









目录
1、Kafka集群安装-安装包准备
安装包下载链接:链接:百度网盘 请输入提取码
提取码:zhjy
拟安装3台kafka分布式节点,需要准备的安装包:
Jdk – 1.8
Zookeeper – 3.4.5
Kafka – 2.11
注意:三台虚拟机都要准备,在配置好主机的情况下,可以通过命令:
scp -r 需要复制的文件或包 hadoop@虚拟机名:/home/hadoop/software/
将需要的包复制到其他虚拟机,如:
scp -r Zookeeper – 3.4.5 hadoop@HadoopSlave02:/home/hadoop/software/2、Kafka集群安装-jdk安装
将jdk安装包上传到服务器(虚拟机)
解压jdk安装包
配置环境变量(环境变量文件/etc/profile)
JAVA_HOME=jdk解压目录
PATH=$PATH:$JAVA_HOME/bin
export JAVA_HOME PATH
查看是否安装成功(命令:java -version)
三台服务器都安装好,安装成功如下所示:
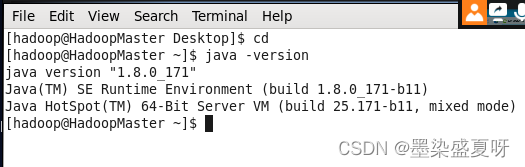

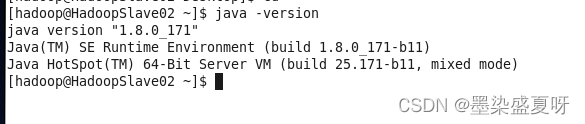
3、Kafka集群安装-zookeeper安装
配置hosts,其中的主机名使用自己的IP。
vim /etc/hosts (给集群节点取别名)
192.168.43.50 HadoopMaster
192.168.43.52 HadoopSlave01
192.168.43.51 HadoopSlave02
3.1将zookeeper安装包上传到服务器
解压zookeeper安装包
tar -zxvf zookeeper-3.4.5.tar.gz配置zookeeper环境变量
查看一下zookeeper的路径:/home/hadoop/software/zookeeper-3.4.5(配置环境时会用到)
ZOOKEEPER_HOME=zookeeper解压目录
PATH=$PATH:$ZOOKEEPER_HOME/bin
实际输入:
#zookeeper
ZOOKEEPER_HOME=/home/hadoop/software/zookeeper-3.4.5
PATH=$PATH:$ZOOKEEPER_HOME/bin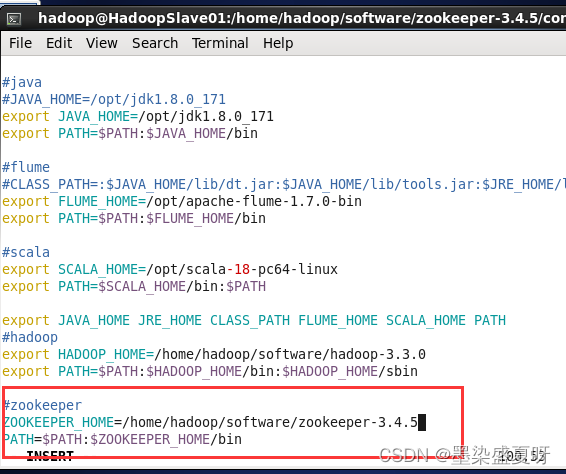
3.2配置zoo.cfg
在zookeeper安装路径的conf目录下将zoo_sample.cfg复制一份命名为zoo.cfg,
cp zoo_sample.cfg zoo.cfg先保存一下conf的路径,方便下面查找:
/home/hadoop/software/zookeeper-3.4.5/conf

