






今天好好梳理一下集合的内容
java中集合一共有两大类: Collection 和 Map
一.Collection集合
我们首先来看一下Collection这个集合,首先它是一个接口,规定了实现类要实现的方法:结构如下:
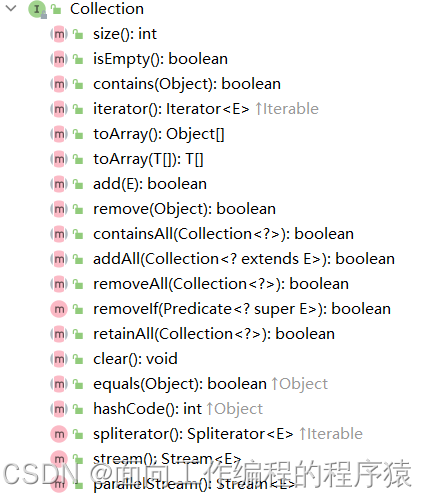
Collection下面有List接口和Set接口继承了Collection,同时也有它们自己独有的方法。
List接口(独有的)

List接口被 ArrayList 和 LinkedList 实现。除了实现以上的方法外,还有一个内部类,叫做Itr ,它实现了一个叫做Iterator的接口。所以在实现Collection接口中iterator()这个方法时,就是创建一个Itr对象然后返回这个对象.这对象也就是我们所说的迭代器.
ArryList是内部有一个Object类型数组的成员变量,用来存放集合中的元素。
LinkedList是内部有一个链表来存储集合中的元素。
ArrayList使用步骤
第一步: 首先创建一个ArrayList数组, ArrayList一共有三个构造方法,一个是无参, 一个是传入一个容量, 一个是传入一个Collection集合. 当无参或者传入一个容量但是容量为0或者传入一个集合但是集合的长度为0时, ArrayList中的数组会初始化为一个空数组.如果是调用的参数为容量的构造方法并且传入的容量大于0时,会将ArrarList中的数组初始化为一个长度为传入的那个值得数组. 如果调用的是参数为集合的构造方法,并且集合中元素个数不为0,那么ArrayList中的那个数组初始化为一个数组,数组中的元素为传入集合的元素,并且长度和集合的元素个数相同.
第二步: 让集合中放入值,放入值后,会将放入值后的长度大小赋给一个变量.然后会判断当前集合中的数组是否为空数组,如果为空数组,则会扩容到(默认大小10和放入值后需要的大小)两者中值大的那个.然后会判断要扩容到的长度是否比当前数组长度大,如果大则进行扩容,扩容规则为(当前数组长度+当前数组长度/2),然后判断扩容后是否比需要的长度大,如果没有,则直接扩容到需要的长度.
LinkdeList是用的链表存储的,不需要扩容,所以它的使用简单,当放入一个元素时,会创建一个node节点,然后将该节点放在链表的末尾.
ArrayList底层是数组实现,所以查询效率高,增删效率低.
LinkdeList底层是链表实现,所以增删效率高,查询效率低.
Set接口 (独有的)
无.也就是Set接口继承了Collection接口,但是自身没有增加自己独有的方法.
Set接口的主要实现类有两个: HashSet 和 TreeSet .
HashSet: HashSet中有一个HashMap集合的属性, 而HashMap集合是通过数组+链表+红黑树实现的.
HashMap中数组存放的其实是Node对象,这个Node对象是HashMap中的一个内部类,这个Node类实现了一个Entry接口,这个接口是Map接口中的内部接口. Node类中有两个属性, 一个是key ,一个是value, 当我们往HashSet放入一个元素时,他会创建一个Node对象,然后把放入的元素赋给Node的key属性,然后放在HashMap内部的数组中.
HashSet的扩容机制: (jdk8中):当链表中元素的个数达到8,同时数组中的个数超过64时,就会进化成红黑树(进一步提高查询效率)。 注:若链表中元素的个数到8,而数组未到64,则按数组容量*2进行扩容,直到扩容到64,再树化。 (第一次添加数据时,数组会扩容到16的大小,当集合中元素个数达到12个就会进行一次扩容)
LinkedHashSet是HashSet的子类,它的底层是LinkedHashMap,LinkedHashMao是HashMap的子类,是通过数组+双向链表+红黑树实现的.
