






一.集合
1.集合体系图
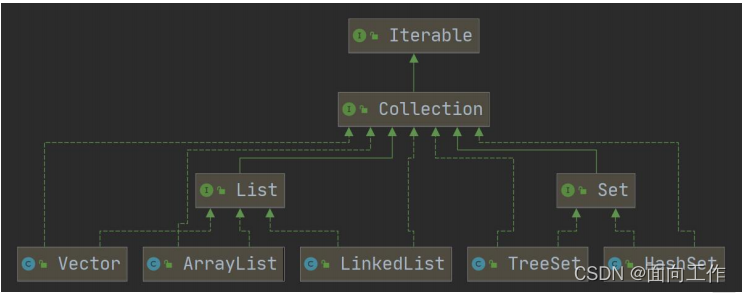
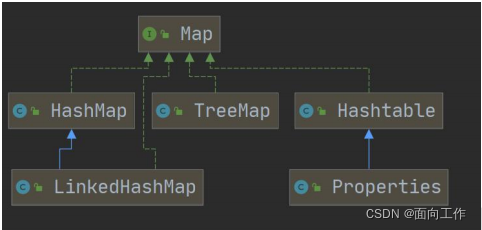
2.集合主要有两种(单列集合和双列集合)
3.Collection接口有两个重要的子接口List和Set,他们的实现子类都是单列集合.
3.Map接口的实现子类是双列集合,存放的k-v.
4.List集合:
(1)List集合是有序的并且元素可以重复
(2)List集合中每个元素都有其索引值,即支持索引.
(4)collection集合的遍历: collection的实现类中都有一个iterator方法,用于返回实现了iterator的对象,该对象也被成为迭代器.
(5)list接口主要方法: (除了继承collection接口的方法,也就是list特有的一些方法)
(1)void add(int index, Eelement):在指定位置插入元素,后面的元素都往后移一个元素
(3)boolean addAll(int index,Collection col):在指定的位置中插入c集合全部的元素,如果集合发生改变,则返回true,否则返回false。意思就是当插入的集合c没有元素,那么就返回false,如果集合c有元素,插入成功,那么就返回true。
(4)Object get(int index): 返回指定位置的元素.如果下标超出集合范围,会抛异常.
(5)int indexOf(Object obj):返回 obj 在集合中首次出现的位置,这里面判断是否为该元素时是通过obj.equals()来判断的.
(6)int lastIndexOf(Object obj):返回 obj 在当前集合中末次出现的位置,原理同上
(7)Object remove(int index):移除指定 index 位置的元素,并返回此元素.
(8)Object set(int index, Object ele):设置指定 index 位置的元素为 ele , 相当于是替换.
(9)List subList(int fromIndex, int toIndex):返回从 fromIndex 到 toIndex 位置的子集合,注意返回的子集合 fromIndex <= subList < toIndex
(6) ArrayList集合的扩容机制:
(1)第一步:创建一个ArrayList集合,如果是无参构造或者是调用有参构造但是参数为0,那么ArrayList类中的数组会初始化一个size=0的数组。也就是空数组.如果调用的有参构造但是参数大于0,则数组会初始化一个size为传入参数的数组.
(2) 第二步: 添加元素, 首先会判断是否是第一次添加(通过判断当前数组是否为空数组), 如果是第一次添加,并且添加的元素个数小于默认容量10时,则将数组需要的大小设为10,如果添加的元素个数大于默认容量时,则将数组需要的大小设为要添加的元素个数.
(3) 第三部: 得到数组需要的大小后, 要讲数组需要的大小与目前大小比较,如果目前数组大小不够需要的数组大小,则进行扩容,扩容为(目前大小+目前大小/2),如果扩容以后的大小仍然不够需要的大小,则直接将数组扩容到需要的大小,
(7)Vector: 和ArrayList几乎相同,只是Vector是线程安全的(加了synchronized),效率比较低.
(8)Vector扩容机制:
(1) 第一步: 创建一个Vector集合,如果是无参构造则内部数组直接初始化一个size=10的数组,有参构造则初始化一个size为传入的参数大小的数组.
(2)第二步: 添加元素,判断添加后的元素个数是否比当前数组的长度大,如果大,则进行扩容,默认就是扩容至原数组长度的的两倍.如果扩容后的大小还是不够添加后的元素个数,则会直接扩容至大小为添加后元素的个数.
(3) 注意:创建Vector集合时,可以指定该数组每次扩容的增量.
(9)LinkedList:底层是一个双向链表,双向链表中增删时不用像数组一样需要移动元素,所以增删效率比较高,但是查找效率比较低.
(10)List集合的遍历方式:
(1) 通过元素的索引遍历。
for (int i = 0; i < list.size(); i++) {
System.out.print(list.get(i) + ",");
}(2) 通过迭代器遍历 注意:遍历过程中不能进行集合的修改和删除。
Iterator iterator = list.iterator();
while (iterator.hasNext()) {
System.out.print(iterator.next() + ",");
}(3) 通过增强for循环 注意:其实也是使用的迭代器
for (Integer i : list) {
System.out.print(i + ",");
}注意: for循环是使用迭代器实现的遍历,所以里面也不能直接使用集合的移出元素的方法。
5.Set集合
(1) Set集合是无序且不能重复的,其中的重复是根据对象的equals值来比较的.
(2)Set集合的遍历:
(1)使用迭代器
Iterator iterator = set.iterator();
while (iterator.hasNext()) {
Object obj = iterator.next();
System.out.println("obj=" + obj);
}(2)使用增强for循环
for (Object o : set) {
System.out.println("o=" + o);
}(3)HashSet的底层是HashMap,HashMap的底层是哈希表(数组+链表+红黑树)
(4)HashSet添加数据时的思路:

(6)我们知道HashMap的底层是和哈希表(数组+链表+红黑树),要想弄懂HashMap的原理,必须先知道哈希表这个数据结构,哈希表这个数据结构可以通过(数组+链表)实现,其主要的思想就是让不同的值放在同一个数组下标的位置,而同一个数组下标的位置用链表来存储多个不同的值,那么怎么让不同的值或者对象放在同一个数组下标呢,这就要使用一种规则,这个规则其实就是一个函数,我们称它为哈希函数,而通过这个函数我们得到的值就叫做哈希值,这个哈希值就是我们对应的下标索引。知道了哈希表数据结构的思想之后我们再来看看HashMap是如何通过哈希表这种数据结构来存储数据的。对于对象,我们是通过equals来判断对象是否相同,通过hascode来得到一个对象的哈希值,我们要想使用哈希表这种数据结构,就得保证equals对应唯一的hascode,而一个hascode对应不同的equals,所以重写equals时要重写hascode来保证这个。然后我们将元素放在了哈希表这种数据结构中后,我们可以看出,不同的对象(equals判断)可能会在一个位置,而相同的对象肯定在一个位置。但是,HashMap它要求不能放置重复的元素(equals判断的),所以我们在添加元素时,要判断当前数组下标位置的链表是否有和自己相同的元素,但是这样判断效率比较低,所以hashMap底层采用了一种方法来优化,我们之前说的将hash值当成数组下标,但是hashmap将hash值又通过一种哈希函数得到了一个hash值,将这个hash值作为数组下标,这时同一个下标位置,存放的值的hash值也可能不同了,我们就可以判断这个hash值是否相同,这个hash值如果相同,那么就再用equals判断一下,如果hash不同,那么equasl肯定不同了。
(7).HashSet的扩容机制和转换为红黑树.

(7)LinkedHashSet: 是HashSet的子类,它的底层是LinkedHashMap(是HashMap的子类)
(8) LinkedHashMap底层结构是 数组+双向链表.
















 331
331











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











