







摘要:我们提出了 REASONIR-8B,这是首个专门针对通用推理任务训练的检索器。现有的检索器在推理任务上表现有限,部分原因是现有的训练数据集侧重于与文档直接相关的简短事实性查询。我们开发了一个合成数据生成流程,针对每篇文档,该流程生成一个具有挑战性且相关的查询,以及一个看似相关但最终无用的困难负样本。通过在合成数据和现有公共数据的混合数据上进行训练,REASONIR-8B 在广泛使用的推理密集型信息检索(IR)基准测试 BRIGHT 上取得了新的最佳成绩:在不使用重排器的情况下,nDCG@10 达到 29.9;使用重排器时,nDCG@10 达到 36.9。在应用于 RAG 任务时,REASONIR-8B 分别将 MMLU 和 GPQA 的性能提升了 6.4% 和 22.6%,与闭卷基线相比,超越了其他检索器和搜索引擎。此外,REASONIR-8B 更有效地利用了测试时的计算资源:在 BRIGHT 上,其性能随着更长、信息更丰富的重写查询而持续提升;即使与大型语言模型(LLM)重排器结合使用时,它仍然超越其他检索器。我们的训练方法具有通用性,可以轻松扩展到未来的 LLM;为此,我们开源了代码、数据和模型。
本文目录
一、背景动机
论文题目:ReasonIR: Training Retrievers for Reasoning Tasks
论文地址:https://arxiv.org/pdf/2504.20595
检索增强生成在事实性问答中被广泛应用。然而,对于需要推理的复杂任务,现有的检索器表现不佳,因为它们主要在简短的事实性查询和直接回答这些问题的文档上进行训练。
为了提升检索器在推理任务中的性能,文章提出了通过合成数据生成和对比训练来专门针对推理任务优化检索器。这种方法旨在生成更具挑战性和相关性的查询和文档对,以提高检索器在推理密集型任务中的表现。
二、核心贡献
- 提出了 ReasonIR-8B,这是第一个专门为推理任务训练的双编码器检索器。开发了 ReasonIR-SYNTHESIZER,一个用于合成推理密集型检索数据的框架,用于对比训练。
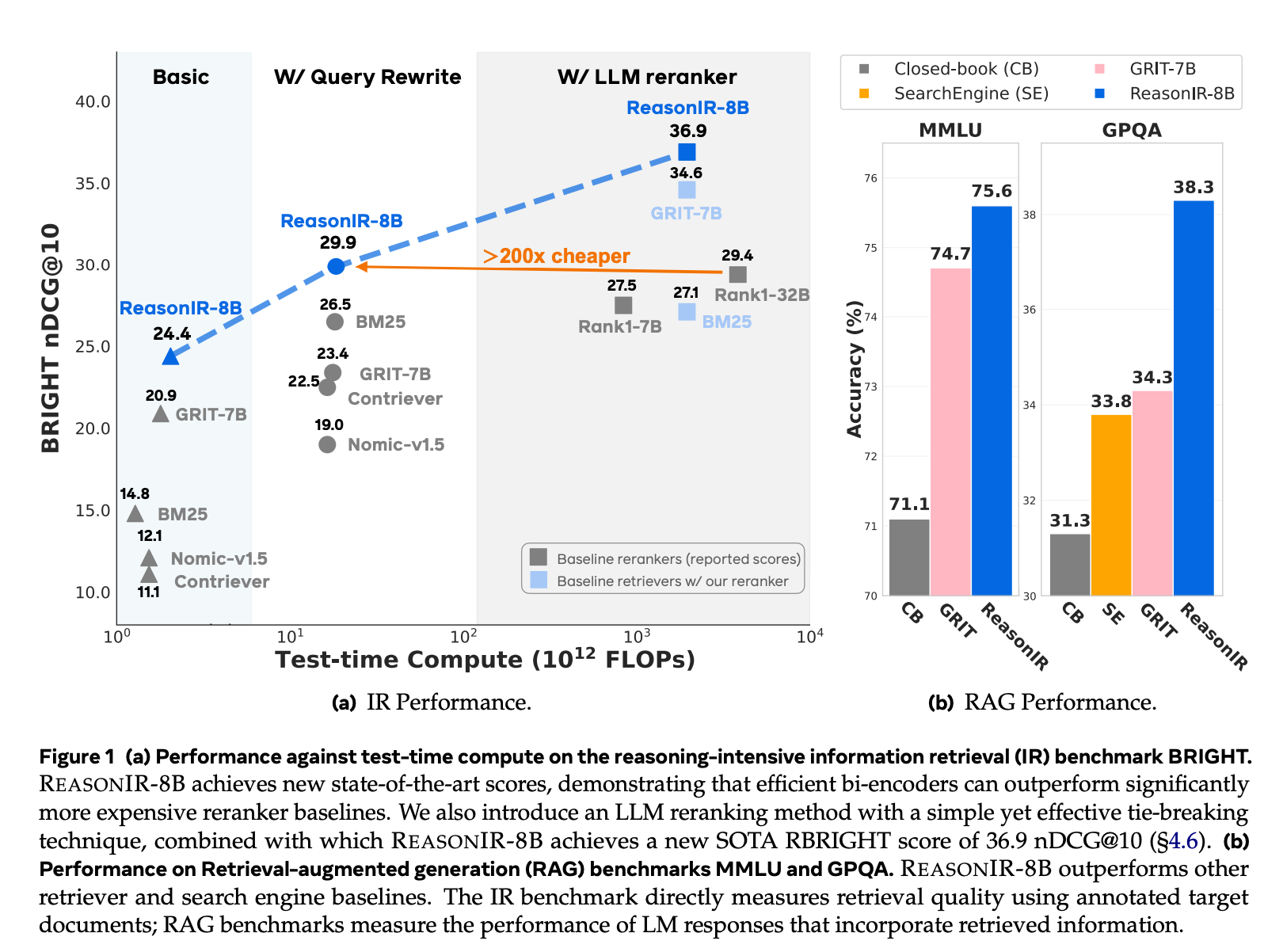
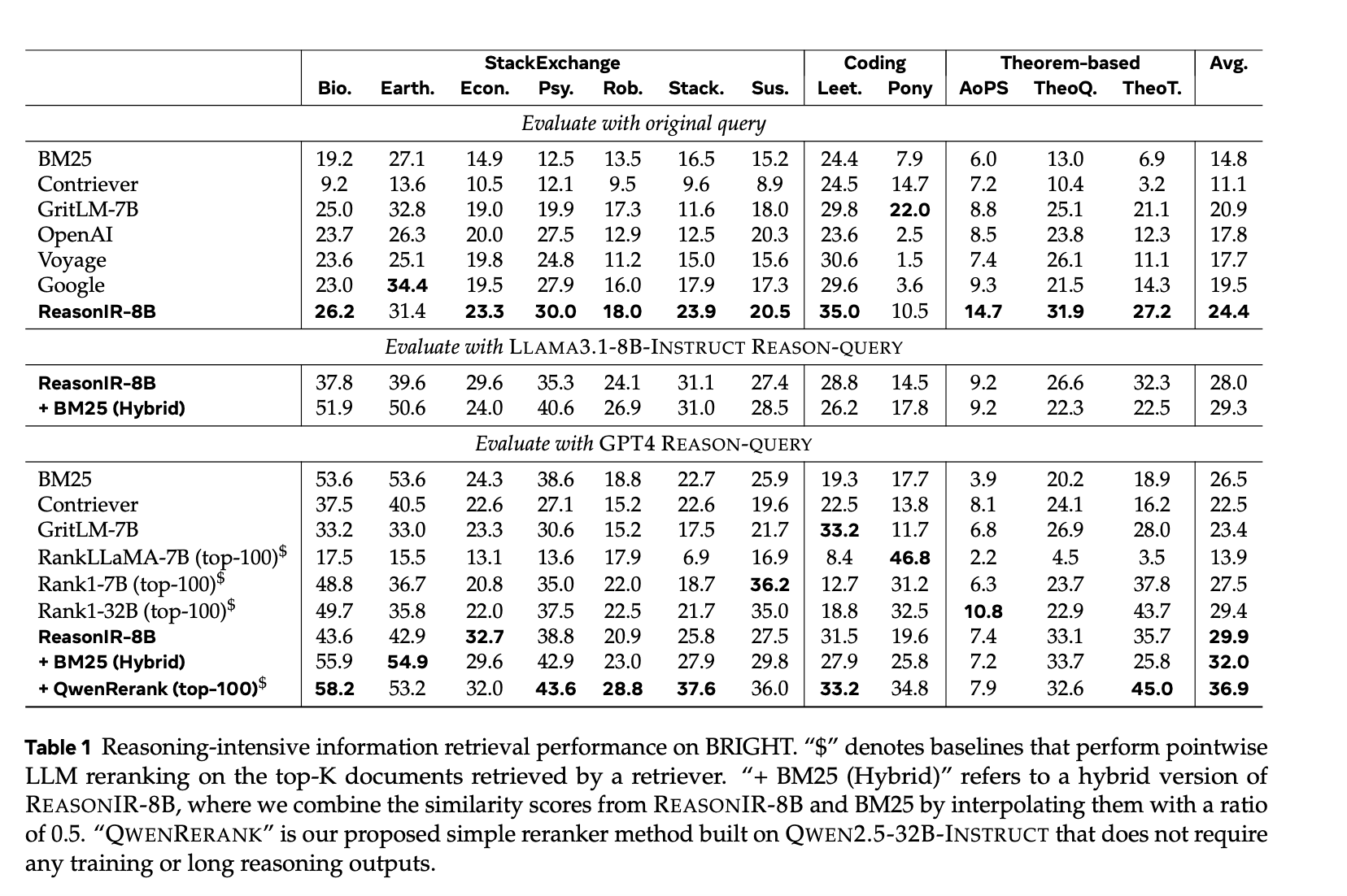