二.Map集合
Map是一个接口,规定了它的实现类要实现的方法。结构如下:

Map的实现类主要有三种: HashMap,Hashtable ,TreeMap。
HashMap:在HashSet中其实我们已经说过这个集合,不一样的地方是,我们在HashSet中添加一个元素时,是创建一个Node对象,然后把元素赋给Node对象中的key属性,而在HashMap中的Node对象其实还有一个value属性,使用HashMap添加元素时我们不是添加一个元素,而是添加两个元素,一个赋给key一个赋给value,而且还有一点不同的是,HashMap集合使用时,会将创建的Node对象放在一个EntrySet集合中,EntrySet是HashMap中的一个内部类,在遍历Map集合时可以获取到这个entryset对象,然后将遍历里面的Node,通过Node可以获取到里面的key和value。
扩容机制和HashSet相同。
HashTable:底层是数组+链表,它是线程安全的,并且初始大小为11,每次扩容为size*2+1
hashtable的key和value都不能为null,
TreeMap: 底层是红黑树,判断是否相等是根据传入的Comparator比较器进行比较的,key值不能为null,而且可以排序,
TreeSet 底层是TreeMap, 元素不能为null,
三.多线程
1.进程是程序的一个实例,就是运行着的程序,是计算机进行资源分配和调度的最小单位
2.线程:进程中的实际运作单位,是计算机进行运算调度的最小单位.
3.并发: 一个cpu同时执行多个线程任务,但是并不是在同一时间,是cpu不断切换这执行.
4.并行:多个cpu同时执行多个任务,是真正意义上的同一时间执行多个线程.
5.java创建线程的方法:
(1)继承Thread类,重写run()方法.
class Thread1 extends Thread{
@Override
public void run() {
System.out.println("创建了一个线程");
}
}(2)实现Runnable接口,然后传给Thread,
class Runnable1 implements Runnable{
@Override
public void run() {
System.out.println("创建了一个线程");
}
public static void main(String[] args) {
Thread thread=new Thread(new Runnable1());
thread.start();
}
}(3)使用Callable和Future创建线程
public static void main(String[] args) {
Callable callable=new Callable() {
@Override
public String call() throws Exception {
System.out.println("线程执行了");
return "string";
}
};
FutureTask futureTask=new FutureTask(callable);
Thread thread = new Thread(futureTask);
thread.start();
try {
String str=(String)futureTask.get();
System.out.println(str);
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}(4)线程常用方法:
(1)setName():为该线程设置一个名字。
(2)getName(): 得到线程的名字
(3)start(): 启动线程
(4)run(); 线程要执行的任务方法
(5)setPriority() 设置线程优先级
(6)getPriority() 得到线程优先级
(7) sleep( ) 静态方法,让当前线程进行休眠,不再获取cpu时间片,如果持有锁不会释放锁.
(8)interrupt( ) 中断线程,其实是设置中断标记为true,会中断处于阻塞线程(sleep(),wait(), join()),阻塞中的线程被中断后会抛出异常并且清除打断标记,
interrupt也可以中断正常运行的线程,只不过此时需要我们自己来处理中断后要干什么(通过判断打断标记的状态)
(9)yield():让出时间片,自己重新进入可运行状态,不会释放持有的锁. (自己也有可能再次获取到时间片,具体要看cpu如何划分时间片)
(10)join(): 让当前线程等待其他线程执行完毕自己再执行,join原理是:获取当前线程对象的锁,然后wait(),线程执行完后会唤醒。
public static void main(String[] args) {
Object p=new Object();
Thread thread1=new Thread(){
@Override
public void run() {
System.out.println("线程执行");
}
};
thread1.start();
try {
thread1.join(); //相当于当前主线程获取了thread1线程对象的锁,然后进行wait(),当thread1线程执行完后会唤醒,然后主线程再执行
} catch (InterruptedException e) {
e.printStackTrace();
}
}6.互斥锁
(1)用户线程:也叫做工作线程,只有所有用户线程都结束了,程序才会结束。
(2)守护线程: 只要所有用户线程都结束,守护线程就算没有执行完毕也会直接结束。
我们创建的线程默认为用户线程,如果想让一个线程作为守护线程,可以用
线程对象.setDaemo(true) 即可.
