






近日,英伟达再次引爆科技圈,推出cosmos世界基础模型(world foundation model),根据英伟达官方解释,cosmos是一个用于加速物理AI开发的平台,可以预测与生成未来虚拟世界物理感知视频的神经网络,以帮助开发者进一步构建未来机器人与自动驾驶应用。WFM如大语言模型,属于一个基础性模型,WFM 通过学习大规模视频数据集中的物理规律和自然行为,能够生成与现实世界具有一定相似性的3D高清视频场景。同时通过扩散模型和自回归模型,对预训练的 WFM 进行微调,可以使其适应特定的物理 AI 任务。对于当下的具身智能模型训练,提供了新的支持。

近年来,其他AI领域,如生成式AI,强化学习AI获得飞速发展,其中生成式AI以GPT为代表,带动AI agent,多模态等相关领域的前行。物理AI,借助传感器观察世界,利用执行器与之互动和改变世界,其发展面临训练数据获取困难的挑战,因为所需数据需包含观察和行动的交错序列,而行动可能干扰物理世界并造成损害,尤其是在 AI 发展初期探索性行动较多时。COSMOS对于物理AI,可以帮助其获取环境与行动数据。
COSMOS 世界基础模型:
对于世界基础模型的直观解释,可见下图,Xo:t代表着在现实世界传感器过去在o-t序列时刻观测到的数据,Ct代表当下物理世界行为环境数据,COSMOS模型平台为W,在W的作用下,预测未来T+1时刻的环境数据以及反应行为,输出^Xt+1。

当前WFM由视频编辑,视频标记,WFM预训练,后训练应用以及安全防护组件这几个部分,用于阻止有害的输出和输入。
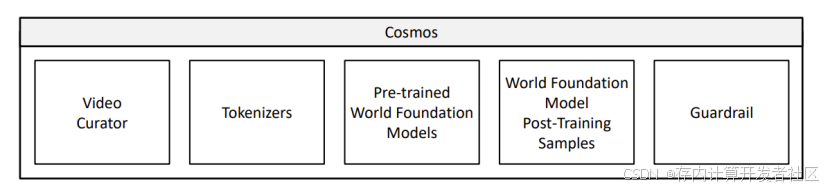
COSMOS 世界基础模型对未来有多种用途:
1,策略评估:让物理AI系统的重复数据与世界基础模型产生交互以替代运行训练好的策略作用于真实的物理世界,提高处理效率以及减少时间的消耗,通过WFM,开发者们可以通过在虚拟世界的数据运行来判断策略是否可行,短时间内做劣质策略的排除,在有限的资源内,提升落地策略的质量。
- 策略初始化:一个策略系统执行命令根据物理AI系统的委派,其通过现实环境当下的观测以及任务执行训练,训练完善的WFM模型,可以根据外部的输入进行动态化调整与作出反应,即可作为一个策划初始化模型系统,帮助定位物理AI中出现的数据问题。
- 策略训练:在强化学习的过程中,WFM配备一个反馈模型,可以作为现实世界的代理,通过提供策略模型的训练反馈,智能体通过与WFM交互熟练掌握解决问题的技能。
- 规划和模型预测控制:WFM可以基于现实物理世界的动作序列来模拟未来可能出现的场景,通过成本/奖励模块量化这些不同数据策略的表现,通过模拟整体结果,可以在物理AI中实现最好的动作序列排列,因其在不同的决策策略中表现,可以提高其在物理世界的准确性上线。
- 合成数据:WFM不仅可用于合成数据,他也可以用作微调以及渲染元数据,设定条件的WFM还可用于SIM2Real场景中。
数据处理流程:
推出一项数据集处理方式,流程主要包括以下5项:分割,过滤,标注,去重,切片;

