






摘要:我们介绍了LLaVA-MoD,这是一个旨在高效训练小型多模态语言模型(s-MLLM)的创新框架,通过从大规模多模态语言模型(l-MLLM)中提取知识来实现。我们的方法解决了多模态语言模型(MLLM)蒸馏中的两个基本挑战。首先,我们通过将稀疏的专家混合(MoE)架构整合到语言模型中,优化了s-MLLM的网络结构,从而在计算效率和模型能力之间取得了平衡。其次,我们提出了一种渐进式知识转移策略,用于全面的知识转移。这种策略从模仿蒸馏开始,通过最小化输出分布之间的Kullback-Leibler(KL)散度,使s-MLLM能够模仿l-MLLM的理解能力。随后,我们引入了通过偏好优化(PO)的偏好蒸馏,其中关键在于将l-MLLM视为参考模型。在这一阶段,s-MLLM辨别优劣示例的能力显著增强,甚至超过了l-MLLM,从而在幻觉基准测试中表现更优。广泛的实验表明,LLaVA-MoD在各种基准测试中超越了现有工作,同时保持了极小的激活参数和低计算成本。值得注意的是,LLaVA-MoD-2B仅使用了0.3%的训练数据和23%的可训练参数,就超越了Qwen-VL-Chat-7B,平均提升了8.8%。这些结果突显了LLaVA-MoD从其教师模型中有效提取全面知识的能力,为高效多模态语言模型的发展铺平了道路。
