




链式思维(Chain of Thought,CoT)推理能够提升语言模型的性能,但往往会在简单问题上导致低效的“过度思考”。我们发现,现有的直接惩罚推理长度的方法未能考虑到不同问题的复杂性差异。我们的方法通过长度和质量的比较来构建奖励机制,基于理论假设共同提升解决方案的正确性和简洁性。此外,我们还进一步将我们的方法应用于没有绝对真值的模糊任务中。在多个推理基准测试中的实验表明,我们的方法在保持准确性的同时,能够生成显著更简洁的解释,有效地教导模型“在需要时才思考”。
一、背景动机
论文题目:Think When You Need: Self-Adaptive Chain-of-Thought Learning
论文地址:https://arxiv.org/pdf/2504.03234v1
链式思考(CoT)推理能够显著提升语言模型在推理任务中的表现,但这种推理方式在处理简单问题时往往会导致不必要的“过度思考”,从而降低效率。
现有方法主要通过直接对回答长度进行惩罚来解决这一问题,但这种方法未能考虑到问题的复杂性差异,并且需要谨慎设计和调整超参数。此外简单问题可能只需要简短的回答,而复杂问题则需要更详细的解释。因此,统一地对长回答进行惩罚可能会损害模型在更复杂问题上的性能。
该文章提出了一种新的自适应链式思考学习方法,通过基于成对比较的奖励算法,有效地解决了语言模型在推理任务中的“过度思考”问题,同时保持了高性能。
二、核心贡献
1、提出了一种新的奖励算法,通过比较样本对之间的长度和质量来构建奖励,而不是直接对回答长度进行惩罚。这种方法基于理论假设,能够同时提高解决方案的正确性和简洁性。
2、文章将该方法应用于没有明确真值的模糊任务,提供了一种在没有明确真值的情况下进行高效学习的方法。
三、实现方法
1、基于成对比较的奖励算法:该方法通过定义样本对之间的成对奖励来计算每个样本的累积奖励。具体来说,对于从 N 个样本中采样的两个样本 mi 和 mj,如果它们满足特定的成对条件 sl,则它们之间的成对奖励定义为
