






2024年10月21日,智源研究院发布原生多模态世界模型Emu3,该模型将图像、文本和视频等不同模态数据转化为离散空间中的token来进行预测,开创跨语言多模态世界模型的全新构建方式。
- 智源Emu3发布,验证多模态模型新范式
在自然语言处理领域,大语言模型(LLM)基于“Next-Token Prediction”的简单目标取得了不错的成果。尽管“Next-Token Prediction”的建模范式被认为是通向通用人工智能(AGI)的一条富有前景的路径,但这种范式在多模态任务中仍然没有被充分证明。这些多模态生成和理解任务仍然由扩散模型(例如 Stable Diffusion)和组合式的方法(例如 CLIP 与LLMs结合的多模态理解)所主导。其中,以Stable Diffusion为代表的扩散模型通过像素级去噪实现图像生成,而CLIP+LLM的拼接式架构则将视觉编码结果强行“翻译”为离散token输入语言模型。这两种主流方案均未真正实现模态间的统一表征与端到端训练,导致生成结果常出现语义断裂、可控性不足等问题。因此,多模态模型新范式亟需研究。
北京智源人工智能研究院(简称:智源研究院,Beijing Academy of Artificial Intelligence,BAAI)是人工智能领域的新型研发机构,于2018年11月14日,在科技部和北京市共同支持下,联合北京人工智能领域优势单位成立。为解决多模态模型范式问题,智源研究院自2023年起相继推出Emu系列模型。2023年7月,智源研究院“悟道・视界”研究团队提出了一种新的多模态大模型训练范式,发布并开源了首个打通从多模态输入到多模态输出的“全能高手”,统一多模态预训练模型Emu。
- 初代Emu1模型创造性地建立了统一的多模态预训练框架,即将图文对、图文交错文档、视频、视频文本对等海量形式各异的多模态数据统一成图文交错序列的格式,并在统一的学习目标下进行训练,即预测序列中的下一个元素。
- 2023年12月21日,Emu2通过大规模自回归生成式多模态预训练显著推动了多模态上下文学习能力的突破。
- 2024年10月21日,Emu3被提出,这是一套全新的最先进的多模态模型。它仅使用“Next-Token Prediction”这一建模范式进行训练。通过将视频、图像、文本编码到离散空间,可以实现从头开始训练一个单一的 Transformer 模型以处理多模态序列的混合数据。
Emu3的突破性在于将“Next-Token Prediction”原则贯彻到多模态场景。其核心架构将图像、文本、视频等模态数据统一离散化为token序列,通过自回归预测实现跨模态理解与生成的端到端训练。这意味着在模型内部,无论是解析一张图片的语义,还是根据文本描述生成视频片段,本质上都是在连续的token空间中进行概率建模。这种设计不仅继承了大语言模型的训练效率优势,更重要的是建立了跨模态信息的无损流通通道——实现了“Next-Token Prediction is All You Need”。
图1 Emu3官网
- Emu3基于下一个token预测,无需扩散模型或组合方法
根据官方发布在arxiv文章(测试报告)和官方介绍,Emu3在多种场景下较传统的基于扩散模型或组合方法的算法有更好的性能。
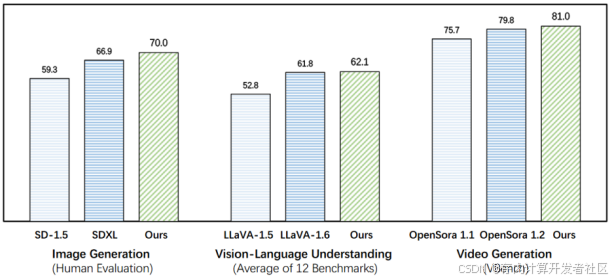
图2 三项主流Token预测类任务中的表现
上图是对Emu3在三项主流Token预测类任务中表现的概览:在图像生成任务中, Emu3在基于人类偏好的评估结果中表现比SD-1.5和SDXL明显更好;在视觉语言理解任务中,Emu3在12项测试中的平均表现更比LLaVA-1.5和LLaVA-1.6更好;在视频生成任务中,Emu3在VBench中的表现好于OpenSora1.1和OpenSora1.2。
