







kettle是一款免费开源的ETL工具,在2006年被Pentaho公司收购,所以也被叫做Pentaho Data Integration。虽然这款工具在细节上还存在一些bug,但随着这些年版本的不断更新,越来越能适应商业化的ETL项目。
kettle具体的数据清洗与同步工作是由转换(transformation)完成的,在转换的开发界面可以实现数据的提取、清洗、同步,转换最终以ktr文件的形式保存下来。
ETL的项目当然不可能只是做一次数据同步,尤其是在数据仓库项目上,是需要大量的、定时的数据同步任务。所以在kettle中使用作业(job)来管理、调度转换,在作业中可以设置转换的同步频率、执行方式等;也可以在作业中再嵌套作业,具体使用方式要看实际项目场景。
转换与作业是kettle工具主要的开发成果,也是最重要的资源,那么这些资源存放在哪里呢?答案是资源库。通过资源库来存放、管理转换与作业。kettle的资源库有3种:数据库资源库、本地资源库、Pentaho Repository。3种资源库的简要介绍如下:
| 资源库类型 | 描述 | 适用性 |
| Database Repository(数据库资源库) | kettle的资源文件存储到数据库中 | 适合团队协同开发管理 |
| File Repository(文件资源库) | 也叫本地资源库,kettle的资源文件存储到本地 | 适合个人本地练习 |
| Pentaho Repository | 需要部署kettle的服务端,kettle的资源文件存储在服务端。具备内容管理、版本管理、依赖完整性检查等用途。 | 适合团队协同开发管理 |
这篇主要会去介绍 Pentaho Repository这种适合团队协同开发的资源库,这也是我所负责的项目一直在使用的资源库类型。21年之前Pentaho Repository的风评确实很差劲,因为资源库卡顿的让人想摔鼠标;但随着9.x版本的客户端与服务端发布问世,Pentaho Repository已经可以胜任项目要求了。
目录
一、Pentaho Repository资源库下载
关于kettle的下载,要分清楚两个大版本:社区版、企业版。社区版是免费的,企业版是收费的。但是社区版不代表就不能使用,它是可以满足大部分的ETL项目的,具体的对比大家可以往下看,官网提供的一张社区版和企业版对比图。
SourceForge是一个开源软件项目托管平台,kettle的客户端和服务端都能在这里直接下载。但2022年左右就不再直接提供软件包下载了;无论是客户端还是服务端,都需要去官网下载。但SourceForge还是提供了官网的社区版和企业版下载地址。
Pentaho from Hitachi Vantara download | SourceForge.net![]() https://sourceforge.net/projects/pentaho/
https://sourceforge.net/projects/pentaho/
