






内容来源:【10分钟快速掌握正则表达式】https://www.bilibili.com/video/BV1da4y1p7iZ?vd_source=a26e0b2a865b90e6c49fc13ed986c490
十分推荐上面的这个视频,内容简单明了,干货十足。
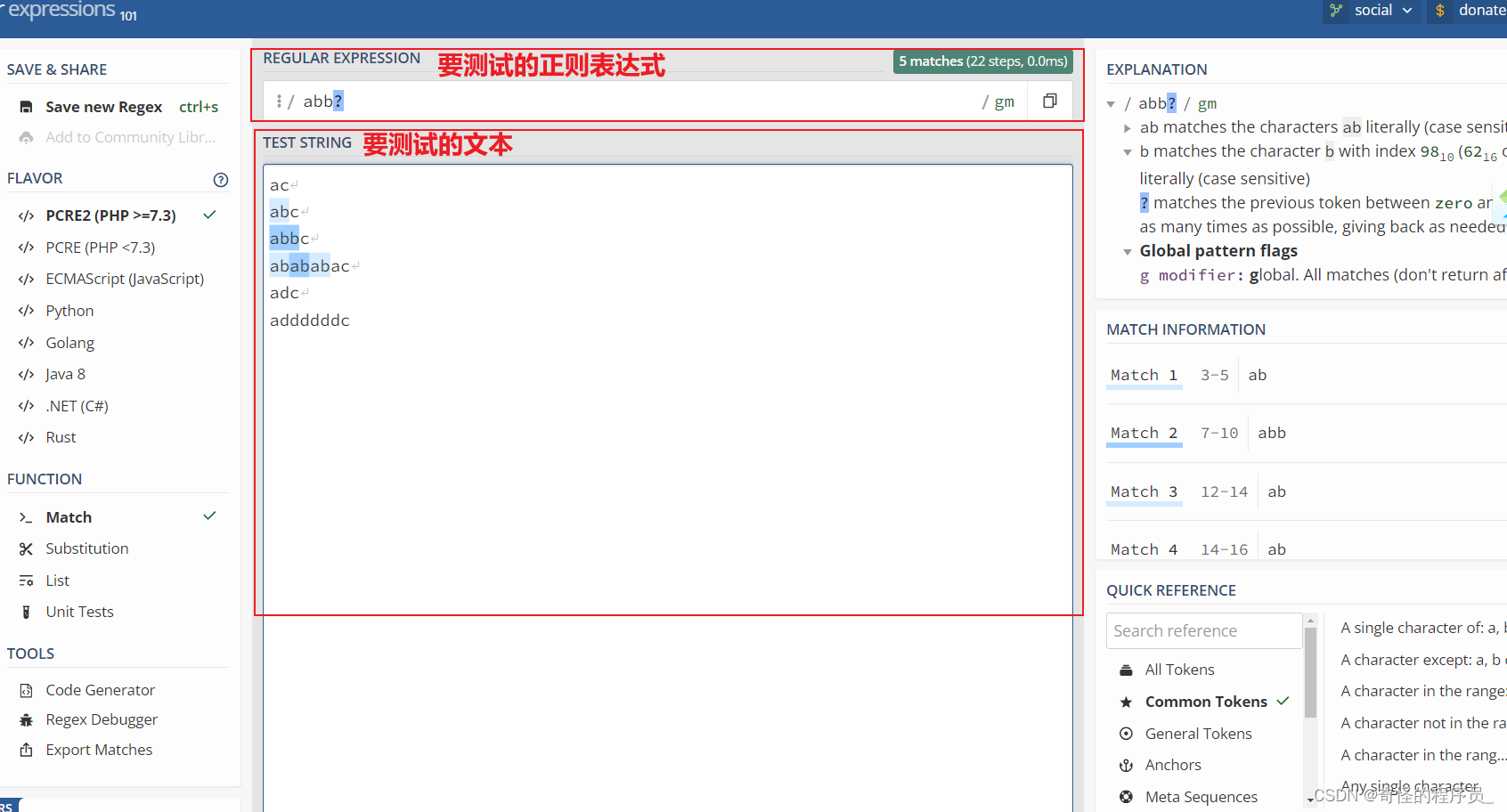
开始前,推荐一个测试正则表达式的网站:http://regex101.com,展示如下
正则表达式中的限定符:
? : 表示其前一个字符可有可无,即可出现一次,或者不出现。例如 Used? 这个表达式,就能匹配Use和Used两个单词。
* :表示匹配0个或者多个字符。通常指的是 ? 的前一个字符可不出现或者出现多次。例如 ab*c 这个表达式,可以匹配 ac、abc 、 abbc、abbbc 等等多个符合规则的单词。
+:表示匹配1个字符以上。通常值 + 的前一个字符至少出现一次以上的单词。例如 ab+c 这个表达式,可以匹配 abc 、abbc 、 abbbbc等等单词,但是不能匹配 ac 。
{n,m} :表示其前一个单词出现 [n,m] 次,例如 ab{2,3}c 这个表达式,只能匹配 abbc 、 abbbc这两个单词。
正则表达式中的运算符:
或与算符 | :表示或运算,例如 a (dog|cat) 这个表达式,能同时匹配 a dog 和 a cat两个句子,但是值得注意的是记得别忘记小括号 () 也会发挥作用。dog|cat 的中文理解是要么是dog,要么是cat。
字符类符 [] :表示句子中的符号,只能取自 [] 中的内容。例如 [abc]+,表示所有由a、b、c三个符号组成的句子,并且每个符号至少出现一次,例如 abbc 、 aabbcc等等。
字符范围 - :可以在[]中指定字符的范围。例如,我们希望匹配所有由小写英文单词组成的句子,可以用 [a-z] 这个正则表达式来进行匹配,或者我们希望匹配所有由英文单词组成的句子,我们可以使用 [a-zA-Z] 来进行匹配。
脱字符 ^ :可以用于匹配除 [] 中的字符组成的句子。例如 我们希望匹配所有没有数字符号的字符串,可以用 [^0-9] 来进行匹配。
元字符
\d : 代表数字字符
\w :代表单词字符,包括所有的英文字符、数字、下划线。
\s :代表空白符,同时包含tab字符和换行符
\D :代表非数组字符
\W : 代表非单词字符
\S : 非空白字符
. : 代表任意一个字符,但不包含换行符
^ :匹配行首,例如 ^a 这个正则表达式,只会匹配出现在一个句子开头的 a
$ :匹配行尾,例如 a$ 这个正则表达式,只会匹配出现在一个句子结尾的 a
一些高级概念
? :将正则表达式的配皮模式从 贪婪匹配 切换到 懒惰匹配模式。
















 684
684

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