7.线程的状态:
从操作系统来说,有5种状态: (1)新建 (2)就绪 (3) 运行 (4) 阻塞 (5) 死亡
从java的枚举类型: (1)NEW (2)Runnable (3)TimedWaiting (4)Waiting (5)Blocked (6) Teminated
其中Runnable由分为 Ready 和 Running 状态。
8.同步和异步通常用来形容方法的调用,同步就是调用方法后,调用方必须等待方法执行结束才能继续往下执行,异步就是可以再调用方法后可以继续往下执行。我们平常用的方法都是同步的,但是使用多线程可以实现异步,但是有时候我们一些共享资源比较敏感,需要多个线程同步执行,则可以使用互斥锁来实现,
9.java中使用一种synchronize关键字来实现互斥锁,即给一个对象加上锁,我们将需要同步的代码称为临界区,我们让多个线程中在执行临界区代码前要获取锁,而这个锁只有一把,谁先获取谁就执行,其他没有获得锁的线程就陷入阻塞,当锁释放之后,会唤醒这些进入阻塞的线程重新竞争这把锁。
public static void main(String[] args) {
Object lock=new Object();
synchronized (lock){
System.out.println("获取了锁");
}
}10.synchronize可以加在代码块上,后面加上对象,表示给这个对象加上锁。
也可以加在实例方法上,表示给当前对象加上锁,
也可以加在静态方法上,表示给整个类的所有对象加锁。
11.线程死锁:
多个线程占用了对方的锁资源,这就会导致死锁。
比如现在有两个对象A, B
有两个线程t1 , t2
t1先获取A的锁然后获取B的锁, t2获取B的锁然后获取A的锁。
t1获取A的锁后获取B的锁之前,t2获取了B的锁,此时它要去获取A的锁,但是A的锁已经被t1占了,t1也要去获取B的锁,此时B的锁被t2拿了,两个线程就都陷入了阻塞。
public static void main(String[] args) {
Object A=new Object();
Object B=new Object();
Thread t1=new Thread(){
@Override
public void run() {
synchronized (A){
System.out.println("获取了对象A的锁");
synchronized (B){
System.out.println("获取了对象B的锁");
}
}
}
};
Thread t2=new Thread(){
@Override
public void run() {
synchronized (B){
System.out.println("获取了对象B的锁");
synchronized (A){
System.out.println("获取了对象A的锁");
}
}
}
};
t1.start();
t2.start();
}四.io流
1.输入和输出: 输入和输出是相当于内存来说的,从硬盘中读取文件到内存中,是输入流,从内存中写数据到硬盘是输出流.
2.io流分为输入流和输出流, 同时也分为字节流和字符流
3.四大流家族: InputStream (字节输入流) OutPutStream (字节输出流) Reader(字符输入流)
Writer(字符输出流) 这些类都是抽象类,使用时要创建实现子类来使用.
4. 这四个流都实现了Closeable接口, 所以都实现了接口中的close方法
5. 输入流都实现了Flushable接口,所以都实现了接口中的flush方法.
6.InputStream: 字节输入流
(1)常用子类:
FileInputStream: 文件输入流
BufferedInputStream: 缓冲字节流
ObjectInputStream: 对象字节输入流.
关系图:

7.OutputStream:字节输出流
(1)常用子类:
FileOutStream 文件字节输出流
BufferedOutputStream:缓冲字节输出流
ObjectOutputStream: 对象字节输出流
8.FileInputStream: 文件字节输入流
(1)使用方式:
public static void main(String[] args){
try {
InputStream file=new FileInputStream("文件路径");
} catch (FileNotFoundException e) {
e.printStackTrace();
}
}注意:文件路径可以是绝对路径和相对路径,绝对路径就是从盘符开始,相对路径idea中是从该项目Project的根路径开始。
读取字节的方法: (1)read() : 读取一个字节,返回值为int类型.方法执行一次后,再次调用会读取下一个字节,当文件没有字节时,读取的是-1.
