







本文选自本人笔记节选,涉及版权,请勿转载。
Partition分区
要求将统计结果按照要求输出到不同文件(分区)中。
默认Partitioner分区
package org.apache.hadoop.mapred.lib;
import org.apache.hadoop.classification.InterfaceAudience;
import org.apache.hadoop.classification.InterfaceStability;
import org.apache.hadoop.mapred.Partitioner;
import org.apache.hadoop.mapred.JobConf;
/**
* Partition keys by their {@link Object#hashCode()}.
*/
@InterfaceAudience.Public
@InterfaceStability.Stable
public class HashPartitioner<K2, V2> implements Partitioner<K2, V2> {
public void configure(JobConf job) {}
/** Use {@link Object#hashCode()} to partition. */
public int getPartition(K2 key, V2 value,
int numReduceTasks) {
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
}
自定义Partitioner步骤
- 自定义类继承Partitioner,重写getPartition()方法
package org.example.mapreduce.partitioner;
import org.apache.hadoop.mapreduce.Partitioner;
public class CustomParitioner extends Partitioner {
@Override
public int getPartition(Object o, Object o2, int numPartitions) {
//控制分区代码逻辑
return numPartitions;
}
}
-
在Job驱动中,设置自定义Partitioner
job.setPartitionerClass(CustomPartitioner.class) -
自定义Partition后,要根据自定义Partition的逻辑设置相应数量的ReduceTask
job.setNumReduceTask(5) -
分区设置
- 如果ReduceTask的数量>getParition的结果数,则会产生几个空的输出文件part-r-000xx;
- 如果ReduceTask的数量<getParition的结果数,则有一部分分区数据无处安放,Exception;
- 如果ReduceTask的数量=1,则不管MapTask端输出多少个分区文件,最终结果都会交给这一个ReduceTask,最终产生一个结果part-r-00000;
- 分区号必须从0开始,逐一累加。
设自定义分区为5
job.setNumReduceTasks(1); //会正常运行,只输出一个文件
job.setNumReduceTasks(2); //Exception
job.setNumReduceTasks(6); //大于5,程序会正常运行,会产生空文件
Partition分区案例实操
需求:将统计结果按照手机归属地不同省份输出到不同文件中。
手机号136、137、138、139开头都分别放到一个独立的4个文件中,其他开头的放到一个文件中。
在序列化案例的基础上增加一个分区类。
package org.example.Writable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
public class ProvincePartitioner extends Partitioner<Text, FlowBean> {
@Override
public int getPartition(Text text, FlowBean flowBean, int numPartitions) {
//获取前三位手机号prePhone
String phone = text.toString();
String prePhone = phone.substring(0, 3);
//定义一个分区号变量partition,根据prePhone设置分区号
int partition;
if("136".equals(prePhone)){
partition = 0;
}else if("137".equals(prePhone)){
partition = 1;
}else if("138".equals(prePhone)){
partition = 2;
}else if("139".equals(prePhone)){
partition = 3;
}else {
partition = 4;
}
//最后返回分区号partition
return partition;
}
}
在驱动函数中增加自定义数据分区设置和ReduceTask设置
public class FlowDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//1 获取job对象
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
//2 关联本Driver类
job.setJarByClass(FlowDriver.class);
//3 关联Mapper和Reducer
job.setMapperClass(FlowMapper.class);
job.setReducerClass(FlowReducer.class);
//4 设置Map端输出KV类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(FlowBean.class);
//5 设置程序最终输出的KV类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
//8 指定自定义分区器
job.setPartitionerClass(ProvincePartitioner.class);
//9 同时指定相应数量的ReduceTask
job.setNumReduceTasks(5);
//6 设置程序的输入输出路径
FileInputFormat.setInputPaths(job, new Path("W:\\IOput\\flowinput"));
FileOutputFormat.setOutputPath(job, new Path("W:\\IOput\\flowoutput"));
//7 提交Job
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
运行结果图
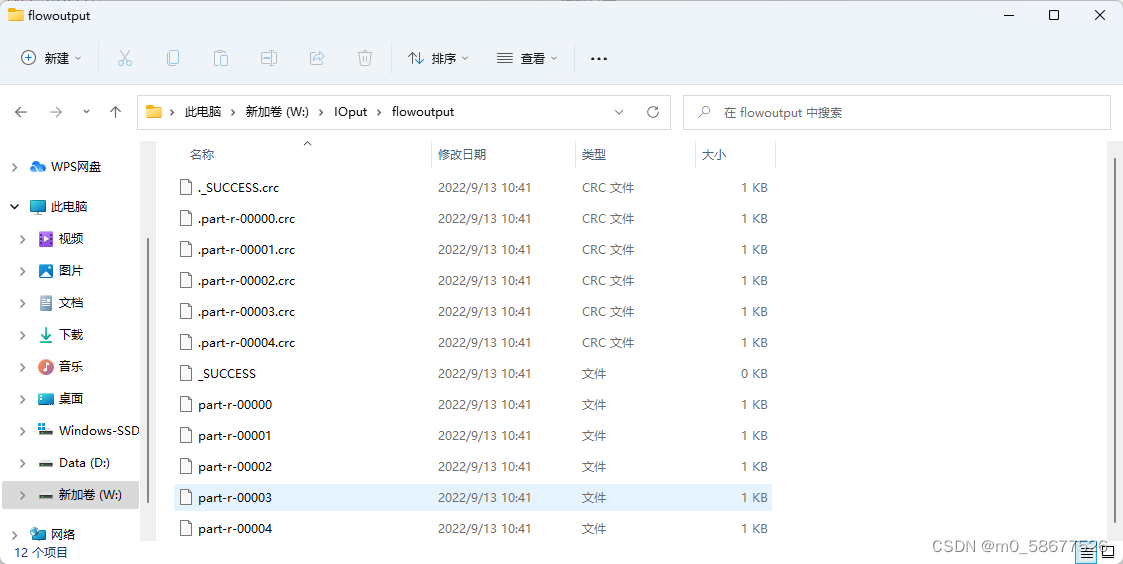
本文选自本人笔记节选,涉及版权,请勿转载。















 861
861











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









