






【实验内容】
- 分析学生考试成绩特征的分布与分散情况
- 分析学生考试成绩与各个特征之间的关系
【实验目的】
(1)掌握pyplot的基础语法。
(2)掌握子图的绘制方法。
(3)掌握饼图的绘制方法。
(4)掌握箱线图的绘制方法。
(5)掌握折线图的绘制方法。
(6)掌握柱形图的绘制方法。
(7)掌握NumPy库中相关函数的使用方法。
【实验技术/工具清单】
集成开发工具:Anaconda3、PyCharm、Jupyter
第三方模块:Numpy、Pandas、Matplotlib、Seaborn
【实验原理/思路】
实训1:分析学生考试成绩特征的分布与分散情况(分别使用matplotlib和searborn实现)
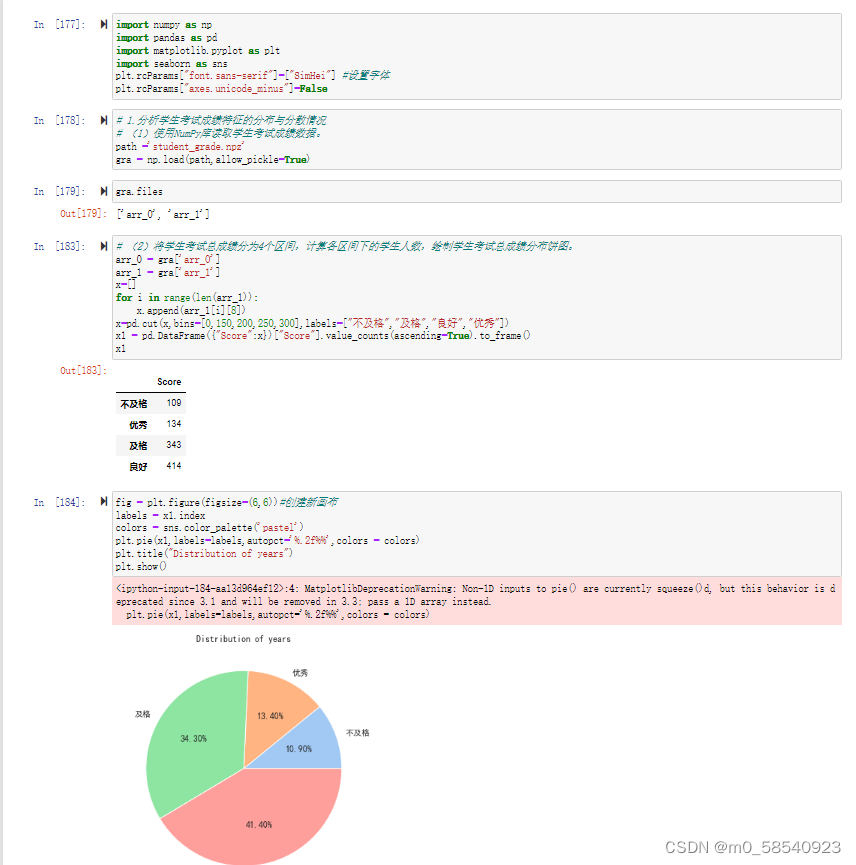
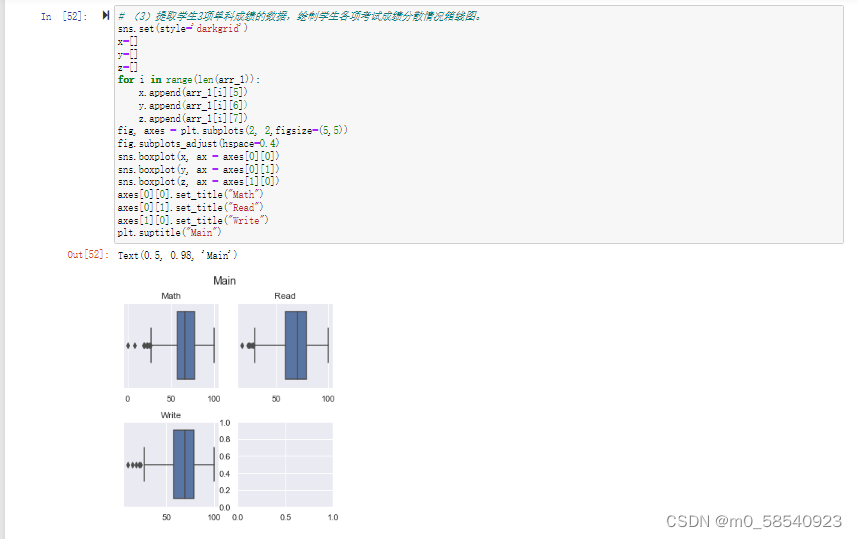
在期末考试后,学校对学生的期末考试成绩及其他特征信息进行了统计,并存为学生成绩特征关系表(student_grade.npz)。学生成绩特征关系表共有8个特征,分别为性别、父母教育水平、自我效能感、考试课程准备情况、数学成绩、阅读成绩、写作成绩和总成绩,其部分数据如表1所示(数据保存在npz文件中,需要通过numpy读取数据,并创建DataFrame数据结构,从而进行数据可视化练习)。为了解学生考试总成绩的分布情况,将总成绩按0~150、150~200、200~250、250~300区间划分为“不及格”“及格”“良好”“优秀”4个等级,通过绘制饼图查看各区间学生人数比例,并通过绘制箱线图查看学生3项单科成绩的分散情况。
表1 学生成绩特征关系表部分数据
实训2:分析学生考试成绩与各个特征之间的关系(分别使用matplotlib和searborn实现)
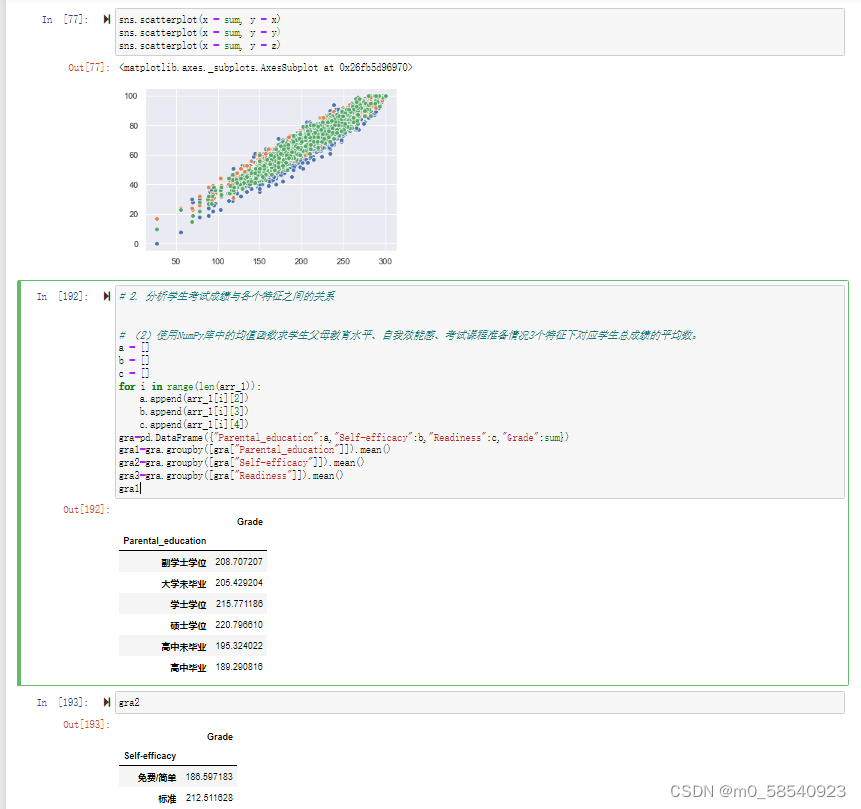