- 在 BRIGHT 基准测试中,ReasonIR-8B 实现了新的最佳性能,nDCG@10 分数达到 29.9(无重排序器)和 36.9(有重排序器)。
- 在 RAG 任务中,ReasonIR-8B 显著提升了 MMLU 和 GPQA 的性能,分别比封闭书本基线提高了 6.4% 和 22.6%。
- 提出了一种简单有效的重排序方法 ReasonIR-Rerank,该方法在推理密集型检索任务中表现优于现有的重排序器。
三、实现方法
3.1 合成数据生成
1、多样化长度数据(VL)
-
目的:扩展检索器对查询的有效上下文长度,使其能够处理更长、更复杂的查询。
-
生成方法:首先,使用 LLM 生成一系列不同长度的查询(300-2000 词)。然后,为每个查询生成一个对应的正文档。这些查询和文档的长度变化较大,以帮助检索器适应不同长度的输入。
2、推理密集型查询(HQ)
-
目的:生成更具挑战性的推理密集型查询,这些查询需要推理才能回答,而不仅仅是简单的关键词匹配。
-
生成方法:
-
种子文档选择:从高质量的文档池中选择推理相关的文档作为种子文档。这些文档涵盖了生物学、经济学、数学等多个领域。
-
查询生成:基于种子文档,使用 LLM 生成推理密集型查询。这些查询需要结合文档中的背景知识和推理模式来回答。
