






目录
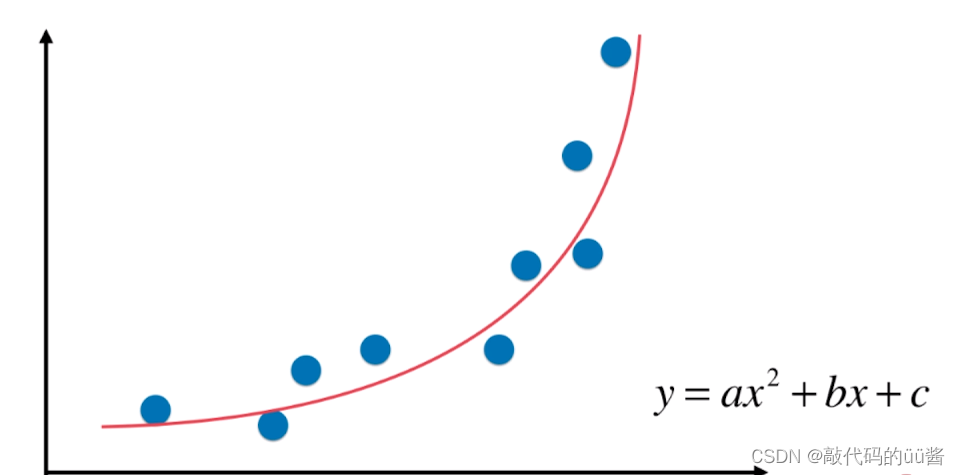
一、什么是多项式回归
假设所有的样本只有一个特征,那么相应的它的方程就可以写成如下式子。在这个式子中,我们将 理解成一个特征,
理解成另外一个特征,即具有一个特征
的样本把它看作是由两个特征构成的数据集。而这个式子本身是一个线性回归的方程,但如果从
的角度来看就是一个非线性的方程,因此称这样的方式叫做多项式回归。
代码示例:
import numpy as np
import matplotlib.pyplot as plt
#生产随机数据100个——范围在(-3,3)
x = np.random.uniform(-3,3,size=100)
X = x.reshape(-1,1)
y = 0.5 *x**2 + x +2 + np.random.normal(0,1,size=100)
from sklearn.linear_model import LinearRegression
lin_reg = LinearRegression()
lin_reg.fit(X,y)
y_predict = lin_reg.predict(X)
plt.scatter(x,y) #原数据
plt.plot(x,y_predict,color='r') #预测值
plt.show()
运行结果:
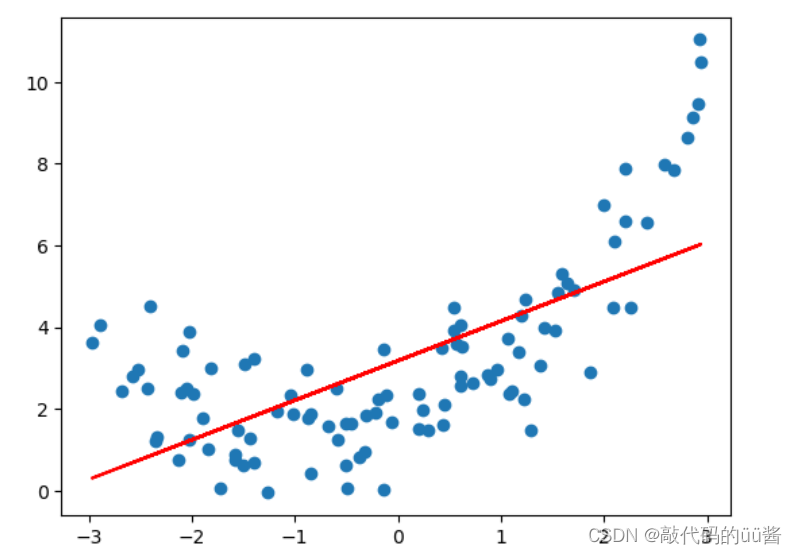
可以看到,拟合效果并不好,因此我们可以添加一个特征。
代码示例:
X2 = np.hstack([X,X**2])
#X2.shape
lin_reg2 = LinearRegression()
lin_reg2.fit(X2,y)
y_predict2 = lin_reg2.predict(X2)
#绘制结果
plt.scatter(x,y)
plt.plot(np.sort(x),y_predict2[np.argsort(x)],color='r') #对x,y_predict2进行排序,光滑展示
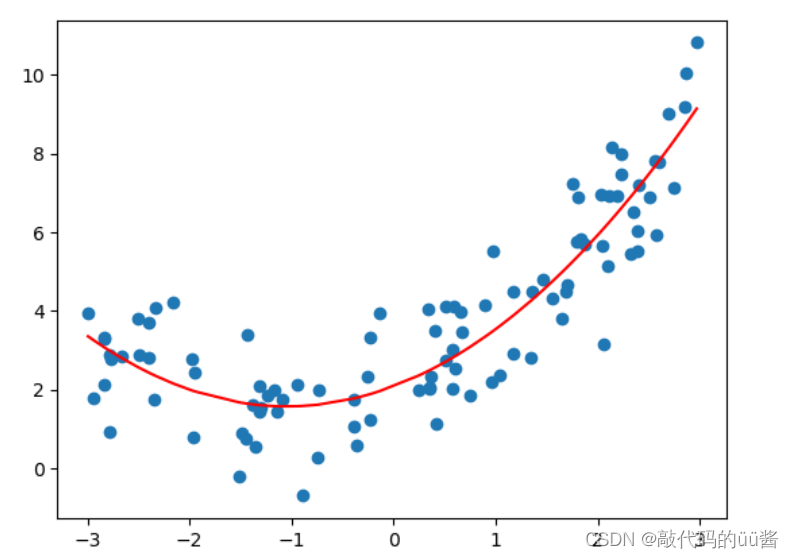
plt.show()运行结果:
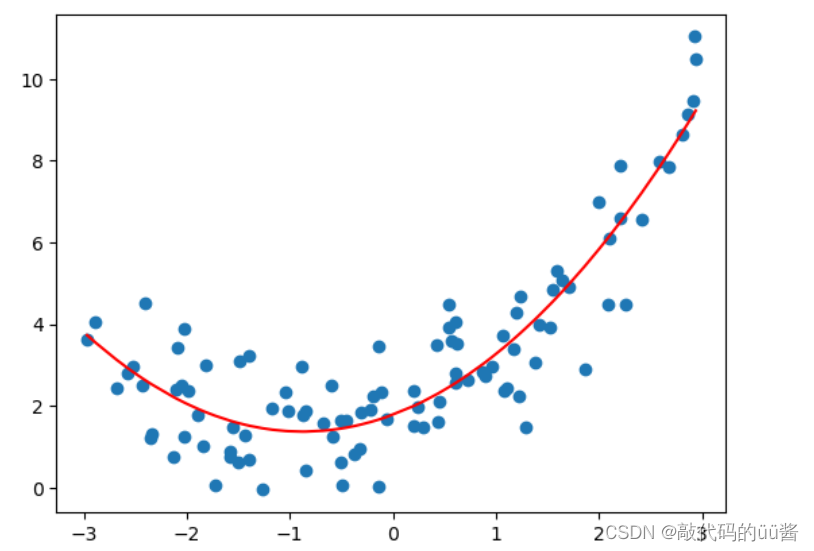
可以看出,经过添加特征 得到的结果拟合效果更好。
多项式回归的思路完全是使用线性回归的思路,它的关键在于向我们原来的数据样本添加新的特征,利用这种多项式组合我们就可以解决一些非线性问题。
二、sklearn中的多项式回归
1、sklearn中的多项式回归
代码示例:
from sklearn.preprocessing import PolynomialFeatures
ploy = PolynomialFeatures(degree = 2) #表示要为原始数据集添加几次幂
ploy.fit(X)
X2 = ploy.transform(X) #将X转换为多项式特征
#X2.shape
