






Python爬虫实战 ---- 中国大学排名
链接:https://www.shanghairanking.cn/rankings/bcur/2023
源代码
# 获取网页内容
# 提取信息到数据结构,二维列表
# 数据结构展示并输出
import requests
import bs4
def getHTMLText(url):
try:
r = requests.get(url, timeout = 30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
# 从html提取内容放大ulist中
def fillUnivList(ulist, html):
soup = bs4.BeautifulSoup(html,'html.parser')
for tr in soup.find('tbody').children:
if isinstance(tr, bs4.element.Tag):
tds = tr('td')
ulist.append([ tds[0].string.strip(), tds[1].find('a','name-cn').string.strip(), tds[2].text.strip() ,tds[3].text.strip(), tds[4].string.strip() ])
# 打印ulist的num个数据信息
def printUnivList(ulist, num):
tmplt = "{0:^10}\t{1:{5}^10}\t{2:{5}^10}\t{3:{5}^10}\t{4:{5}^10}"
print(tmplt.format('排名', '学校', '地区', '类型', '总分', chr(12288)))
for i in range(num):
u = ulist[i]
u[0] = u[0] if u[0] is not None else "暂无信息"
u[1] = u[1] if u[1] is not None else "暂无信息"
u[2] = u[2] if u[2] is not None else "暂无信息"
u[3] = u[3] if u[3] is not None else "暂无信息"
u[4] = u[4] if u[4] is not None else "暂无信息"
print(tmplt.format(u[0], u[1], u[2], u[3], u[4], chr(12288)))
def main():
uinfo = []
url = 'https://www.shanghairanking.cn/rankings/bcur/2023'
html = getHTMLText(url)
fillUnivList(uinfo, html)
printUnivList(uinfo, 20)
main()
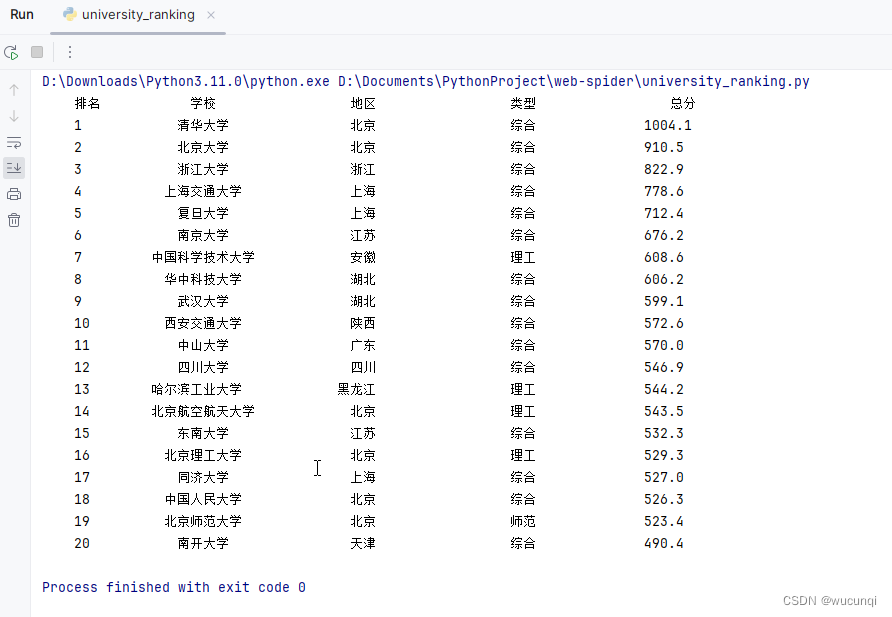
运行结果
结语
创作不易,坚持输出优质文章,您的支持是我最大的动力。

















 977
977











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