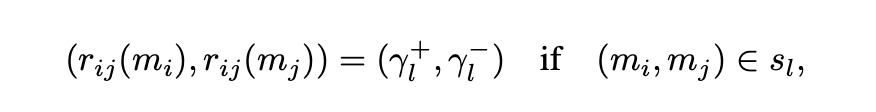
其中 mi 是正样本,mj 是负样本,分别获得奖励 γl+ 和 γl−。
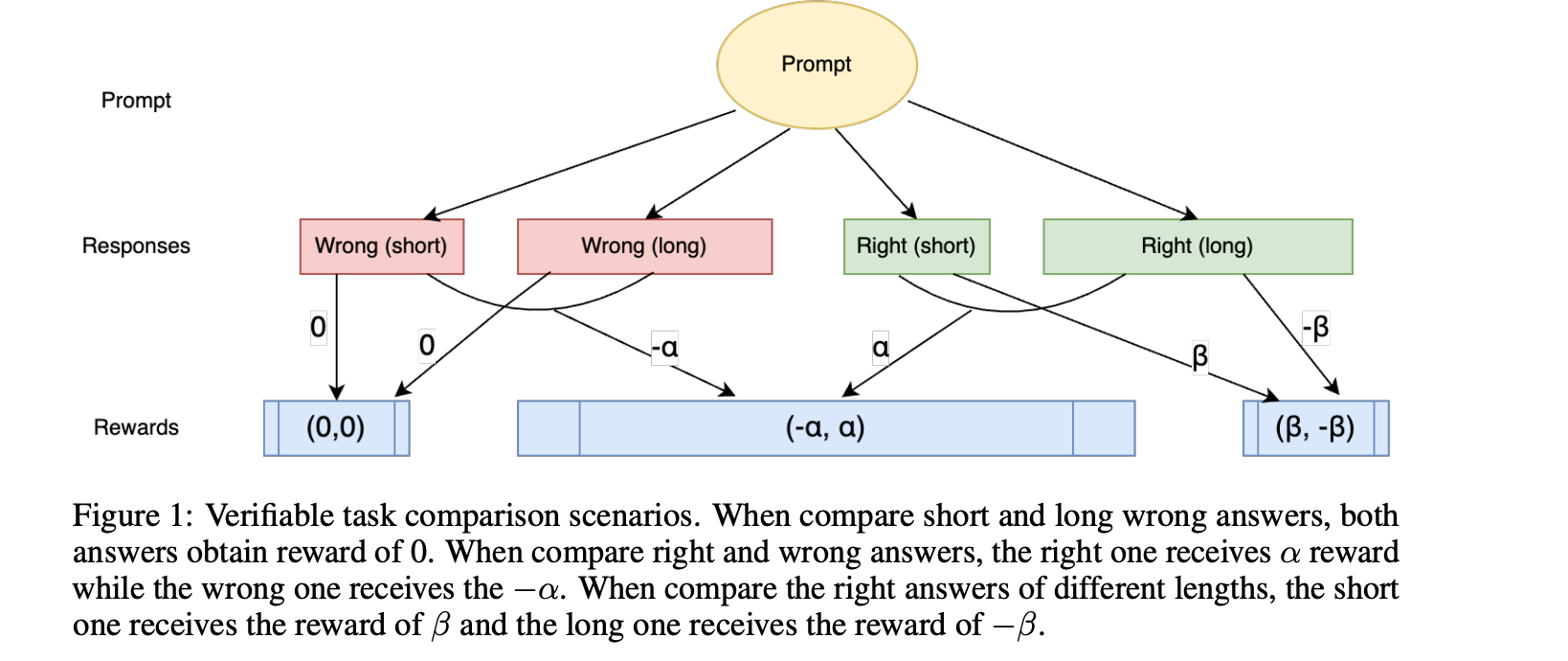
2、可验证任务设置:在有明确真值答案的推理任务中,根据回答的正确性对回答进行分类,并基于以下假设建立成对奖励场景:
- 假设 1:正确答案获得的奖励高于错误答案。
- 假设 2:在正确答案中,较短的回答获得的奖励高于较长的回答。
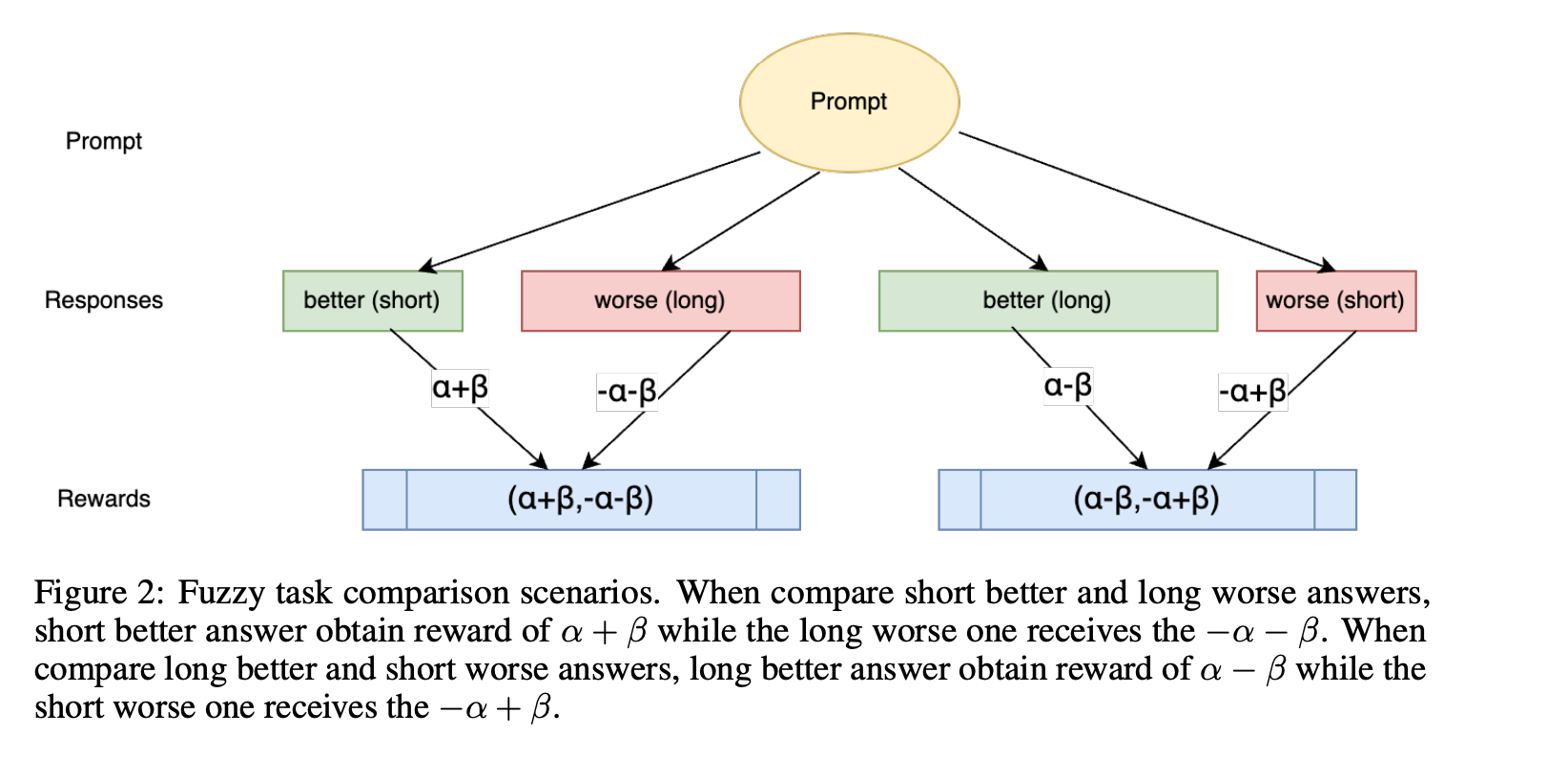
3、模糊任务设置:在没有明确真值答案的任务中,根据回答的质量和长度建立成对奖励场景:
- 假设 5:更好的回答获得的奖励高于较差的回答。
- 假设 6:较长的回答会受到额外的惩罚。
四、实验结果
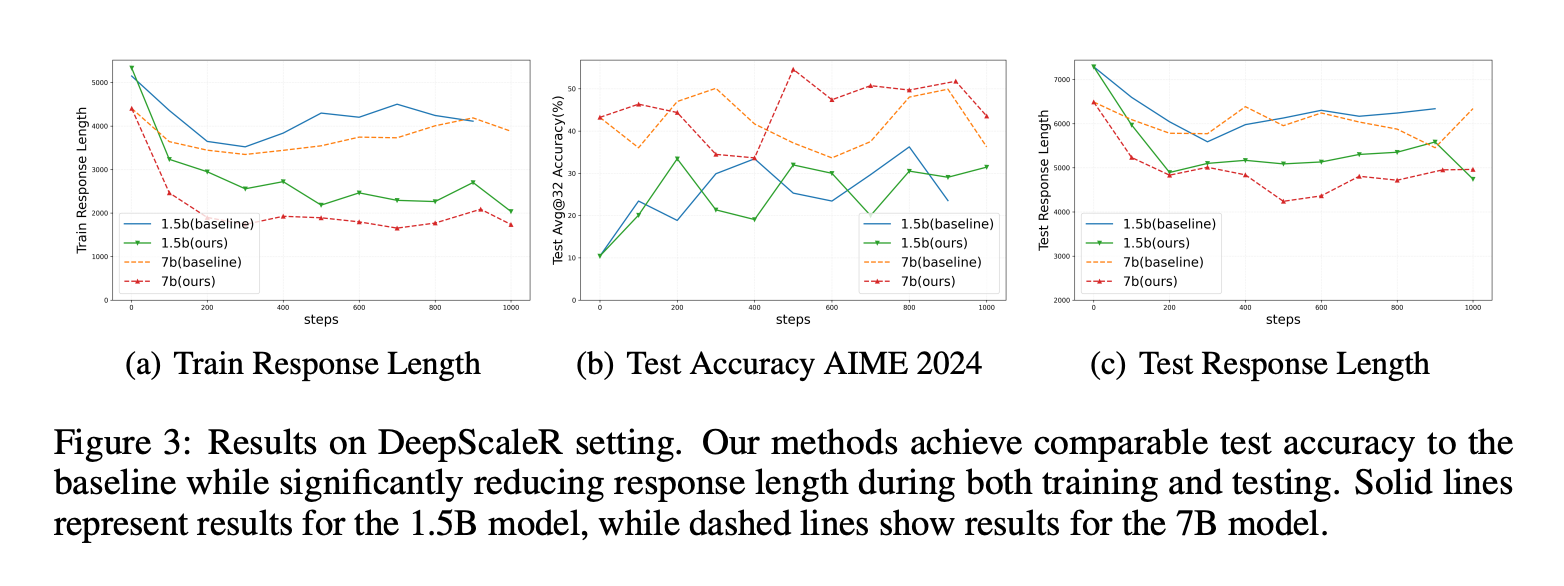
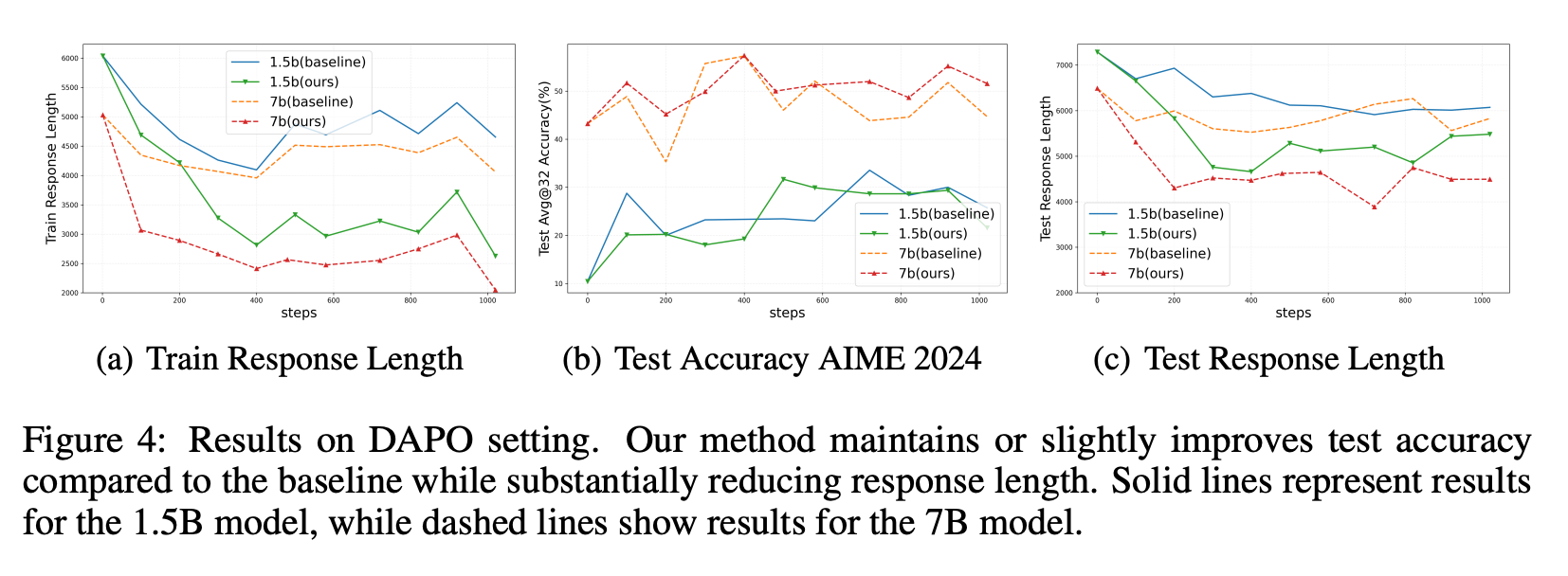
1、使用 DeepSeek-R1-Distill-Qwen-1.5B 和 7B 模型进行实验,采用 AdamW 优化器,最大上下文窗口为 8K。在 DeepScaleR-Preview-Dataset 上,该方法在训练过程中显著减少了回答长度,从超过 4000 个 token 降低到不到 2000 个 token,而基线保持在约 2500 个 token。在测试阶段,该方法保持了与基线相当的准确率,同时在测试中保持了较短的回答长度。
2、在 DAPO-MATH-17K 数据集上,该方法在保持准确率的同时,显著缩短了回答长度。对于 7B 模型,该方法将训练回答长度从超过 4000 个 token 降低到约 2500 个 token,测试回答长度从 6000 个 token 降低到约 4500 个 token。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