-
3、多轮硬负样本生成
-
目的:为每个查询生成看似相关但实际上无帮助的硬负样本文档,以增加训练的难度。
-
生成方法:在多轮对话中,基于查询和正文档生成硬负样本。这些负样本在表面上与查询有词汇重叠,但实际内容与查询无关。

3.2 对比训练
-
训练目标:通过对比学习,优化检索器将查询嵌入到与相关文档更接近的嵌入空间中。
-
训练数据:结合公共数据集(如 MS MARCO、Natural Questions 等)、多样化长度数据(VL)和推理密集型查询数据(HQ)进行训练。
-
训练细节:
-
使用 LLAMA3.1-8B 作为基础模型。
-
使用双向注意力掩码(bi-directional attention mask)以适应检索任务。
-
使用对比学习目标,优化检索器将查询嵌入到与相关文档更接近的嵌入空间中。
-
使用 GradCache 和跨设备负样本技术,以支持大规模训练。
-
3.3 测试时技术
-
查询重写:通过扩展查询长度,增加查询中的信息量,以提高检索性能。
-
方法:使用 LLM 重写查询,使其更具信息量和推理能力。
-
示例:将一个简单的查询扩展为一个详细的推理问题。
-
-
重排序器:使用 LLM 重排序器对检索到的文档进行重新排序,进一步提升检索质量。
-
方法:提出了一种简单的重排序方法 ReasonIR-Rerank,通过插值检索器分数和重排序器分数来打破平局。
-
示例:使用 Qwen-32B 作为重排序器,结合检索器分数和重排序器分数进行最终评分。
-
四、实验结果
4.1 信息检索(IR)性能
-
基准测试:使用 BRIGHT 基准测试评估推理密集型信息检索性能,使用 nDCG@10 作为评估指标。
-
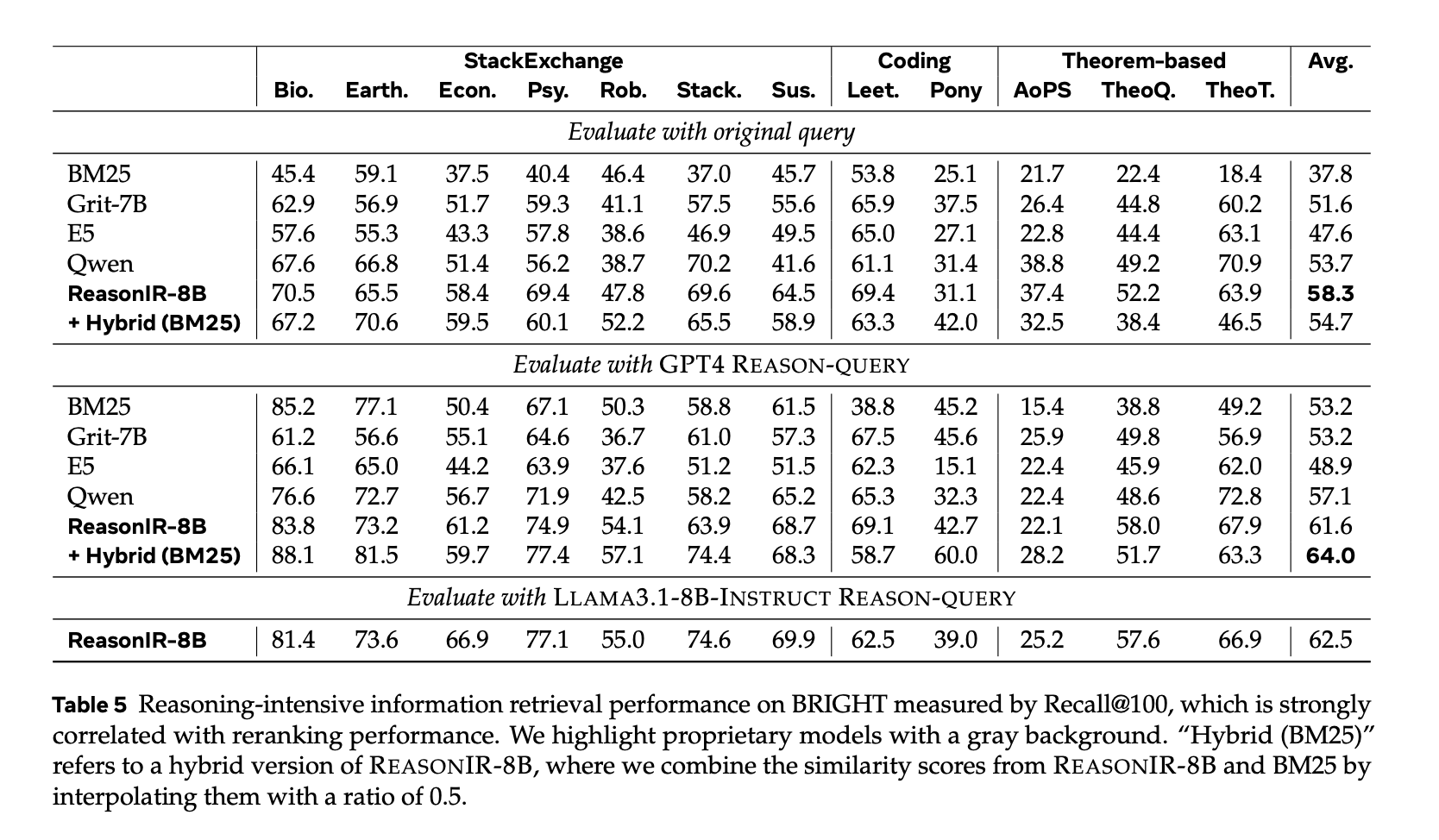
原始查询:ReasonIR-8B 实现了 24.4 的 nDCG@10 分数,显著优于其他检索器(如 BM25、GRIT-7B 等)。
-
重写查询:使用 GPT4 重写查询后,ReasonIR-8B 实现了 29.9 的 nDCG@10 分数,进一步提升了性能。
-
结合重排序器:与 QwenRerank 结合时,ReasonIR-8B 实现了 36.9 的 nDCG@10 分数,优于其他检索器和重排序器的组合。
4.2 检索增强生成(RAG)性能
-