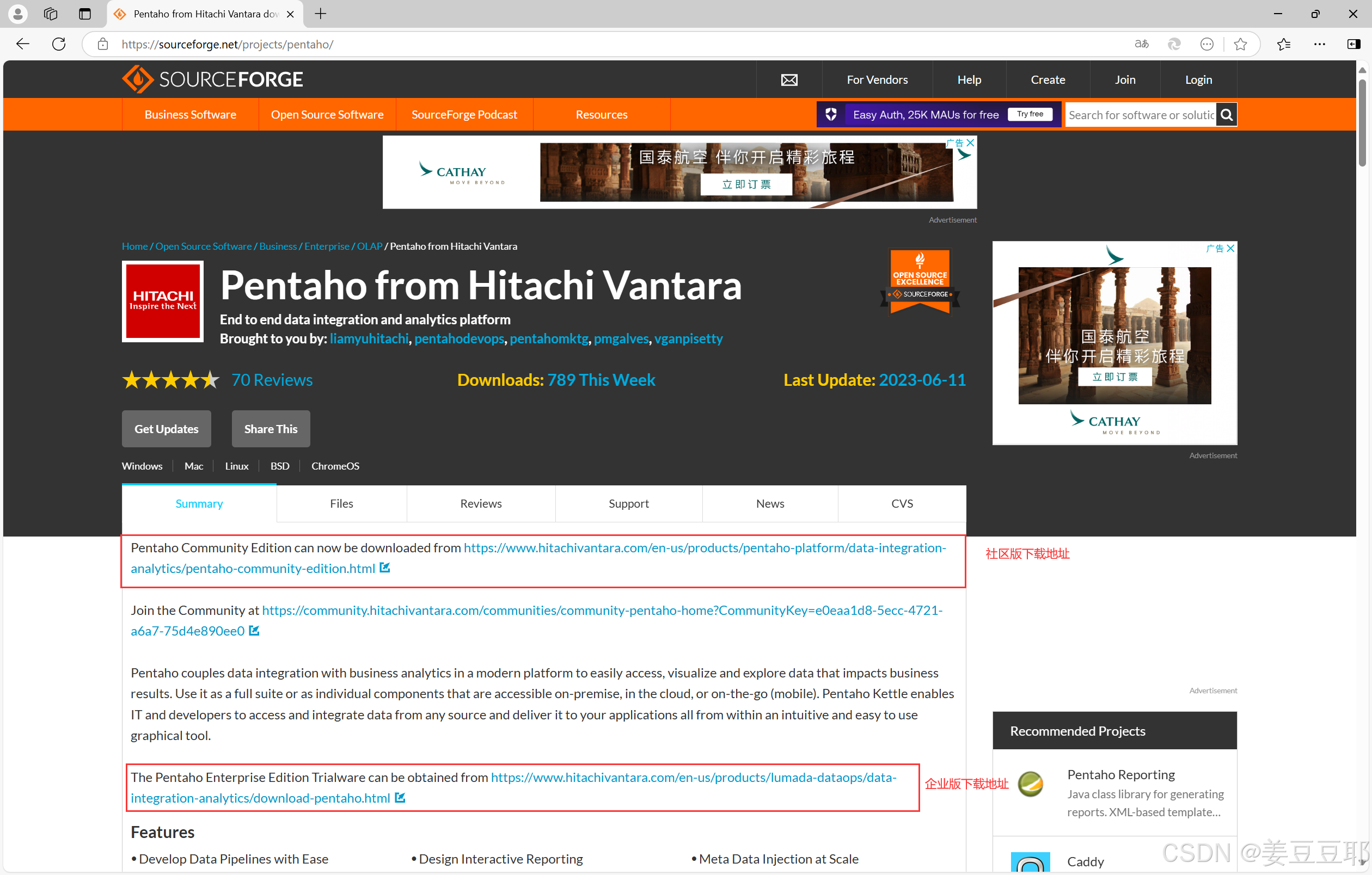
但是在2024年年底,kettle官网似乎是关闭了所有的社区版软件下载途径。无论是按照SourceForge提供的官网下载地址,还是从官网上自己探索社区版下载途径都无功而返。
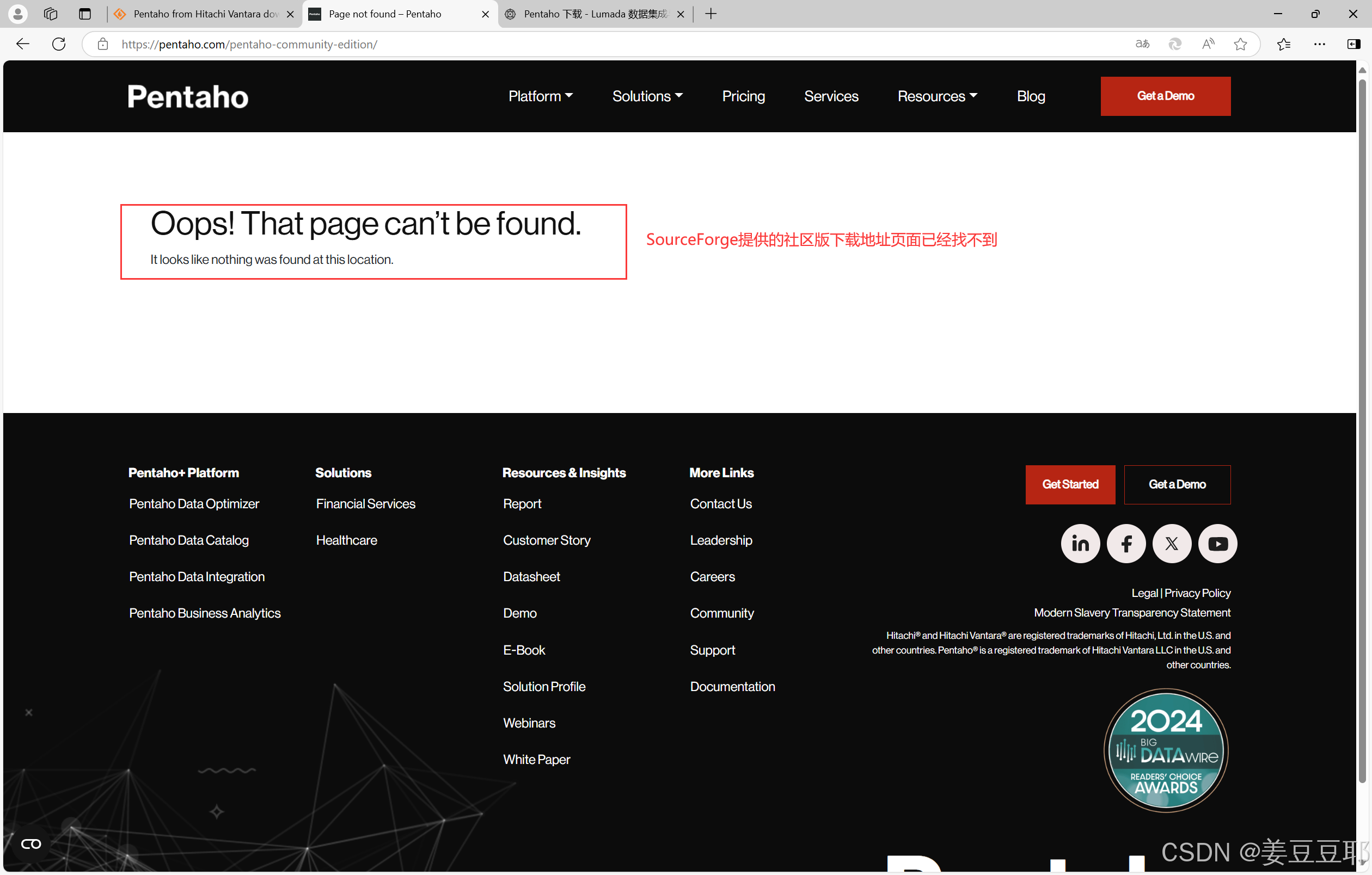
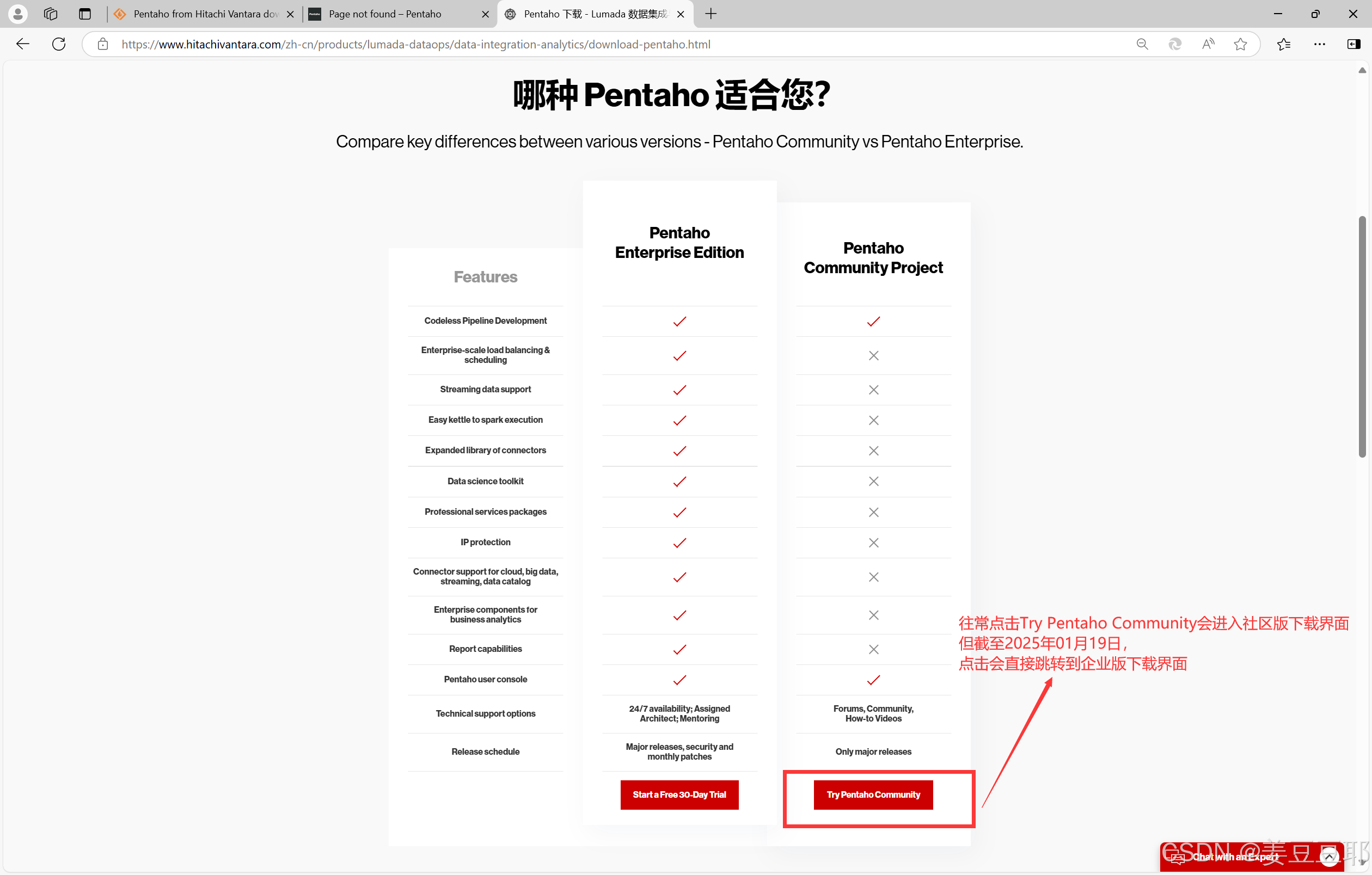
具体为什么会出现这种情况,官网上也没有看到通知和新闻,只当是它在维护吧。我在这里先给大家提供一个百度网盘下载链接,pentaho server版本是9.4,client版本是9.3。等到后续官网恢复了社区版下载,这篇文章我会把这一段再更新掉。
通过网盘分享的文件:pentaho-community
链接: https://pan.baidu.com/s/1Ryc7j1JXehBVDYfLBiMP3Q提取码: zqd1
二、Pentaho Repository资源库部署
Pentaho Repository是由tomcat发布,在Windows和Linux操作系统上都可以部署。但是经过测试发现部署在Windows上bug会更多,因为Windows server服务器有个比较头疼的点,每一年左右就要重启一次,否则就会出许多莫名其妙的bug(亲测在win2008、win2012、win2016、win2019上都有这种问题)。所以还是推荐在Linux系统上部署。
1、部署前环境
下面是部署前的环境说明,也是这几年尝试过的一些经验总结。
虚拟化平台
现在大部分项目都在使用虚拟化平台,比如老牌的虚拟化软件VMware、新兴的云计算平台华为云等。但是不建议大家将Pentaho Repository部署在华为云的服务器上,并不是诋毁华为云,它在其他方面可能做的很优秀;只是真的在测试过程中发现Pentaho Repository在华为云服务器上的性能很差;这个大家可以看我的另一篇文章:kettle经验篇:Pentaho Repository 类型资源库卡顿问题-CSDN博客![]() https://blog.csdn.net/m0_58872140/article/details/144790947?spm=1001.2014.3001.5501
https://blog.csdn.net/m0_58872140/article/details/144790947?spm=1001.2014.3001.5501
Linux操作系统
目前已经在RHEL7、RHEL8、centos7、centos8、Anolis OS 8.9系统上部署使用过,均比较稳定,其他操作系统版本未测试,所以不好评价。
Pentaho Repository 版本
