






 文章探讨了如何通过端到端训练的PointLLM模型,让大型语言模型理解点云数据,解决3D对象理解中的挑战。研究提出了利用大规模点云字幕数据自动生成指令跟随数据的方法,以及PointLLM的两阶段训练策略,旨在提升模型在3D对象分类和描述任务中的性能。
文章探讨了如何通过端到端训练的PointLLM模型,让大型语言模型理解点云数据,解决3D对象理解中的挑战。研究提出了利用大规模点云字幕数据自动生成指令跟随数据的方法,以及PointLLM的两阶段训练策略,旨在提升模型在3D对象分类和描述任务中的性能。
论文地址:[2308.16911] PointLLM: Empowering Large Language Models to Understand Point Clouds (arxiv.org)
背景:
LLM的进步对自然语言处理产生了深远的影响,但是尚未完全融入3D理解领域。掌握基于文本的任务只是LLM所能实现的一个方面。LLM的一个方向在于理解3D结构,人们可以通过口头命令交互式地创建和编辑3D内容等。虽然现有的基于图像的LVLM提供了理解3D结构的途径,但是还面临着诸如深度模糊、遮挡和视点依赖性等困难。存在选择最佳视图或使用多视图图像等解决方案,但由于对象的任意方向,这些解决方案可能难以实现,并可能增加模型的复杂性。相比之下,点云提供了高效且通用的三维表示。它们提供直接的几何和外观数据,能够更全面地了解3D形状、有效的遮挡管理和独立于视点的分析。
增强LLM对3D对象点云的理解会带来三个问题:缺乏训练数据,建立合适的模型架构的必要性,以及缺乏全面的基准和评估方法
研究现状:
用语言理解对象点云。受连接视觉和文本模态的CLIP等模型的启发,3D对象领域也出现了类似的进步。PointCLIP、PointCLIPv2和CLIP2Point利用点云的深度图像投影与2D CLIP模型进行3D识别。其他一些,如ULIP、JM3D、OpenShape和CG3D,使用点云、图像和文本的三元组来训练点云编码器与CLIP表示对齐。ULIP-2和OpenShape已经通过使用图像字幕模型自动生成数据来扩展这一点,增强了训练三元组的可扩展性。Cap3D和UniG3D采用类似的方法生成点文本数据集。在我们的工作中,我们利用Cap3D在Ob-javerse上的字幕在训练PointLLM中自动生成指令数据。最近引入的3D-LLM还试图通过将对象渲染为多视图图像,使用CLIP和SAM等2D基础模型进行特征提取,以及BLIP等2D MLLMs进行输出生成,使LLM能够理解3D。同时,Point-Bind LLM将点云特征与ImageBind对齐,并使用像ImagebindLLM这样的2D MLLM进行生成。虽然简单,但由于其检索性质,它面临着幻觉等挑战。与众不同的是,PointLLM通过端到端训练提供了对对象点云的直接和全面的理解,实现了准确、开放和自由形式的交互。
研究内容:
A、Point-Text Instruction Following Data
端到端多模态LLM开发中的艰巨挑战是获取大规模的多模态 instruction-following data(指令跟随数据),这对于表示学习、调整潜在空间以及引导模型遵守人类意图十分重要。("representation learning" 指的是模型学习如何有效地表示输入数据的过程。在多模态语言模型(LLM)的上下文中,这通常涉及到学习如何表示来自多种感觉模态(比如文本、图像、语音等)的信息,以便模型能够更好地理解和处理这些信息。) 然而,手动标记此类数据成本过高且耗费大量人力,为了克服这一点,本文提出了一种在GPT-4的帮助下利用大规模点云字幕数据集Cap3D的自动数据生成技术,生成的数据集遵循统一的指令遵循模板,由Brief-description instrutions和complex instrutions 组成,分别有助于潜在空间对齐和指令调整。