为了了解学生父母教育水平、自我效能感、考试课程准备情况这3个特征与总成绩之间是否存在某些关系,基于实训1的数据,对这3个特征下不同值所对应的学生总成绩求平均值,绘制折线图查看父母教育水平与总成绩的关系,绘制柱形图分别查看自我效能感、考试课程准备情况与总成绩的关系,并对结果进行分析。
【实验步骤】
1.分析学生考试成绩特征的分布与分散情况
(1)使用NumPy库读取学生考试成绩数据。
(2)将学生考试总成绩分为4个区间,计算各区间下的学生人数,绘制学生考试总成绩分布饼图。
(3)提取学生3项单科成绩的数据,绘制学生各项考试成绩分散情况箱线图。
(4)分析学生考试总成绩的分布情况和3项单科成绩的分散情况。
2. 分析学生考试成绩与各个特征之间的关系
(1)创建画布,并添加子图。
(2)使用NumPy库中的均值函数求学生父母教育水平、自我效能感、考试课程准备情况3个特征下对应学生总成绩的平均数。
(3)在子图上绘制对应的折线图或柱形图。
(4)分析3个特征与考试总成绩的关系。
【实验记录与结果分析】
实现源代码和执行结果。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
plt.rcParams["font.sans-serif"]=["SimHei"] #设置字体
plt.rcParams["axes.unicode_minus"]=False
# 1.分析学生考试成绩特征的分布与分散情况
# (1)使用NumPy库读取学生考试成绩数据。
path ='student_grade.npz'
gra = np.load(path,allow_pickle=True)
# (2)将学生考试总成绩分为4个区间,计算各区间下的学生人数,绘制学生考试总成绩分布饼图。
arr_0 = gra['arr_0']
arr_1 = gra['arr_1']
x=[]
for i in range(len(arr_1)):
x.append(arr_1[i][8])
x=pd.cut(x,bins=[0,150,200,250,300],labels=["不及格","及格","良好","优秀"])