目前项目使用的版本有Pentaho Server 9.2、Pentaho Server 9.3、Pentaho Server 9.4,也都比较稳定,截至2025年1月,Pentaho Server版本已经出到了10.2,但是Pentaho Server 9.4之后的版本都还没试用过,但按照kettle的发展水平来说,应该也不会差。
服务器
在项目上,Pentaho Repository资源库所需要的存储资源并不高,一般的项目有个300G就足够了。CPU在8核以上,内存在16G以上。
如果是自己练习自己玩,存储有个50G都可以;CPU双核、内存8G就能跑得很流畅。
2、部署过程
下面开始给大家描述下部署过程。
| 序号 | 步骤 |
| 1 | 服务器配置检查 |
| 2 | 上传pentaho server软件包 |
| 3 | 检查环境变量 |
| 4 | 开放防火墙端口 |
| 5 | 启动资源库 |
| 6 | 验证资源库 |
1、服务器配置检查
(1)CPU
项目上部署,服务器CPU至少要8核;自己练习2核就够。
(2)内存
项目上部署,服务器内存至少16G;自己练习有个8G就足够。
(3)存储
建议是有个专门的挂载点去存放Pentaho Repository资源库内容,且使用LVM逻辑卷管理。一般项目上在划分服务器的时候,如果不提前说清楚,存储基本上都划到根目录下,而且是标准分区,扩容很麻烦。如果是在自己练习的时候,也建议按照这种规范来。当然,直接放到根目录也是可以的,这里只是在讲一种规范。
例如下图是我自己搭的一个测试服务器,是新建了一个/pentaho的挂载点,Pentaho Repository的软件包以及资源内容都存在在这里。
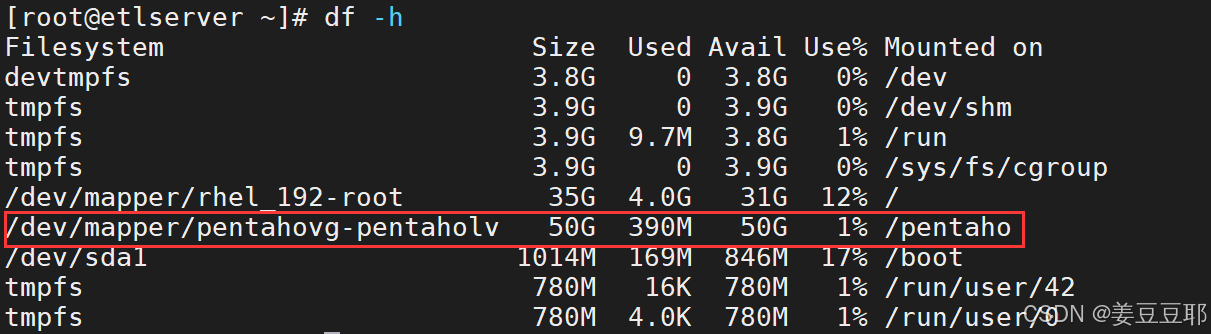
顺便把新增挂载点存储的方法分享给小白朋友
#1、为服务器新增一块磁盘
#2、创建pv
pvcreate /dev/sdb #sdb是新增的磁盘盘符
#3、创建vg
vgcreate pentahovg
#4、创建lv
lvcreate -n pentaholv --extents 100%FREE pentahovg
#5、格式化
mkfs.xfs /dev/pentahovg/pentaholv
#6、创建挂载点目录
mkdir /pentaho
#7、将挂载信息写入/etc/fstab
echo "/dev/pentahovg/pentaholv /pentaho xfs defaults 0 0" >> /etc/fstab
#8、立即挂载
mount /pentaho2、上传pentaho server软件包
上传到提前准备好的/pentaho目录下,并解压。
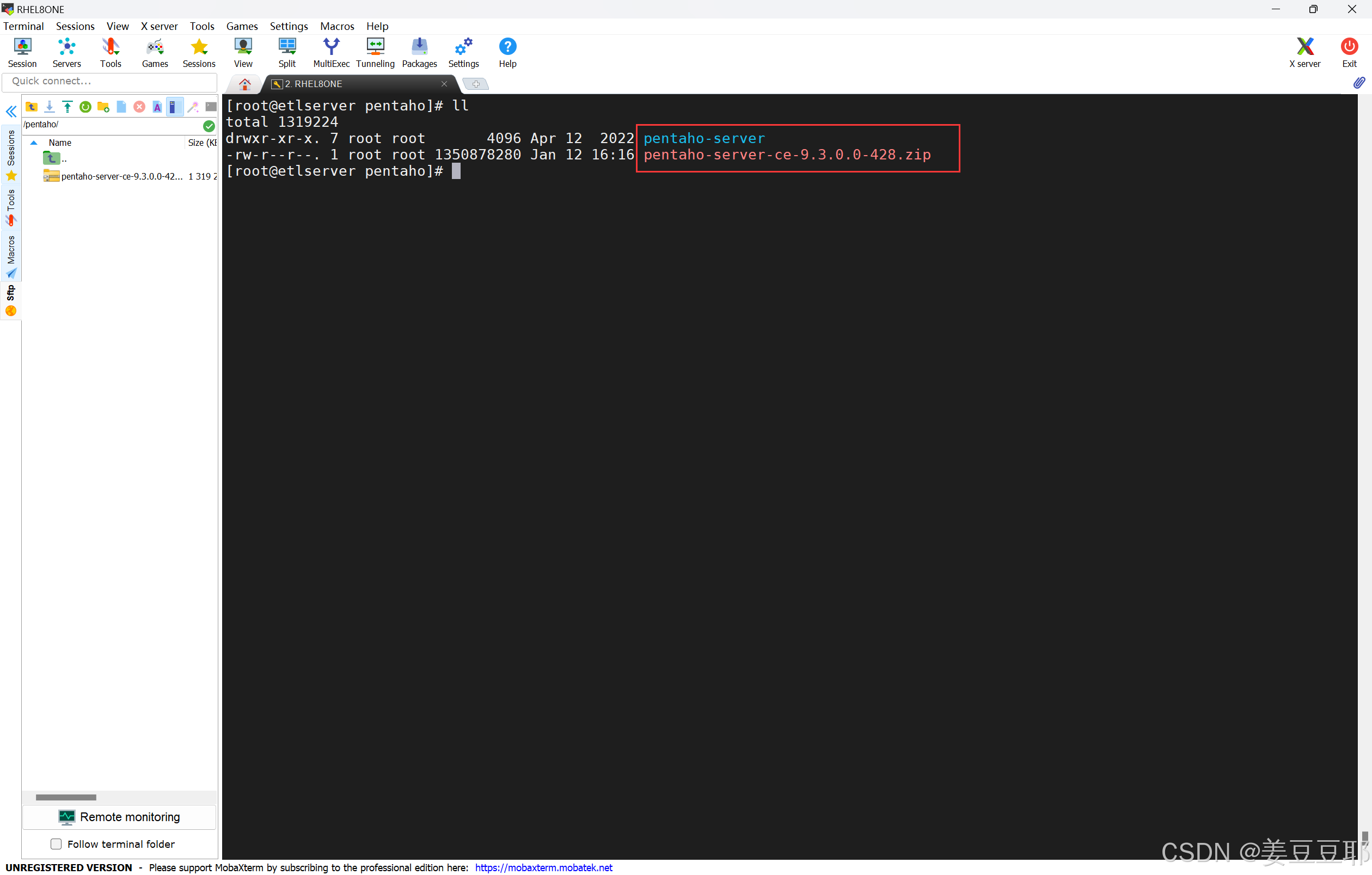
3、检查环境变量
(1)检查Java环境,看是否安装了JDK1.8
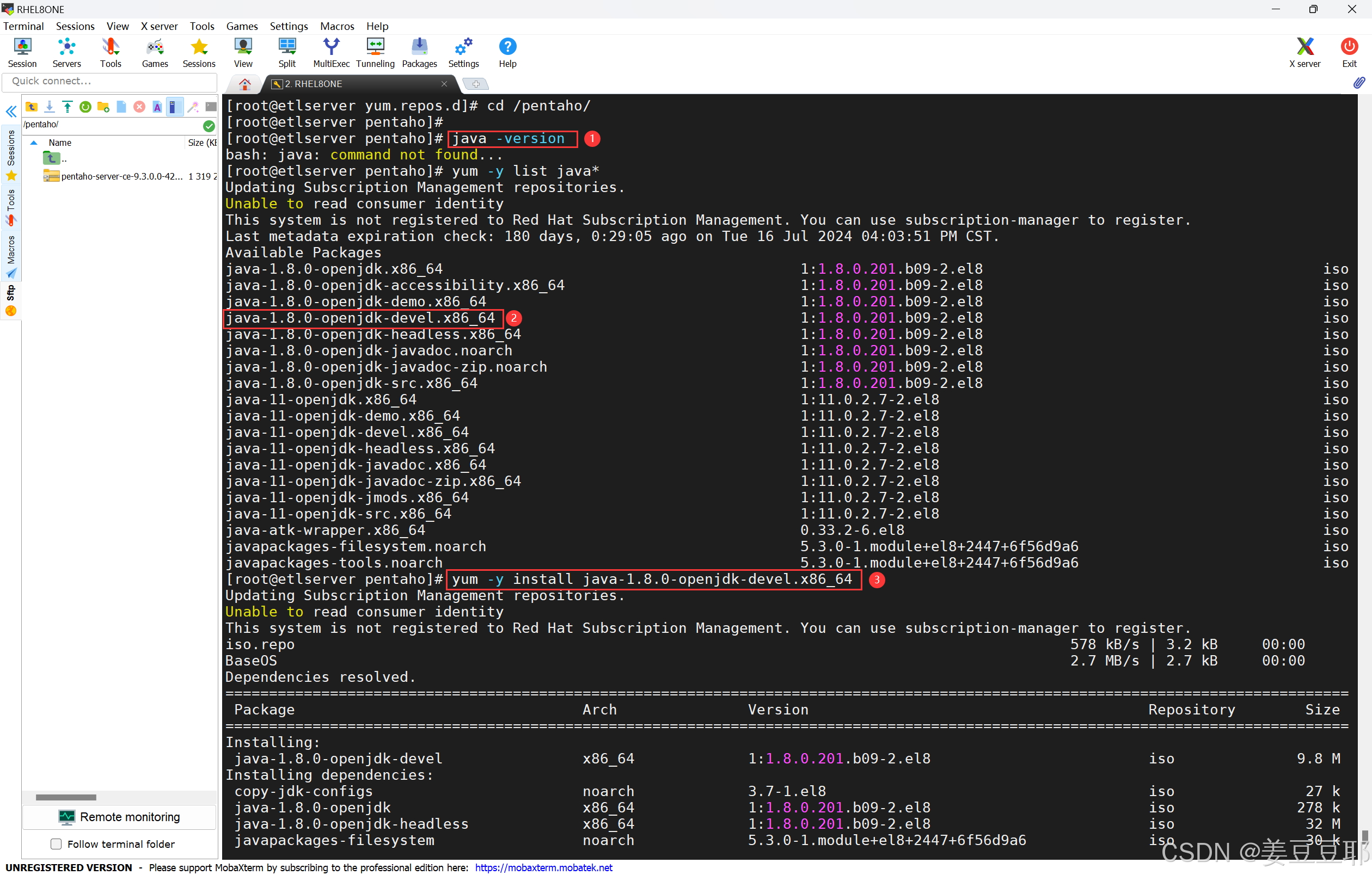
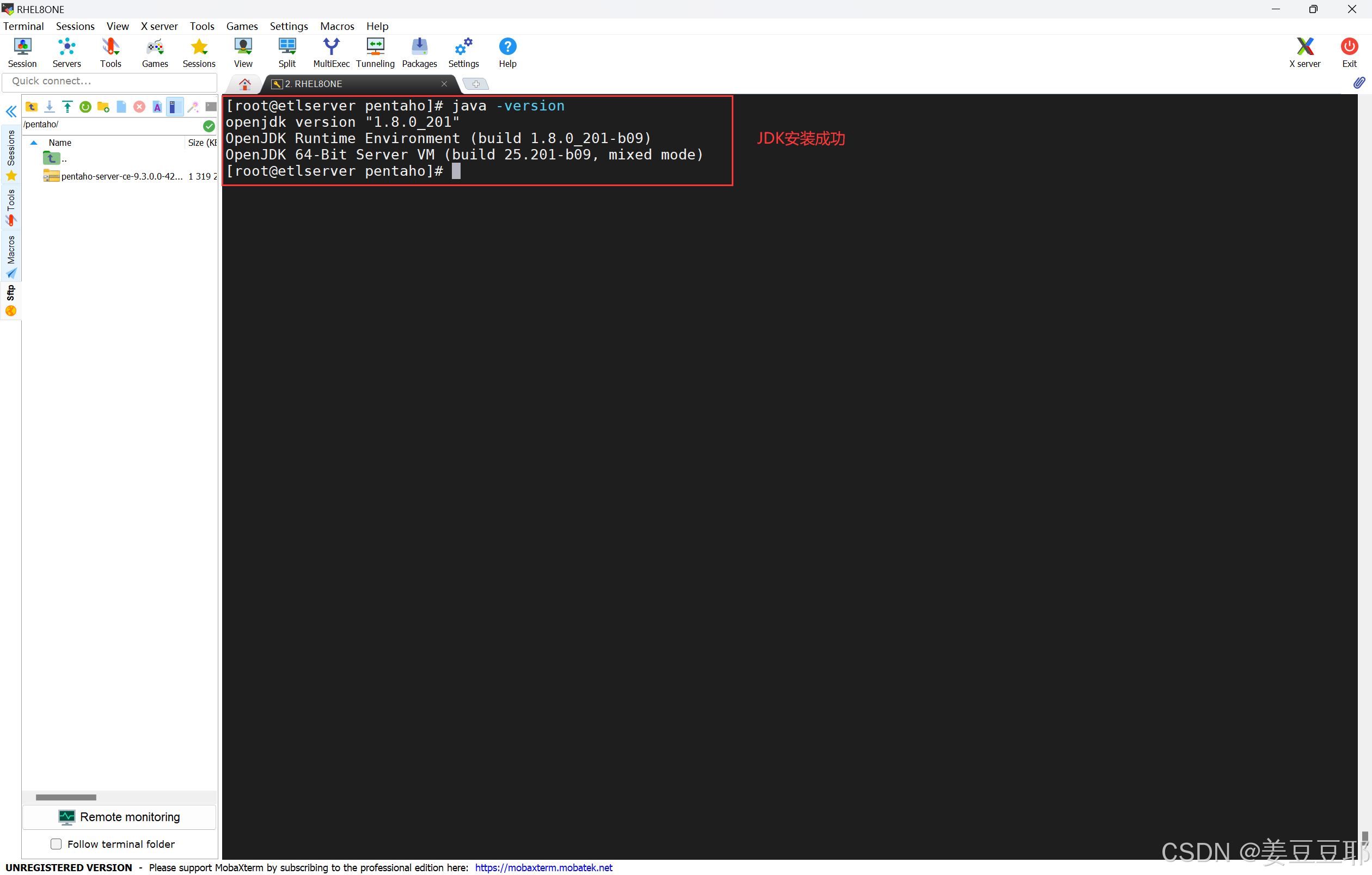