B、模型结构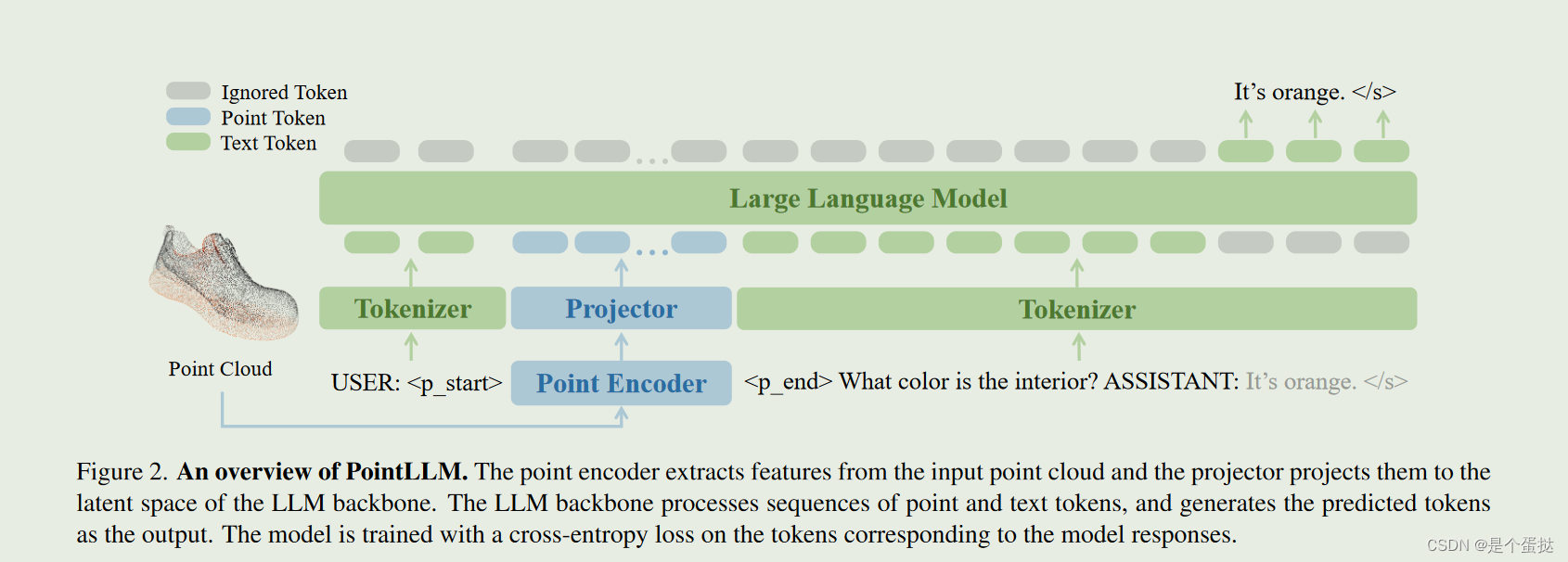
如图所示,PointLLM是一个生成模型,旨在完成包含点云和文本的多模态句子。该模型有三个模块组成:预训练的point cloud encoder、 projector和LLM,
point cloud encoder:包括了多层的transformer block
projector:包含多个线性层和GULU激活函数
C、双阶段训练
第一阶段:特征对齐阶段,冻结点云编码器和LLM的参数,并仅仅训练MLP projector,在这个阶段,训练过程使用简短的描述指令,旨在有效地将点特征与文本标记空间对齐。
第二阶段:指令调整阶段,冻结点云编码器,同时联合训练projector和LLM;第二阶段使用复杂指令,帮助模型建立理解和响应包括点云数据在内的复杂指令的能力。
模型性能:
使用两个基准来评估模型的感知能力和泛化能力:Generative 3D Object Classification 和3D Object Captioning.
代码实现
[OpenRobotLab/PointLLM: arXiv 2023] PointLLM: Empowering Large Language Models to Understand Point Clouds (github.com)
git clone git@github.com:OpenRobotLab/PointLLM.git
cd PointLLM
conda create -n pointllm python=3.10 -y
conda activate pointllm
pip install --upgrade pip # enable PEP 660 support
pip install -e .
# * for training
pip install ninja
pip install flash-attn
# 下载数据,AutoDL需要先开启学术加速 (notebook 中运行)
#学术加速
import subprocess
import os
result = subprocess.run('bash -c "source /etc/network_turbo && env | grep proxy"', shell=True, capture_output=True, text=True)
output = result.stdout
for line in output.splitlines():
if '=' in line:
var, value = line.split('=', 1)
os.environ[var] = value
pip install -U huggingface_hub
export HF_ENDPOINT=https://hf-mirror.com
huggingface-cli download --resume-download RunsenXu/PointLLM --local-dir PointLLM --cache-dir cache --token hf_xxxx --repo-type dataset
# 待补充


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