表1 文本转图像测试
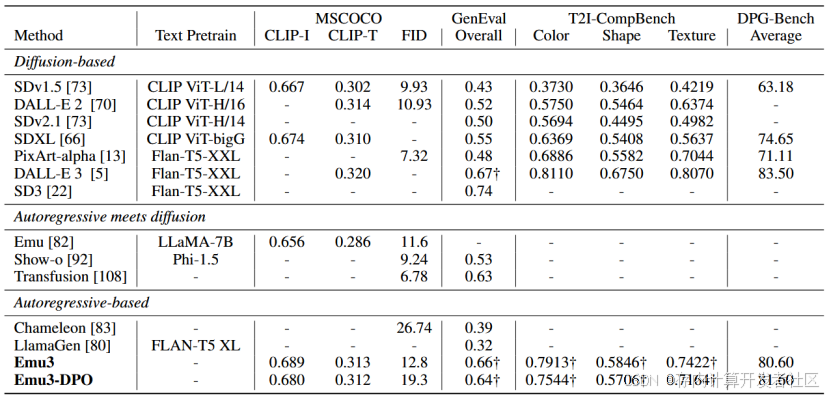
具体来说,作者在MSCOCO-30K、GenEval、T2I-CompBench和DPG-Bench等流行的文本转图像地测试中进行了评估,四个评测基准分别针对不同的文本生成图像任务的能力,MSCOCO数据集主要用于图像描述和文本到图像生成任务的通用的评估,GenEval提供了一个多维度、多任务的NLG评估框架,强调全面性和细粒度,T2I-CompBench专门用于评估文本到图像生成模型在组合性方面的能力,DPG-Bench专注于评估文本生成模型在生成多样化释义方面的能力,评测结果如上表所示。作者指出,由于Emu3在训练过程中使用了相当比例的合成标签,因此相比于较短的提示词,它在较长的提示词中表现出更优异的性能。而GenEval和T2I-CompBench中的提示词过于简略,无法准确反映模型的真实表现。在引入DPO后,Emu3的评估结果略有下降,作者推测这可能是由于所用数据集中的整体偏好与评估基准不一致。
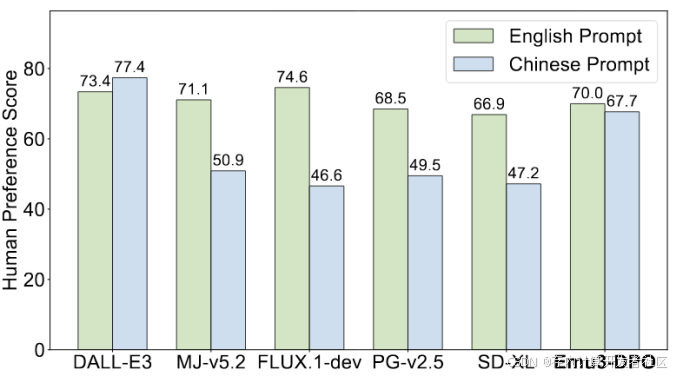
图3 中英文文本生成图像
进一步地,文章作者在中文和英文两种提示词下对Emu3和其他模型的表现进行了人工评估,相较于其他模型,它在中文提示词下的表现明显更优,整体而言可以达到DALL-E3的水平。直接偏好优化,简称DPO,是一种使模型输出与人类偏好对齐的有效方法。Emu3采用自回归模型和统一的Token预测框架,回归模型这种逐个Token生成的方式与DPO的训练目标契合,并且由于采用统一的Token预测,使得DPO可以应用于各个模态。
总之,在没有使用任何预训练语言模型的情况下,Emu3在文本生成图像领域的表现超越大多数基于扩散模型的其他方法,与DALL-E3在同一水平。
表2 评估模型的视频生成能力
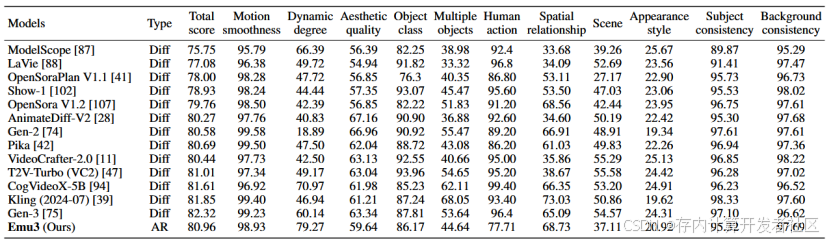
作者还评估了Emu3模型的视频生成能力。Emu3原生支持5s的24帧视频生成,并且可以通过自回归的方法无限扩展。作者在VBench中进行了评估,这是一个用于全面评估多模态大语言模型在视频理解方面能力的基准。它旨在解决现有视频理解基准的局限性,提供一个更全面、更细粒度、更可靠的评估体系。除了Emu3是自回归模型外,其他公开可比的方法都是扩散模型,尽管如此,Emu3的表现仍具有很强的竞争力。虽然它不及最先进的如Kling和Gen-3的模型,但由于大多数同类开源模型。
表3 视觉-语言基准评估
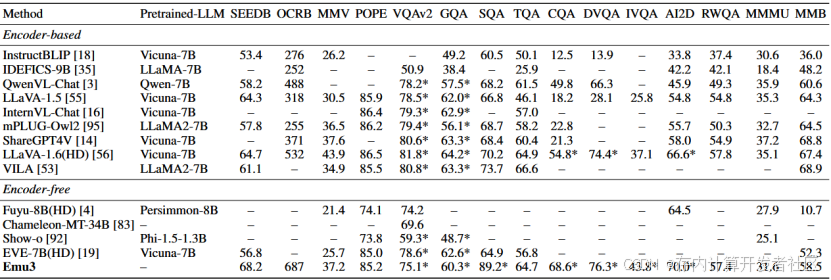
作者最后对Emu3在视觉-语言基准中进行了评估,测试其处理多模态信息和帧预测的能力。作者分别对使用预训练的CLIP视觉编码器的方法和不适用预训练编码器的方法两种情况进行了测试(CLIP是一种具有强大图像特征提取能力的模型,可以提升各种视觉-语言任务的性能)。Emu3作为一种无视觉编码器、不依赖专门预训练的LLM和CLIP实现的方法,在各个方法的测试中表现出优异的成绩,展现出Emu3在多模态理解中强大的能力。
综上所述,Emu3基于自回归的Token预测方法在文-图生成、文-视频生成、帧预测中表现出强大的竞争力。
三、多模态任务表现亮眼,引发海内外研究者热议
基于Emu3提供的强大Vision Tokenizer,Emu3可以将视频、图像转换为离散的token,和文本一起输入模型中。同时基于对于下一个token的预测,Emu3在图像生成、视频生成、视频预测和多模态理解等多模态任务中表现亮眼。
- 图像生成
Emu3通过预测下一个视觉token来生成高质量图像,模型也可以自然支持灵活的分辨率和不同风格。

