.5-3之间。
而根据原教程up测试可以得出其数值不会影响大的运动构成,但是会影响运动推导的“细节”,就是可能让画面变“糊”,这里适当增加Min CFG或最终CFG即可。
**Augmentation Level
**
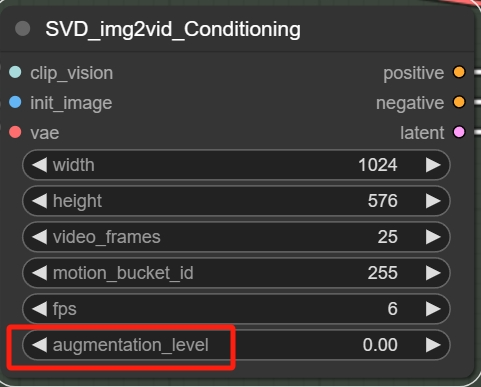
这个增强水平直接理解就是添加到图片中的噪声量,这个数值越高,视频与初始帧的差异就越大,增加这个数值也可以增加画面的运动。
但是这个参数对数值很敏感,一般不超过1。多数时候保持默认参数,但是当在使用与默认尺寸(1024*768)不同的视频尺寸时,最好把这个数值增加到0.2-0.3,否则画面会有很大概率是错乱的。

这样改一些参数之后所生成的画面就稳定多了
文生图生视频
在完成了简单的图生视频之后就可以进行我们学习Stable Diffusion时最开始接触的文生图。
在经历了这么多篇文章之后其实很多小伙伴对文生图的步骤已经非常熟悉了,即便是第一次接触Stable Diffusion的小伙伴看到这篇文章也可以跟随我下面的操作进行文生图生视频。
在之前的WebUI中都是先进行文生图,然后丢到诸如EbSynth等视频生成扩展中将图片加载为视频。
但是ComfyUI中可以有一套完整的从文生图再到图生视频的工作流程:

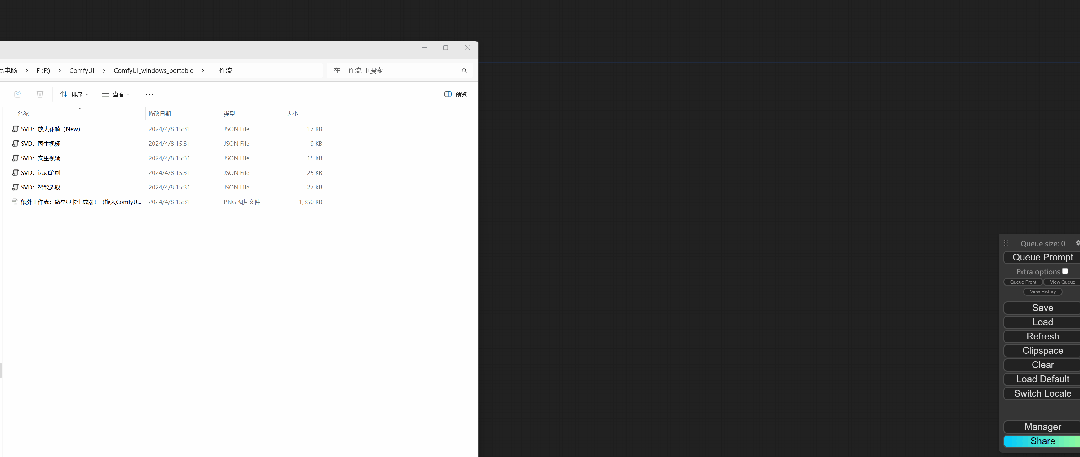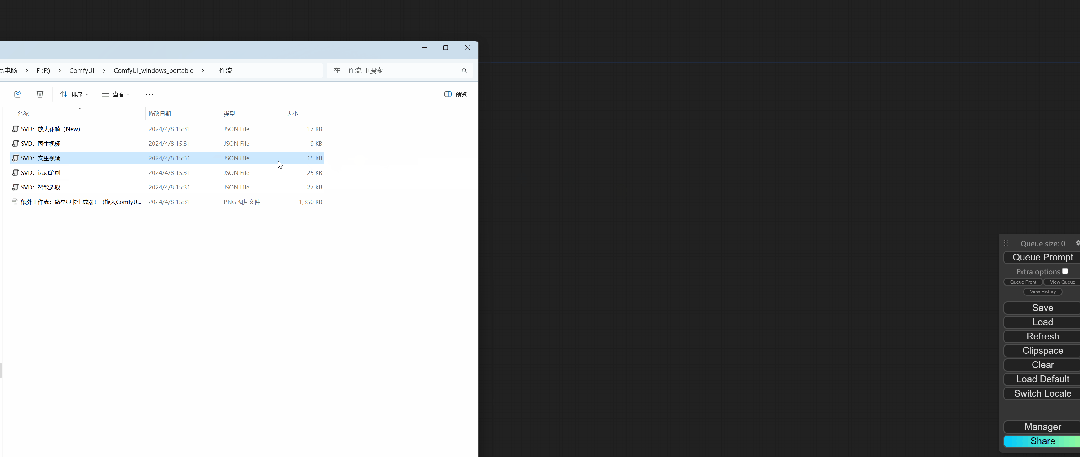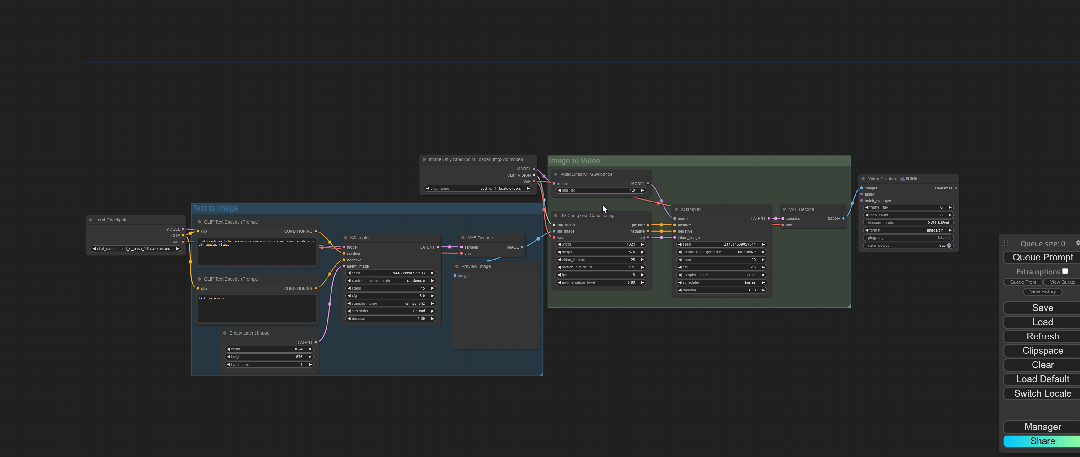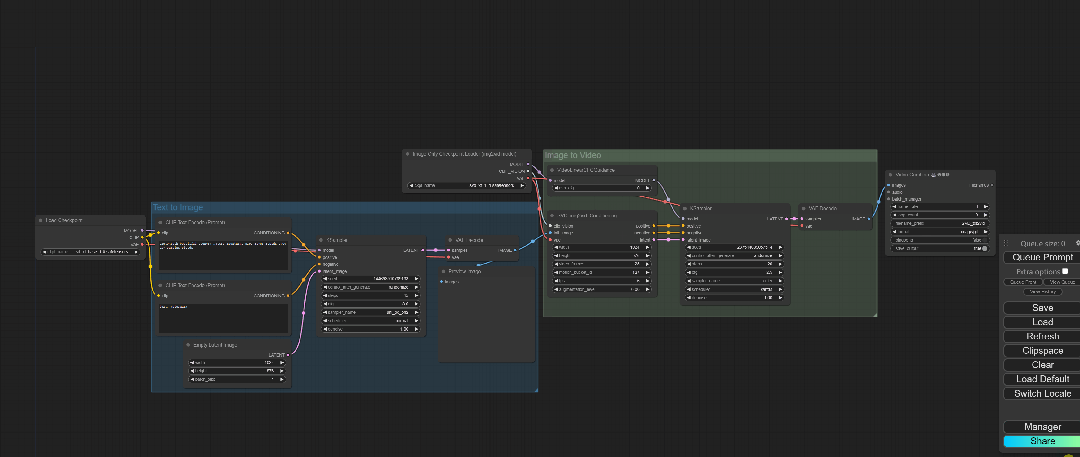