使用专有及公开视频数据,涵盖驾驶、手部动作等 9 类,旨在支持 Physical AI 开发,原始数据约 20M 小时,经处理生成约 108 个预训练和 107 个微调视频剪辑。其中,涵盖了各种物理AI应用,并将训练视频数据集划分为以下类别:
- 驾驶(11%)
- 手部动作和物体操作(16%)
- 人体动作和活动(10%)
- 空间意识和导航(16%)
- 第一人称视角(8%)
- 自然动态(20%)
- 动态相机运动(8%)
- 合成渲染(4%)
- 其他(7%)
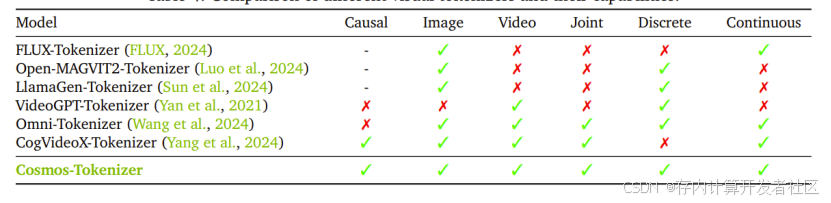
Tokenizer
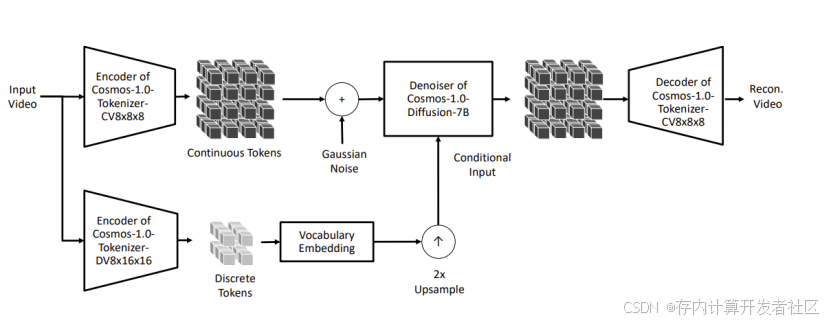
在 Cosmos 中,Tokenizer 是现代大规模模型的关键构建模块,其核心作用是将原始的视觉数据(如图像和视频)转换为更高效的表示形式,输入视频,经过编码的视频数据为encoder token,通过cosmos模型,解码成decoder token,重新生成视频,以便模型能够更好地处理和学习。
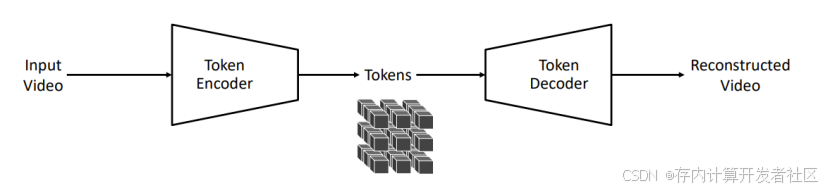
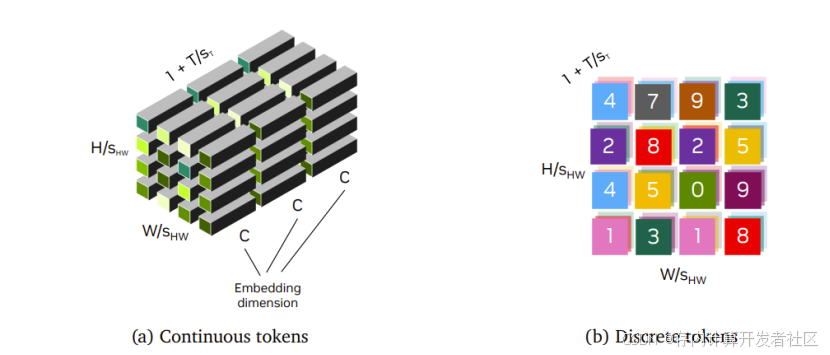
它通过在无监督的方式下学习到的瓶颈潜在空间,将冗余的视觉数据压缩为紧凑的语义令牌。具体而言,Cosmos Tokenizer 包含连续和离散两种类型,
连续 Tokenizer 如在潜在扩散模型(如 Stable Diffusion、VideoLDM 等)中使用,将视觉数据编码为连续的潜在嵌入,适合基于连续分布采样生成数据的模型;
离散 Tokenizer 则常见于自回归变压器模型(如 VideoPoet 等),把视觉数据编码为离散的潜在代码,映射为量化索引,便于与基于交叉熵损失训练的模型(如 GPT 等)集成。
联合训练图像和视频,交替使用不同批次,分两阶段训练,先优化 L1 和感知损失,再用光学流和 Gram - matrix 损失及对抗损失增强效果,依不同压缩率训练多种模型。
性能评估:在多个基准数据集评估,相比其他 tokenizer,在时空压缩比和重建质量上表现优异,运行速度更快且模型更小,在图像和视频处理上均有优势
预训练模型:
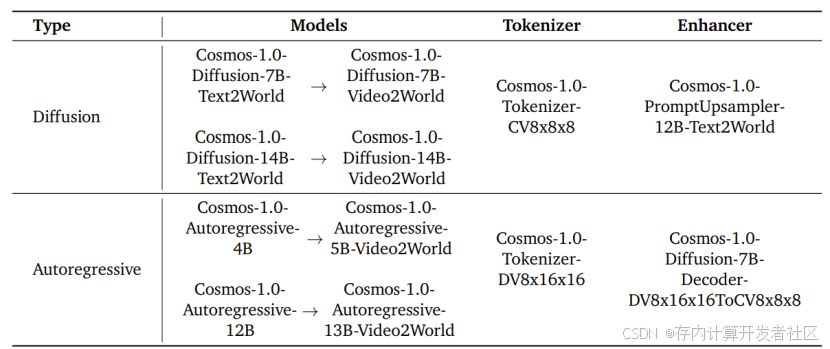
扩散模型:基于潜在扩散模型,用特定 tokenizer 处理视频,采用 EDM 训练方法及独特架构,含 3D 补丁化、混合位置嵌入等,通过联合训练等策略优化,利用并行技术高效训练,还有 prompt upsampler 提升输入质量,生成视频质量高。
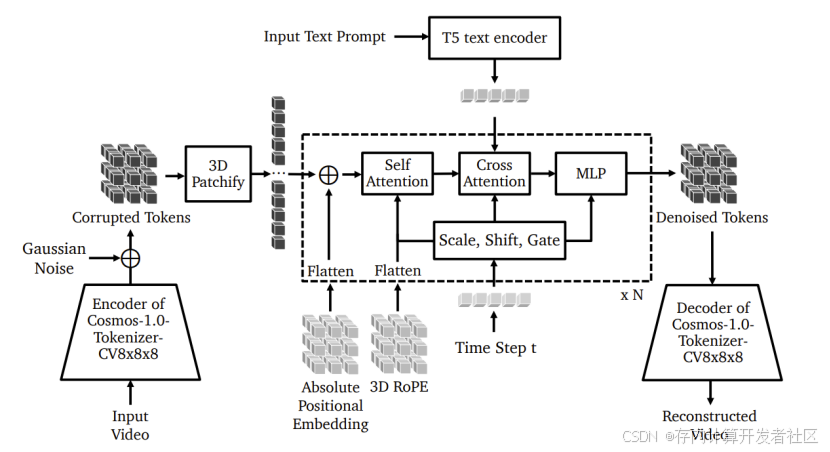
