






背景
通常LLM只能在用户提供的文本输入内做出相应是不够的,应该人类之间的互动设计多个渠道,包括视频和文本。一些工作将图像映射到类似文本的标记中,使LLM能够理解图像。与仅仅进行图像理解任务相比,增强LLM理解视频的能力更具有挑战性。目前有一些模型可以处理图像或者视频单个视觉模态。
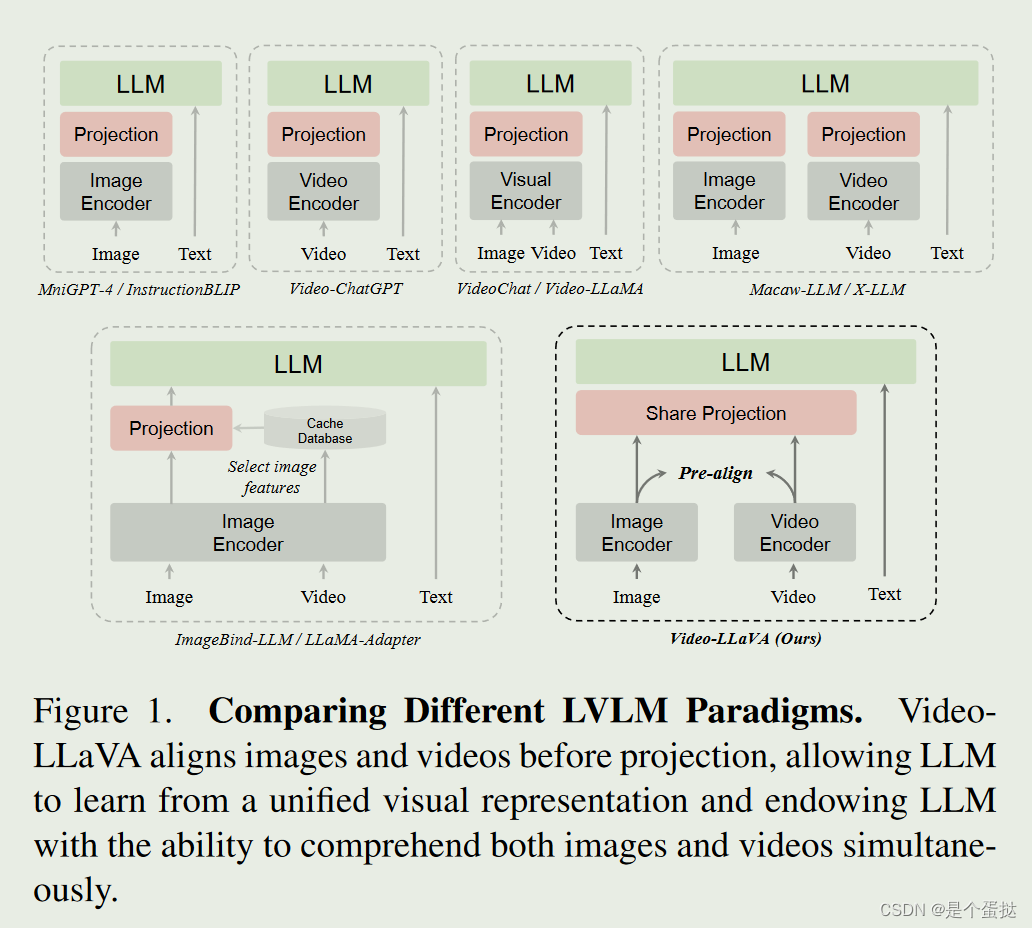
图中表现了不同LVLM类型的模型范式。一般来说,分开进行学习性能会更好,因为对于不同模态的特征进行统一具有难度,导致模型性能下降。
本文提出了一个Video LLaVA,用于LVLM同时处理图像和视频。如上图,Video-LLaVA首先将图像和视频的表示与统一的视觉特征空间对齐,然后使用共享投影层来映射LLM的统一视觉表示。
技术现状
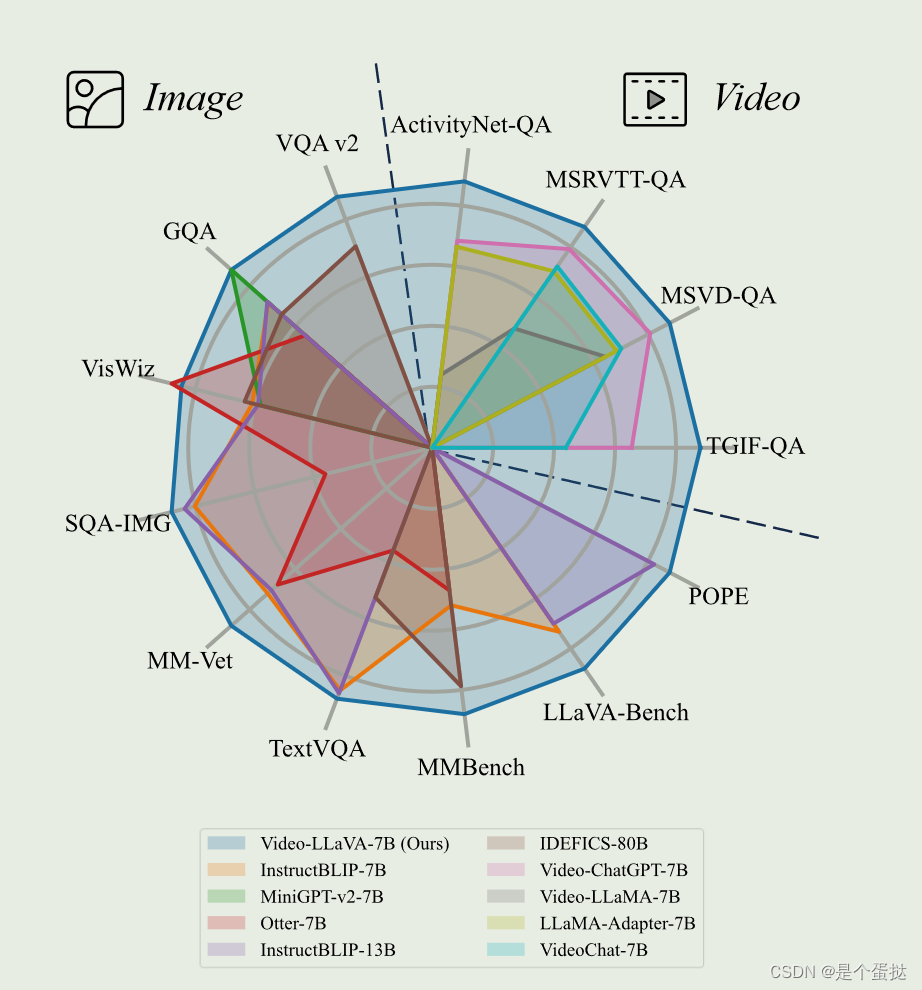