我在这里使用了yum安装。但很多项目上可能是纯内网环境,也没有挂载镜像,也没有局域yum源。这种情况其实也不要紧,大家使用rpm离线安装即可,只是一个jdk而已,很简单。jdk的提网盘链接放在下面了。
链接: https://pan.baidu.com/s/1ZxaFb65PqNWYwgyM-wKbZw
提取码: zqd1
拿到jdk包上传到服务器,执行如下命令
rpm -ivh jdk-8-linux-x64.rpm(2)将pentaho server的重要目录设置到环境变量
这个步骤其实不做也不影像,只是我习惯了去做。一个是因为方便,一个是因为怕忘记目录在哪里。这里有3个重要目录:启动目录,资源库目录、资源库版本目录。
#将启动目录写入环境变量
echo "PENTAHO_HOME=/pentaho/pentaho-server" >> ~/.bash_profile
#将资源库文件目录写入环境变量
echo "PENTAHO_DATA=$PENTAHO_HOME/pentaho-solutions/system/jackrabbit/repository/workspaces/default" >> ~/.bash_profile
#将资源库版本文件目录写入环境变量
echo "PENTAHO_DATA_VERSION=$PENTAHO_HOME/pentaho-solutions/system/jackrabbit/repository/version" >> ~/.bash_profile
#加载环境变量
source ~/.bash_profile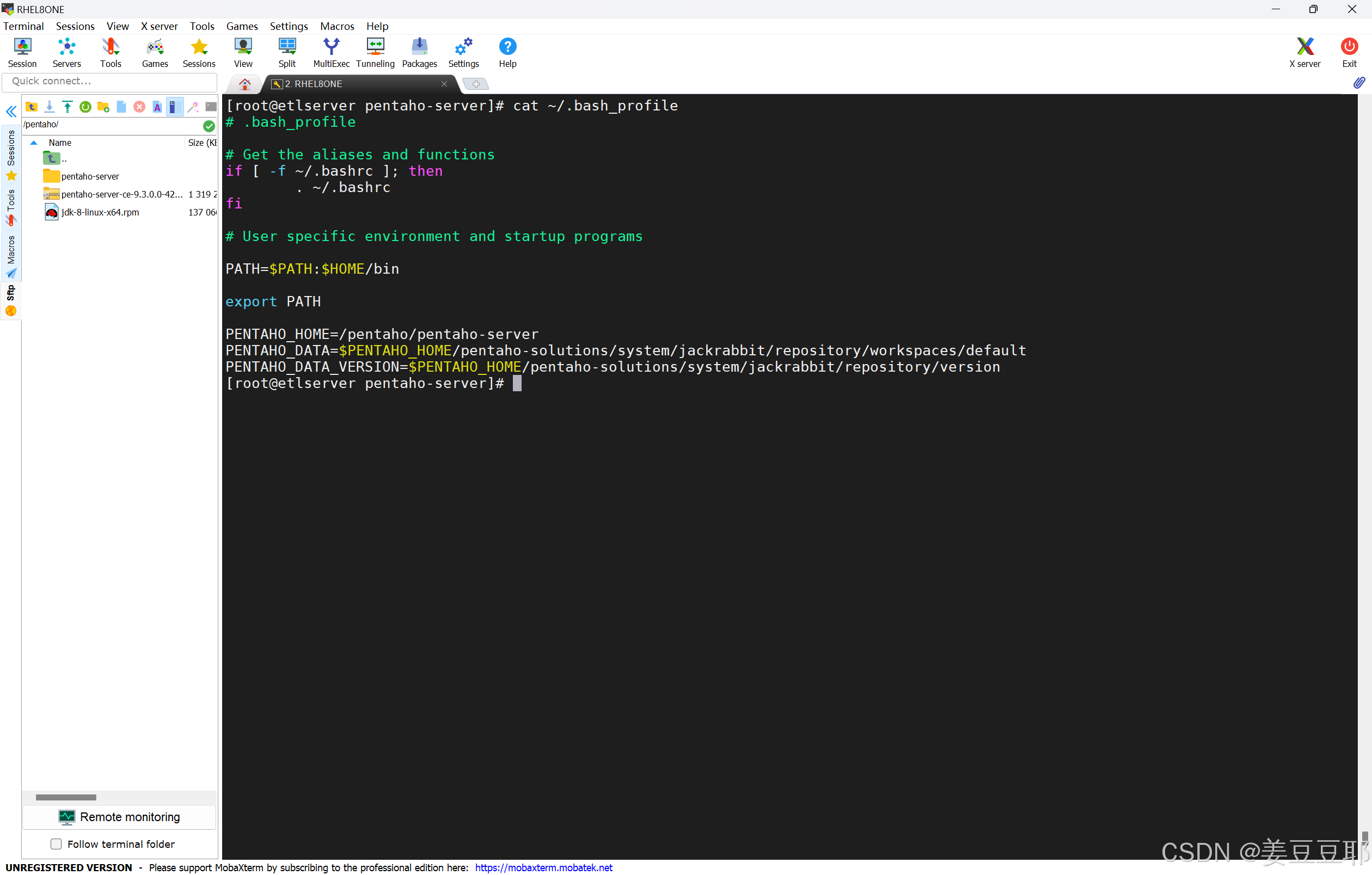
4、开放防火墙端口
如果项目允许关闭防火墙,就直接关掉防火墙最方便。如果不能关闭防火墙,就需要开放pentaho server的端口。pentaho server的默认端口是8080
firewall-cmd --permanent --add-port=8080/tcp
firewall-cmd --reload
firewall-cmd --permanent --list-ports5、启动资源库
启动资源库很简单,进入到pentaho server的启动目录,执行启动脚本。执行脚本后不会立即启动成功,需要等待1分钟左右。
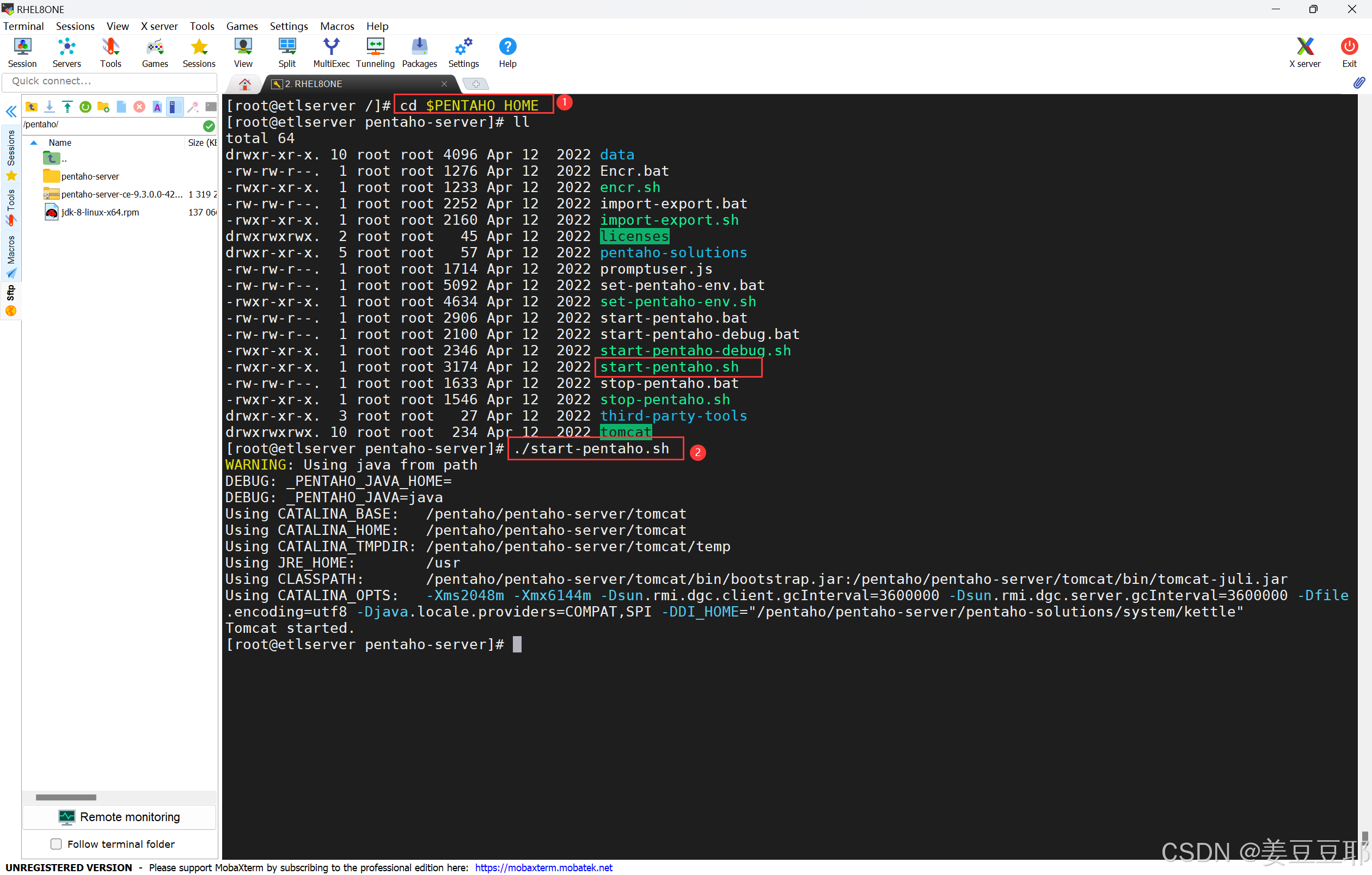
6、验证资源库
验证资源库是否部署成功,可以用以下方法。
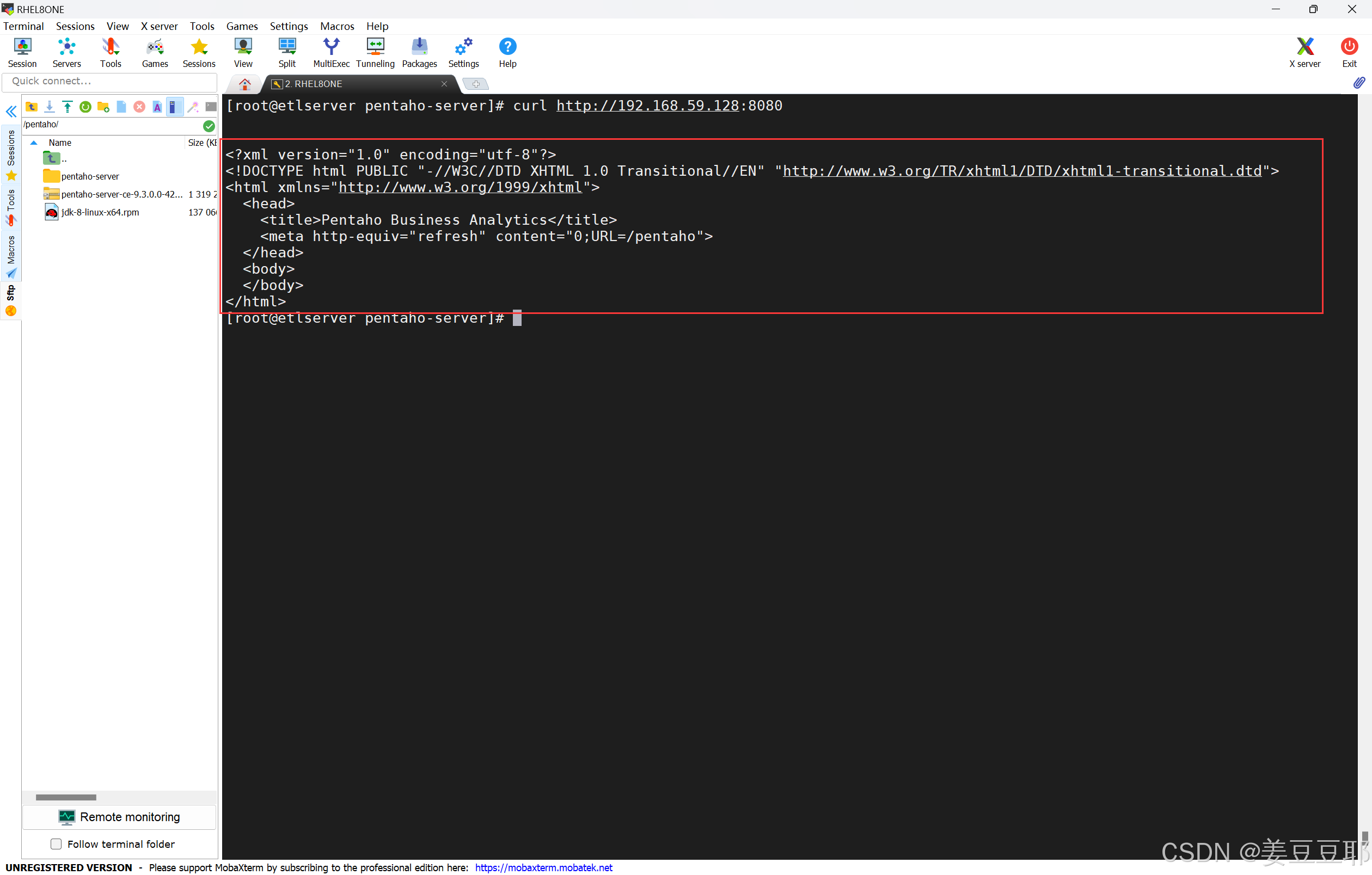
使用curl命令
curl 服务器ip:8080当出现以下输出时,说明已经部署成功了。
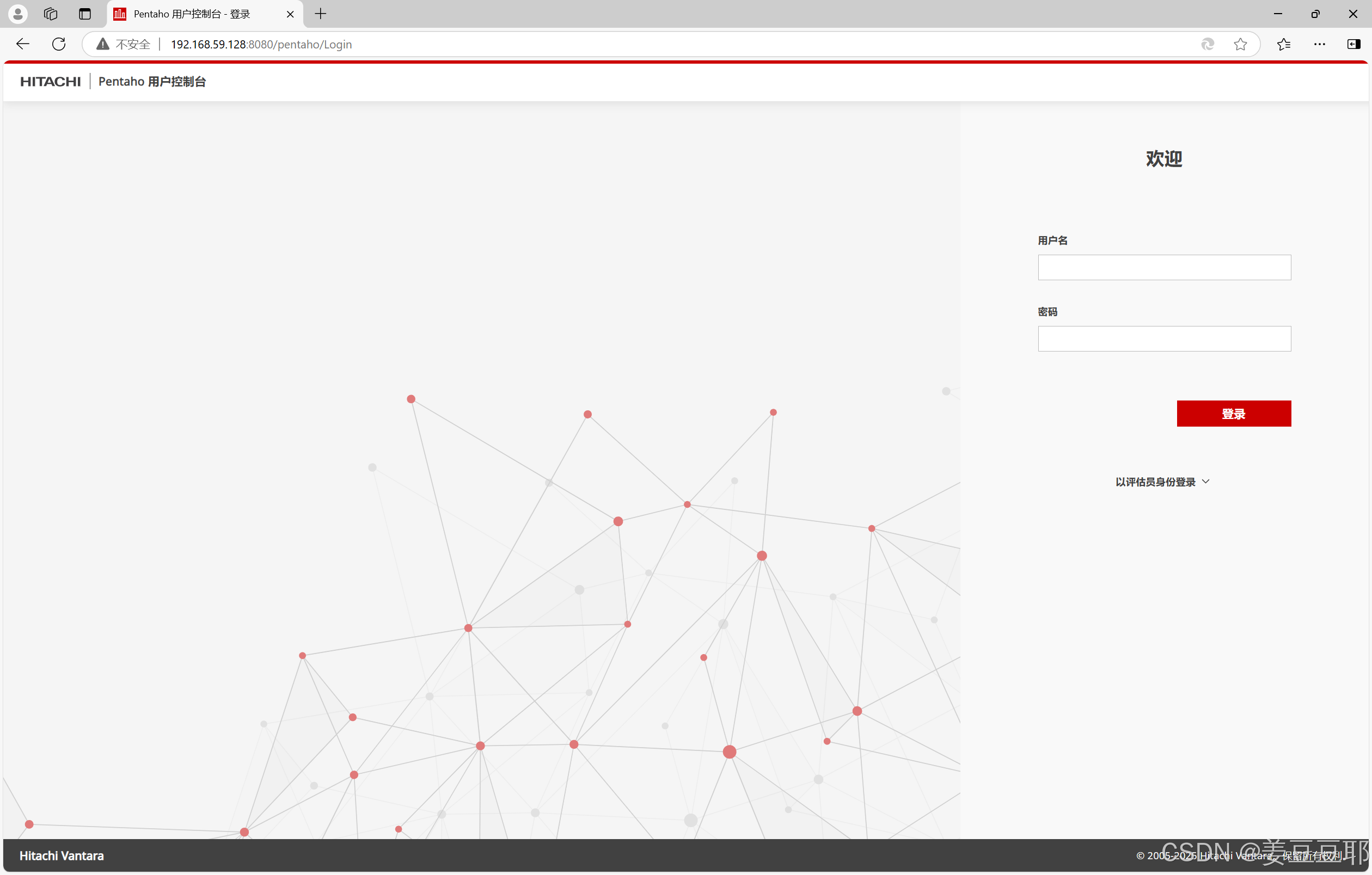
还可以直接在浏览器上输入pentaho Repository地址——服务器IP:8080/pentaho
出现如下界面,说明也部署成功了。这里的用户名可以使用默认admin用户密码:admin/password
