






 本文介绍了如何使用Python和Pandas库处理某地区房屋销售数据,包括读取CSV文件,处理时间信息,提取特征,进行描述性统计和分组聚合,以分析房屋销售情况和价格特性。
本文介绍了如何使用Python和Pandas库处理某地区房屋销售数据,包括读取CSV文件,处理时间信息,提取特征,进行描述性统计和分组聚合,以分析房屋销售情况和价格特性。
【实验内容】
- 读取并查看某地区房屋销售数据的基本信息
- 提取房屋售出时间信息并描述房屋价格信息
- 使用分组聚合方法分析房屋销售情况
【实验目的】
(1)掌握CSV文件数据的读取方法。
(2)掌握DataFrame的常用属性和方法。
(3)掌握DataFrame的索引和切片操作。
(4)掌握时间字符串和标准时间的转换方法。
(5)掌握pandas 描述性统计方法。
(6)掌握分组聚合的步骤。
(7)掌握groupby()的使用方法。
(8)掌握transform()、agg()、apply()聚合方法。
【实验技术/工具清单】
集成开发工具:Anaconda3、PyCharm、Jupyter
第三方模块:Numpy、Pandas
【实验原理/思路】
实训1:读取并查看某地区房屋销售数据的基本信息
某房产销售经理为了解某地区2010年-2019年的房屋销售情况,现需查看该地区房屋销售数据。该地区房屋销售数据主要存放了房屋售出时间、地区邮编、房屋价格、房屋类型和配套房间数5个特征,部分数据如表1所示,其中房屋类型有普通住宅(house)和单身公寓(unit)两种。探索数据的基本信息,通过索引操作查询到房屋类型为单身公寓的数据,同时观察数据的整体分布并发现数据间的关联。注意,地区邮编特征已完成脱敏处理,因此只存在4位数。
表1 某地区部分房屋销售数据