x1=pd.DataFrame({"Score":x})["Score"].value_counts(ascending=True).to_frame()
x1
fig = plt.figure(figsize=(6,6))#创建新画布
labels = x1.index
colors = sns.color_palette('pastel')
plt.pie(x1,labels=labels,autopct='%.2f%%',colors = colors)
plt.title("Distribution of years")
plt.show()
# (3)提取学生3项单科成绩的数据,绘制学生各项考试成绩分散情况箱线图。
sns.set(style='darkgrid')
x=[]
y=[]
z=[]
for i in range(len(arr_1)):
x.append(arr_1[i][5])
y.append(arr_1[i][6])
z.append(arr_1[i][7])
fig, axes = plt.subplots(2, 2,figsize=(5,5))
fig.subplots_adjust(hspace=0.4)
sns.boxplot(x, ax = axes[0][0])
sns.boxplot(y, ax = axes[0][1])
sns.boxplot(z, ax = axes[1][0])
axes[0][0].set_title("Math")
axes[0][1].set_title("Read")
axes[1][0].set_title("Write")
plt.suptitle("Main")
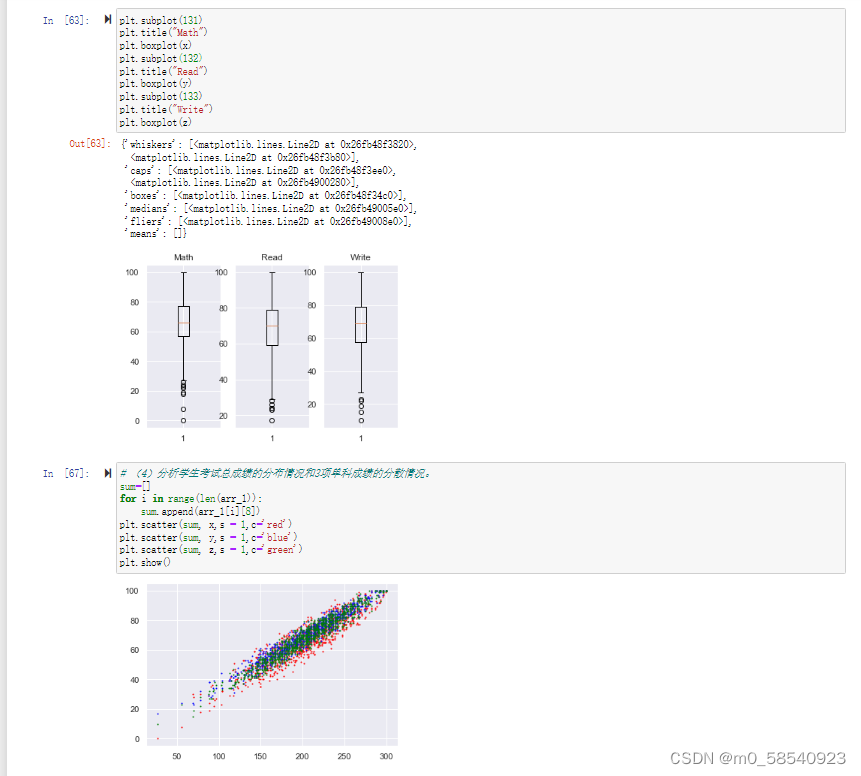
plt.subplot(131)
plt.title("Math")
plt.boxplot(x)
plt.subplot(132)
plt.title("Read")
plt.boxplot(y)
plt.subplot(133)
plt.title("Write")
plt.boxplot(z)
