






Kafka简介
Apache Kafka是 一个分布式流处理平台. 这到底意味着什么呢?
我们知道流处理平台有以下三种特性:
- 可以让你发布和订阅流式的记录。这一方面与消息队列或者企业消息系统类似。
- 可以储存流式的记录,并且有较好的容错性。
- 可以在流式记录产生时就进行处理。
Kafka适合什么样的场景?
它可以用于两大类别的应用: - 构造实时流数据管道,它可以在系统或应用之间可靠地获取数据。 (相当于message queue)
- 构建实时流式应用程序,对这些流数据进行转换或者影响。 (就是流处理,通过kafka stream topic和topic之间内部进行变化)
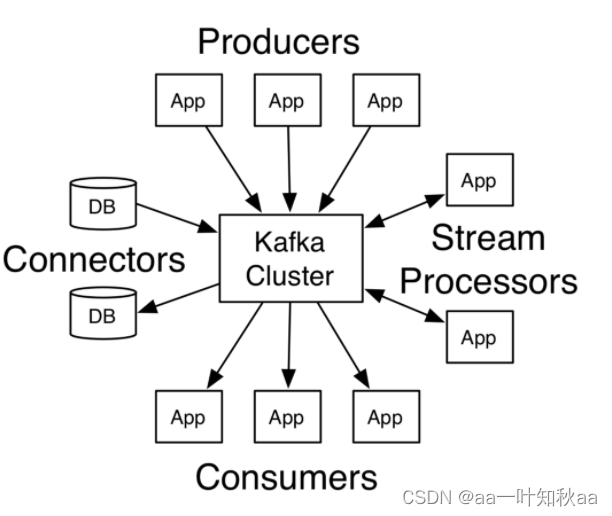
为了理解Kafka是如何做到以上所说的功能,从下面开始,我们将深入探索Kafka的特性。.
首先是一些概念:
• Kafka作为一个集群,运行在一台或者多台服务器上.
• Kafka 通过 topic 对存储的流数据进行分类。
• 每条记录中包含一个key,一个value和一个timestamp(时间戳)。
Kafka有四个核心的API:
• The Producer API 允许一个应用程序发布一串流式的数据到一个或者多个Kafka topic。
• The Consumer API 允许一个应用程序订阅一个或多个 topic ,并且对发布给他们的流式数据进行处理。
• The Streams API 允许一个应用程序作为一个流处理器,消费一个或者多个topic产生的输入流,然后生产一个输出流到一个或多个topic中去,在输入输出流中进行有效的转换。
• The Connector API 允许构建并运行可重用的生产者或者消费者,将Kafka topics连接到已存在的应用程序或者数据系统。比如,连接到一个关系型数据库,捕捉表(table)的所有变更内容。
分布式
日志的分区partition (分布)在Kafka集群的服务器上。每个服务器在处理数据和请求时,共享这些分区。每一个分区都会在已配置的服务器上进行备份,确保容错性.
每个分区都有一台 server 作为 “leader”,零台或者多台server作为 follwers 。leader server 处理一切对 partition (分区)的读写请求,而follwers只需被动的同步leader上的数据。当leader宕机了,followers 中的一台服务器会自动成为新的 leader。每台 server 都会成为某些分区的 leader 和某些分区的 follower,因此集群的负载是平衡的。
生产者
生产者可以将数据发布到所选择的topic(主题)中。生产者负责将记录分配到topic的哪一个 partition(分区)中。可以使用循环的方式来简单地实现负载均衡,也可以根据某些语义分区函数(例如:记录中的key)来完成。下面会介绍更多关于分区的使用。
消费者
消费者使用一个 消费组 名称来进行标识,发布到topic中的每条记录被分配给订阅消费组中的一个消费者实例.消费者实例可以分布在多个进程中或者多个机器上。
如果所有的消费者实例在同一消费组中,消息记录会负载平衡到每一个消费者实例.
如果所有的消费者实例在不同的消费组中,每条消息记录会广播到所有的消费者进程.
kafka的一些关键术语:
• Producer:生产者,消息产生和发送端。
• Broker:Kafka 实例,多个 broker 组成一个 Kafka 集群,通常一台机器部署一个 Kafka 实例,一个实例挂了不影响其他实例。
• Consumer:消费者,拉取消息进行消费。 一个 topic 可以让若干个消费者进行消费,若干个消费者组成一个 Consumer Group 即消费组,一条消息只能被消费组中一个 Consumer 消费。
• Topic:主题,服务端消息的逻辑存储单元。一个 topic 通常包含若干个 Partition 分区。
• Partition:topic 的分区,分布式存储在各个 broker 中, 实现发布与订阅的负载均衡。若干个分区可以被若干个 Consumer 同时消费,达到消费者高吞吐量。一个分区拥有多个副本(Replica),这是Kafka在可靠性和可用性方面的设计,后面会重点介绍。
• message:消息,或称日志消息,是 Kafka 服务端实际存储的数据,每一条消息都由一个 key、一个 value 以及消息时间戳 timestamp 组成。
• offset:偏移量,分区中的消息位置,由 Kafka 自身维护,Consumer 消费时也要保存一份 offset 以维护消费过的消息位置。
ansible一键安装kafka集群的配置
首先创建ansible的工作目录,随便创建一个目录就行了
mkdir /ansible/kafka/
如下创建目录和文件
[root@server151 ~]# tree /ansible/kafka/
/ansible/kafka/
├── all.yaml
├── hosts
└── install_kafka
├── defaults
│ └── main.yml
├── tasks
│ └── main.yml
└── templates
└── kafka.sh.j2
先配置好主机清单,在自己的主机修改成对应的主机就好了
[root@server151 ~]# cat /ansible/kafka/hosts
[kafka]
192.168.121.153 ip=153 IP=192.168.121.153
192.168.121.154 ip=154 IP=192.168.121.154
192.168.121.155 ip=155 IP=192.168.121.155
然后编写运行角色的脚本
[root@server151 ~]# cat /ansible/kafka/all.yaml
---
- name: kafka
hosts: kafka
roles:
- install_kafka
然后编写defaults变量,这个也是,根据主机修改就可以了
[root@server151 ~]# cat /ansible/kafka/install_kafka/defaults/main.yml
IP1: 192.168.121.153
IP2: 192.168.121.154
IP3: 192.168.121.155
ip1: 153
ip2: 154
ip3: 155
然后编写执行的任务
[root@server151 ~]# cat /ansible/kafka/install_kafka/tasks/main.yml
- name: tempalte shell
template:
src: templates/kafka.sh.j2
dest: /root/kafka.sh
- name: run kafka.sh
shell: "bash /root/kafka.sh"