本文目录
一、背景动机
论文题目:LLAVA-MOD: MAKING LLAVA TINY VIA MOEKNOWLEDGE DISTILLATION
论文地址:https://openreview.net/pdf?id=uWtLOy35WD
MLLMs通过将视觉编码器与大型语言模型(LLMs)结合,在多模态任务中展现出巨大潜力。然而,这些模型的庞大尺寸和对大量训练数据的依赖带来了显著的计算挑战,例如训练成本高昂、推理速度慢,限制了其在实际应用中的部署,尤其是在移动设备等资源受限的环境中。
为了在性能和效率之间取得平衡,更多的人开始探索小型多模态语言模型(s-MLLMs)。然而,以往的研究主要集中在高质量数据的收集和筛选上,这些方法虽然有效,但受限于模型容量,难以进一步提升性能。
知识蒸馏是一种通过将大型模型的知识转移到小型模型来提升其性能的技术。通过使小型模型的输出分布与大型模型对齐,可以使其利用大型模型中嵌入的丰富知识,从而在不显著增加计算成本的情况下提升性能。该文章提出了LLaVA-MoD(Multimodal Language Model via Mixture-of-Expert Knowledge Distillation)新型框架,旨在通过知识蒸馏从大规模多模态语言模型(l-MLLM)中高效训练小型多模态语言模型(s-MLLM)。