基准测试:使用 MMLU 和 GPQA 基准测试评估推理密集型 RAG 任务的性能。
-
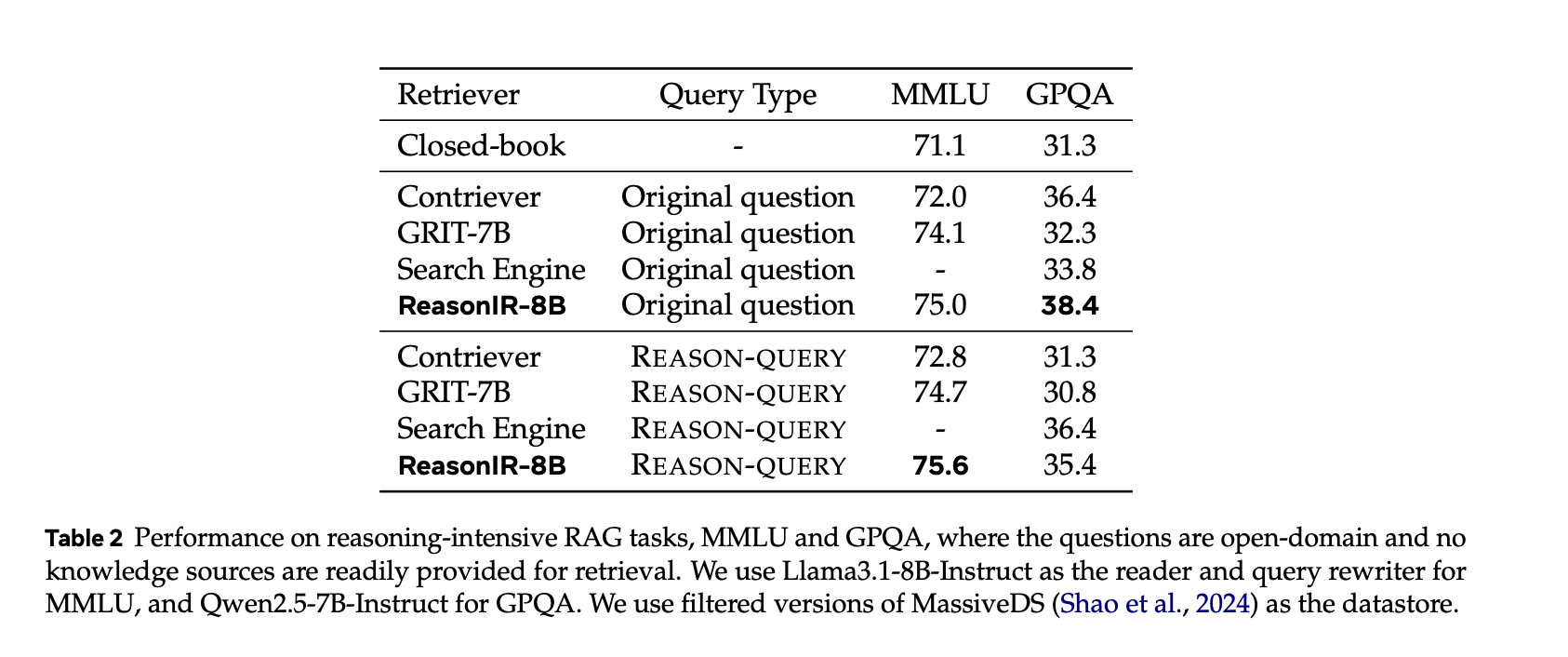
MMLU:ReasonIR-8B 将性能从封闭书本基线的 71.1 提升到 75.6,相对提升了 6.4%。
-
GPQA:ReasonIR-8B 将性能从封闭书本基线的 31.3 提升到 38.4,相对提升了 22.6%。
-
与搜索引擎比较:在 GPQA 上,ReasonIR-8B 的表现优于 You.com 搜索引擎。
4.3 测试时扩展
-
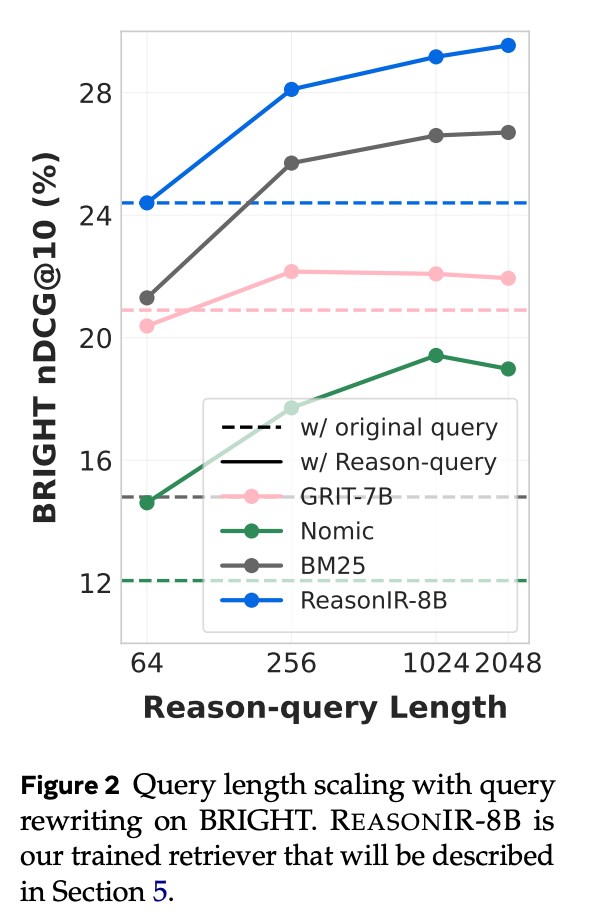
查询长度扩展:ReasonIR-8B 能够有效利用更长的重写查询,而其他检索器在查询长度增加时性能提升有限或甚至下降。在 BRIGHT 上,随着查询长度从 64 词增加到 2048 词,ReasonIR-8B 的性能持续提升,而其他检索器(如 GRIT-7B 和 Nomic-v1.5)的性能提升有限。
4.4 与重排序器结合
-
重排序器性能:ReasonIR-8B 与 QwenRerank 结合时,在 BRIGHT 上取得了 36.9 的 nDCG@10 分数,优于其他检索器和重排序器的组合。