# (4)分析学生考试总成绩的分布情况和3项单科成绩的分散情况。
sum=[]
for i in range(len(arr_1)):
sum.append(arr_1[i][8])
plt.scatter(sum, x,s = 1,c='red')
plt.scatter(sum, y,s = 1,c='blue')
plt.scatter(sum, z,s = 1,c='green')
plt.show()
sns.scatterplot(x = sum, y = x)
sns.scatterplot(x = sum, y = y)
sns.scatterplot(x = sum, y = z)
# 2. 分析学生考试成绩与各个特征之间的关系
# (2)使用NumPy库中的均值函数求学生父母教育水平、自我效能感、考试课程准备情况3个特征下对应学生总成绩的平均数。
a = []
b = []
c = []
for i in range(len(arr_1)):
a.append(arr_1[i][2])
b.append(arr_1[i][3])
c.append(arr_1[i][4])
gra=pd.DataFrame({"Parental_education":a,"Self-efficacy":b,"Readiness":c,"Grade":sum})
gra1=gra.groupby([gra["Parental_education"]]).mean()
gra2=gra.groupby([gra["Self-efficacy"]]).mean()
gra3=gra.groupby([gra["Readiness"]]).mean()
gra1
gra2
gra3
# (1)创建画布,并添加子图。
fig, axes = plt.subplots(figsize=(15,10))
fig.subplots_adjust(hspace=0.4)
# (3)在子图上绘制对应的折线图或柱形图。
plt.rcParams["font.sans-serif"]=["SimHei"] #设置字体