基于实训1的数据,在房屋售出时间特征中存在时间数据,提取时间数据内存在的有用信息,如将“2010/1/4 0:00”转换成“2010-1-4”的形式。对时间信息的提取一方面可以加深房产销售经理对数据的理解,另一方面能够去除无意义的时间信息。此外,还可通过描述性统计分析该地区房屋的平均价格、价格区间、价格众数等,便于进一步获取该地区房屋价格信息。
实训3:使用分组聚合方法分析房屋销售情况
为了解买房者购买房屋的类型喜好,需要根据房屋所在的地理位置进行分组聚合,然后进行组内和组间分析,从而为买房者提供更好的服务。基于实训1的数据,提取地区邮编特征中数据的前两位,如提取“2615”中的“26”,并生成 new_postcode特征存储提取的内容,其目的是便于统计不同地区房屋价格以及房屋性价比。最后根据 new_postcode特征对数据进行分组操作,从而获取不同地区的房屋价格信息并进行比较。
【实验步骤】
1.读取并查看某地区房屋销售数据的基本信息
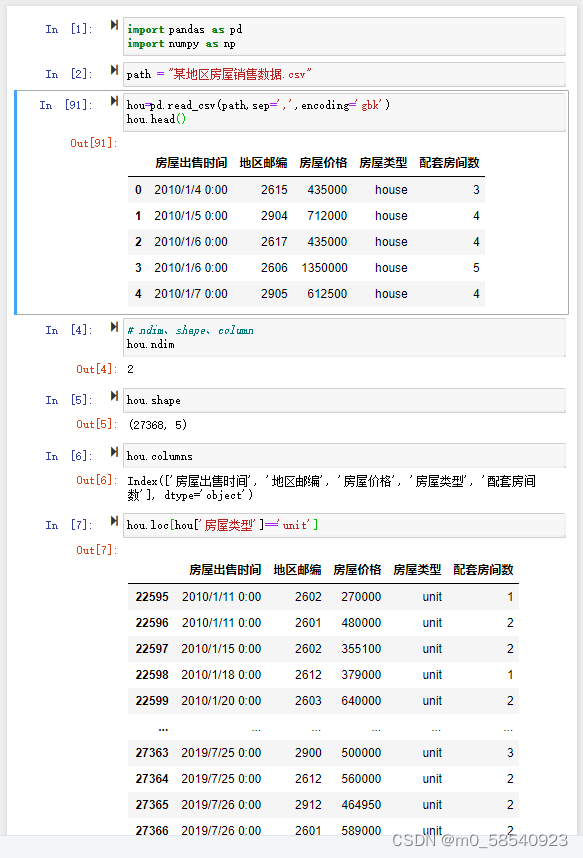
(1)使用read_csv函数读取“某地区房屋销售数据.csv”。
(2)使用ndim、shape、columns属性分别查看数据的维度、形状,以及所有特征名称。
(3)使用iloc()方法、loc()方法对房屋类型为unit的数据进行索引操作。
2. 提取房屋售出时间信息并描述房屋价格信息
(1)使用to_datetime 函数转换房屋售出时间字符串。
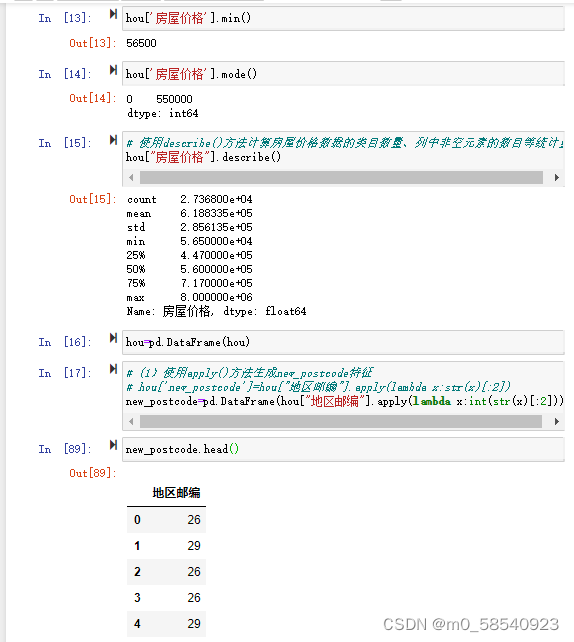
(2)使用mean、max、min、mode函数分别计算该地区房屋价格的均值、最大值、最小值和众数。
(3)使用describe()方法计算房屋价格数据的类目数量、列中非空元素的数目等统计量。
3. 使用分组聚合方法分析房屋销售情况
(1)使用apply()方法生成new_postcode特征。
(2)使用agg()方法和count函数计算出每个地区的房屋售出总数。
(3)使用 groupby()方法对房屋类型进行分组,并对新地区邮编new_postcode 进行分组后赋值给新的数据框housesale1。
(4)使用transform()聚合方法和mean函数计算housesale1中房屋价格的均值。
【实验记录与结果分析】
实现源代码和执行结果。
import pandas as pd
import numpy as np
path = "某地区房屋销售数据.csv"
hou=pd.read_csv(path,sep=',',encoding='gbk')
hou.head()
# ndim、shape、column
hou.ndim
hou.shape
hou.columns
hou.loc[hou['房屋类型']=='unit']
hou.iloc[(hou['房屋类型']=='unit').tolist()]
hou['房屋出售时间']=pd.to_datetime(hou['房屋出售时间'])
hou.head()
# 使用mean、max、min、mode函数分别计算该地区房屋价格的均值、最大值、最小值和众数。
hou['房屋价格'].mean()
hou['房屋价格'].max()
hou['房屋价格'].min()
hou['房屋价格'].mode()
# 使用describe()方法计算房屋价格数据的类目数量、列中非空元素的数目等统计量
hou["房屋价格"].describe()
hou=pd.DataFrame(hou)
# (1)使用apply()方法生成new_postcode特征
# hou['new_postcode']=hou["地区邮编"].apply(lambda x:str(x)[:2])
new_postcode=pd.DataFrame(hou["地区邮编"].apply(lambda x:int(str(x)[:2])))
new_postcode.head()
# 2)使用agg()方法和count函数计算出每个地区的房屋售出总数。
# hou.groupby("new_postcode").agg({"new_postcode":["count"]})
new_postcode.groupby("地区邮编").agg({"地区邮编":["count"]})
# (3)使用 groupby()方法对房屋类型进行分组,并对新地区邮编new_postcode 进行分组后赋值给新的数据框housesale1。
# hou['new_postcode']=hou["地区邮编"].apply(lambda x:str(x)[:2])
hou_style=hou.copy(deep=True)
hou_style['new_postcode']=new_postcode
# (3)使用 groupby()方法对房屋类型进行分组,并对新地区邮编new_postcode 进行分组后赋值给新的数据框housesale1。
housesale1=hou_style.groupby([hou_style["房屋类型"],hou_style["new_postcode"]])
housesale1.mean()
# 使用transform()聚合方法和mean函数计算housesale1中房屋价格的均值。
hou_style["区域房屋平均价格"]=pd.DataFrame((housesale1["房屋价格"].transform('mean')))
hou_style.head()|
|




















 657
657

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









