







摘要:大型推理模型(LRMs)展现出了卓越的推理能力,但主要依赖于参数化知识,这限制了其事实准确性。尽管最近的研究为基于强化学习(RL)的LRMs配备了检索能力,但它们存在过度思考和推理不够稳健的问题,降低了其在问答(QA)任务中的有效性。为了解决这一问题,我们提出了ReaRAG,这是一种增强事实性的推理模型,能够在不进行过多迭代的情况下探索多样化的查询。我们的解决方案包括一个具有推理链长度上限的新型数据构建框架。具体来说,我们首先利用一个LRM进行深思熟虑的思考,然后从预定义的动作空间(搜索和完成)中选择一个动作。对于搜索动作,会在RAG引擎上执行一个查询,查询结果作为观察结果返回,以指导后续的推理步骤。这一过程会一直迭代,直到选择了一个完成动作。得益于ReaRAG强大的推理能力,我们的方法在多跳问答方面优于现有的基线模型。进一步的分析突出了其强大的反思能力,能够识别错误并优化其推理轨迹。我们的研究增强了LRMs的事实性,同时有效地将稳健的推理整合到检索增强生成(RAG)中。
目录
一、背景动机
论文题目:ReaRAG: Knowledge-guided Reasoning Enhances Factuality of Large Reasoning Models with Iterative Retrieval Augmented Generation
论文地址:https://arxiv.org/pdf/2503.21729
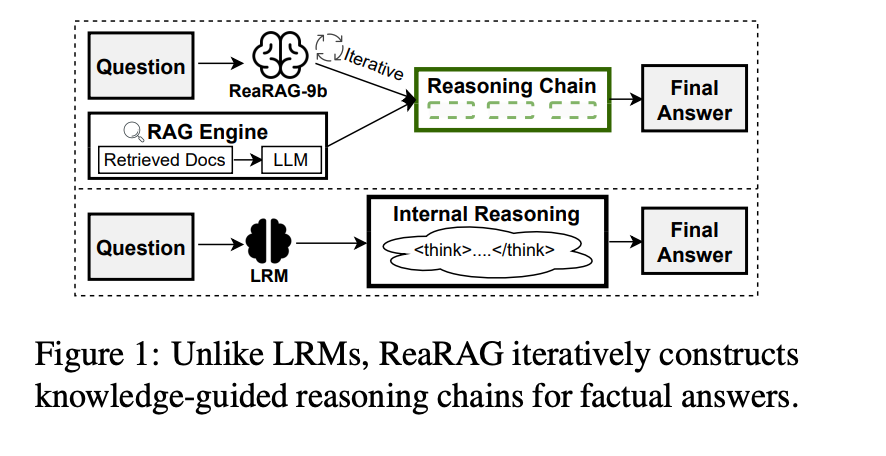
推理模型在复杂任务中表现出色,但主要依赖于参数化知识,这限制了它们在多跳问答任务中的表现,RAG通过整合外部知识来增强LLMs的事实性,但在检索相关文档时面临挑战,需要精确地制定搜索查询。