三、Pentaho Repository资源库登录
在客户端总共有3种资源库可以选择配置登录,这3种资源库在文章开头已经和大家分享过了:本地资源库、数据库资源库、pentaho repository资源库。下面和大家描述下pentaho repository资源库的配置登录过程。
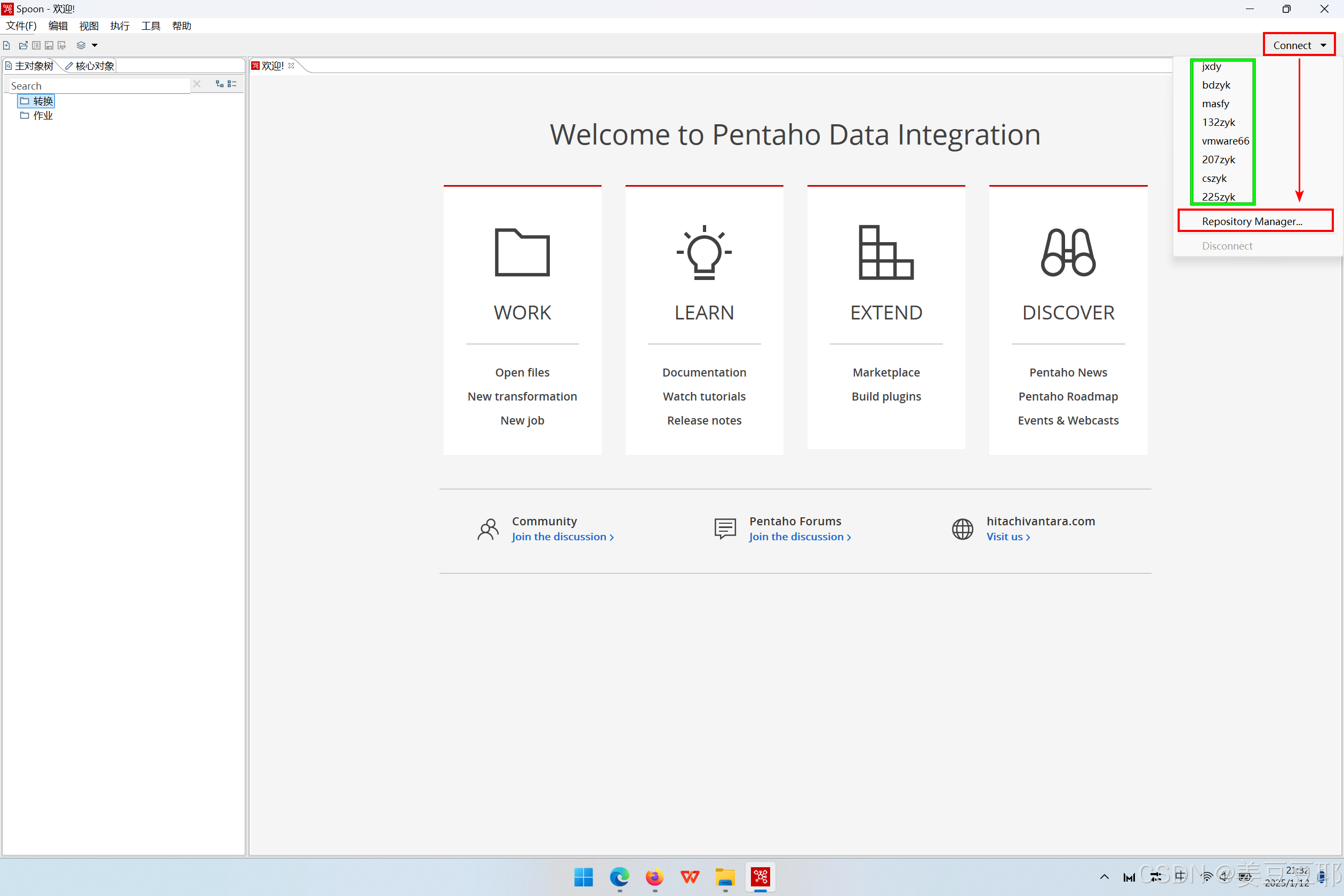
1、点击客户端右上角的connect
可以在图中看到 “Repository Manager”,点击即可进行资源库管理界面。而图中绿色框中的内容是当前客户端已经配置连接过的资源库。
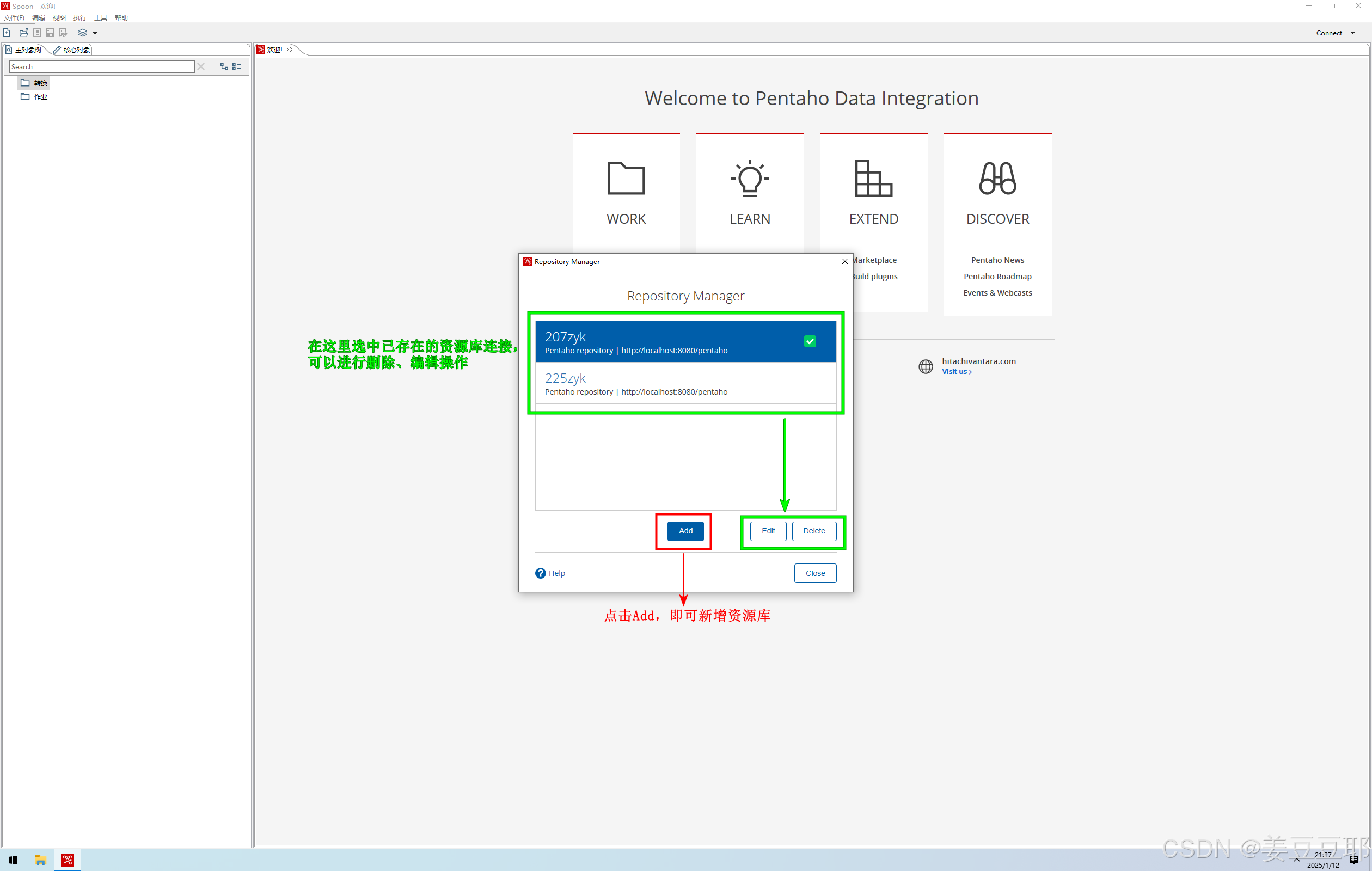
2、新增资源库
当前界面是资源库管理界面,按照图中操作即可对现有的资源库连接进行删除和修改;亦可进行新增资源库。
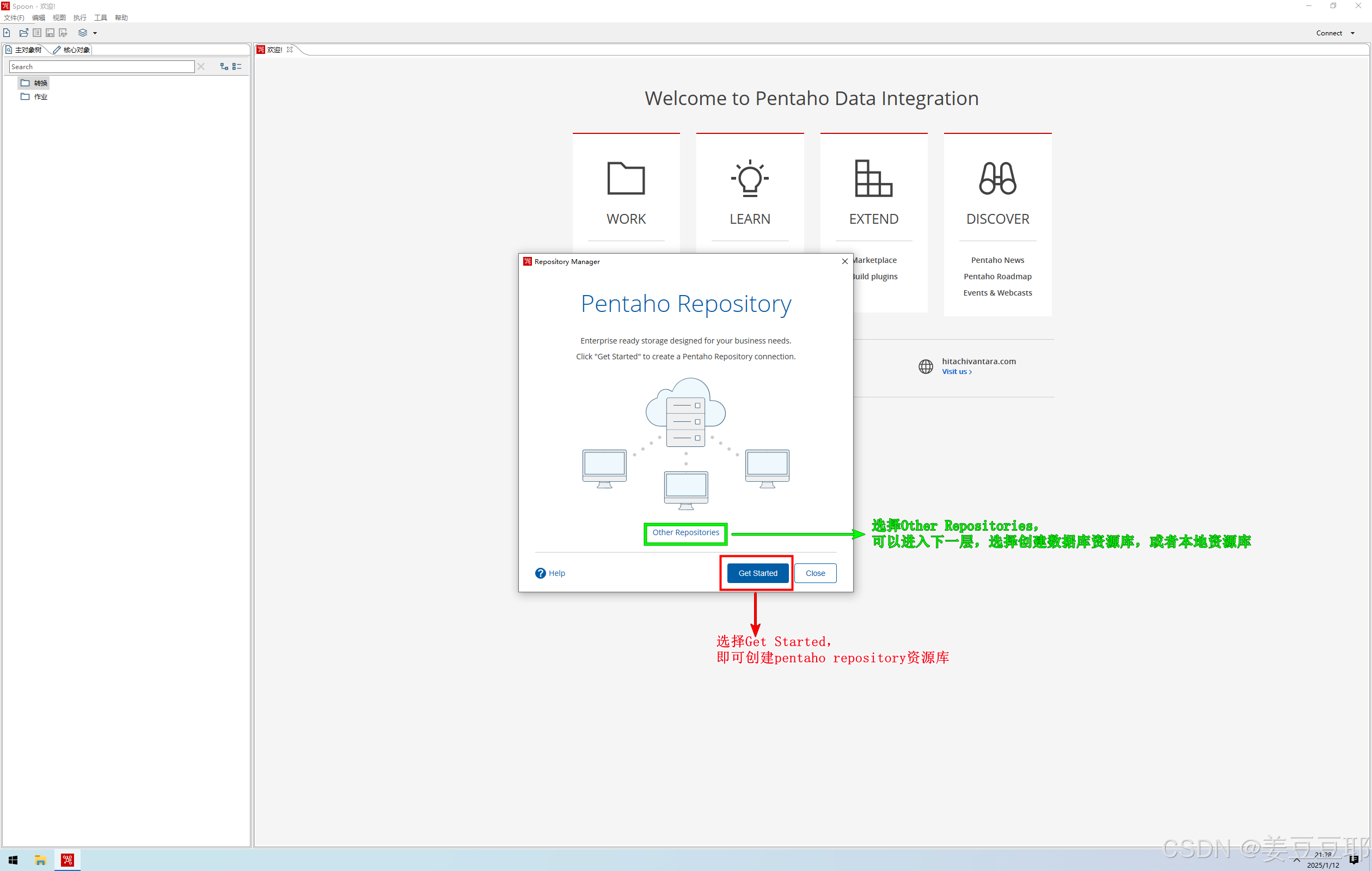
3、选择Get Started
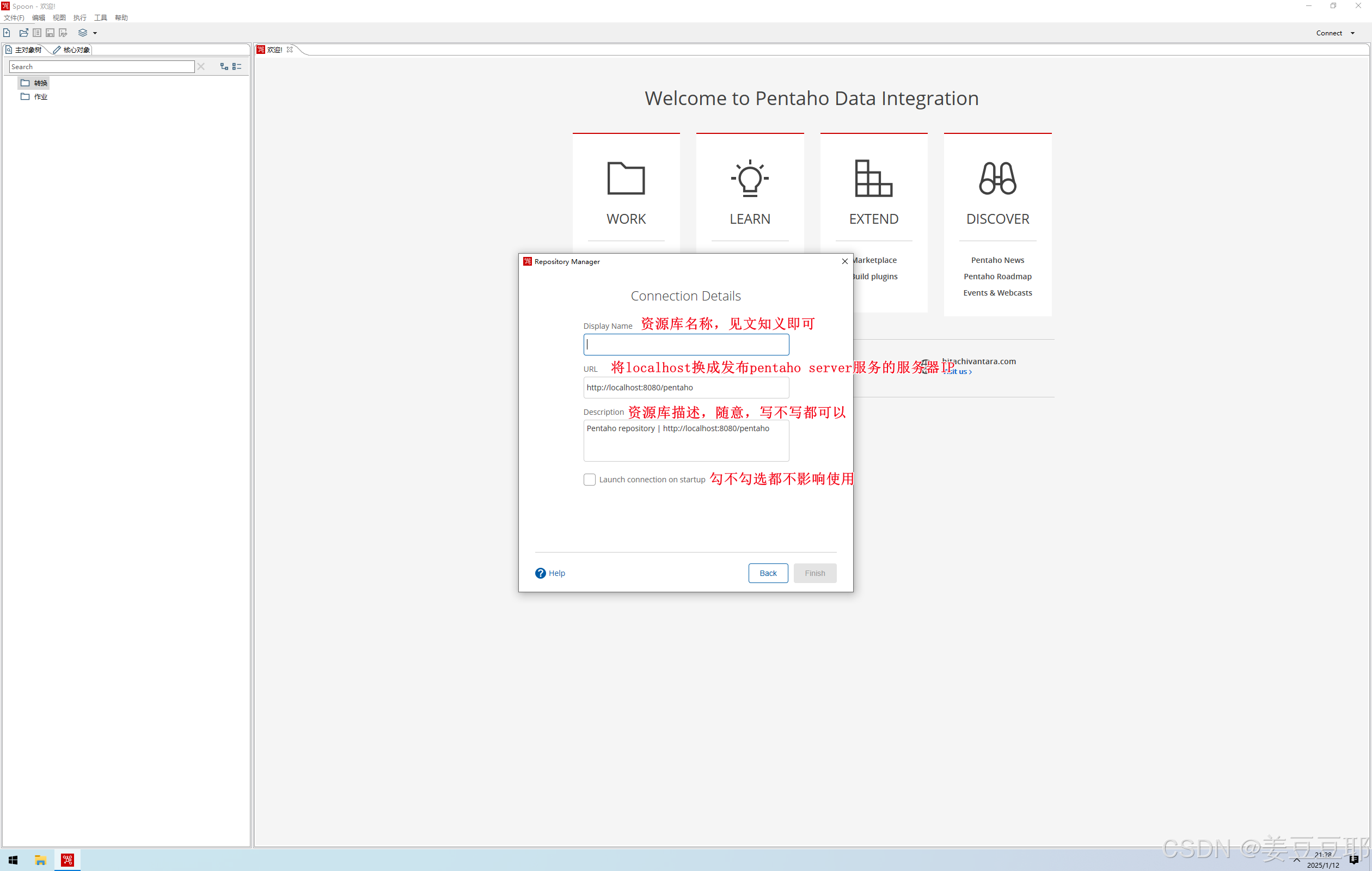
4、配置pentaho repository资源库
| 配置参数 | 说明 |
| Display Name | 【必填】资源库名称,起名字的时候见文知义即可 |
| URL | 【必填】把localhost换成部署服务器IP |
| Description | 【可选】这里主要是对资源库的描述,填写与否都可以 |
| Launch connection on startup | 【可选】这里勾选与否都不影像资源库使用 |
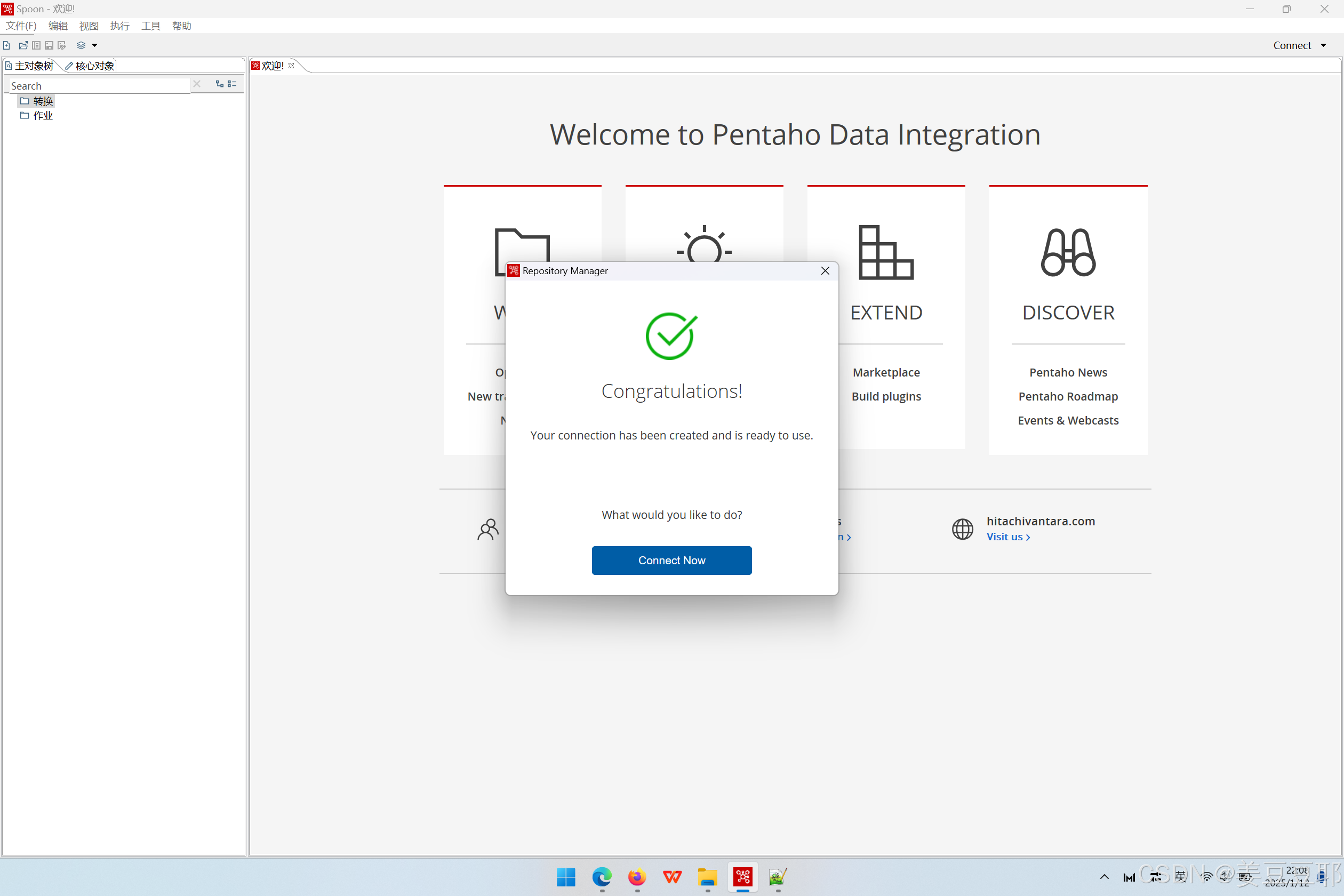
5、配置完成
以上的参数配置完成后,点击右下角的Finish即可 。此时已经配置完成,会出现如下界面。
6、登录资源库
配置完成后,点击右上角connect;选择刚刚创建的资源库名称,即可弹出用户登录界面,此时输入用户密码即可登录。至于用户密码如何设置,大家可以往下看。
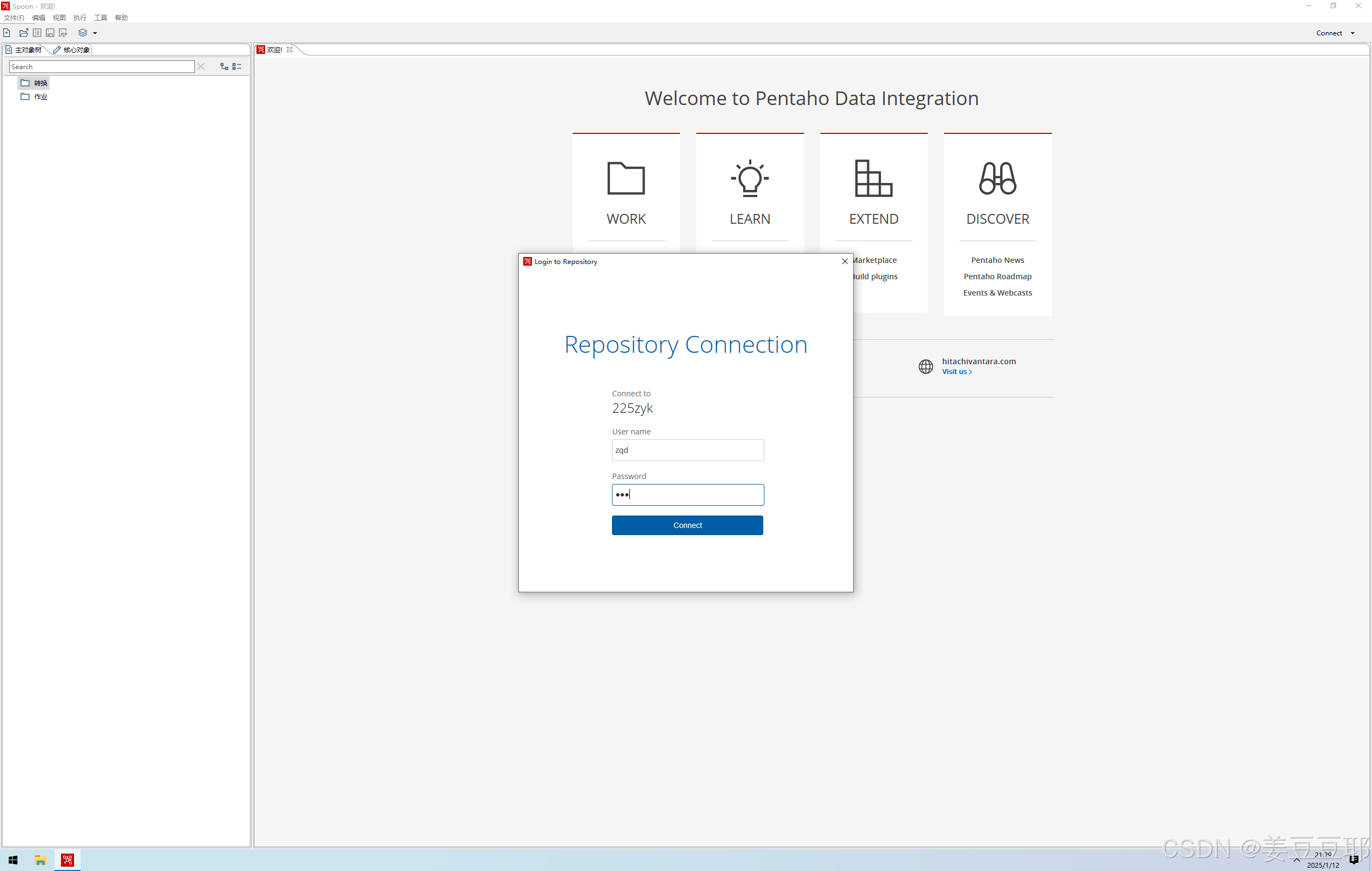
四、Pentaho Repository资源库管理
在ETL项目上对于资源库的管理是非常重要的一项工作,巧用资源库管理可以极大的提高工作效率,这里会选择几个比较常用的点和大家分享。
| 序号 | 资源库管理内容 |
| 1 | 资源库用户管理 |
| 2 | 资源库导入导出 |
| 3 | 资源库迁移技巧 |
| 4 | 资源库作业规范 |
| 5 | 资源库版本管理 |
| 6 | 资源库回收站管理 |
1、资源库用户管理
Pentaho Repository是一个适合团队协同开发的资源库。虽然一个用户可以多人同时登录,但是在ETL项目管理的时候,往往是需要知晓转换、作业各个版本的修改人是谁,方便溯源。所以必须要创建多个用户。下面简述Pentaho Repository创建用户步骤。
(1)登录Pentaho Server服务的web界面