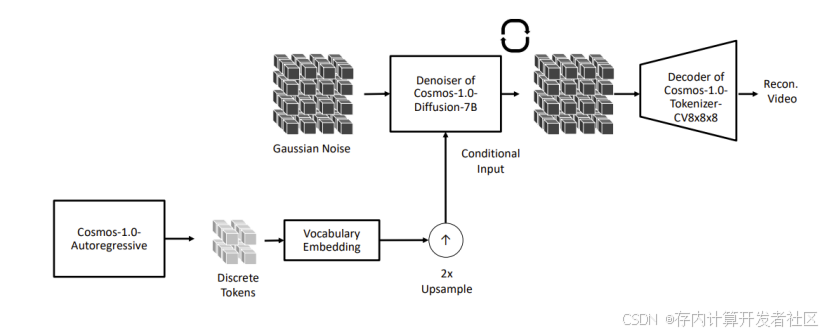
自回归模型:将视频转换为离散 tokens 后用 Transformer 解码器训练,架构上有 3D 位置嵌入等改进,训练分阶段进行并引入稳定项,采用并行技术和多种优化方法提升性能,虽有局限但在部分场景有潜力。
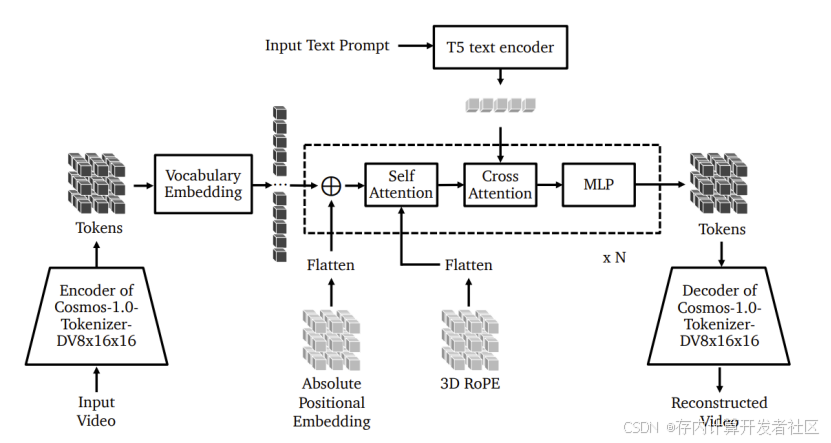
在模型训练方面,两种模型都基于大规模的视频数据进行训练,但采用了不同的训练策略和目标。扩散模型采用如 EDM(Elucidated Diffusion Model)的训练方法,将视频生成问题分解为一系列的去噪问题。通过在不同噪声水平下对模型进行训练,使其学习从噪声视频到真实视频的转换过程,在训练过程中会对视频进行 tokenization 操作,如使用 Cosmos - 1.0 - Tokenizer - CV8x8x8 将视频转换为连续的潜在表示,以降低计算成本并简化任务。
而自回归模型则类似于语言建模,将视频转换为离散的视频 tokens(如使用 Cosmos - 1.0 - Tokenizer - DV8x16x16),然后训练 Transformer 解码器基于过去的视频 tokens 预测下一个视频 token,通过最小化负对数似然损失来优化模型。
在模型结构上,两者也有各自的特点和改进措施,但也存在一些相互关联和补充的地方。扩散模型的 denoiser 网络在处理视频时采用了 3D patchification 过程对输入进行预处理,并利用混合位置嵌入(如 3D 因子化 Rotary Position Embedding 和可学习的嵌入)来适应不同的视频尺寸和帧率,同时通过 cross - attention 层来整合文本信息,实现对视频生成的条件控制。自回归模型则通过添加 3D - aware 位置嵌入(包括 3D 因子化 Rotary Position Embedding 和 3D 因子化绝对位置嵌入)来捕捉视频的时空信息,同样利用 cross - attention 来结合文本输入,并且引入了 Query - Key Normalization 和 z - loss 等机制来提高训练的稳定性。
在机器人操作和自动驾驶等应用的后训练中,会根据具体任务对两种模型进行针对性的微调。如在机器人操作的指令 - 视频预测任务中,对扩散模型(Cosmos - 1.0 - Diffusion - 7B - Video2World)和自回归模型(Cosmos - 1.0 - Autoregressive - 5B - Video2World)都进行了基于特定数据集的微调,使其能够更好地适应任务需求,通过在模型中添加相应的模块(如在自回归模型中添加动作嵌入 MLP 来处理动作向量输入)来整合不同模态的信息,实现两种模型在实际应用中的有效结合。