二、核心贡献
1、提出LLaVA-MoD框架,该框架通过结合稀疏的Mixture-of-Experts(MoE)架构和知识蒸馏技术,解决了从大规模MLLM到小型MLLM的知识转移问题。
2、优化s-MLLM的网络结构,其通过在语言模型中集成MoE架构,平衡了计算效率和模型能力,使小型模型能够在保持高效的同时吸收复杂知识。
3、提出渐进式知识转移策略,该策略包括模仿蒸馏和偏好蒸馏两个阶段,模仿蒸馏通过最小化输出分布的 KL 散度,使s-MLLM能够模仿l-MLLM的理解能力;偏好蒸馏则通过偏好优化,显著增强了s-MLLM在区分优劣样本方面的能力,使其在幻觉基准测试中超越l-MLLM。
三、实现方法
3.1 结构设计
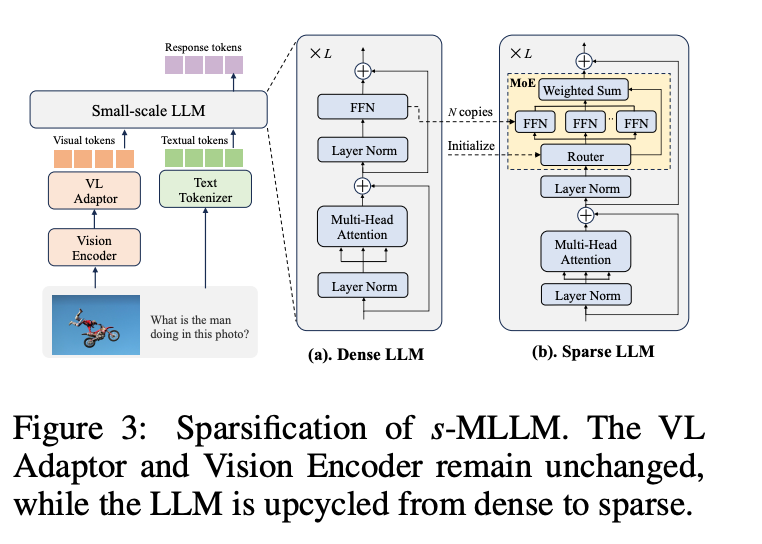
LLaVA-MoD的s-MLLM由三个主要部分组成:视觉编码器(Vision Encoder)、大型语言模型(LLM)和视觉-语言适配器(VL Adaptor)。为了在保持训练和推理效率的同时,增强模型对复杂多模态知识的捕捉能力,文章在LLM中引入了稀疏的Mixture-of-Experts(MoE)架构。