(2) read(byte[]): 读取所有字节并放入传入的字节数组中,返回值为读取到的字节个数.
(3) close(): 关闭流,防止资源浪费.
(4) available(): 返回还剩下未读的字节数量.
(5) skip(int): 跳过指定的字节数,经过这个方法后,再读取会从跳过去之后的字节开始读.
9.FileOutputStream: 文件字节输出流:
(1)使用方式:
public static void main(String[] args){
try {
OutputStream outputStream=new FileOutputStream("文件路径",true);// 如果后面那个参数为true,表示写入的内容是追加到文件的后面,false,则是覆盖。
} catch (FileNotFoundException e) {
e.printStackTrace();
}
}写入字节的方法:
(1)write(int) :将一个字节写入文件。由于char可以自动转型为int,所以也可以直接传入字符。
(2)write(byte[]): 讲一个字节数组写入文件。
(3) write( byte[], int off, int len): 将字节数组从off下标开始,len长度的字节写入文件.
10.FileReader: 字符输入流
继承关系:
使用方法:
public static void main(String[] args){
try {
Reader reader=new FileReader("文件路径");
} catch (Exception e) {
e.printStackTrace();
}
}读字节的方法:read():返回int类型(字符对应的ascii码值). 读取不到就返回-1.
read(char[]): 读取字符然后放入到char数组中,
11.FileWriter:字符输出流
继承关系: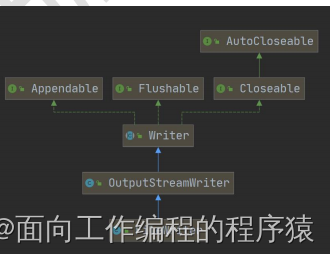
使用方法:
public static void main(String[] args){
try {
Writer writer=new FileWriter("文件路径",true);//第二个参数如果为true,则每次写数据都是在后面添加,false则是覆盖,默认为false
} catch (Exception e) {
e.printStackTrace();
}
}写字符的方法:
writer(' '):写入一个字符。
writer(int ) :传入字符的ascill码值,写入该字符.
writer(char[]) :写入一个char数组
writer(String):写入一个字符串
12. io流图解:
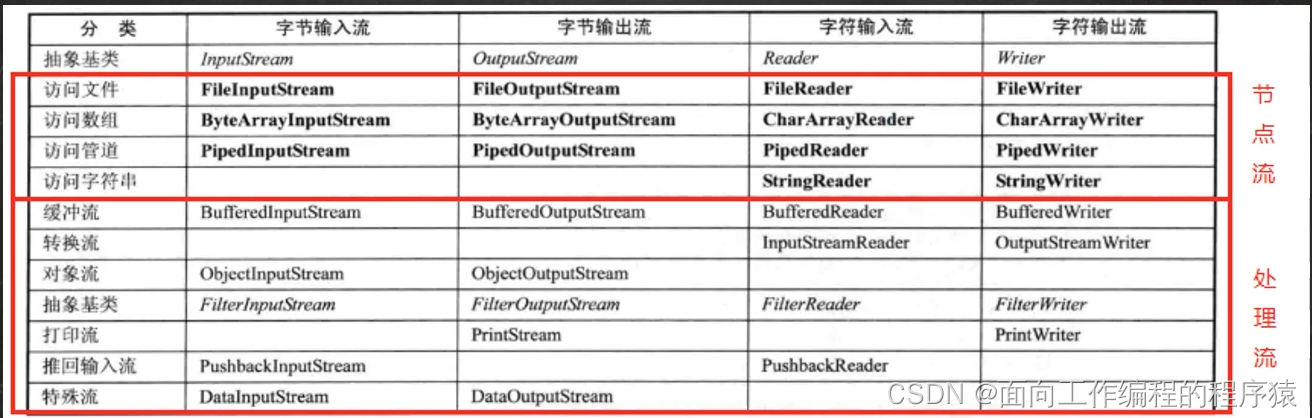
13. 处理流:是内部封装了一个节点流对象,然后对节点流对象的功能进行增强,实际底层操作文件还是使用的节点流,只不过封装了一下。
















 4512
4512











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