这个工作流的下载链接我会放在文末,直接拖拽进ComfyUI即可。
整个流程其实还是很简单的,就是在我们刚刚图生视频前面多了一个文生图的节点组合,接下来就一个方块一个方块进行操作。
模型加载
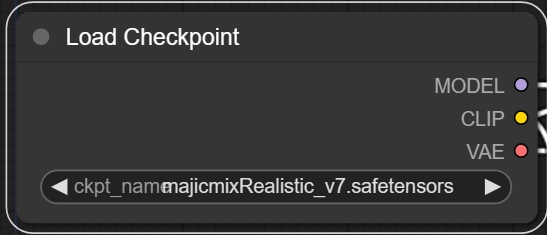
在最左边有一个Load Checkpoint的节点,这里是加载要使用的绘图大模型,无论是SD1.5还是SDXL的都可以。
提示词
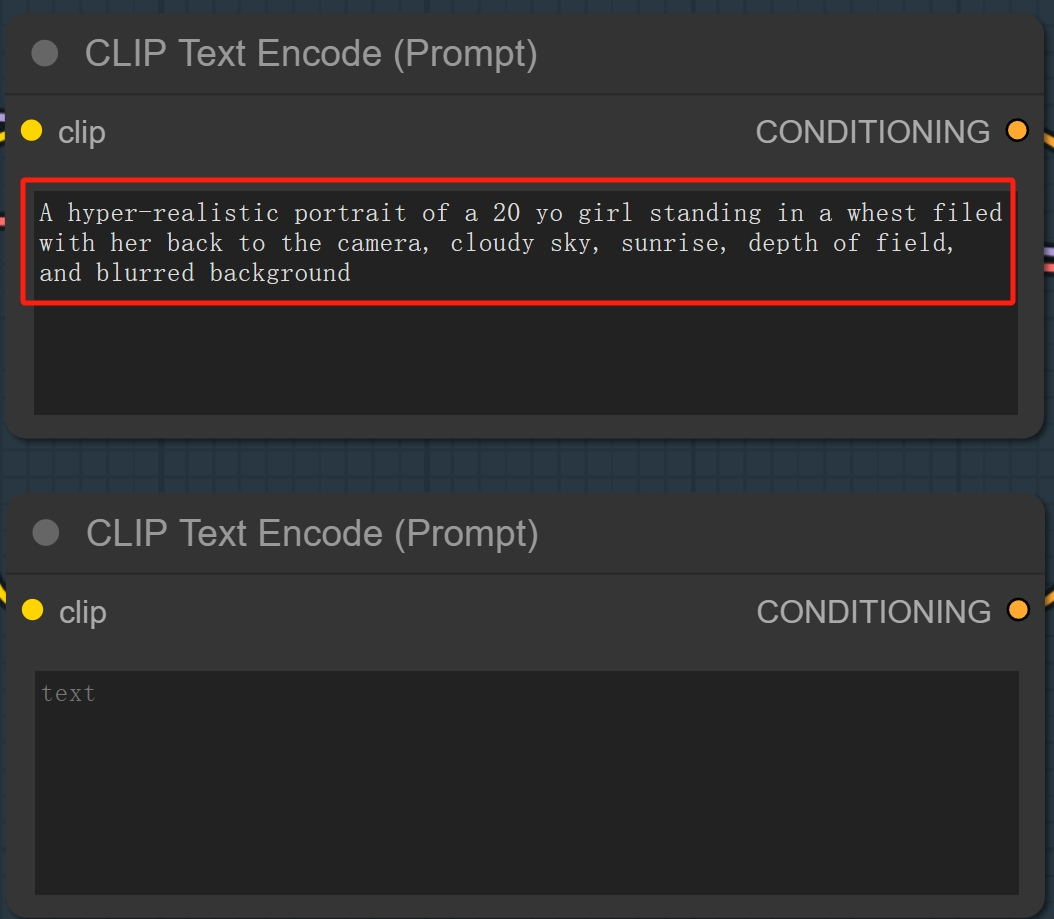
接下来来到文本编码器部分,在上方的文本框中输入自己想要的提示词,当然也可以参考原视频up主提供的:
A hyper-realistic portrait of a 20 yo girl standing in a whest filed with her back to the camera, cloudy sky, sunrise, depth of field, and blurred background
生成
接下来在右侧的绿色部分进行简单的参数调整(也可以先默认)后直接点击添加提示词队列Queue Prompt
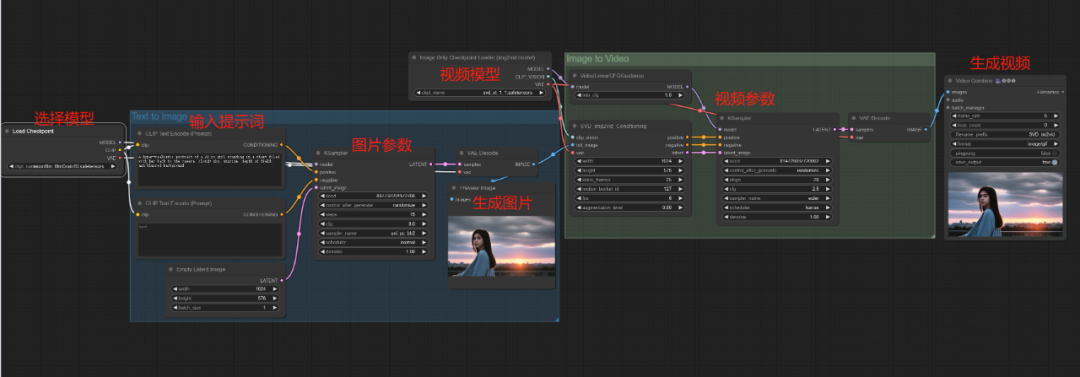
这样就是一个简单明了从左到右的文生图生视频流程。
SVD就是这么简单好用,AI视频模型的训练就是投喂大量的视频让AI学习视频在不同的时间节点上的静态帧差异,久而久之视频的“动态/运动规律”在AI眼里变得有迹可循。
这样一来给AI输入一个图片,AI就可以去“预测”接下来一段时间内AI会发生的画面运动。所以一个视频最终呈现出来的是什么样的,很大程度上取决于最开始的图片。
今天的内容就到这里啦!