web界面的地址在上面已经提到过,地址是【服务器IP:8080/pentaho】。刚部署完还没有创建用户的时候,可以使用admin进行登录,admin的默认密码是password。
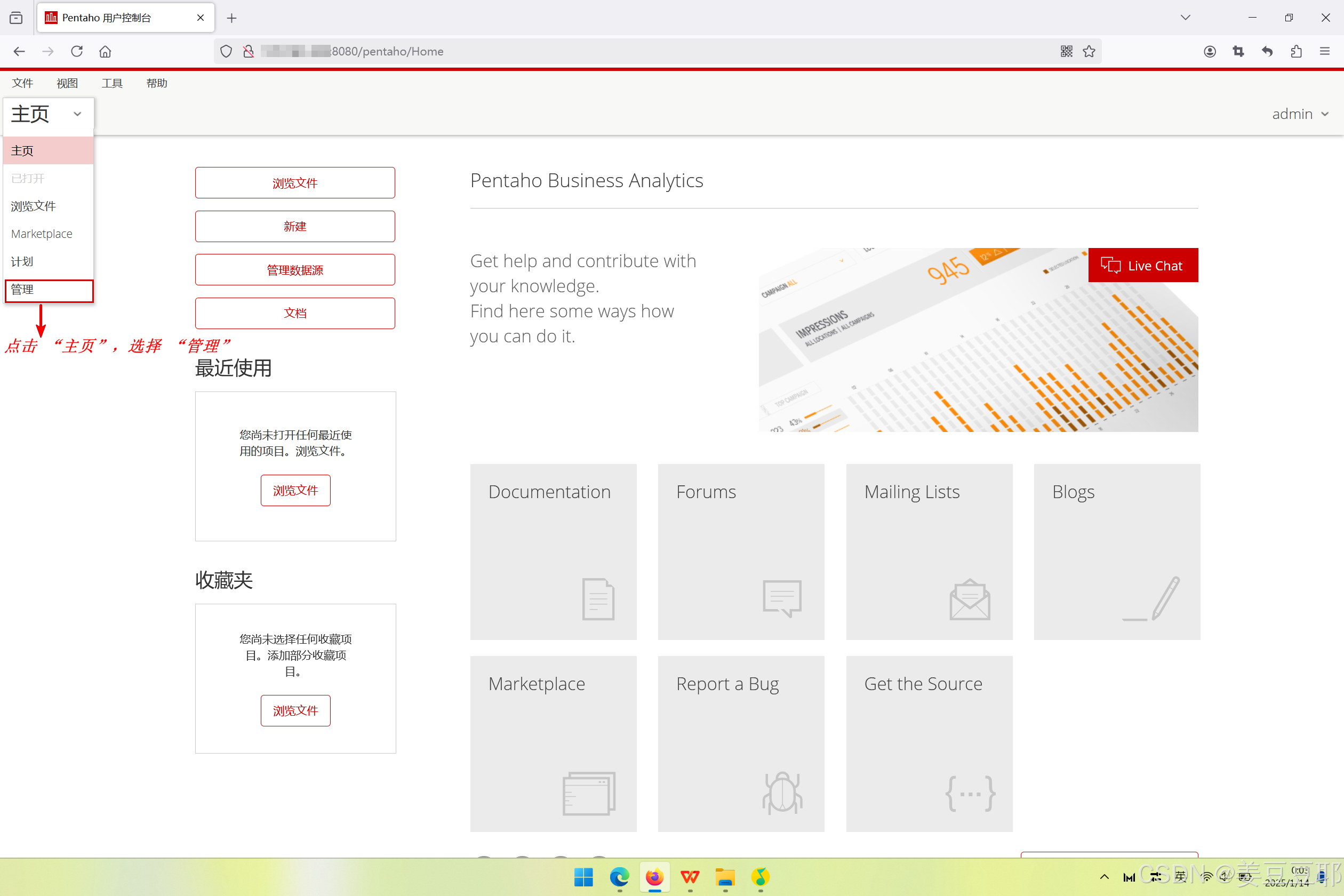
(2)点击 “主页”,选择 “管理”
下面这张图就是pentaho的web主页面,进入后点击左上角的主页,选择下划出的 “管理”点击。
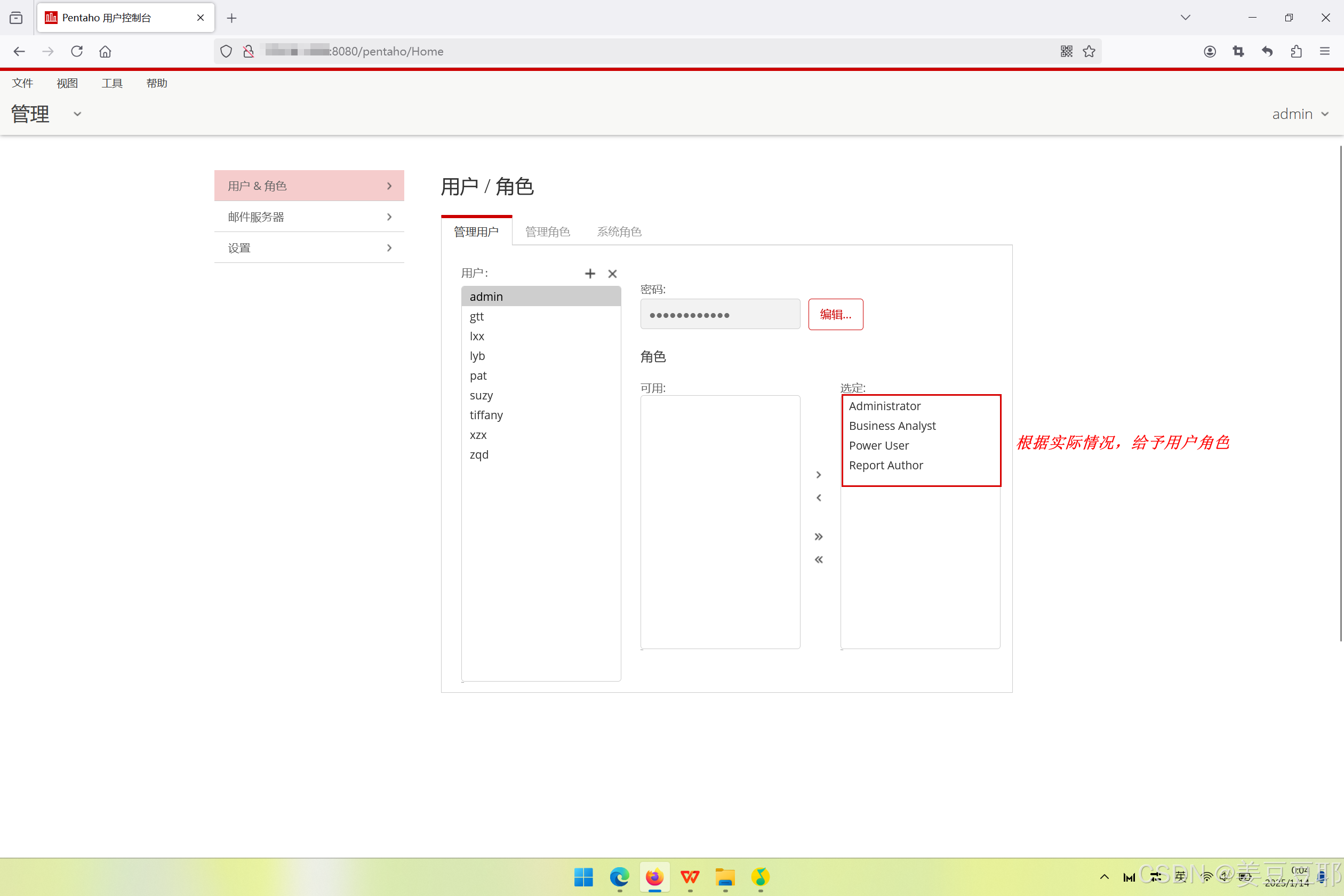
(3)增删改用户与角色权限
在第(2)步选择“管理”后,会进入到如下界面。在此界面可以进行用户的增删改、角色的增删改。这里的用户角色,如果比较严格的话就按照实际需要分配角色或者重新创建角色;如果项目上没有那么严格就直接全给了。
2、资源库导入导出
在项目上,资源库的导入与导出是很频繁的。因为ETL项目多了以后,有很多ETL模型是可以复用的;从其他项目拿来ETL模型后,直接导入修修改改就能用,这会大大提高工作效率。下面简述资源库导入导出步骤。
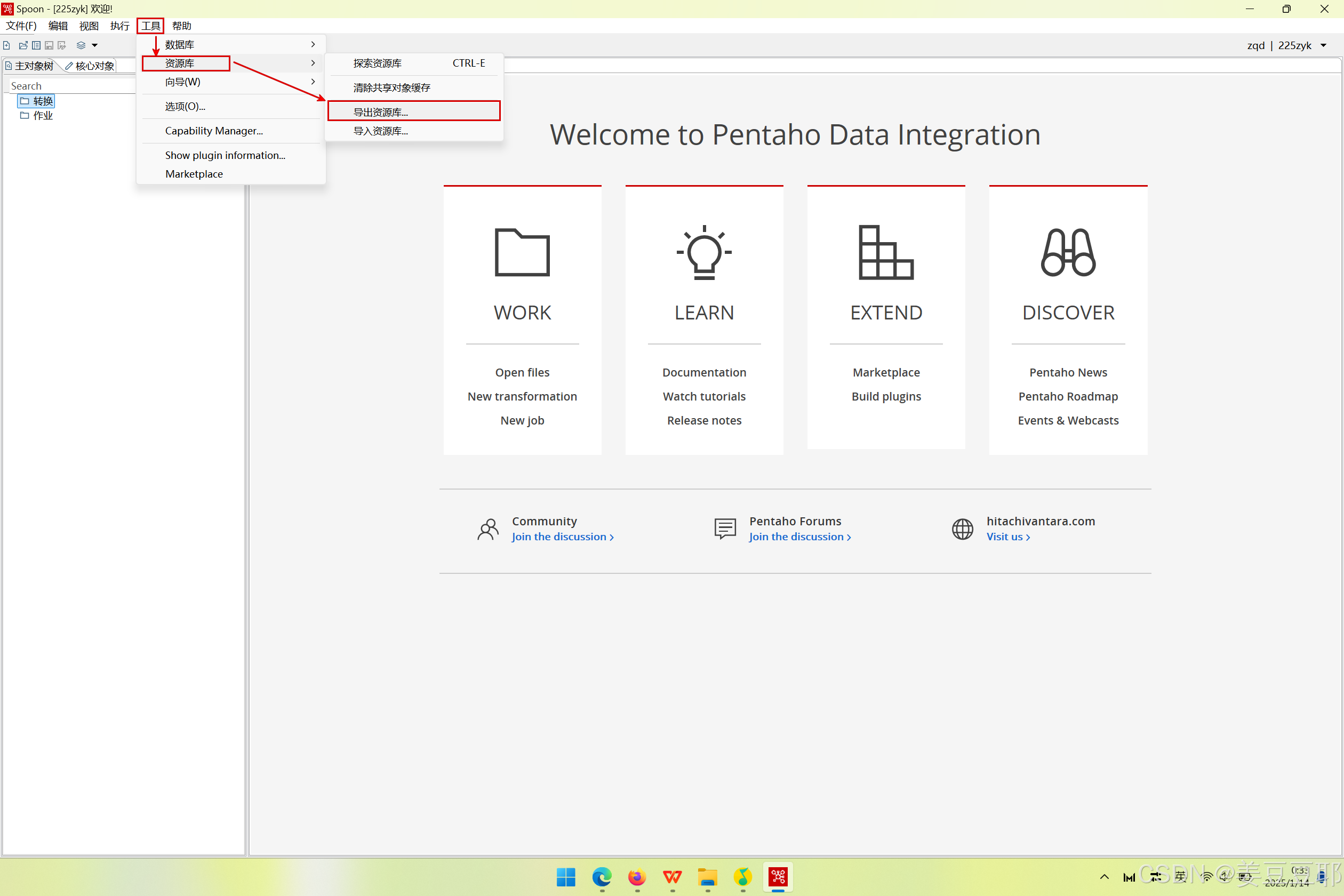
- 资源库导出
(1)客户端界面依次选择【工具】—>【资源库】—>【导出资源库】
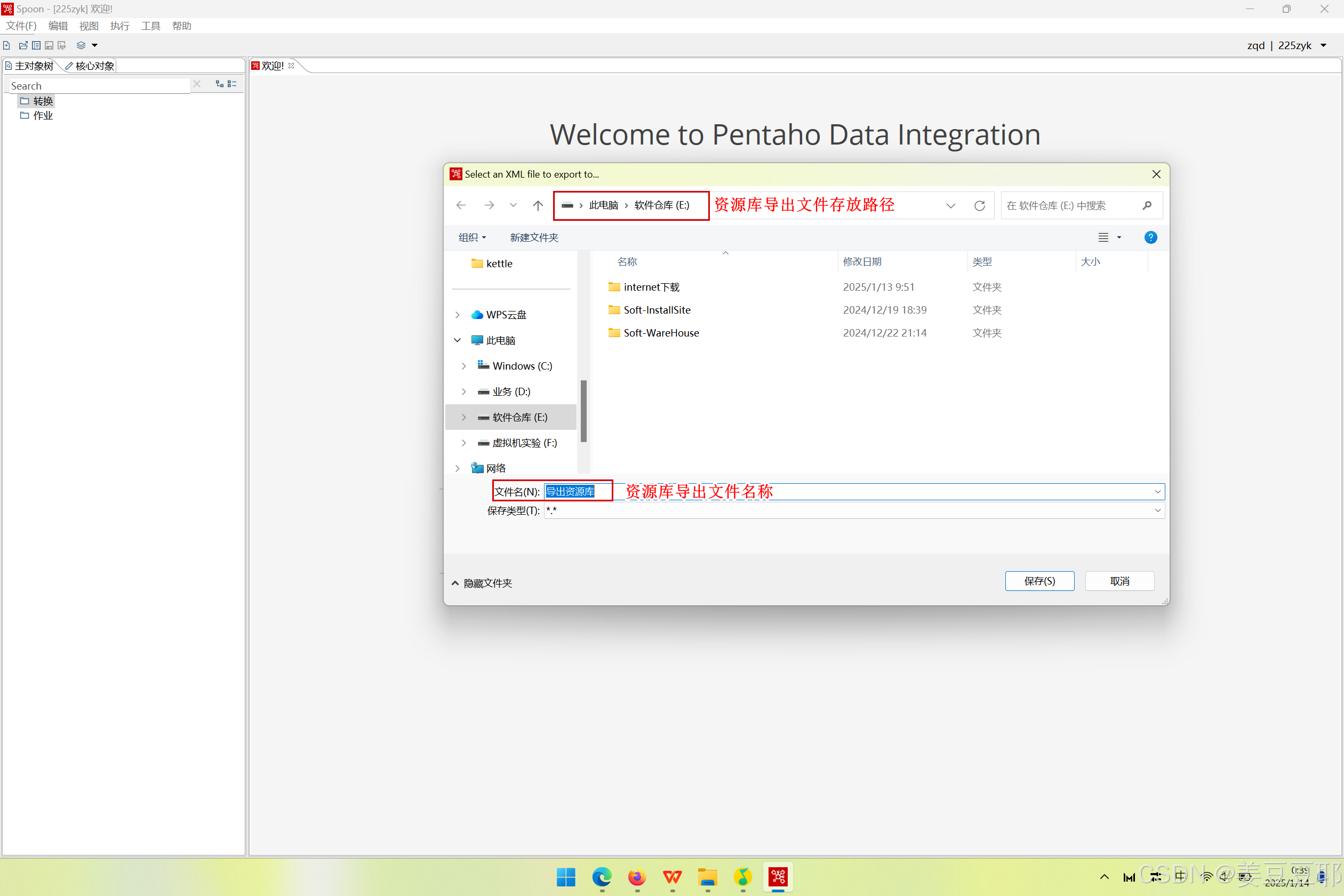
(2)选择导出资源库文件存放路径、设置导出资源库文件名称
设置完后,点击保存!
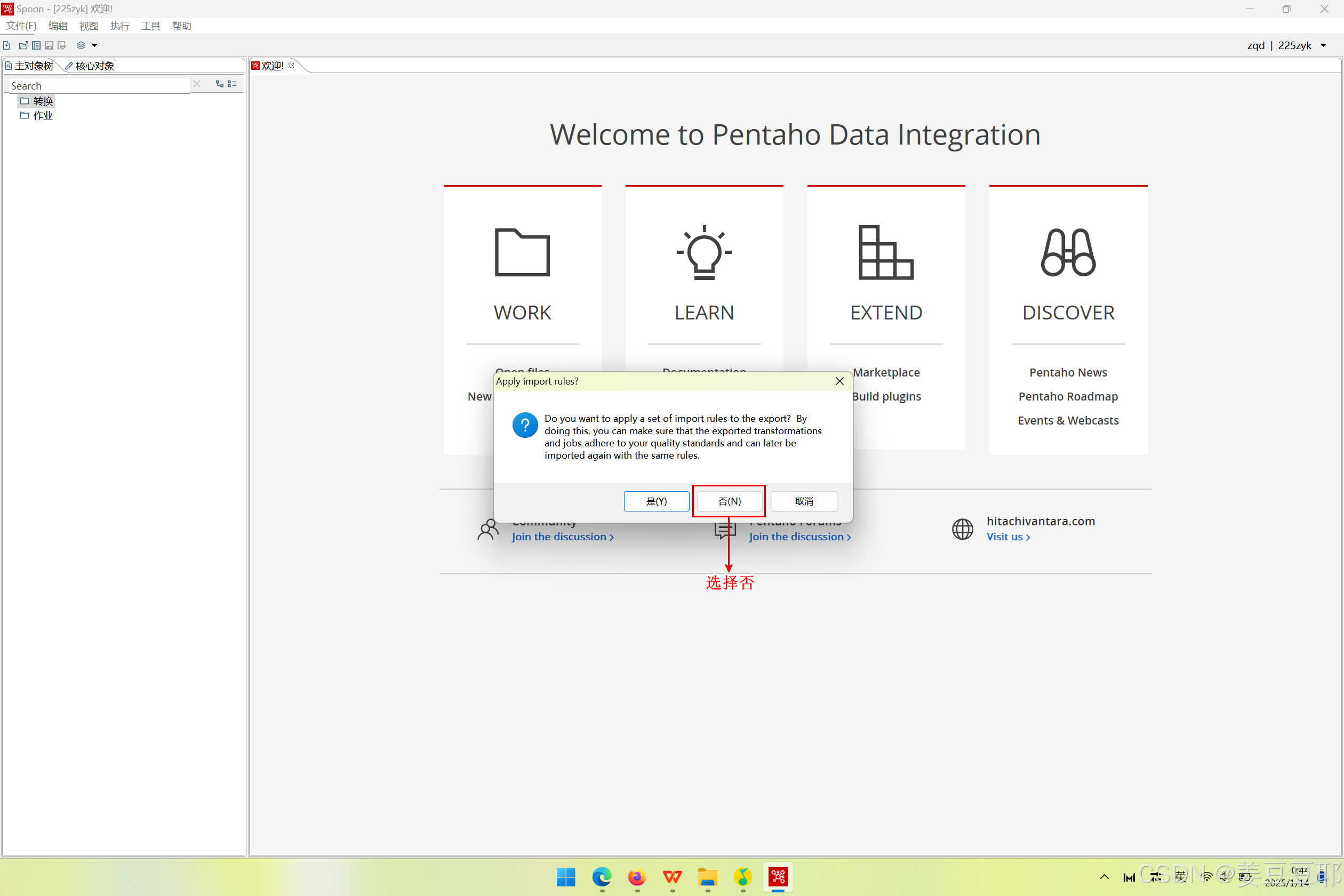
(3)不设置规则
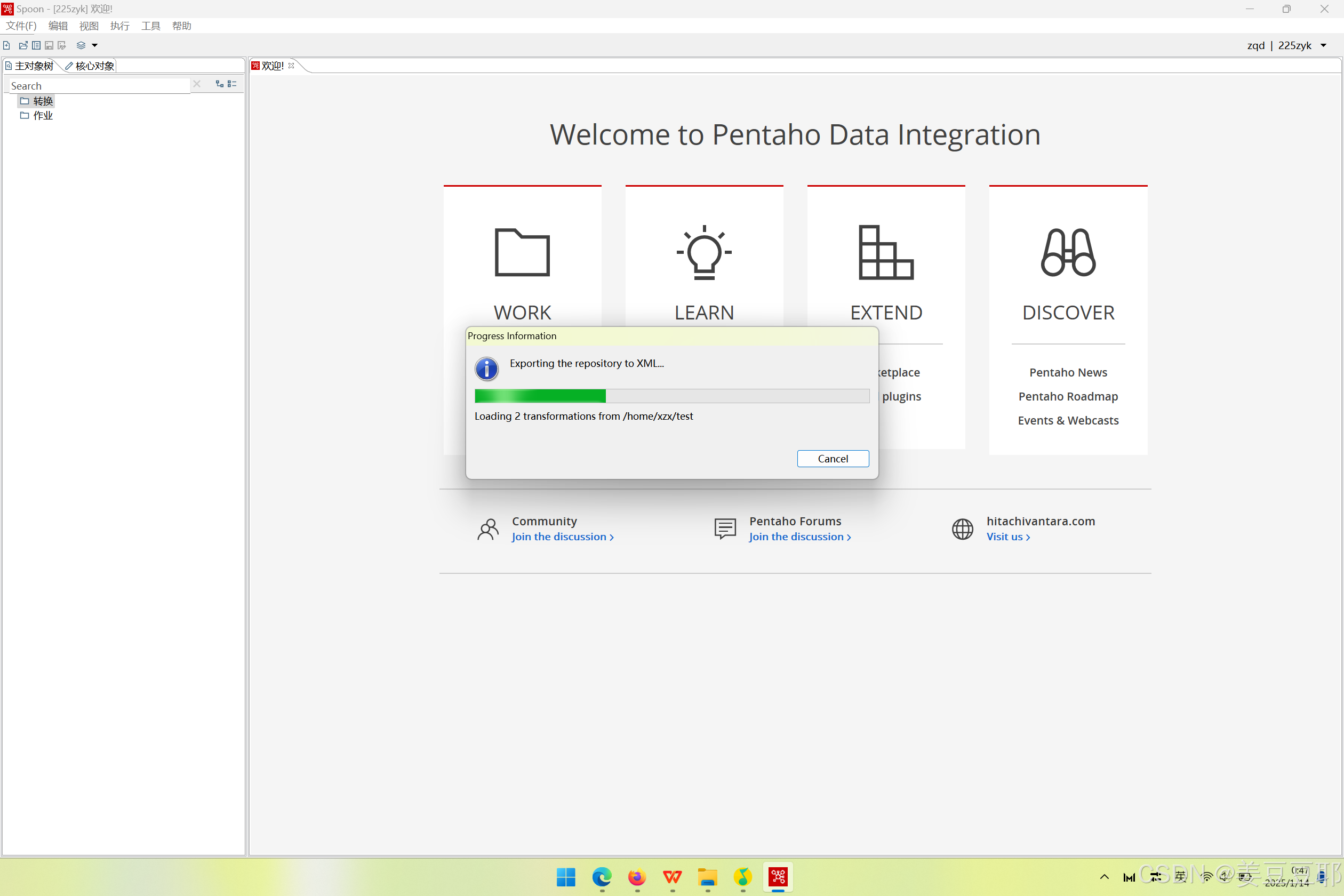
(4) 开始执行导出
(5)导出完成

- 资源库导入
(1)客户端界面依次选择【工具】—>【资源库】—>【导入资源库】
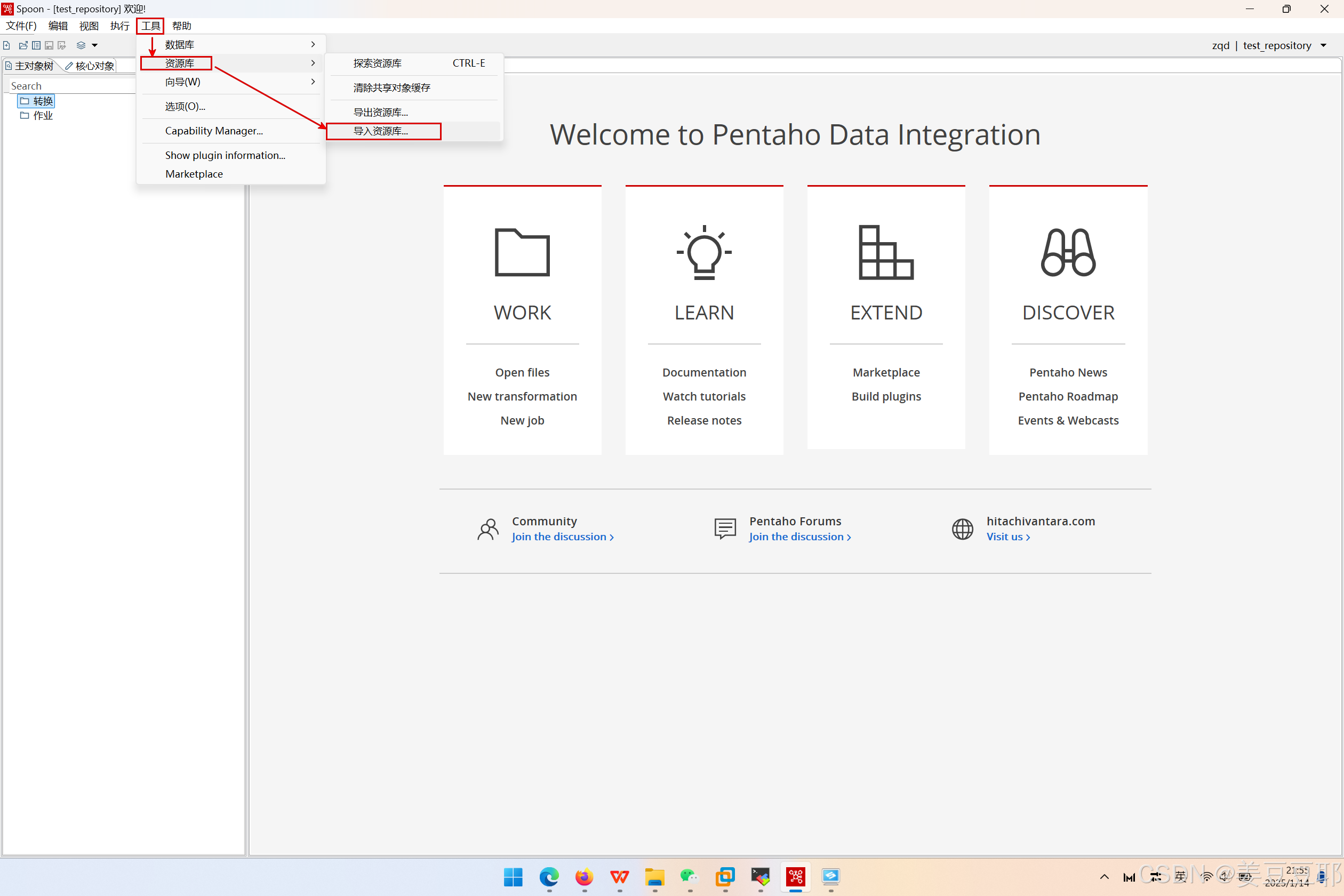
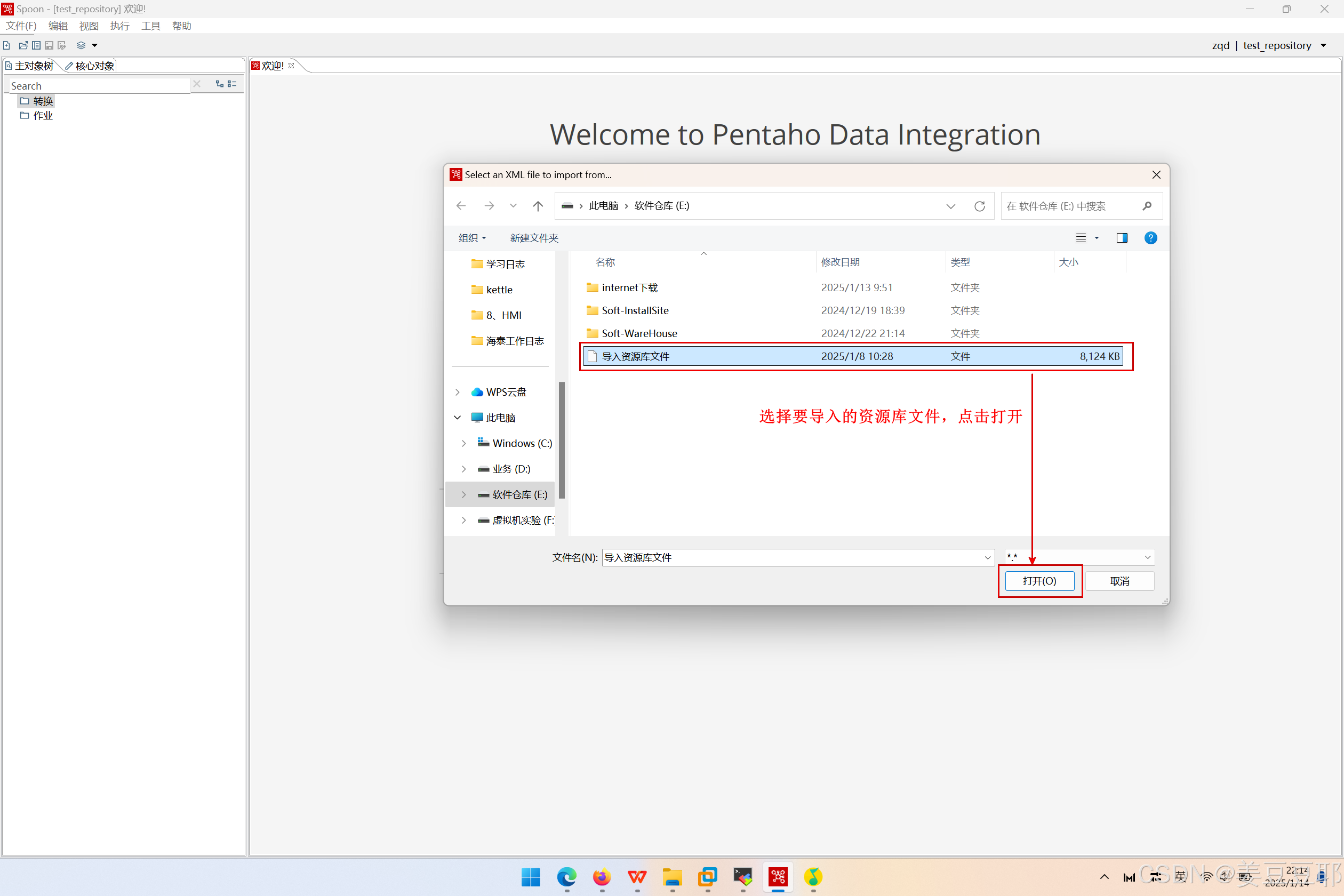
(2)选择要导入的资源库文件
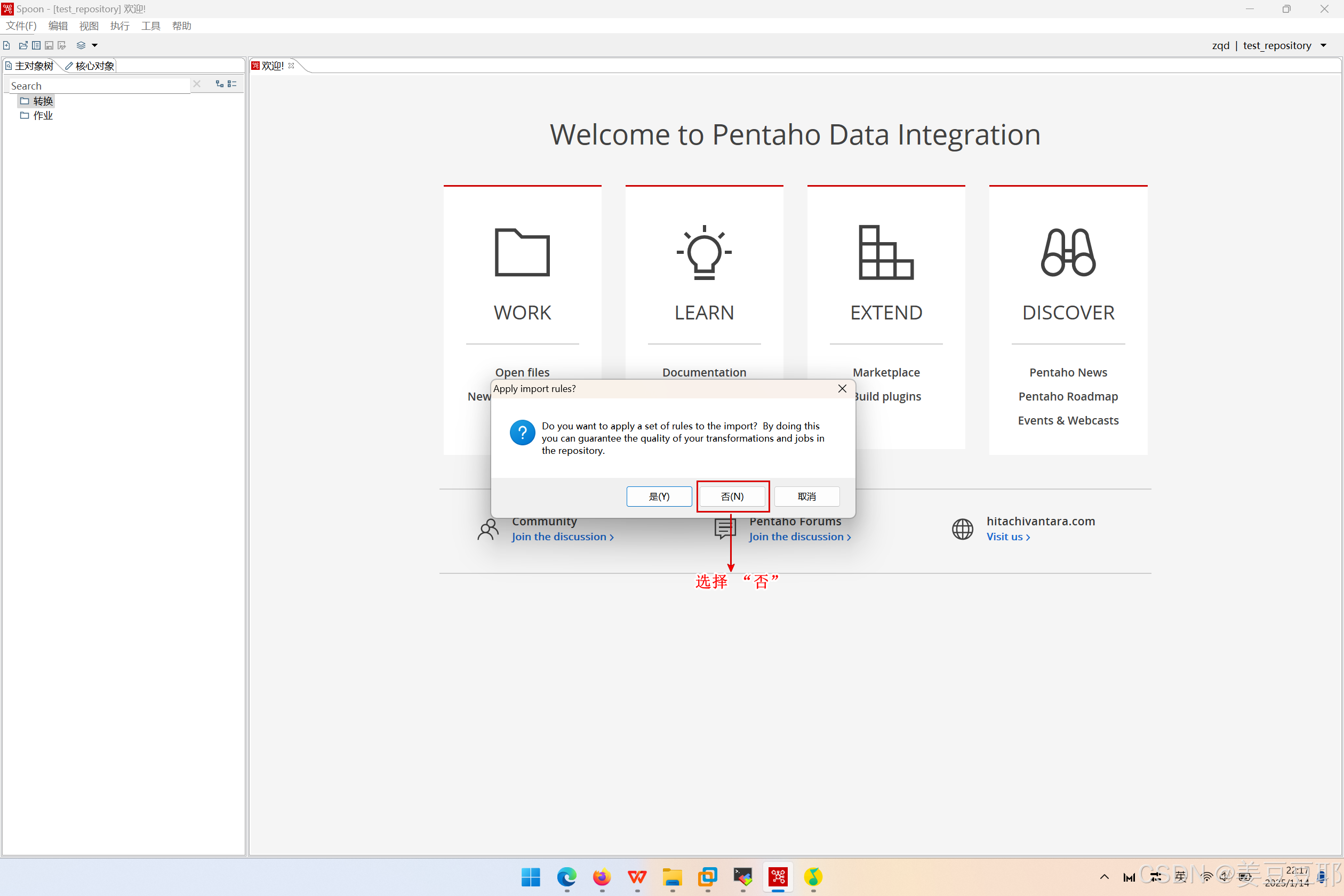
(3)不应用规则
(4)选择导入的资源放置的目录
可以按照需要提前新建一个目录,用于放置导入的资源!

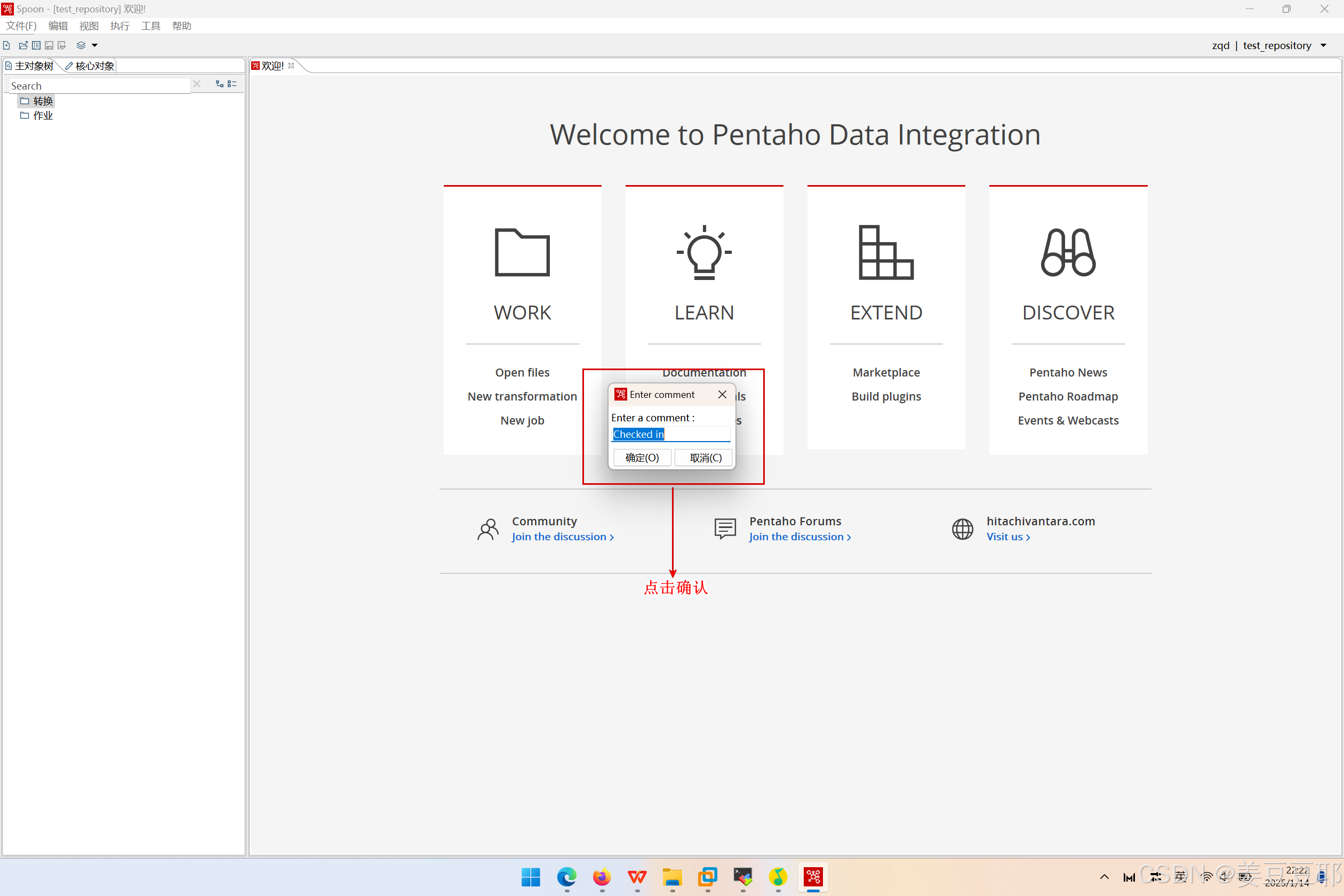
(5)嵌入
(6)完成导入
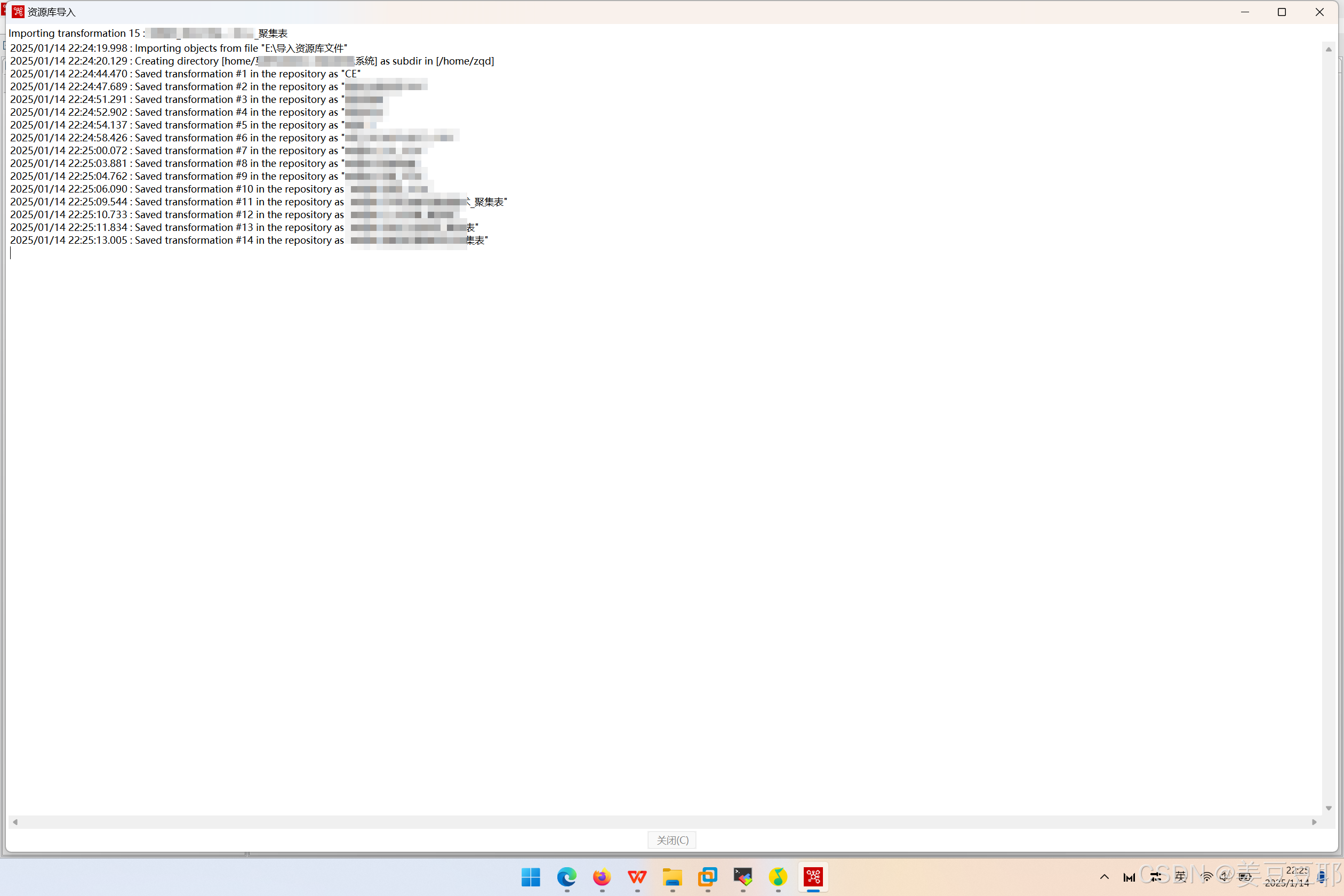
完成上述步骤后,等到资源库导入完成即可。
3、资源库迁移技巧
上面和大家分享了资源库的导入导出,步骤其实很简单。但其实在导入的时候有个特别头疼的问题,就是在做资源库导入的时候,会出现一个情况:导入的资源会在导入时选择的目录下重新按照【/home/.....】这样的路径格式去存储。
这个情况会造成两个问题:一个是没有按照自己预想的规划存放ktr和kjb文件;一个是会使得资源中的作业中的绝对路径失效,因为路径已经变化了。
那如何处理这个情况呢?