plt.rcParams["axes.unicode_minus"]=False
# 绘柱状图
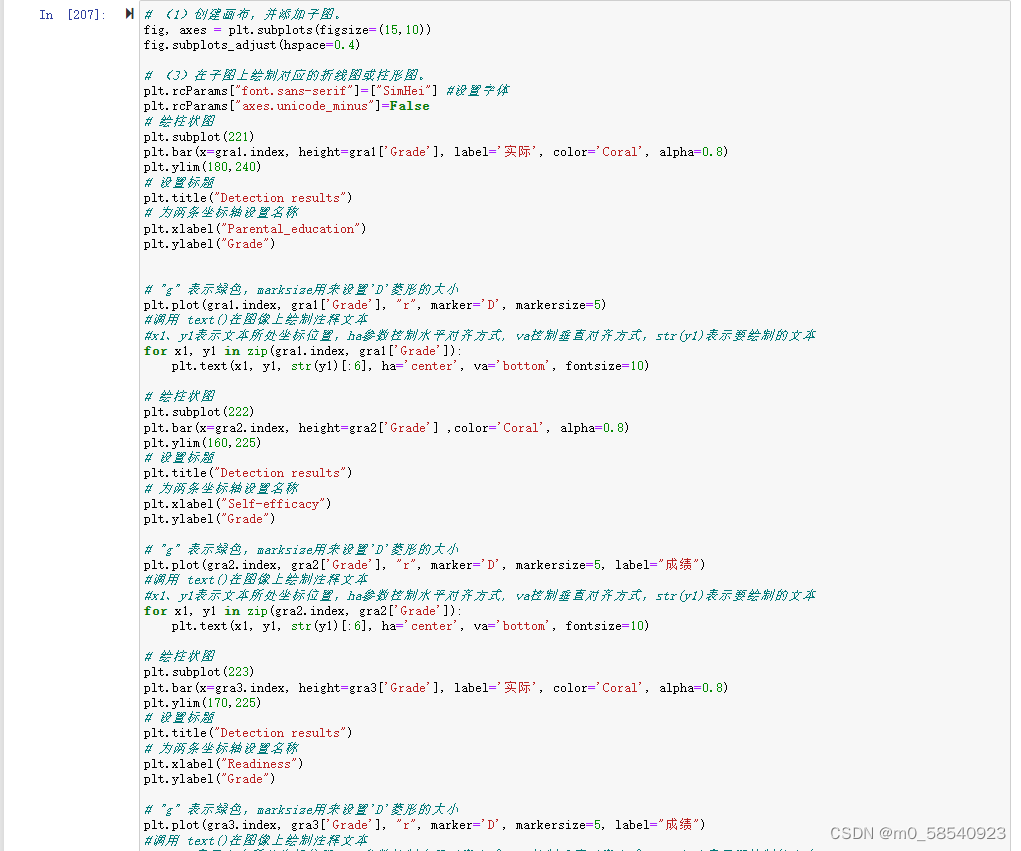
plt.subplot(221)
plt.bar(x=gra1.index, height=gra1['Grade'], label='实际', color='Coral', alpha=0.8)
plt.ylim(180,240)
# 设置标题
plt.title("Detection results")
# 为两条坐标轴设置名称
plt.xlabel("Parental_education")
plt.ylabel("Grade")
# "g" 表示绿色,marksize用来设置'D'菱形的大小
plt.plot(gra1.index, gra1['Grade'], "r", marker='D', markersize=5)
#调用 text()在图像上绘制注释文本
#x1、y1表示文本所处坐标位置,ha参数控制水平对齐方式, va控制垂直对齐方式,str(y1)表示要绘制的文本
for x1, y1 in zip(gra1.index, gra1['Grade']):
plt.text(x1, y1, str(y1)[:6], ha='center', va='bottom', fontsize=10)
# 绘柱状图
plt.subplot(222)
plt.bar(x=gra2.index, height=gra2['Grade'] ,color='Coral', alpha=0.8)
plt.ylim(160,225)
# 设置标题
plt.title("Detection results")
# 为两条坐标轴设置名称
plt.xlabel("Self-efficacy")
plt.ylabel("Grade")