(((masterpiece))), (((best quality))), (((full body))), (((motion blur))), (((spiral lines))), ((grand ice skating exhibition)), (((raise leg))), (((raise skates))), (((white beige see through floral print lace dress))), ((sleeves)), cinematic light, countless crowd, wind, night, solo, 1girl, sweat, ((wet body)), (((black hair))), ((very long hair)), ponytail, ribbon, high neck, collar, enjoy, shy, blush, (((petite figure))), (((face towards the sky))), ((hair flows upwards)), lora:girllikeflyingspin:0.8
Negative prompt: (worst quality:2.0), (low quality:2.0), (((normal quality))), (((multiple arms:1.2))), (((multiple legs:1.2))), (((multiple views))), multiple hands, multiple feet, easynegative, lowres, bad-hand-5, badhandv4, bad_prompt_version2-neg, discontinuous background, badly drawn hands, bad anatomy, bad proportions, 2girls, 3girls, inaccurate limb, twisted limb, malformed limb, inaccurate body, twisted body, malformed body, cropped, error, fat, ugly, flat chest,
-
Steps: 30
-
Sampler: Euler a
-
CFG scale: 7
-
Seed: 132126053
-
Size: 512x512
-
Model hash: 7c819b6d13
-
Model: majicmixRealistic_v7
-
Denoising strength: 0.7
-
Clip skip: 2
-
ENSD: 31337
-
Hires upscale: 2
-
Hires upscaler: R-ESRGAN 4x+
-
Version: v1.8.0
问题汇总:
在有些小伙伴安装好ComfyUI之后将工作流程拖到界面时可能会遇到这样一个提示:
ComfyUI web interface:
“When loading the graph, the following node types were not found:
VHS_VideoCombine
Nodes that have failed to load will show as red on the graph.”