模型在图像与视频的15个数据集上表现优异
文章贡献
1、提出了Video LLaVA,在训练过程中,将视觉信号绑定到语言特征空间,统一视觉表示,并且提供一种在投影前对齐的解决方案,使得模型具有同时对图像和视频执行视觉推理功能
2、实验证明统一的视觉表示有利于LLM学习同时处理图像和视频,验证了模态的互补性,与单一模态设计的模型相比,表现出了显著的优势。
整体结构
模型由LanguageBind encoders、大语言模型、视觉投影层、单词嵌入层。
首先使用LanguageBind encoders来获得视觉特征,编码器能够将不同的模态映射到文本特征空间中,从而提供统一的视觉表示。随后,通过共享投影层对统一的视觉表示进行编码,然后将其与标记化的文本查询相结合,并输入到LLM中生成相应的相应。
文章内容
1、United Visual Representation:目标是将图像和视频映射到共享的特征空间中,使得LLM能够在统一的视觉表示中进行学习。将不同模态的信息压缩到一个公共特征空间中,使模型能够从密集的特征空间中提取信息,促进模态的相互作用和互补性。
2、Alignment Before Projection(投影前对齐):使用预训练权重LanguageBind,在共享空间中对齐图像和语言,并且使用VIDAL-10M数据集的300万个视频-文本对将视频表示与语言空间对齐,通过共享这个语言空间,图像和视频最终汇聚到一个统一的视觉特征空间,该过程称为“emergent alignment of images and videos”
通过LanguageBind,可以预先对齐LLM的输入,并减少不同视觉信号的表示之间的差距。统一的视觉表示在通过共享投影层之后被送入LLM中。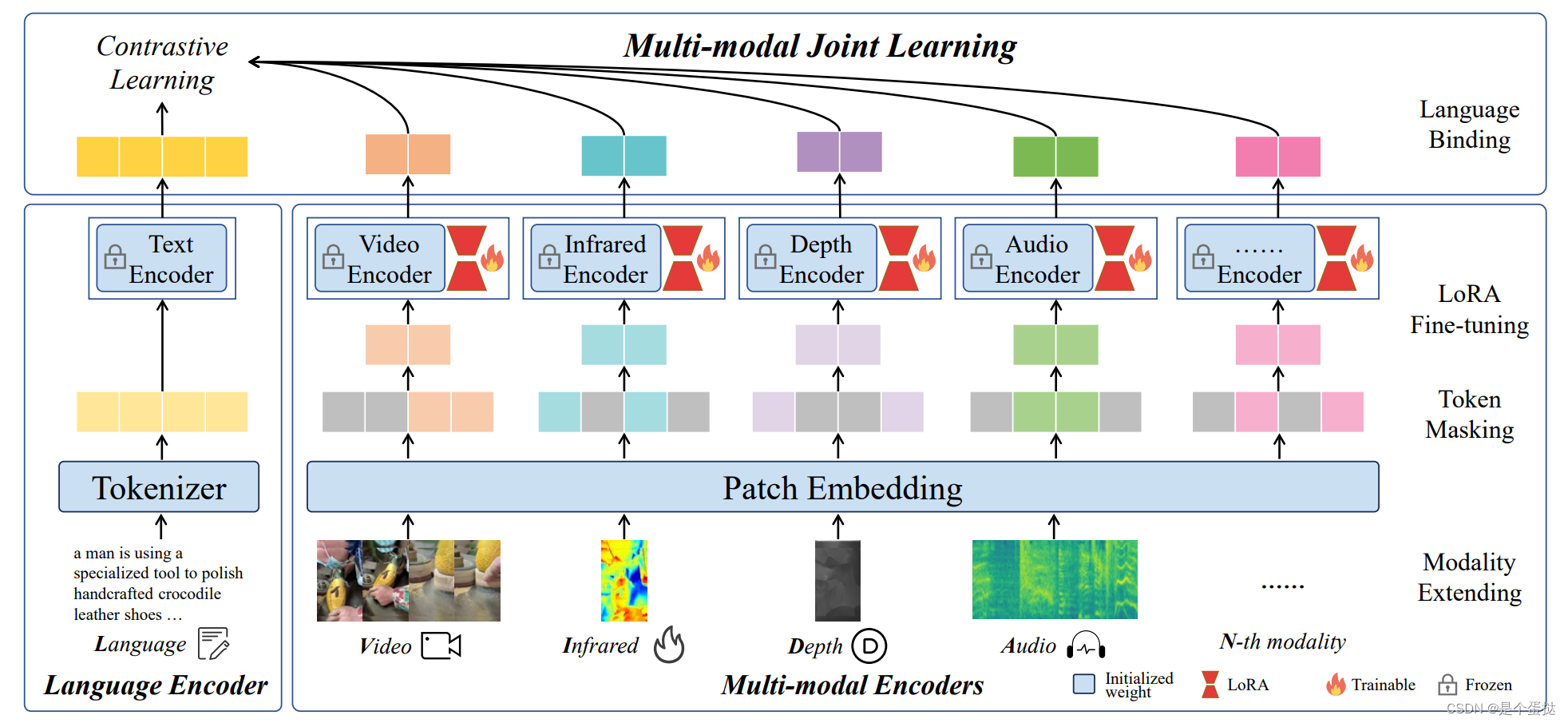