# "g" 表示绿色,marksize用来设置'D'菱形的大小
plt.plot(gra2.index, gra2['Grade'], "r", marker='D', markersize=5, label="成绩")
#调用 text()在图像上绘制注释文本
#x1、y1表示文本所处坐标位置,ha参数控制水平对齐方式, va控制垂直对齐方式,str(y1)表示要绘制的文本
for x1, y1 in zip(gra2.index, gra2['Grade']):
plt.text(x1, y1, str(y1)[:6], ha='center', va='bottom', fontsize=10)
# 绘柱状图
plt.subplot(223)
plt.bar(x=gra3.index, height=gra3['Grade'], label='实际', color='Coral', alpha=0.8)
plt.ylim(170,225)
# 设置标题
plt.title("Detection results")
# 为两条坐标轴设置名称
plt.xlabel("Readiness")
plt.ylabel("Grade")
# "g" 表示绿色,marksize用来设置'D'菱形的大小
plt.plot(gra3.index, gra3['Grade'], "r", marker='D', markersize=5, label="成绩")
#调用 text()在图像上绘制注释文本
#x1、y1表示文本所处坐标位置,ha参数控制水平对齐方式, va控制垂直对齐方式,str(y1)表示要绘制的文本
for x1, y1 in zip(gra3.index, gra3['Grade']):
plt.text(x1, y1, str(y1)[:6], ha='center', va='bottom', fontsize=10)
plt.show()
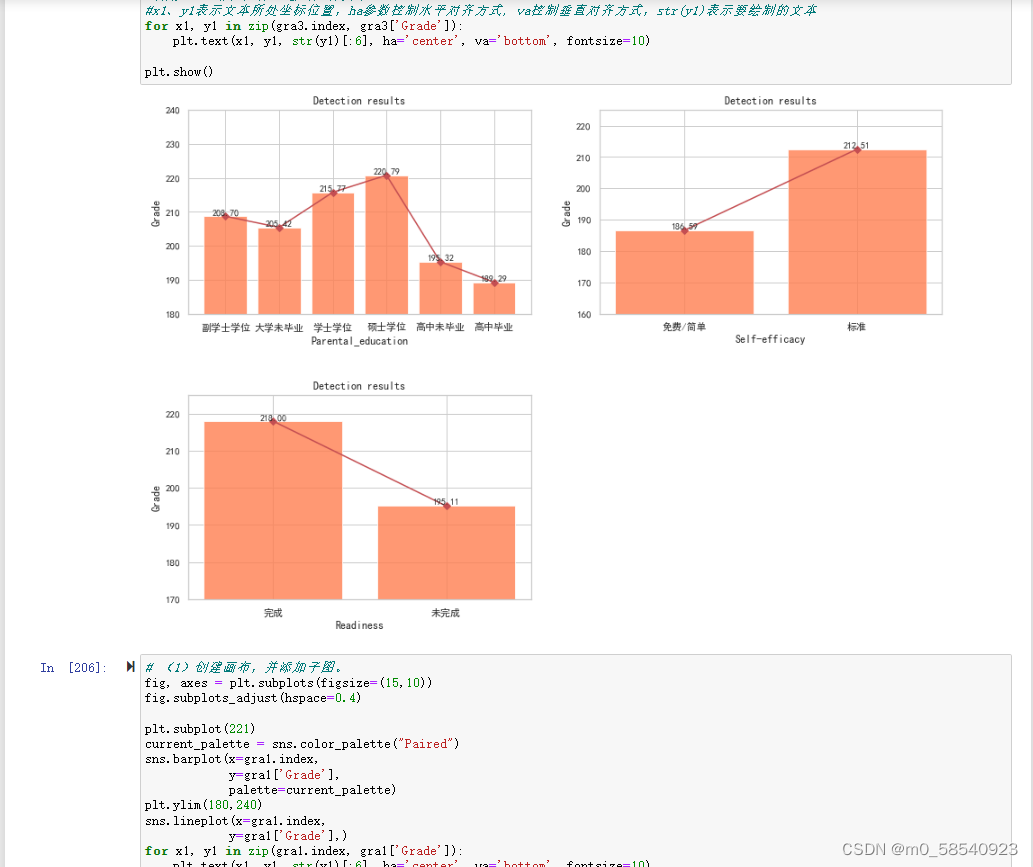
# (1)创建画布,并添加子图。
fig, axes = plt.subplots(figsize=(15,10))