- name: source profile
shell: "source /etc/profile"
然后编写在各主机运行的脚本
jdk和kafka的安装我是从自己的其它主机拉过来的
安装那段可以去掉或者改成适合自己主机的安装方式
这个可以根据自己的机器安装就好了,反正又不用改配置文件
[root@server151 ~]# cat /ansible/kafka/install_kafka/templates/kafka.sh.j2
#! /bin/bash
wget http://192.168.121.133/jdk-8u321-linux-x64.tar.gz
tar -xf jdk-8u321-linux-x64.tar.gz -C /usr/local/
cat > /etc/profile.d/jdk.sh << EOF
JAVA_HOME=/usr/local/jdk1.8.0_321
JRE_HOME=\$JAVA_HOME/jre
CLASSPATH=.:\$JAVA_HOME/lib/dt.jar:\$JAVA_HOME/lib/tools.jar:\$JRE_HOME/lib
PATH=\$PATH:\$JAVA_HOME/bin:\$JRE_HOME/bin
export JAVA_HOME JRE_HOME CLASSPATH
EOF
source /etc/profile
wget http://192.168.121.133/kafka_2.13-2.5.0.tgz
tar -xf kafka_2.13-2.5.0.tgz -C /usr/local/
cat > /etc/profile.d/kafka.sh << EOF
PATH=/usr/local/kafka/bin/:${PATH}
EOF
source /etc/profile
#前面的都是安装jdk和kafka的,下面开始才是配置文件的修改
cat >> /usr/local/kafka_2.13-2.5.0/config/zookeeper.properties << EOF
tickTime=2000
initLimit=5
syncLimit=5
server.{{ip1}}={{IP1}}:2888:3888
server.{{ip2}}={{IP2}}:2888:3888
server.{{ip3}}={{IP3}}:2888:3888
EOF
mkdir /tmp/zookeeper
echo {{ip}} > /tmp/zookeeper/myid
sed -i 's/broker.id=0/broker.id={{ip}}/' /usr/local/kafka_2.13-2.5.0/config/server.properties
sed -i 's/zookeeper.connect=localhost:2181/zookeeper.connect={{IP}}:2181/' /usr/local/kafka_2.13-2.5.0/config/server.properties
echo "listeners=PLAINTEXT://{{IP}}:9092" >> /usr/local/kafka_2.13-2.5.0/config/server.properties
#以守护进程方式启动zookeeper
/usr/local/kafka_2.13-2.5.0/bin/zookeeper-server-start.sh -daemon /usr/local/kafka_2.13-2.5.0/config/zookeeper.properties
sleep 30
#以守护进程方式启动kafka
/usr/local/kafka_2.13-2.5.0/bin/kafka-server-start.sh -daemon /usr/local/kafka_2.13-2.5.0/config/server.properties
配置文件这样就可以了,然后配置ssh互信让ansible以密钥方式连接受控主机
[root@server151 kafka]# ssh-keygen -t rsa
[root@server151 kafka]# ssh-copy-id 192.168.121.153
[root@server151 kafka]# ssh-copy-id 192.168.121.154
[root@server151 kafka]# ssh-copy-id 192.168.121.155
ssh互信配置好以后就可以就可以启动ansible安装kafka集群了
记得进入到/ansible/kafka目录下再执行,不然就要指定文件完整的路径
[root@server151 kafka]# ansible-playbook -i ./hosts all.yaml
然后去三台主机中的随便一台创建一个主题测试
[root@server153 ~]# /usr/local/kafka_2.13-2.5.0/bin/kafka-topics.sh --bootstrap-server 192.168.121.153:9092,192.168.121.154:9092,192.168.121.155:9092 --create --topic nginxs --partitions 2 --replication-factor 3 --config cleanup.policy=delete --config retention.ms=36000000
Created topic nginxs.
[root@server153 ~]# /usr/local/kafka_2.13-2.5.0/bin/kafka-topics.sh --bootstrap-server 192.168.121.153:9092,192.168.121.154:9092,192.168.121.155:9092 --describe
Topic: nginxs PartitionCount: 2 ReplicationFactor: 3 Configs: cleanup.policy=delete,segment.bytes=1073741824,retention.ms=36000000
Topic: nginxs Partition: 0 Leader: 155 Replicas: 155,154,153 Isr: 155,154,153
Topic: nginxs Partition: 1 Leader: 154 Replicas: 154,153,155 Isr: 154,153,155
可以看到创建的主题且所有副本都完整,这样就完成了集群的安装














 438
438











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