现有的迭代检索策略在构建推理链时存在错误传播的问题,早期步骤中的错误会误导后续的检索和推理,最终降低整体答案质量。此外,基于强化学习(RL)的推理模型倾向于过度思考,这对于多跳QA任务来说是不必要的。
文章提出了ReaRAG方法,它通过迭代构建知识引导的推理链,以及反思机制识别错误并调整推理路径,有效地提高了LRMs在多跳QA任务中的事实性和推理能力。
二、核心贡献
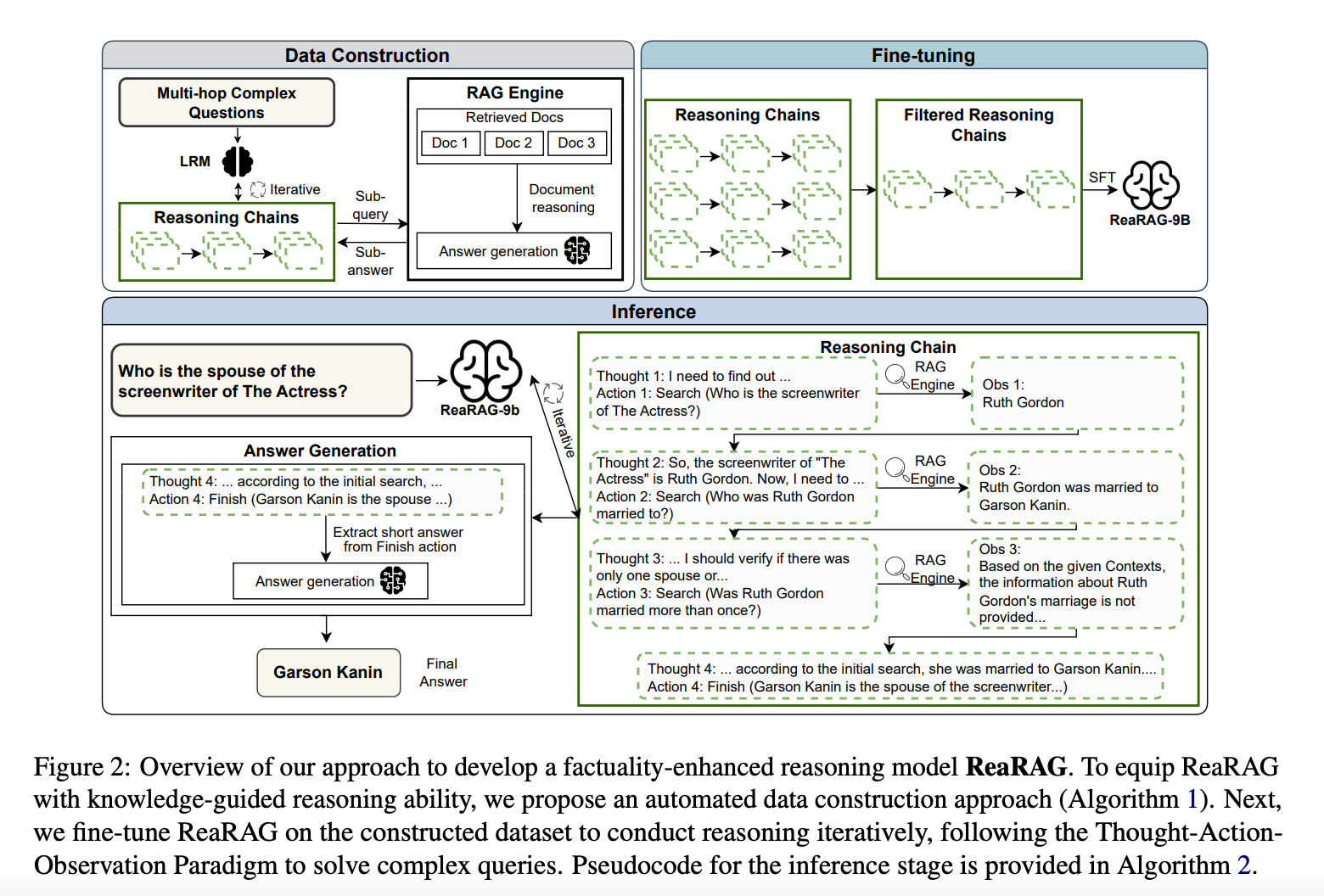
1、提出了一种新的事实性增强推理模型ReaRAG,它通过迭代构建知识引导的推理链来解决多跳QA任务。
2、设计了一个新的数据构建框架,该框架通过限制推理链的最大长度来提高检索的鲁棒性,并减少过度思考。
3、通过在推理过程中引入反思(reflection)机制,ReaRAG能够识别错误并调整其推理路径,从而提高答案的准确性。
三、实现方法
3.1 任务定义
ReaRAG专注于多跳QA任务,目标是构建一个知识引导的推理链C,以增强生成答案的事实正确性。推理链由一系列步骤组成,每一步包括推理思考(τt)、动作(αt)和观察(ot)。其定义了两种动作类型Search(搜索)和Finish(完成),搜索动作会触发对RAG引擎的查询,而完成动作则表示推理链的结束。
-
推理思考(Thought, τt):模型对当前情况的思考。
-
动作(Action, αt):模型选择的动作,可以是搜索(Search)或完成(Finish)。
-
观察(Observation, ot):执行动作后从RAG引擎返回的反馈。
-
Search:执行搜索查询,从RAG引擎获取相关信息。
{
"name": "search",