而这里要解决也很简单,只需要跟随着我的步骤:首先要关闭整个ComfyUI,然后找到ComfyUI的根目录:
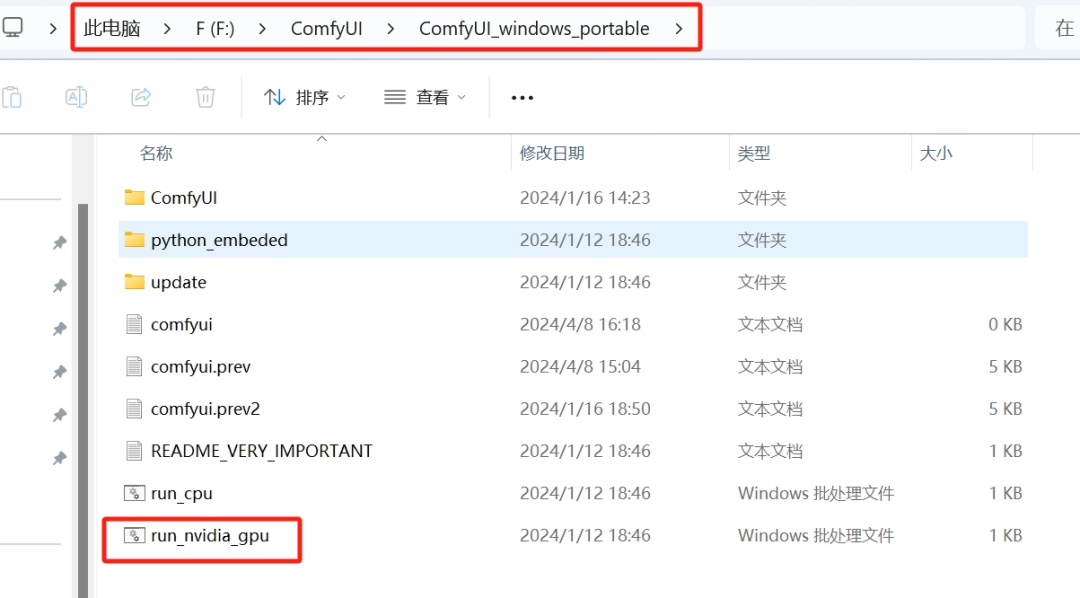
也就是有着启动选项的这个地方,在这里将上方的路径双击后输入CMD。
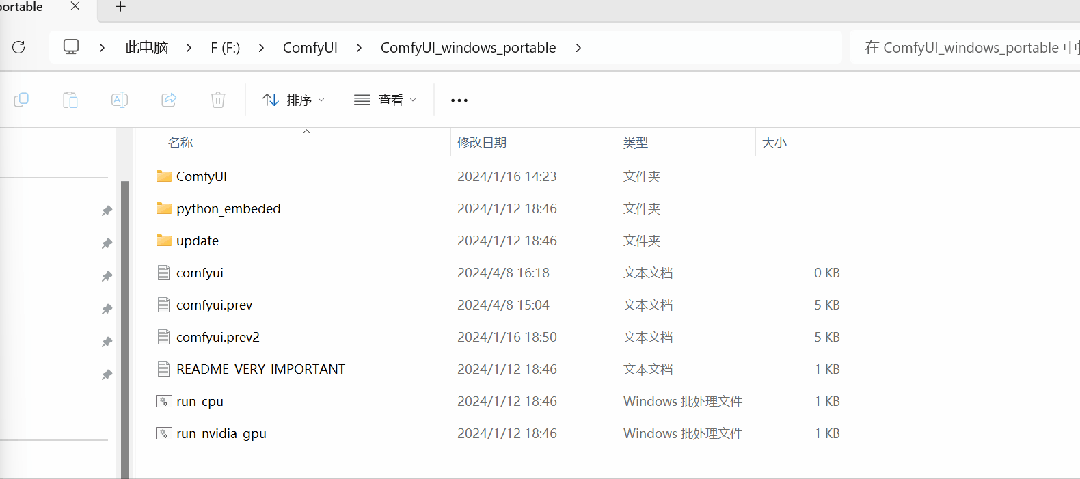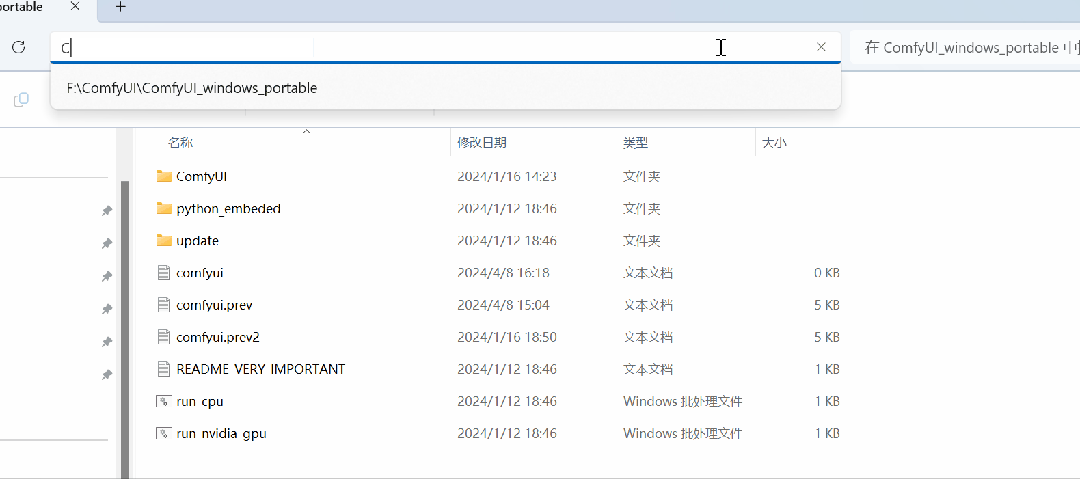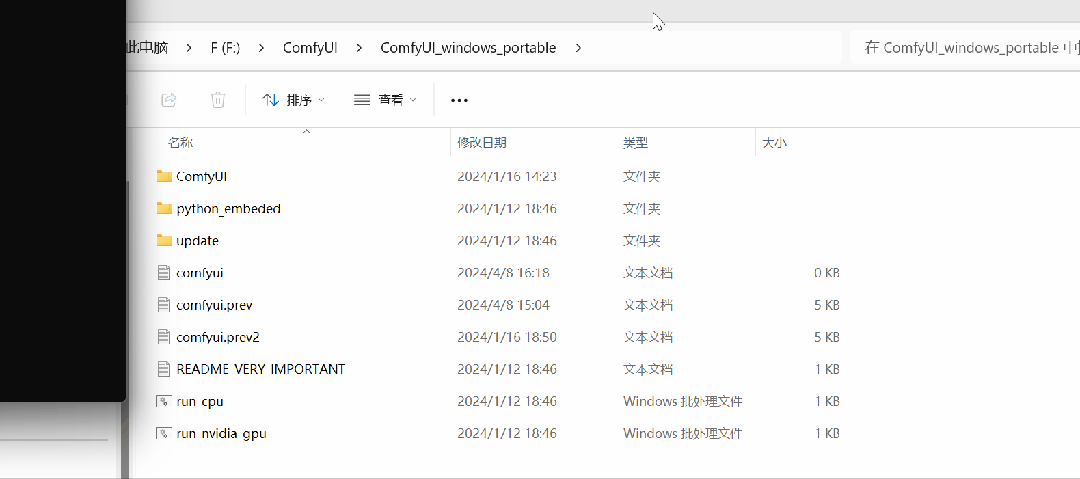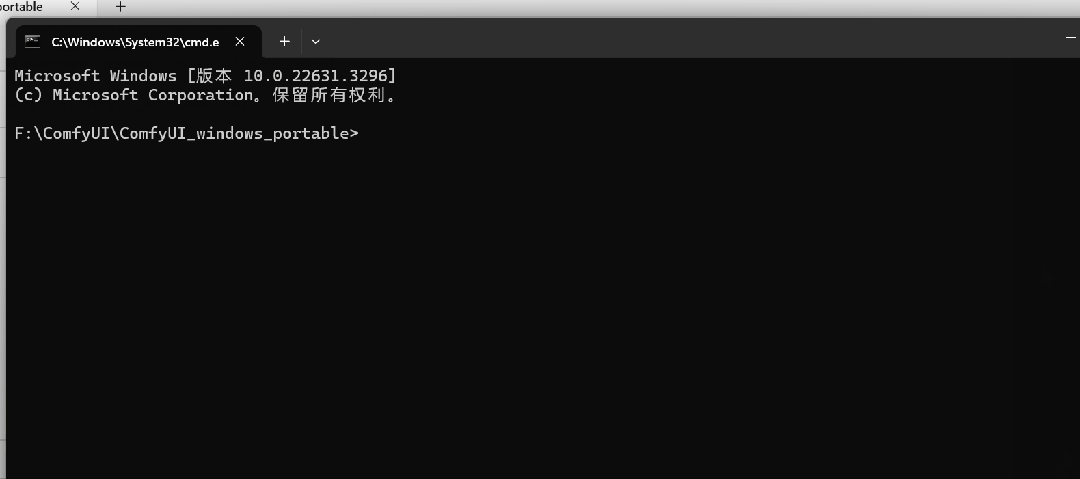
就会有着这么个界面出现:
在这里面分别输入两行代码,先输入这一行:
python_embeded\python.exe -m pip uninstall -y opencv-python opencv-contrib-python opencv-python-headless