方法就是将ktr和kjb文件移动至提前规划的目录。怎么移动呢?kettle客户端不支持批量移动。成百上千个转换和作业,一个个靠手移动真的得累死人。在这个场景下,pentaho server的web界面,就发挥了作用!下面给大家做下分享演示。
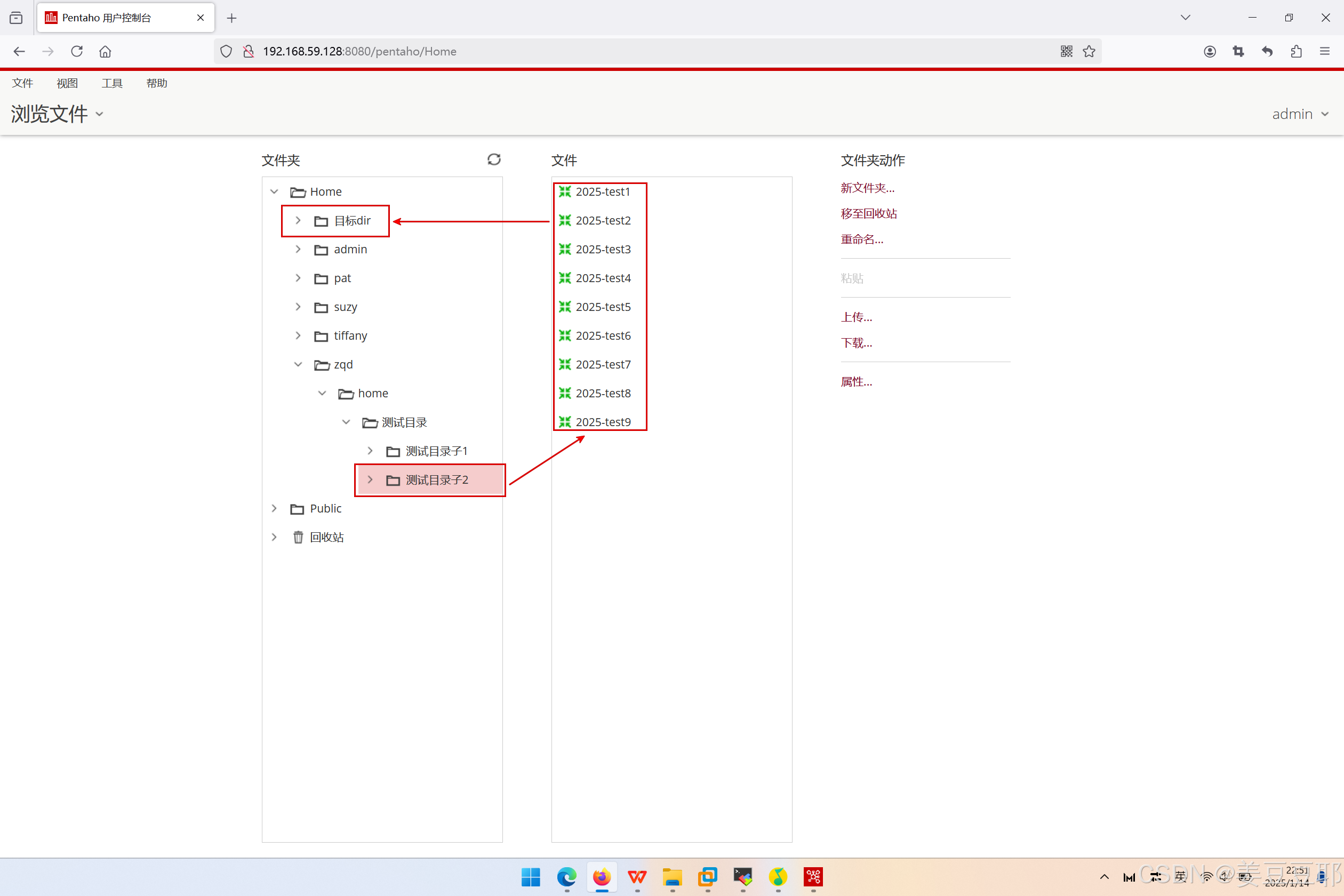
(1)将测试目录子2的ktr文件批量移动到目标dir
点击pentaho server的web界面中的浏览文件,即可进入如下界面。找到需要移动的文件目录,并确认目标目录是哪个。
(2)ktr/kjb文件全选
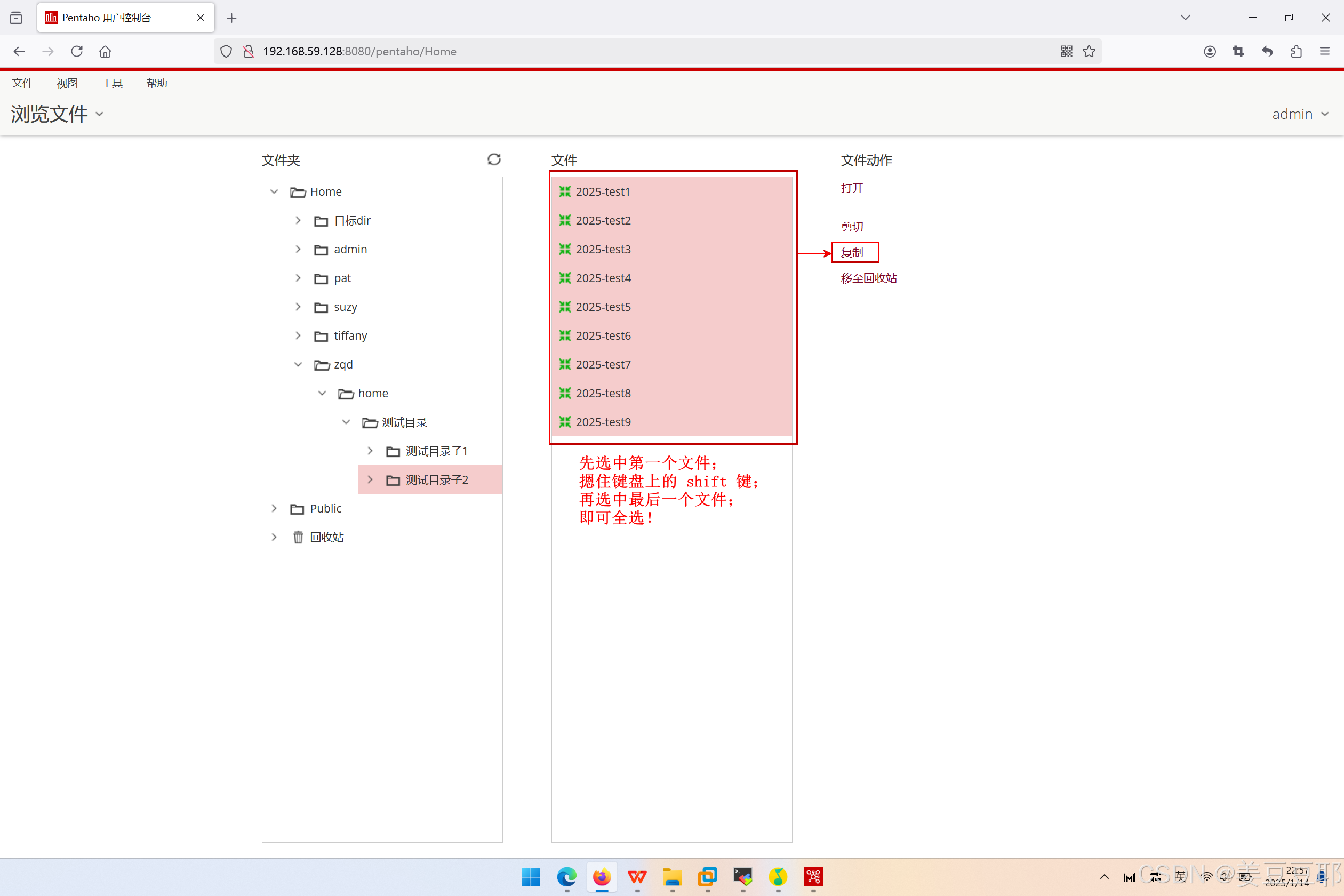
在kettle的客户端中,是没有全选这个操作的。但是在web界面可以,简单的说就是web界面的文件管理功能,就类似于在操作系统上的文件操作。
打开需要移动的文件目录后,先选中第一个文件;再摁住键盘上的 shift 键;最后选中最后一个文件;此刻已经全选文件。然后点击文件右侧的复制(或者剪切都可以)
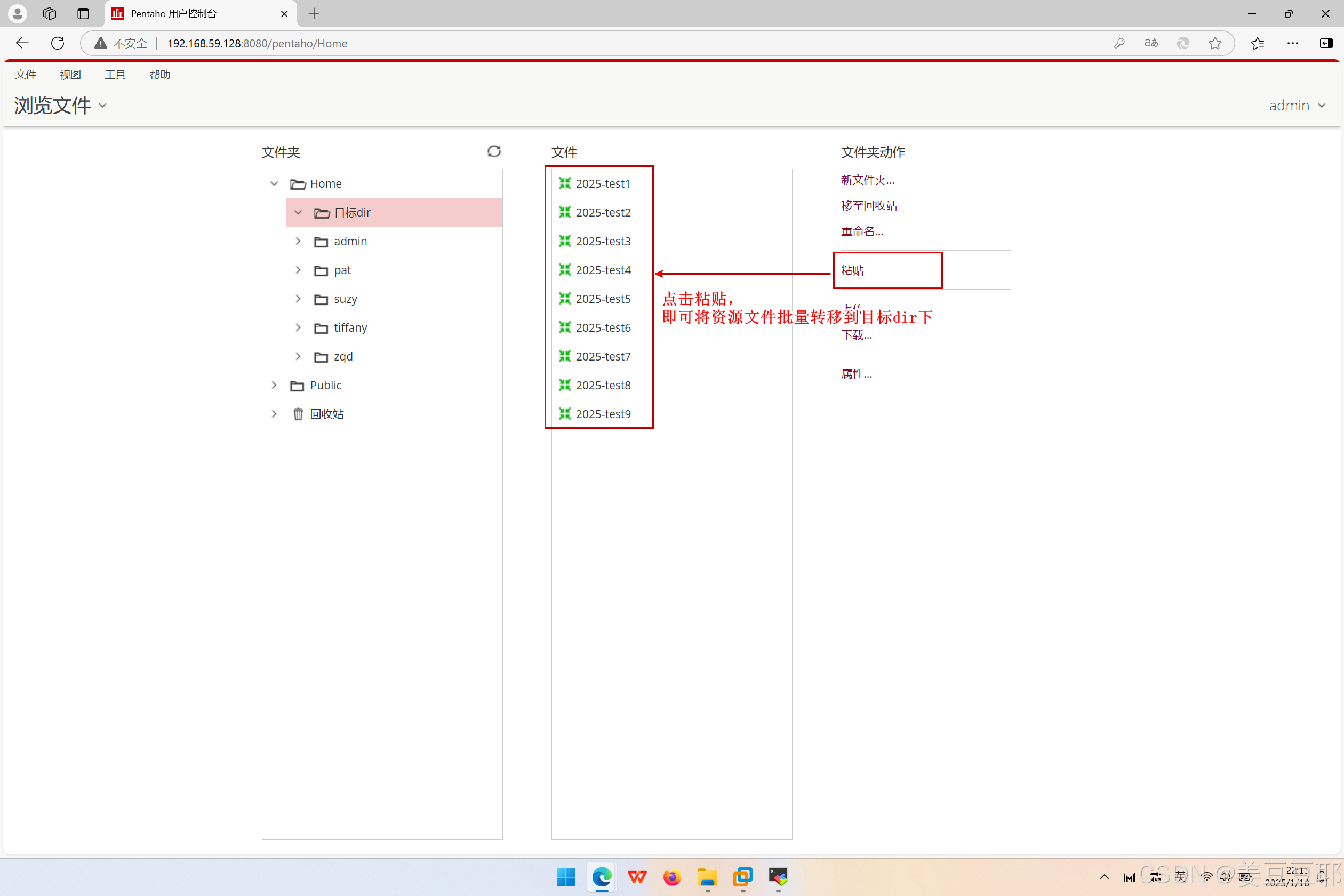
(3)粘贴至目标dir
进入目标dir目录下,点击粘贴,即可将复制或者剪切的资源文件批量移动到目标dir下。
4、资源库作业规范
通过上面的分享,我们已经可以进行对资源库进行迁移,并批量处理ktr与kjb资源文件的技巧。但是距离真正使用导入的资源库,还有一个关卡——作业中的ktr绝对路径或者kjb绝对路径。
建议的规范操作是ktr绝对路径或者kjb绝对路径设置为全局变量,这样即使说想要将ktr、kjb文件更换一个新的目录,也不必再担心因为目录变更而导致作业无法正常执行了。
如下图
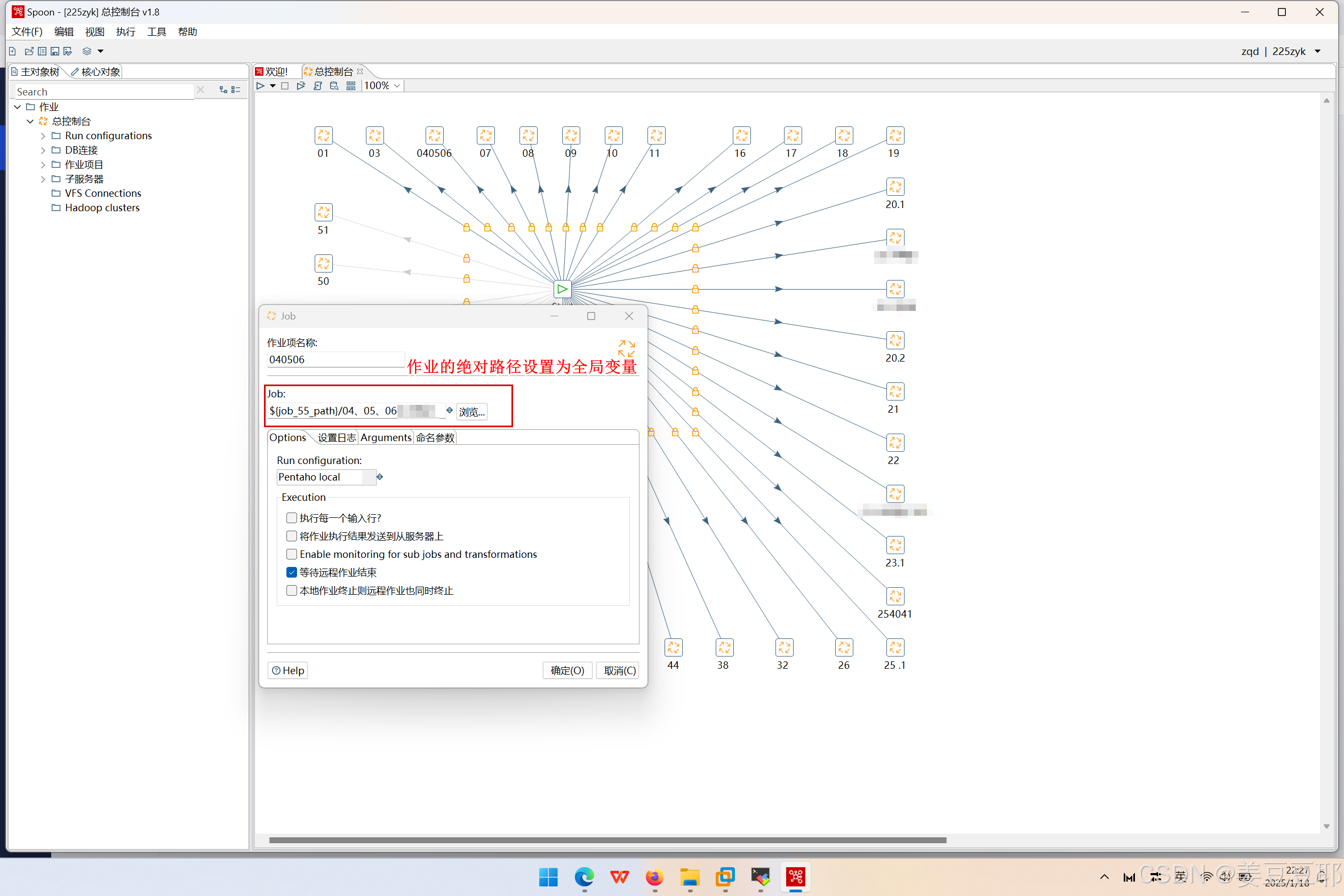
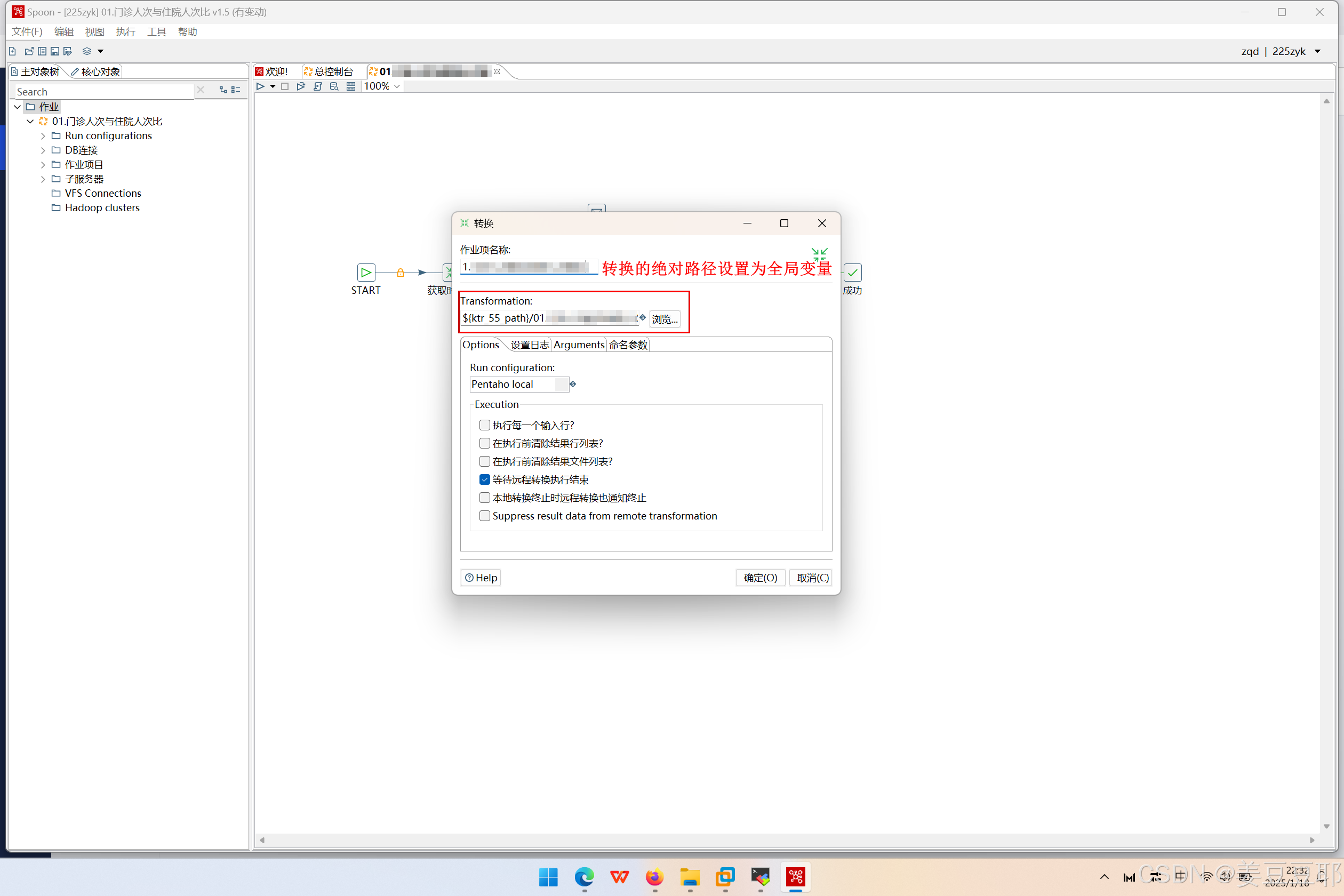
那么全局变量在哪里设置呢?大家可以看下图。
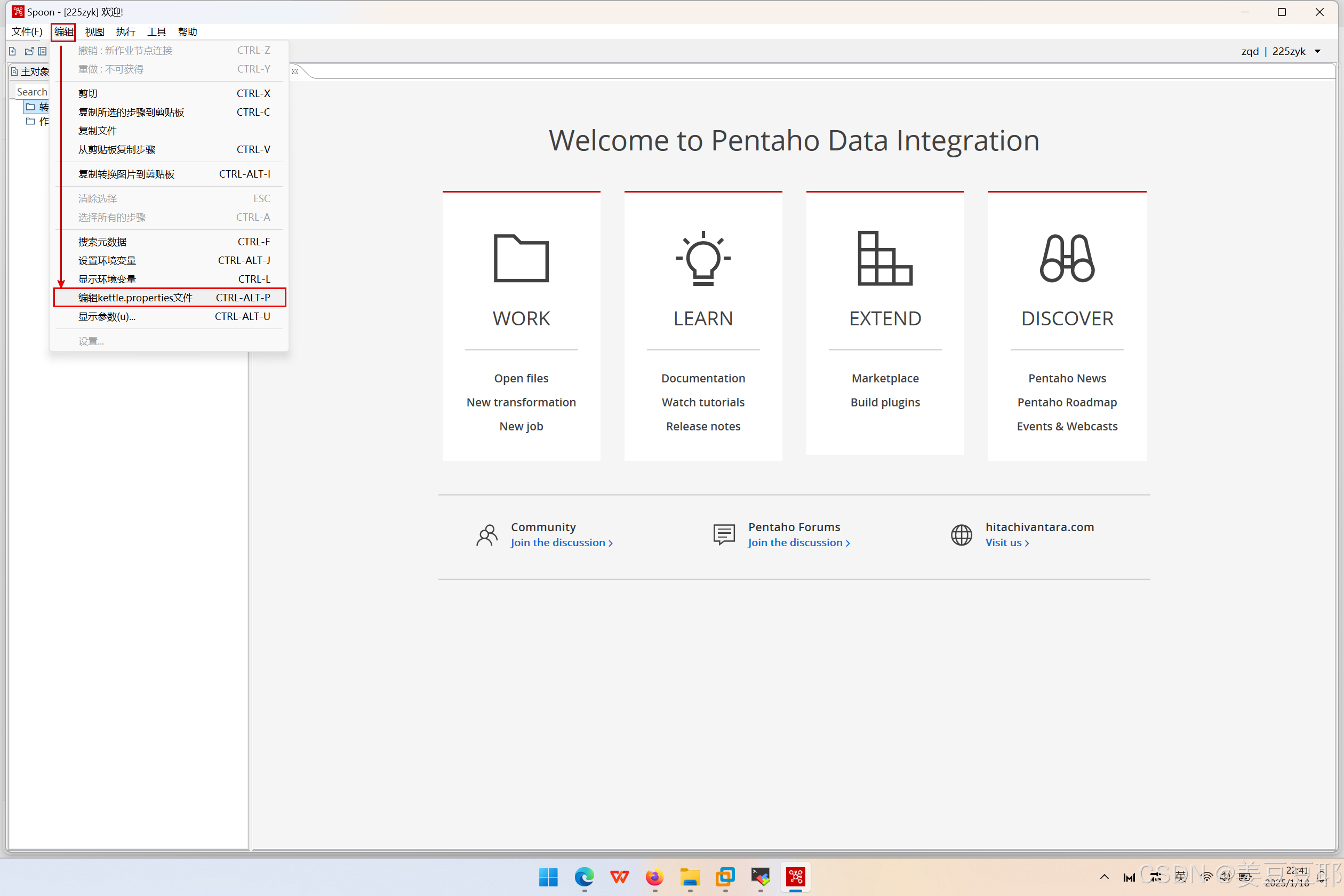
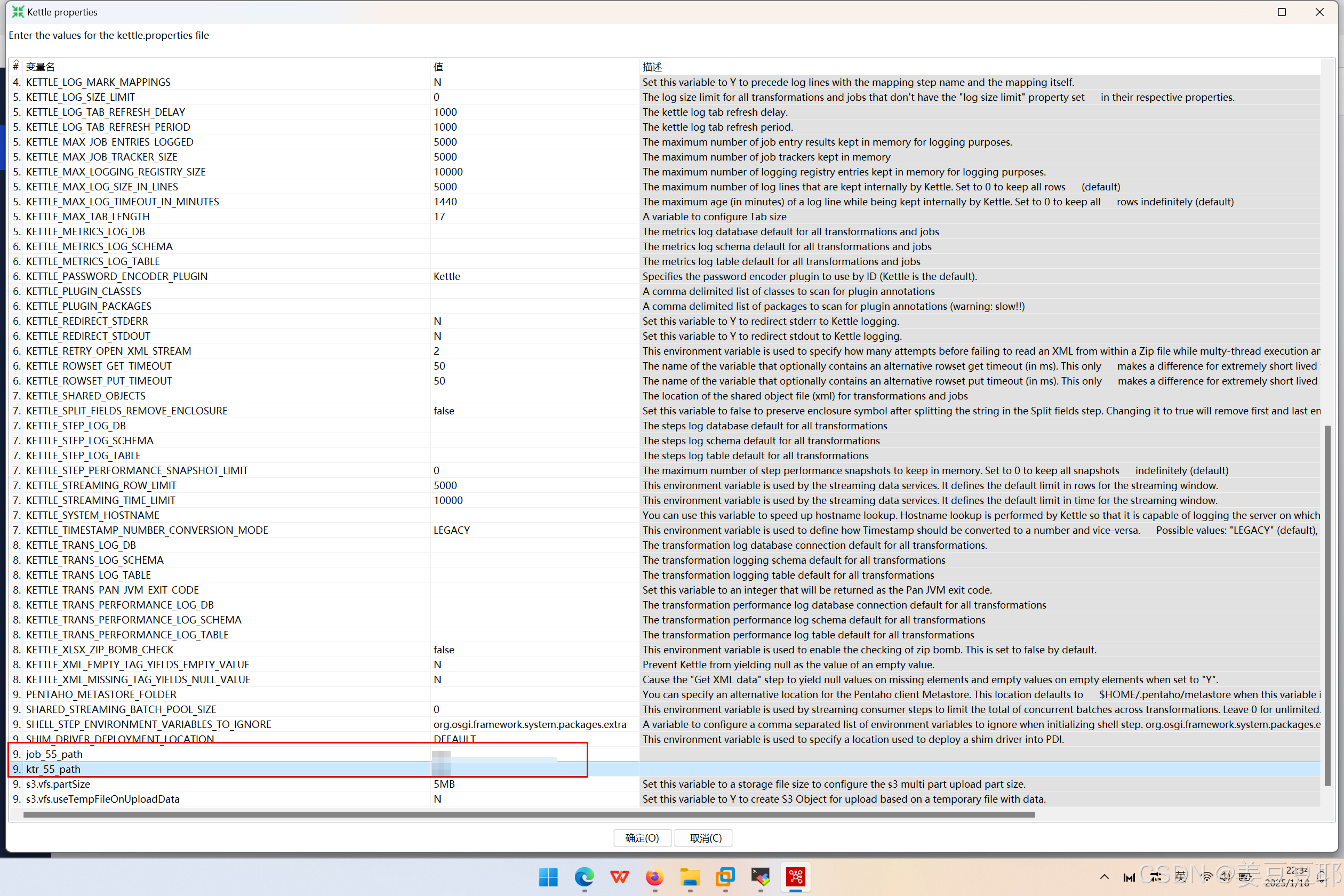
5、资源库版本管理
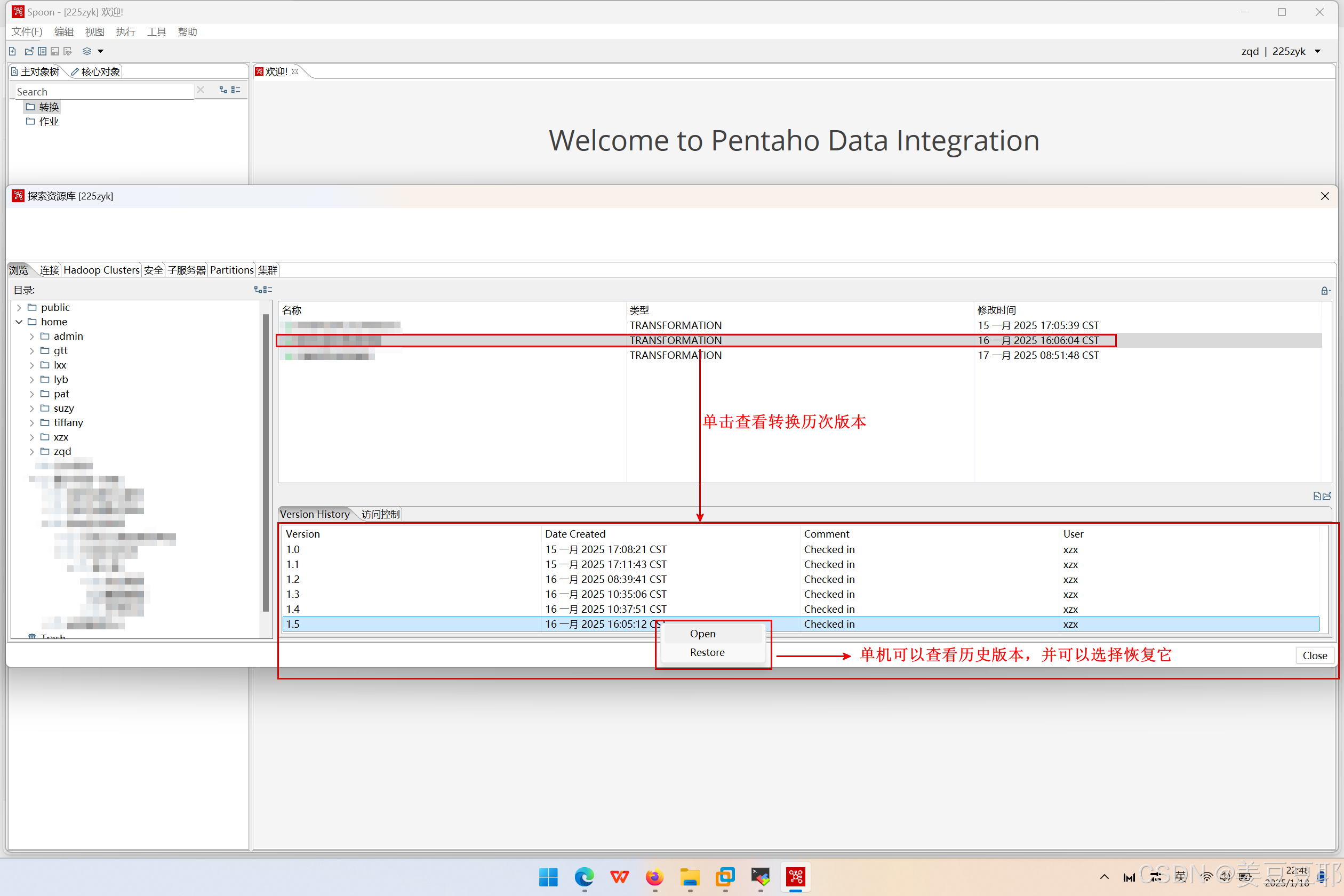
pentaho repository提供了版本管理。因为有时ETL开发人员可能因为手快于脑保存错了ETL模型,此时想要恢复到之前的版本,也是支持的。
并且版本管理可以查看到历史版本的修改者是哪个用户,可以进行溯源管理,也是防止ETL开发人员随意甩锅哦~
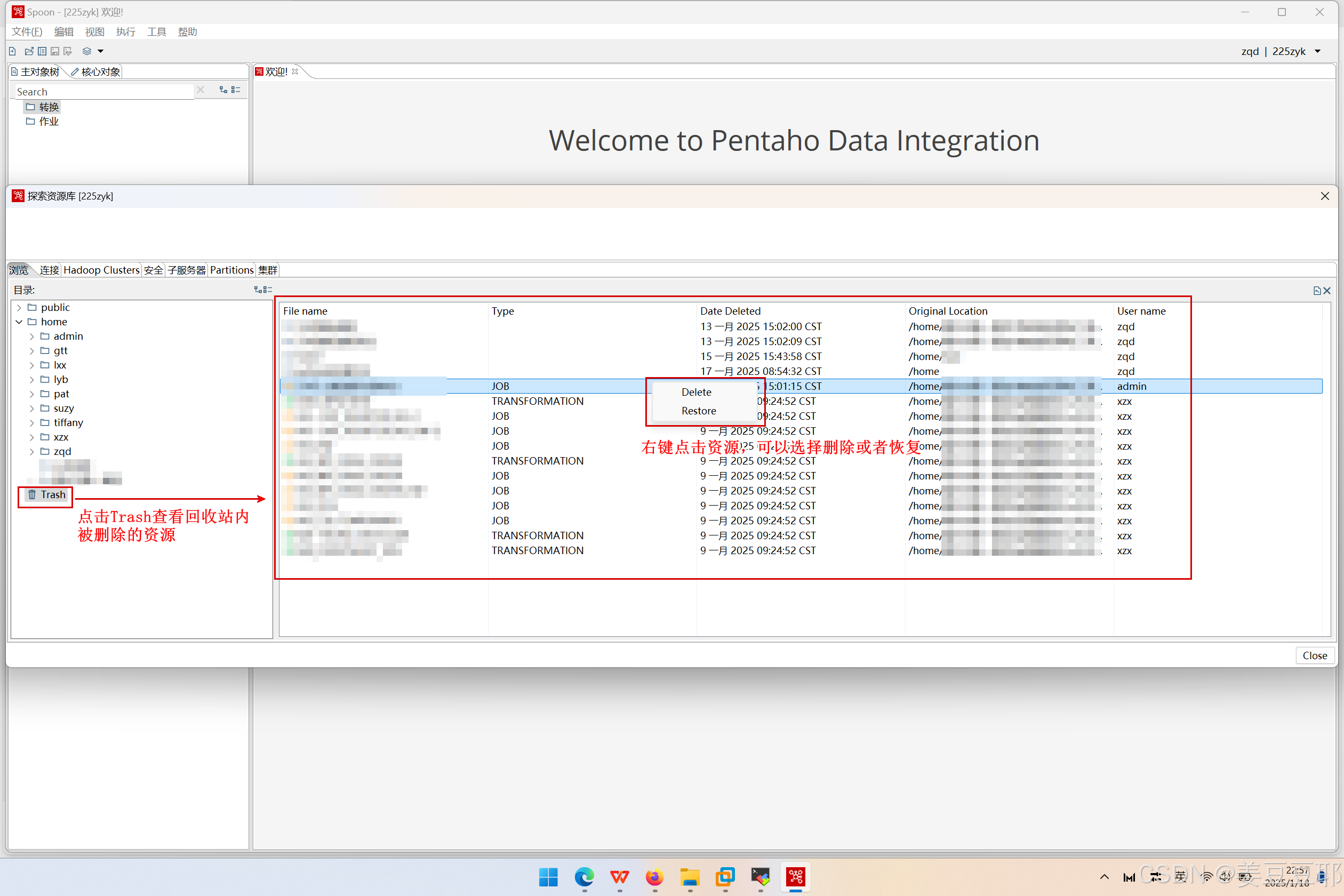
6、资源库回收站管理
工程师也是人嘛,人总有失误的时候。有时候我们可能会失误删除某些重要资源,重新开发就不划算了。所以可以利用pentaho repository资源库的回收站功能,对误删资源进行恢复。当然您也可以选择彻底删除该资源。
五、Pentaho Repository资源库备份
虽然pentaho repository资源库具有回收站功能,但是如果我们的资源库因为其他原因发生了损坏或者丢失,是很难恢复的。所以我们可以通过备份脚本对资源库进行全量备份,以下是资源库备份shell脚本的一个样例,供大家参考。
#!/bin/bash
#定义备份文件目录,即kettle-资源库安装所有目录
default_db_path="/home/pentaho/pentaho-server"
#备份文件,先找到文件,找到后,然后备份文件(压缩包形式备份):
#需要备份的文件有 2 个:default目录下面的db.mv.db 和 version目录下面的db.mv.db.
#有些项目现场的文件不是db.mv.db,有可能是db.h2.db文件。
#第一步:定义日期,用于下面备份文件用;
DATE=$(date +%Y%m%dT%H%M%S)
#备份第一个文件(default目录中db文件):
cd $default_db_path/pentaho-solutions/system/jackrabbit/repository/workspaces/default &&