-
计算效率:ReasonIR-8B 在测试时的计算效率远高于传统的重排序器(如 Rank1-32B),在推理密集型任务中表现更优。
4.5 消融研究
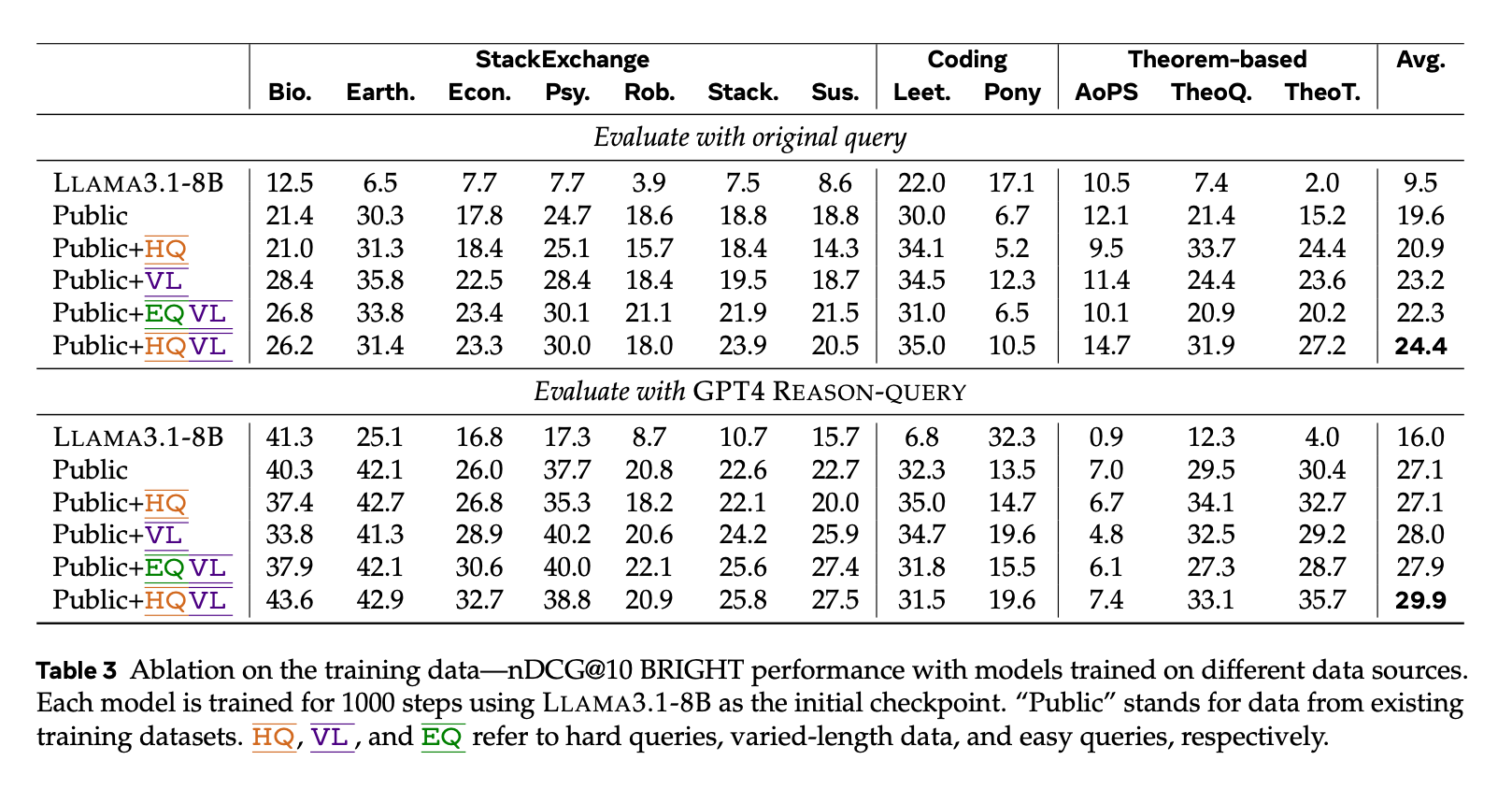
- 单独使用 VL 数据:在原始查询上表现最佳,nDCG@10 分数为 23.2。
-
单独使用 HQ 数据:在重写查询上表现最佳,nDCG@10 分数为 28.5。
-
结合 VL 和 HQ 数据:在原始查询和重写查询上均取得了最佳性能,nDCG@10 分数分别为 24.4 和 29.9。
五、总结
ReasonIR-8B是一种专门为推理任务设计的检索器,旨在解决传统检索器在处理复杂推理任务时的局限性。ReasonIR-8B基于LLaMA3.1-8B模型,并进行了关键修改,包括注意力掩码从因果关系更改为双向,以提高嵌入质量,从而更好地捕捉查询和文档之间的复杂关系。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