然后按回车,在运行完毕后再输入第二行:
**python_embeded\python.exe -m pip install opencv-python==**4.7.0.72
之后按回车,等待一小会后就能看到这样的界面:
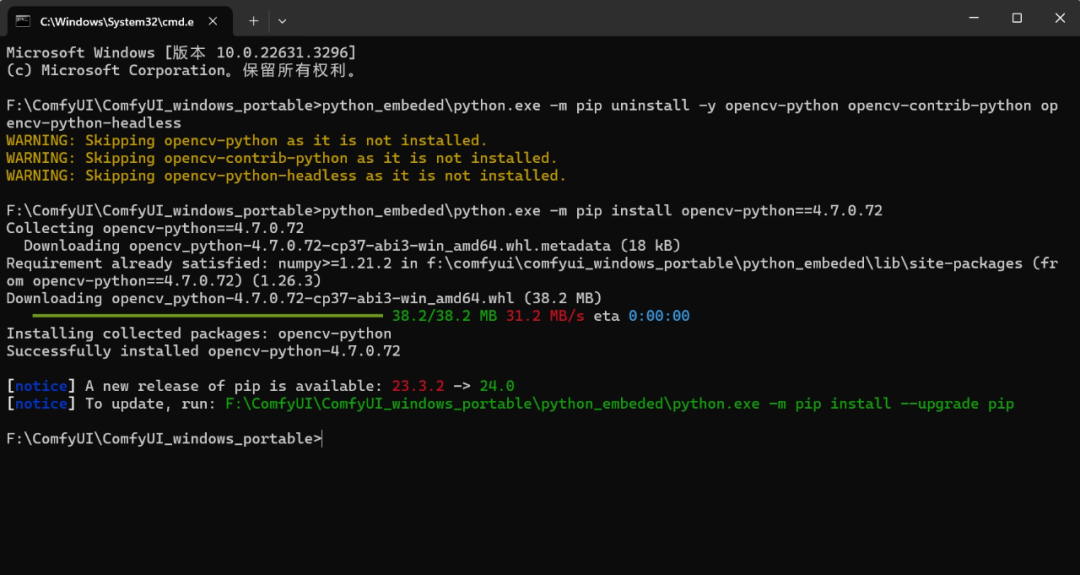
然后重启ComfyUI问题就解决了!
写在最后
感兴趣的小伙伴,赠送全套AIGC学习资料,包含AI绘画、AI人工智能等前沿科技教程和软件工具,具体看这里。

AIGC技术的未来发展前景广阔,随着人工智能技术的不断发展,AIGC技术也将不断提高。未来,AIGC技术将在游戏和计算领域得到更广泛的应用,使游戏和计算系统具有更高效、更智能、更灵活的特性。同时,AIGC技术也将与人工智能技术紧密结合,在更多的领域得到广泛应用,对程序员来说影响至关重要。未来,AIGC技术将继续得到提高,同时也将与人工智能技术紧密结合,在更多的领域得到广泛应用。

一、AIGC所有方向的学习路线
AIGC所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、AIGC必备工具
工具都帮大家整理好了,安装就可直接上手!

三、最新AIGC学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。


四、AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

 若有侵权,请联系删除
若有侵权,请联系删除















 1393
1393

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