后训练应用:
针对COSMOS平台训练的应用,展示以下案例:
- ·相机控制:在特定数据集上对扩散模型微调,添加相机控制条件,训练和评估表明模型能生成高质量 3D 世界视频,相机控制性能好。

- 机器人操作:针对指令和动作任务分别构建数据集,微调扩散和自回归模型,在不同评估指标上均优于基线模型,有效提升机器人操作任务性能。

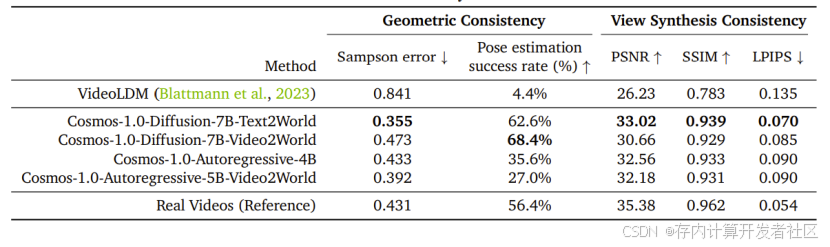
- 自动驾驶:用内部数据集对扩散模型微调,改进架构实现多视图生成,在视频质量、一致性和轨迹跟踪等评估中表现出色,能准确生成驾驶场景视频。

总结:
Cosmos 世界模型构建了通用的物理世界模拟器框架,其预训练的世界基础模型通过学习大规模视频数据中的物理规律和自然行为,能为物理 AI 系统提供一个可参考的世界模型,减少在真实环境中大量数据收集和训练的成本与风险,使物理 AI 系统在虚拟环境中进行有效训练和测试,加速开发进程。
在不同物理 AI 应用场景下表现出良好适应性。在机器人操作任务中,通过对预训练模型的微调,能根据指令或动作向量准确预测机器人操作的视频结果,提升机器人在复杂任务中的规划和执行能力;在自动驾驶领域,可生成多视图、高分辨率且符合物理规律的驾驶场景视频,为自动驾驶车辆的训练提供丰富多样的模拟环境,增强其应对不同路况和场景的能力。
拥有完善的数据处理流程和高效的 tokenizer。数据处理流程能筛选和准备高质量、多样化的视频数据,tokenizer 则可将视频数据压缩为适合模型学习的紧凑表示形式,减少计算资源消耗,提高模型训练和推理效率,使物理 AI 系统能够更好地利用大规模视觉数据进行学习和决策。
尽管在一定程度上学习到了物理规律,但生成的视频仍存在物理一致性问题,如物体持久性错误、接触丰富场景下的动力学不准确以及对物理原理(如重力、光线交互和流体动力学)的遵循不够精确等,这些问题限制了其在对物理精度要求较高的任务中的应用效果。自回归模型和扩散模型虽各有优势,但都存在一定局限性。在物理AI的发展上,由英伟达率领往前走了一大步。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