"description": "It can help you find useful information through the internet or local knowledge base.",
"parameters": {
"type": "object",
"properties": {
"query": {
"description": "what you want to search"
}
},
"required": ["query"]
}
}-
Finish:结束推理链,生成最终答案。
{
"name": "finish",
"description": "You can use this function to make a conclusion from the reasoning process and give the final answer.",
"parameters": {
"type": "object",
"properties": {
"answer": {
"description": "the final answer"
}
},
"required": ["answer"]
}
}3.2 框架构成
1、数据构建:通过自动化数据构建方法生成推理链。给定一个多跳问题,模型会生成一系列的推理思考和动作,直到选择完成动作或达到最大迭代次数Tmax。
2、模型微调:使用构建的数据集对ReaRAG进行监督微调(SFT),优化模型在推理过程中的表现。
- 思考-行动-观察范式:训练模型以生成思考(推理步骤)、行动(搜索查询或完成命令),并结合观察(检索到的信息)
- 损失掩码:损失仅在思考和行动的 tokens 上计算,而不是在观察的 tokens 上计算(这些 tokens 来自外部来源)
- 格式规范:训练数据遵循特定的格式,该格式区分思考、行动和观察
3、推理阶段:在推理阶段,ReaRAG迭代执行搜索动作,直到选择完成动作。模型通过外部知识引导推理过程,检测错误并调整推理路径。
- 初始推理:给定一个问题,模型首先进行深思熟虑的思考,以了解它需要哪些信息
- 行动选择:根据其推理,模型决定是否:
- 执行带有特定查询的
Search行动 - 选择带有最终答案的
Finish行动
- 执行带有特定查询的
- 知识整合:当选择
Search行动时,模型将检索到的信息整合到其推理中 - 反思和完善:模型反思其推理轨迹,检测错误,并根据外部知识调整其推理
- 答案生成:在模型选择
Finish后,它会提取最终答案并生成一个简洁的版本
四、实验结果
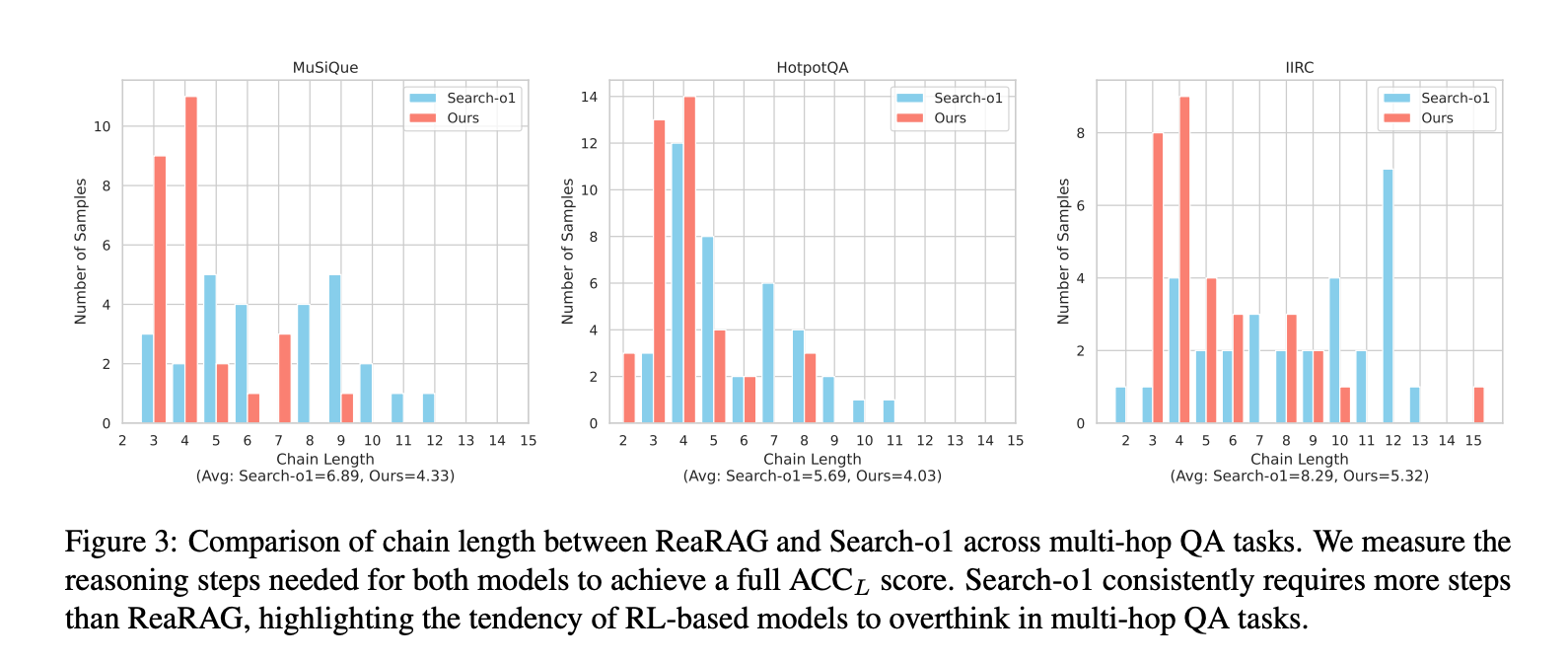
1、在MuSiQue、HotpotQA、IIRC几个多跳QA基准测试上进行实验,与多种基线方法进行比较,分别比最佳基线提高了14.5%、6.5%和2.25%的ACCL分数,以及7%、7%和8.5%的EM分数。
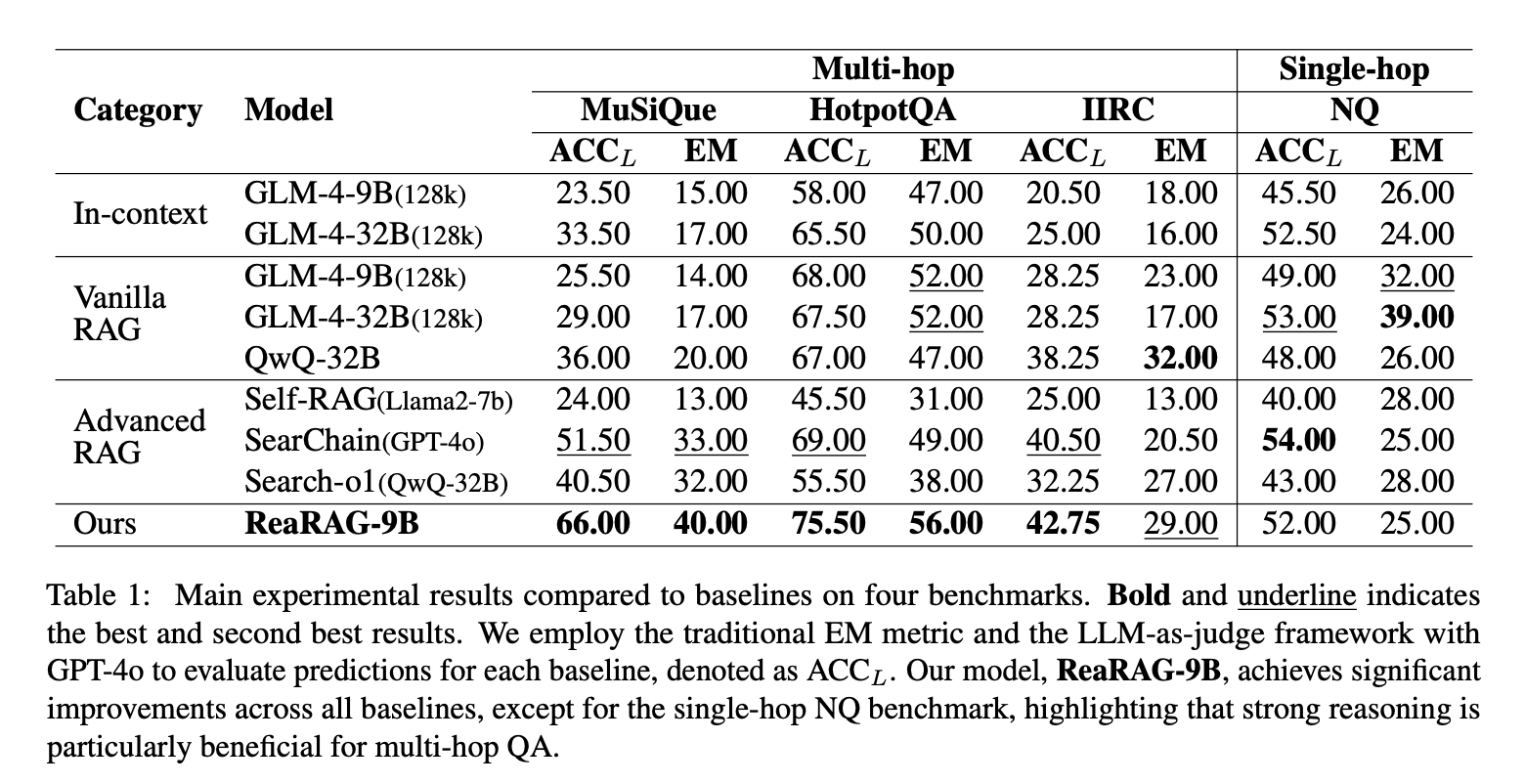
2、在单跳任务NQ上,ReaRAG的表现与Searh-o1相当,但略低于使用GLM-4-32B作为后端的Vanilla RAG。
五、局限性
1、ReaRAG的动作空间目前仅限于搜索和完成,无法执行如代码编译、数学计算或实时网络搜索等操作,限制了其在多样化问题领域的适应性。
2、数据构建过程依赖于LRM的强大指令遵循能力,但由于有效性问题,大量数据被丢弃,导致计算效率低下和资源浪费。
3、ReaRAG通过多次推理步骤迭代解决问题,虽然提高了准确性,但也增加了推理时间。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