具体来说,他们将LLM中的前馈网络(FFN)复制为多个专家模块,并引入一个线性层作为路由器,动态地激活最相关的专家模块。这种设计允许s-MLLM在不同的输入下选择性地激活最相关的专家,从而在保持计算效率的同时,有效地吸收来自l-MLLM的知识。
3.2 渐进式知识转移策略
LLaVA-MoD采用了两阶段的渐进式知识转移策略,包括模仿蒸馏(Mimic Distillation)和偏好蒸馏(Preference Distillation)。
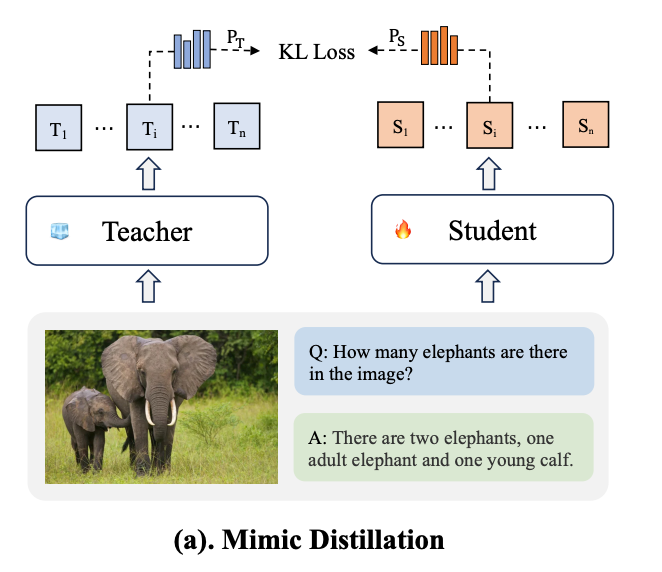
- 模仿蒸馏(Mimic Distillation)
- 在密集到密集(Dense-to-Dense, D2D)阶段,通过最小化s-MLLM和l-MLLM输出分布之间的Kullback-Leibler(KL)散度,使s-MLLM能够模仿l-MLLM的理解能力。
- 密集到稀疏(Dense-to-Sparse, D2S)阶段,则将s-MLLM从密集结构转换为稀疏结构,并使用多任务数据集进行蒸馏,以获取更复杂的专门知识。
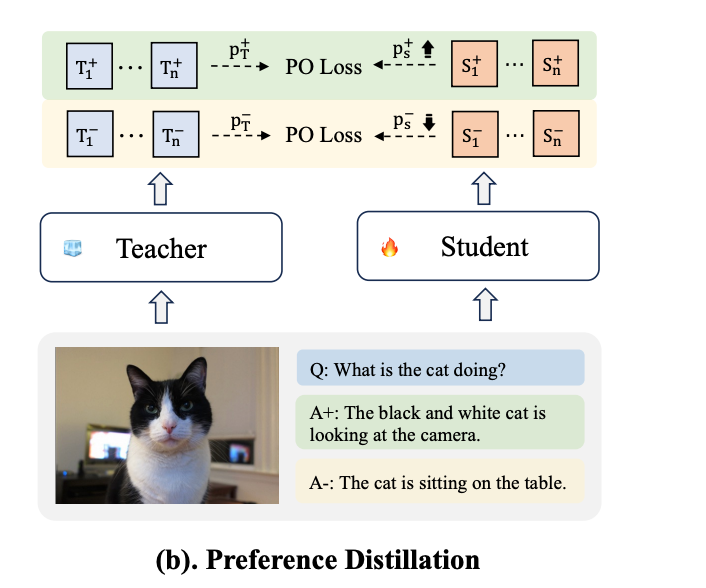
- 偏好蒸馏(Preference Distillation):