server.1=HadoopMaster:2888:3888
server.2=HadoopSlave01:2888:3888
server.3=HadoopSlave02:2888:3888如下配置
分别在HadoopMaster、HadoopSlave01、HadoopSlave02
下/home/hadoop/software/data/zkdata
先保存一下zkdata的路径,方便查找:
/home/hadoop/software/data/zkdata
vim myid 新建myid文件,内容分别为1、2、3保存。
(注意:这编写的myid内容要与下面编写的server.properties配置中的broker.id,和zoo.cfg中配置的server.id一致,内容都分别为1,、2、3)
三台服务器启动zookeeper (注意关闭防火墙)
centos7关闭防火墙:systemctl stop firewalld.service
查看防火墙状态:firewall-cmd --state
启动命令:zkServer.sh start
查看状态:zkServer.sh status
4、Kafka集群安装-kafka安装
4.1将Kafka安装包上传到服务器
解压Kafka安装包
tar -zxvf kafka_2.11-2.3.1.tgzkafka的路径:/home/hadoop/software/kafka_2.11-2.3.1(下面配置环境需要用到)
在Kafka根目录下创建日志文件夹logs
配置Kafka环境变量
KAFKA_HOME=Kafka解压目录
PATH=$PATH:$KAFKA_HOME/bin
现实输入:
#kafka
KAFKA_HOME=/home/hadoop/software/kafka_2.11-2.3.1
PATH=$PATH:$KAFKA_HOME/bin/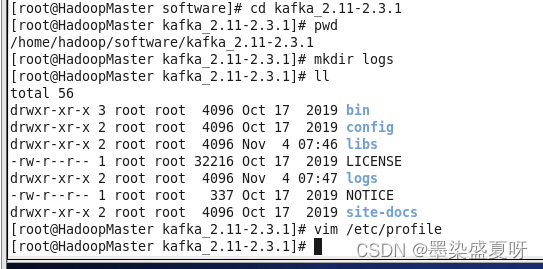
4.2配置server.properties
在Kafka安装路径的config目录下配置server.properties
先保存一下config的路径,方便下面查找:
/home/hadoop/software/kafka_2.11-2.3.1/config
vim server.properties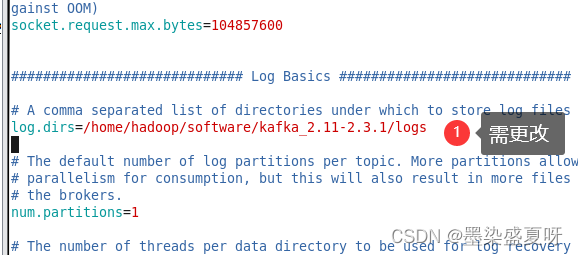
配置内容:
zookeeper.connect=HadoopMaster:2181,HadoopSlave01:2181,HadoopSlave02:2181保存一下路径:/home/hadoop/software/kafka_2.11-2.3.1/config
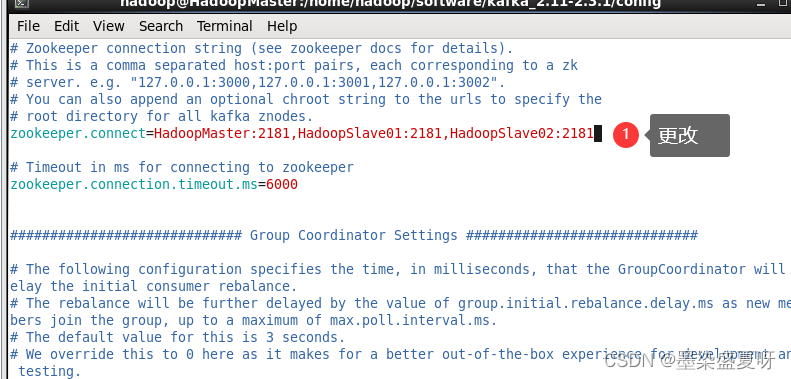
配置内容:
#broker的全局唯一编号,不能重复
broker.id=1
#kafka运行日志存放的路径
/home/hadoop/software/kafka_2.11-2.3.1/logs
#配置连接zookeeper集群地址
zookeeper.connect=HadoopMaster:2181,HadoopSlave01:2181,HadoopSlave02:21814.3启动zookeeper集群
命令:
zkServer.sh start
启动Kafka集群
bin/kafka-server-start.sh /home/hadoop/software/kafka_2.11-2.3.1/config /server.properties(这里出现问题:)
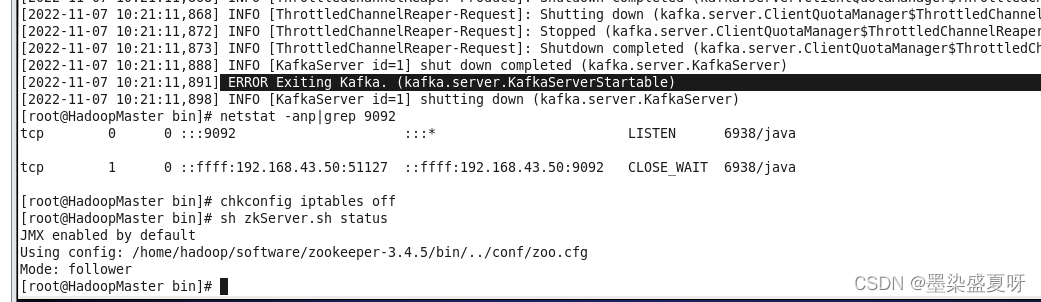
ERROR Exiting Kafka. (kafka.server.KafkaServerStartable)
排查:
(1)、netstat -anp/grep 9092,发端口不在监听状态,就感觉防火墙问题,看了下防火墙是关的这步没毛病,排除
(2)、sh zkServer.sh status查看Mode,一台是leader ,另外两台均是follower,这步没毛病,排除
检查:



(3)、查看server.properties配置中的broker.id,是否有重复,这步没毛病,排除
(4)、查看server.properties配置中的broker.id,是否与myid和zoo.cfg中配置的server.id一致,这步没毛病,排除
(5)、那可能是连接zookeeper的超时问题?在server.properties 中查看
zookeeper.connection.timeout.ms=6000,把6000改大,我这里改为60000(如果没有这个参数就自己添加上)问题真在这!!!

(6)、再次启动kafka,在kafka的bin目录下:
./kafka-server-start.sh /home/hadoop/software/kafka_2.11-2.3.1/config/server.properties
关闭Kafka集群
bin/kafka-server-stop.sh stop
5、Kafka控制台基本操作
创建名为zhh的topic
./kafka-topics.sh --create --zookeeper 192.168.43.51:2181 --topic test --partitions 3 --replication-factor 1
-zookeeper:zookeeper集群节点
--partitions:分区数
--replication-factor:副本数
--topic:topic名称
写入消息 按ctrl+c输入完成
./kafka-console-producer.sh --broker-list 192.168.43.51:9092 --topic test
查询topic列表
bin/kafka-topics.sh --list -zookeeper HadoopSlave02:2181
删除topic
bin/kafka-topics.sh --delete -zookeeper HadoopSlave02:2181 --topic zhh
注意:配置了delete.topic.enable为true才能删除topic。
查询topic信息
bin/kafka-topics.sh --describe --zookeeper HadoopSlave01:2181 --topic zhh
修改topic分区数
bin/kafka-topics.sh --zookeeper HadoopSlave01:2181 --alter --topic zhh --partitions 6
启动生产者进程并发送消息
bin/kafka-console-producer.sh --broker-list HadooopSlave01:2182 --topic zhh启动消费者进程并消费消息
bin/kafka-console-consumer.sh --bootstrap-server HadoopSlave02:9092 --topic zhh --from- beginning --group t1--from-beginning:表示从头开始接收数据
--group:指定消费者组
查询topic中的offset
bin/kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list HadoopSlave02:9092 --topic zhh --time -1
bin/kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list HadoopSlave02:9092 --topic zhh --time -2
--time -1表示要获取指定topic所有分区当前的最大位移, --time -1表示获取当前最早位移
















 2916
2916











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