结论
图片理解上的性能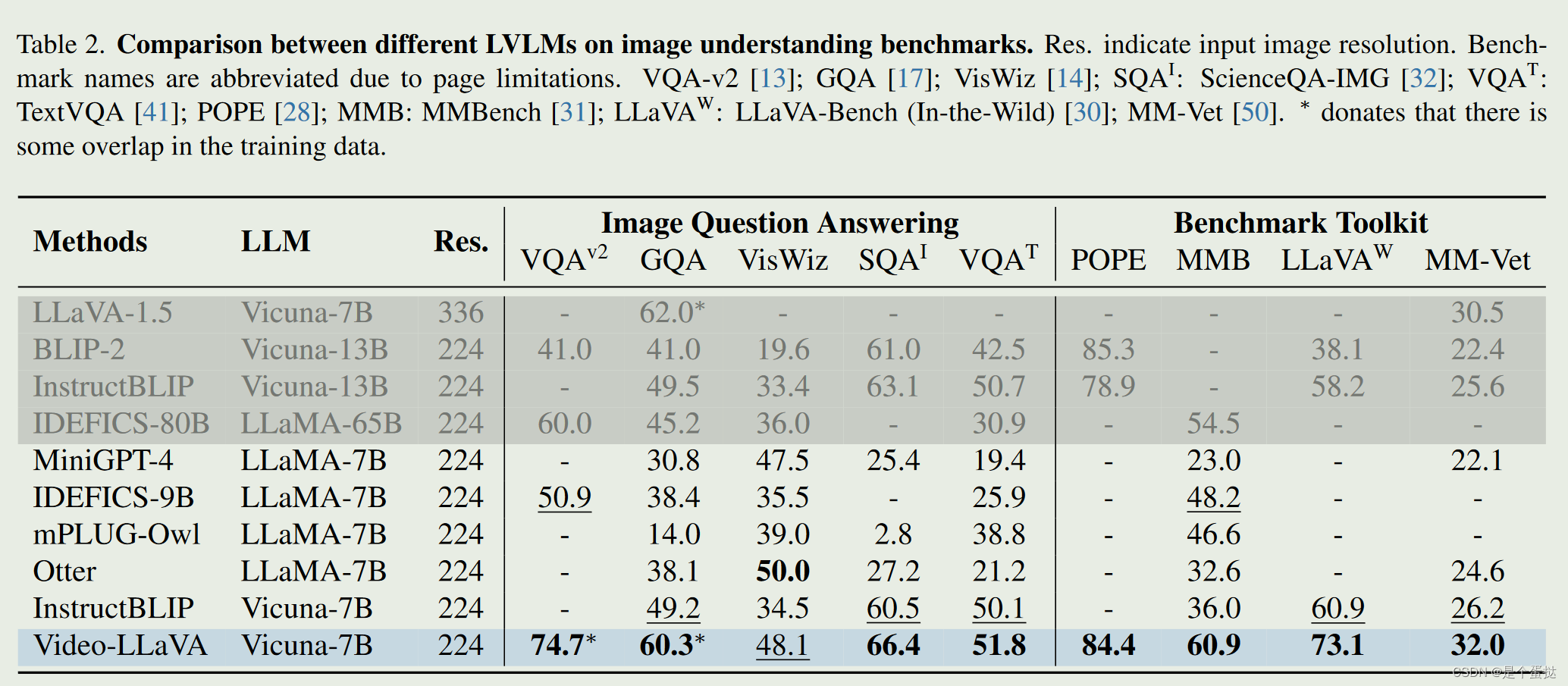
视频理解上的性能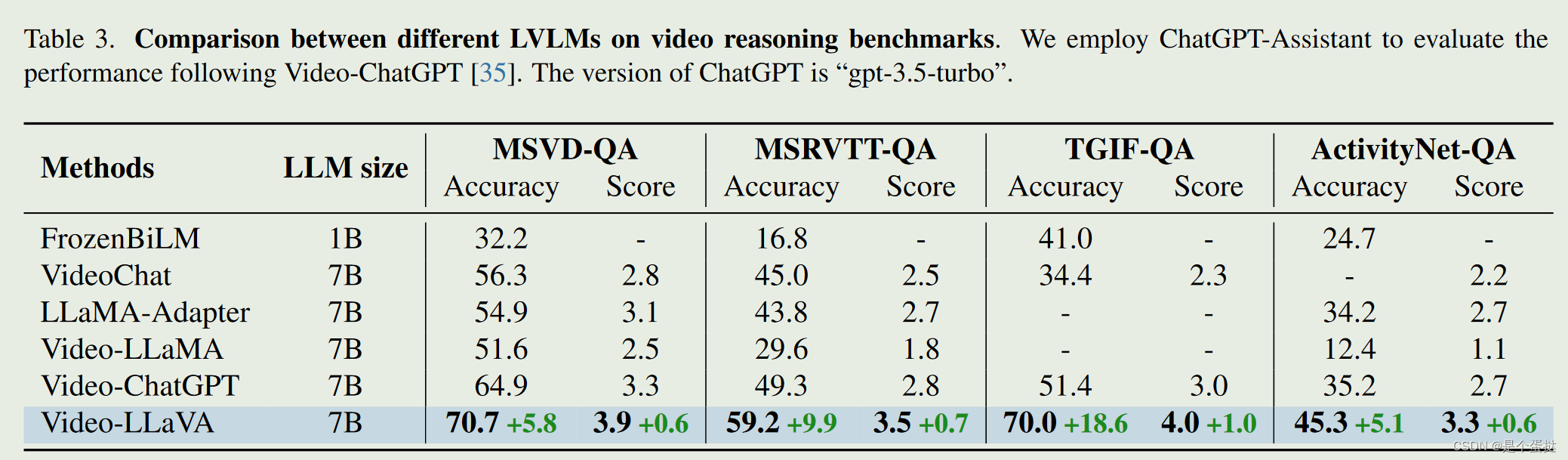
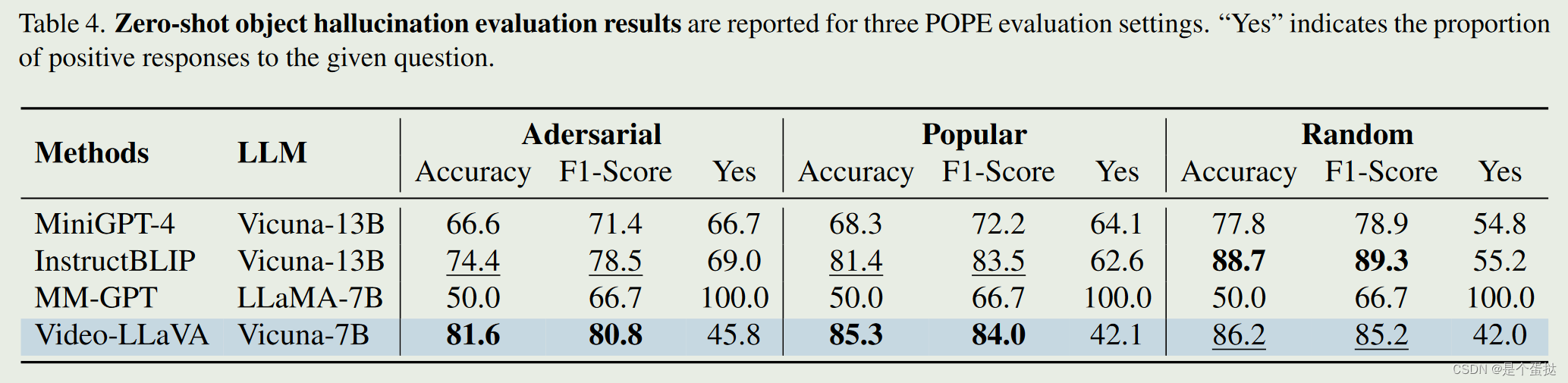
零样本对象幻觉评价结果:
多模态大模型的幻觉问题与评估 - 知乎 (zhihu.com)
LVLMs虽然在较为复杂的图像问答问题上表现出色,却难以正确回答一些看似更简单的问题,例如判断图像中是否存在某物体。在 image captioning 领域,这种模型生成了图像中不存在的物体的现象被称为物体幻觉 (Object Hallucination)。
POPE:一种基于轮询的物体探测评测方法 (Polling-based Object Probing Evaluation, POPE)
关于图像中未出现物体的选择,受此前关于多模态指令数据对幻觉影响的分析启发设计了三种采样策略:
-
Random sampling:随机选取不在图像中的物体
-
Popular sampling: 优先选取出现频率较高的物体
-
Adversarial sampling: 优先选取和图像中物体频繁共现的物体
理解图片:与GPT-4进行比较,本文所提模型相应更加全面、更加直观、更有逻辑性。
理解视频:所提模型更能够根据给定的说明从视频中提取关键信息(例如紫色文本)

理解图像和视频组成的输入能力。

证明了Video-LLaVA具有从统一的视觉表示中学习理解图像和视频的能力。
代码复现
待补充xxxxx















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