- 在这一阶段,l-MLLM提供关于“好”和“坏”样本的知识,作为s-MLLM的参考。s-MLLM利用这些知识调整其概率分布,确保对好样本的预测概率高于l-MLLM,而对坏样本的预测概率低于l-MLLM。这一过程显著增强了s-MLLM在减少幻觉(hallucination)方面的能力,使其在幻觉基准测试中超越了l-MLLM。
四、实验结论
4.1 性能优势
-
多模态理解基准测试(Comprehension-Oriented Benchmarks)
-
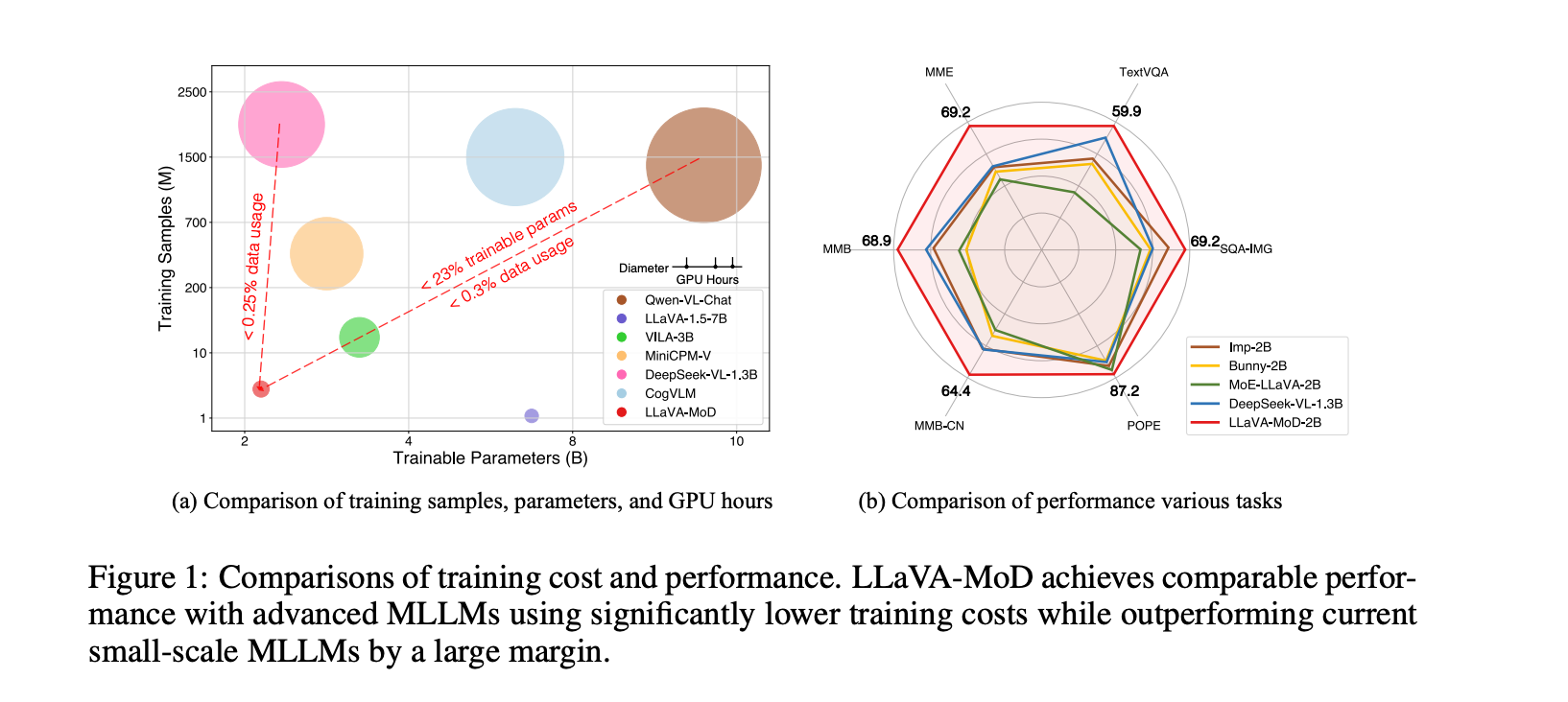
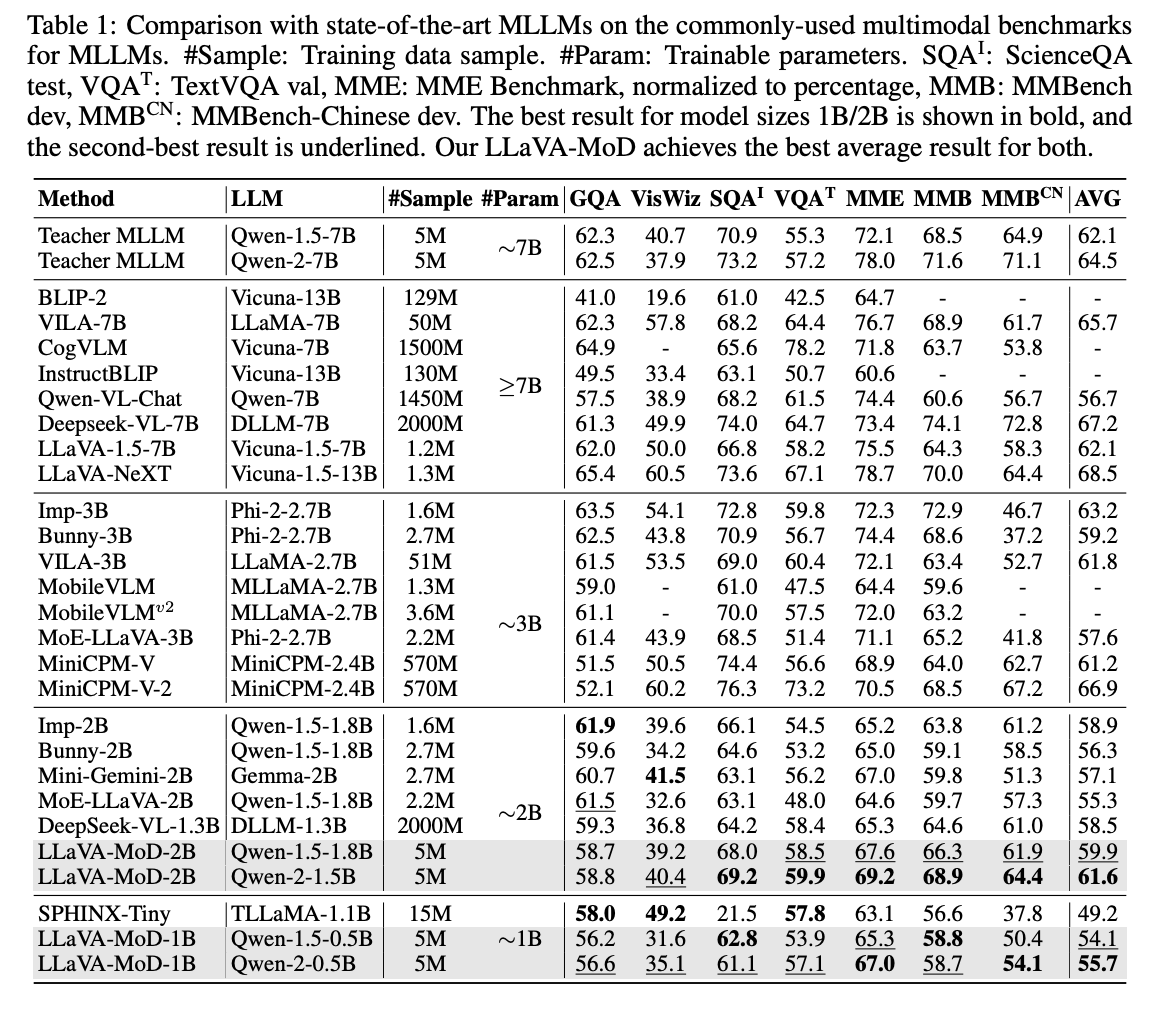
LLaVA-MoD在多个多模态基准测试中取得了最佳平均结果。2B大小的LLaVA-MoD在多个基准测试中超过了Mini-Gemini-2B(Li et al., 2024)8.1%,并且在使用较低图像分辨率(336 vs. 768)的情况下实现了这一优势。
-
此外,LLaVA-MoD-2B在性能上与大型多模态语言模型(如Qwen-VL-Chat-7B)相匹配,甚至在某些基准测试中超过了它们。
-
-
幻觉基准测试(Hallucination-Oriented Benchmarks)