from sklearn.linear_model import LinearRegression
lin_reg2 = LinearRegression()
lin_reg2.fit(X2,y)
y_predict2 = lin_reg2.predict(X2)
#绘制结果
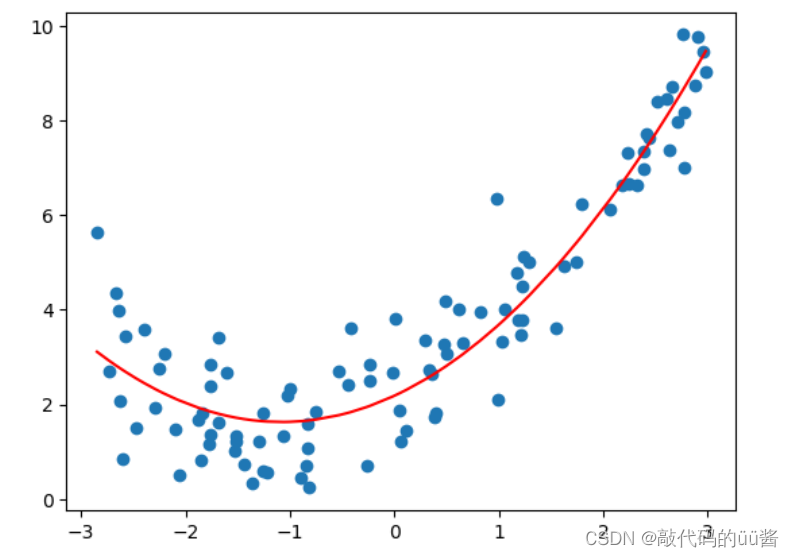
plt.scatter(x,y)
plt.plot(np.sort(x),y_predict2[np.argsort(x)],color='r') #对x,y_predict2进行排序,光滑展示
plt.show()运行结果:
2、关于PolynomialFeatures
代码示例:
X = np.arange(1,11).reshape(-1,2) #随机矩阵
ploy = PolynomialFeatures(degree = 2)
ploy.fit(X)
X2 = ploy.transform(X)
X2
运行结果:

第一列数据为1,对应的就是0次幂;第二列和第三列对应的就是我们原来的矩阵X,第三列就是我们特征X1平方的结果,最后一列就是我们特征X2平方的结果,而中间的第五列就是X1×X2的结果。
因此,对于2次幂的特征,如果原来数据只有x1,x2两个特征,那么会生成3列2次幂特征。那么degree=3呢?

相应的会生成10列3次幂特征。
3、Pipeline管道
代码示例:
x = np.random.uniform(-3,3,size=100)
X = x.reshape(-1,1)
y = 0.5 *x**2 + x +2 + np.random.normal(0,1,size=100)
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import PolynomialFeatures
from sklearn.preprocessing import StandardScaler
#创建管道——使用管道的形式将三步骤合并在一起,可以方便直接调用,
ploy_reg = Pipeline([
("ploy",PolynomialFeatures(degree = 2)),
("std_scaler",StandardScaler()),
("lin_reg",LinearRegression())
])
ploy_reg.fit(X,y)
y_predict = ploy_reg.predict(X)
#验证结果
plt.scatter(x,y)
plt.plot(np.sort(x),y_predict[np.argsort(x)],color='r') #对x,y_predict2进行排序,光滑展示
plt.show()运行结果:















 2570
2570











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