latest_db=$(ls -t db.*.db | head -n 1)
#压缩备份文件,减少空间
if [ -z "$latest_db" ]; then #-z 表示后面参数是否为空
echo "在${default_db_path}/pentaho-solutions/system/jackrabbit/repository/workspaces/default目录下没有找到 ${latest_db} 文件!"
else
echo "在${default_db_path}/pentaho-solutions/system/jackrabbit/repository/workspaces/default目录下已找到 $latest_db 文件"
tar -czvf ${latest_db}_$DATE.tar.gz db.*.db &
echo "成功备份:${latest_db}!文件"
fi
#删除备份文件,只保留最新的10个文件。处理思路:
#1、先统计压缩包gz文件有多少个;
#2、超过10个以上的,删除前面几个,然后每删除一个,变量累加1.
#3、不超过10个文件,不进入到删除界面。
#定义保留文件数
ReservedNum=7
#第一步:*.tar.gz为文件类型,不写查找所有文件
FileNum=$(ls -l *.tar.gz |grep ^- |wc -l)
#第二步:ls -rt [r 表示倒序,即最旧的数据放在最上面,t 表示按时间]
while(( FileNum > ReservedNum))
do
echo "备份文件个数:$FileNum"
OldFile=$(ls -rt *.tar.gz| head -1)
echo "删除文件:" $OldFile
rm -f $OldFile
let "FileNum--"
done
#备份第2个文件(version目录下的db文件)
cd $default_db_path/pentaho-solutions/system/jackrabbit/repository/version &&
latest_db=$(ls -t db.*.db | head -n 1)
#压缩备份文件,减少空间
if [ -z "$latest_db" ]; then #-z 表示后面参数是否为空
echo "在${default_db_path}/pentaho-solutions/system/jackrabbit/repository/version目录下没有找到 ${latest_db} 文件!"
else
echo "在${default_db_path}/pentaho-solutions/system/jackrabbit/repository/version目录下已找到 $latest_db 文件"
tar -czvf ${latest_db}_$DATE.tar.gz db.*.db &
echo "成功备份:${latest_db}!文件"
fi
#删除备份文件,只保留最新的10个文件。处理思路:
#1、先统计压缩包gz文件有多少个;
#2、超过10个以上的,删除前面几个,然后每删除一个,变量累加1.
#3、不超过10个文件,不进入到删除界面。
#定义保留文件数
ReservedNum=7
#第一步:*.tar.gz为文件类型,不写查找所有文件
FileNum=$(ls -l *.tar.gz |grep ^- |wc -l)
#第二步:ls -rt [r 表示倒序,即最旧的数据放在最上面,t 表示按时间]
while(( FileNum > ReservedNum))
do
echo "备份文件个数:$FileNum"
OldFile=$(ls -rt *.tar.gz| head -1)
echo "删除文件:" $OldFile
rm -f $OldFile
let "FileNum--"
done
exit 0


















 1104
1104

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