-
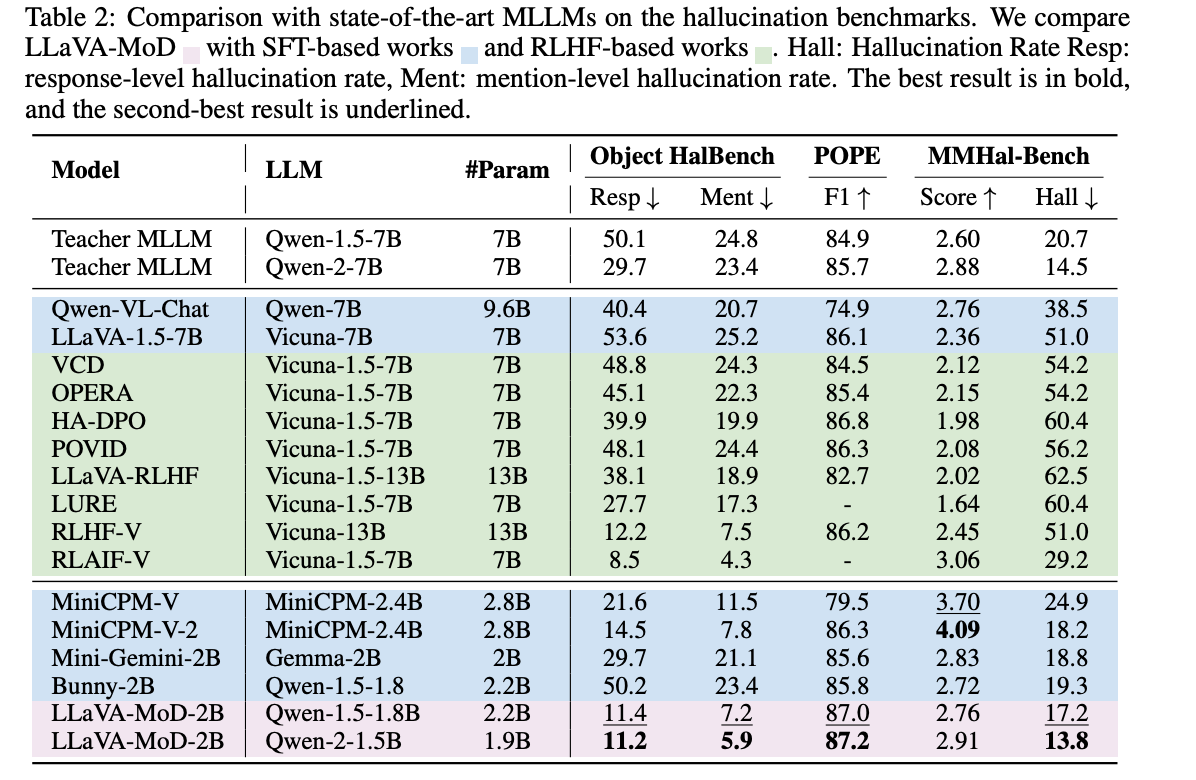
LLaVA-MoD在减少幻觉方面表现出色,甚至超过了其教师模型。在Object HalBench上,LLaVA-MoD-2B在响应级幻觉率和提及级幻觉率上分别比RLHF-V(Yu et al., 2024a)低8.2%和21.3%。这表明偏好蒸馏在最小化幻觉方面非常有效。
-
4.2 效率优势
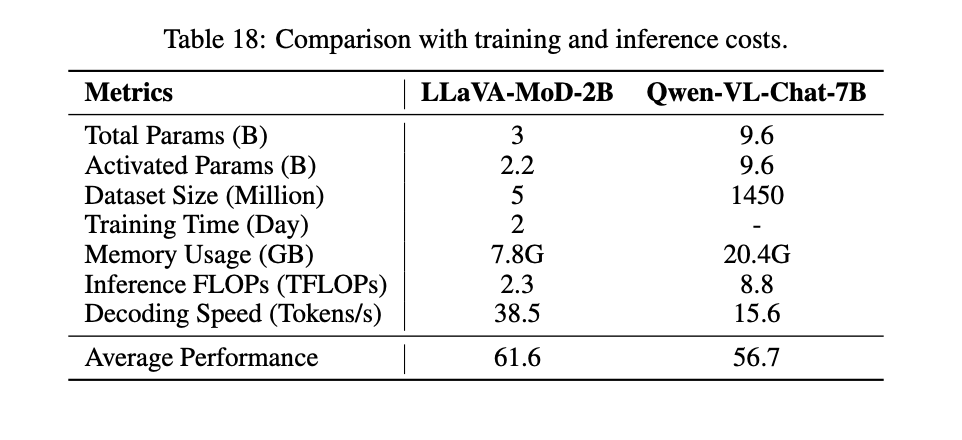
LLaVA-MoD在训练和推理方面都表现出显著的效率。与Qwen-VL-Chat-7B相比,LLaVA-MoD-2B仅使用了0.3%的训练数据和23%的可训练参数,同时在单个A100-80G GPU上的解码速度提高了2.5倍,FLOPs降低了26%,内存消耗降低了38%。
五、总结
LLaVA-MoD通过创新的MoE架构和渐进式知识蒸馏策略,有效地从大规模MLLM中提取知识,训练出性能卓越且计算高效的小型多模态语言模型。它在多模态理解和幻觉减少方面均取得了显著成果。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