图4 Emu3图像生成部分示例
- 视频生成
和使用视频扩散模型以从噪声中生成视频的Sora等模型不同,Emu3只通过预测序列中的下一个token来因果性的生成视频。

图5 Emu3视频生成部分示例
- 视频预测
在视频的上下文中,Emu3可以自然地扩展视频并预测接下来会发生什么。模型可以模拟物理世界中环境、人和动物。

图6 Emu3视频预测部分示例
- 视频-语言理解
Emu3 展现了强大的感知能力,能够理解物理世界并提供连贯的文本回复。值得注意的是,这种能力是在不依赖于LLM和CLIP的情况下实现的。

图7 Emu3视频-语言理解部分示例
Emu3一经发布便在国内外社交媒体上引起热议,SOTA、all you need等评论层出不穷。
图8 Emu3引发网友热议
有网友指出:“这是几个月以来最重要的研究,我们现在非常接近拥有一个处理所有数据模态的单一架构。”甚至有网友评价:“也许我们会得到一个真正开放的 OpenAI v2?”
图9 Emu3引发网友热议
此外,智源研究院已经开源了Emu3生成和理解一体的预训练模型以及相应的SFT训练代码,以便后续研究和社区构建与集成:
代码:https://github.com/baaivision/Emu3
项目页面:https://emu.baai.ac.cn/
模型:https://huggingface.co/collections/BAAI/emu3-66f4e64f70850ff358a2e60f
参考资料
[1] Wang, Xinlong, et al. "Emu3: Next-token prediction is all you need." arXiv preprint arXiv:2409.18869 (2024).


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