fig.subplots_adjust(hspace=0.4)
plt.subplot(221)
current_palette = sns.color_palette("Paired")
sns.barplot(x=gra1.index,
y=gra1['Grade'],
palette=current_palette)
plt.ylim(180,240)
sns.lineplot(x=gra1.index,
y=gra1['Grade'],)
for x1, y1 in zip(gra1.index, gra1['Grade']):
plt.text(x1, y1, str(y1)[:6], ha='center', va='bottom', fontsize=10)
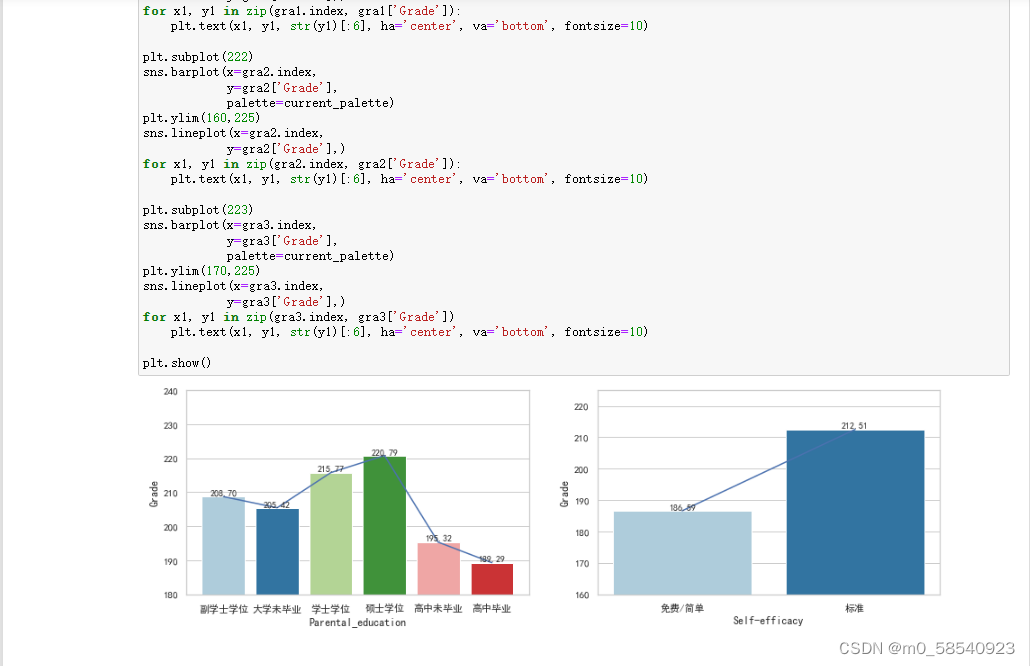
plt.subplot(222)
sns.barplot(x=gra2.index,
y=gra2['Grade'],
palette=current_palette)
plt.ylim(160,225)
sns.lineplot(x=gra2.index,
y=gra2['Grade'],)
for x1, y1 in zip(gra2.index, gra2['Grade']):
plt.text(x1, y1, str(y1)[:6], ha='center', va='bottom', fontsize=10)
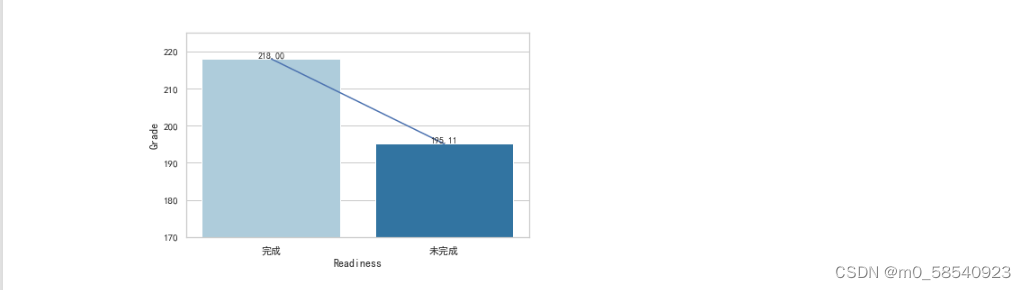
plt.subplot(223)
sns.barplot(x=gra3.index,
y=gra3['Grade'],
palette=current_palette)
plt.ylim(170,225)
sns.lineplot(x=gra3.index,
y=gra3['Grade'],)
for x1, y1 in zip(gra3.index, gra3['Grade'])
plt.text(x1, y1, str(y1)[:6], ha='center', va='bottom', fontsize=10)
plt.show()
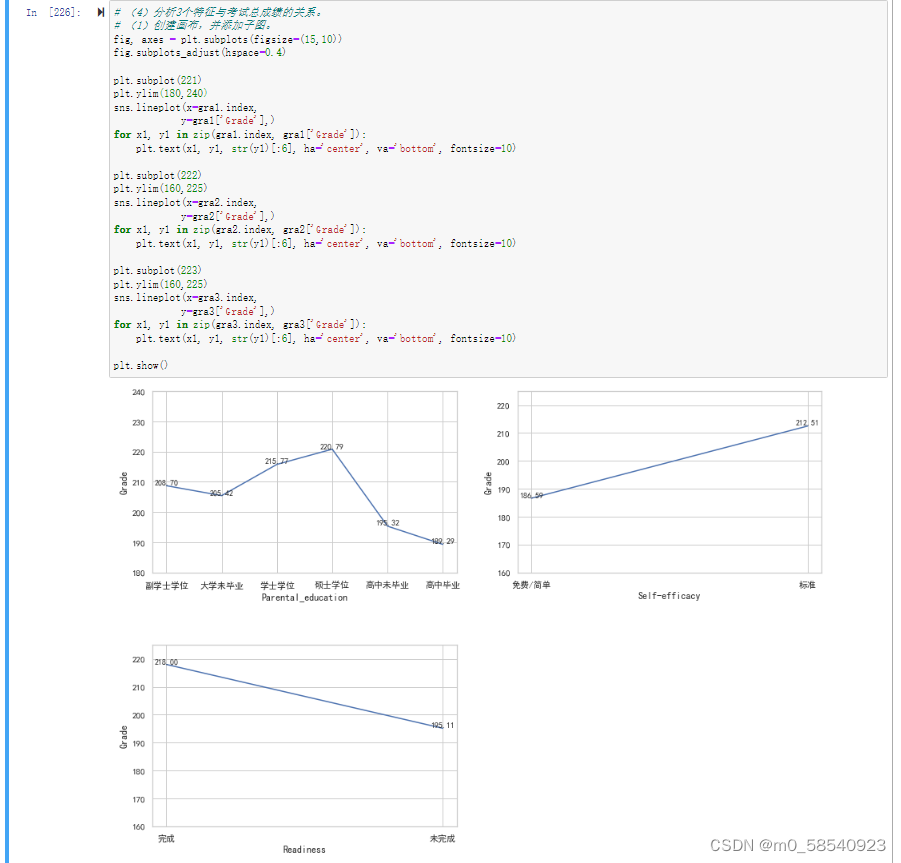
# (4)分析3个特征与考试总成绩的关系。
# (1)创建画布,并添加子图。
fig, axes = plt.subplots(figsize=(15,10))
fig.subplots_adjust(hspace=0.4)
plt.subplot(221)
plt.ylim(180,240)
sns.lineplot(x=gra1.index,
y=gra1['Grade'],)
for x1, y1 in zip(gra1.index, gra1['Grade']):
plt.text(x1, y1, str(y1)[:6], ha='center', va='bottom', fontsize=10)
plt.subplot(222)
plt.ylim(160,225)
sns.lineplot(x=gra2.index,
y=gra2['Grade'],)
for x1, y1 in zip(gra2.index, gra2['Grade']):
plt.text(x1, y1, str(y1)[:6], ha='center', va='bottom', fontsize=10)
plt.subplot(223)
plt.ylim(160,225)
sns.lineplot(x=gra3.index,
y=gra3['Grade'],)
for x1, y1 in zip(gra3.index, gra3['Grade']):
plt.text(x1, y1, str(y1)[:6], ha='center', va='bottom', fontsize=10)
plt.show()|
|



















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









