






- 引言
深度学习等AI算法的快速发展,驱动了对算力需求的持续增长。尤其是在边缘计算领域,AI应用的普及对设备的算力提出了更高的要求。在资源受限的边缘设备中,高能效(EEF)成为衡量AI芯片性能的关键指标。不同的AI应用对计算精度的需求各不相同。高精度应用通常需要浮点(Floating-Point,FP)数据格式。而对于一些对精度要求较低的边缘推理应用,定点(Integer,INT)数据格式则可以提供更高的能效。
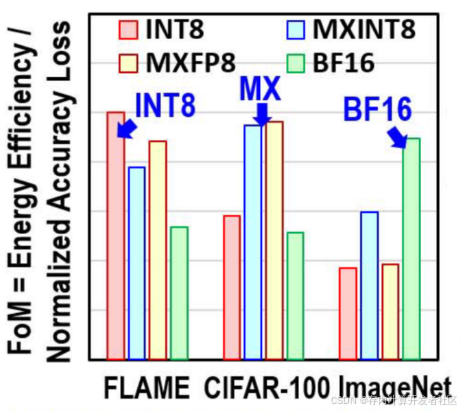
图1 CIFAR-100在不同精度的例化效果
为了进一步平衡能效和精度,混合精度(Mixed-Precision,MX)数据格式应运而生。MX数据格式通过共享比例因子(Shared-ScaleFactor,SS)等技术,在低位宽数据表示下,实现接近浮点精度的动态范围。未来的AI芯片需要能够灵活支持INT、FP和MX等多种数据格式,以适应不同应用场景的需求。
浮点计算内存一体化(FP-CIM)方案能够克服INT-CIM的精度限制,支持高精度的浮点运算,满足对精度要求较高的AI应用需求。然而FP-CIM的能效相对较低,且需要更高的位宽和复杂的硬件电路(如归一化单元),导致硬件开销和功耗显著增加,限制了其在资源受限场景中的应用。相比之下混合精度(MX)数据格式可以在低位宽下实现接近浮点精度的动态范围,从而在保证精度的同时提升能效。为了充分发挥MX数据格式的优势,可以开发针对MX数据格式优化的CIM架构和硬件电路以克服现有CIM方案在数据格式和能效方面的局限性,由此多模式计算内存一体化(MX-INT-FPCIM)架构应运而生。架构旨在融合INT-CIM的高能效、FP-CIM的高精度以及MX数据格式的平衡性,从而实现对多数据格式的灵活支持。
- 当下问题
传统的CIM架构在处理MX数据格式时存在明显的不足。具体来说,对于MX数据格式,通常需要在CIM宏之外进行浮点到MX格式的转换(FP→MX转换)以及共享比例因子(Shared-Scale,SS)处理。FP→MX转换是当输入数据或权重以浮点格式存储时,为了利用MX格式的能效优势,需要首先将浮点数据转换为MX格式。这一转换过程通常需要在CIM外部的数字信号处理单元(DSP)或CPU上完成。MX格式的核心在于共享比例因子。比例因子的计算、存储和应用,以及后续的反比例缩放等操作及SS处理,在传统设计中也往往需要在CIM外部的计算单元中进行。
为了进行FP→MX转换和SS处理,需要将大量数据从内存传输到外部计算单元,处理完成后再将数据传输回内存或CIM。频繁的数据传输显著增加了系统总线的负载,且外部计算单元(如DSP或CPU)需要额外的硬件资源来执行FP→MX转换和SS处理。大量的外部数据传输,加上外部计算单元的功耗,都会降低整体系统的能效,还增加了系统芯片的面积。另一方面,在神经网络的实际应用中,ADT(AdderTree,ADT)的输入数据往往不是完全随机的,而是存在一定的统计特性。传统的ADT设计并没有针对AI高频输入模式进行优化,这就导致了在处理高频输入模式时,传统ADT存在不必要的能耗和面积开销。例如,对于输入模式0/0/0或0/1/0,很多全加器内部的晶体管可能并不需要进行翻转或切换。
在典型的卷积神经网络(CNN)等深度学习模型中,不同层的通道数(NCH)是由神经网络模型本身的结构特点决定的,旨在提取不同层次的特征信息。常见的加速器往往采用内存写入路径或ALU缓冲写入路径,为了处理所有的NCH,需要将计算任务分割成多个切片(slices),每个切片处理一部分NCH。对于每个切片,都需要从系统外部的权重缓冲器(Wbuffer)中重复获取权重数据。这种重复的数据传输增加了能耗和延迟。为了适应神经网络层通道数的多样性,需要采用更加灵活的数据写入机制,根据NCH的大小动态选择最优的写入路径(内存写入或ALU缓冲写入)。
- 创新点
- 多模式输入处理单元(M2-IPU)
M2-IPU将SS处理和FP2MX处理集成至了CIM单元的内部,以减少大量的在CIM单元之外的数据移动。如图2上所示,M2-IPU主要包括一个最大查找器 (MAX-FD)、一个乘积(PD)SS方差检测器 (PD-VD)、一个混合对齐数生成器 (HAL-GEN)、SS 控制器(CTRL)和 IN-mantissa(INM)处理单元(INM-PU)。
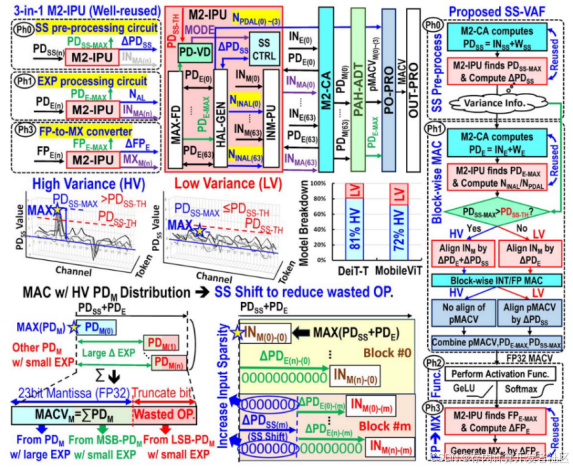
图2 M2-IPU和SS-VAF工作流

2.模式感知混合加法树(PAH-ADT)
PAH-ADT混合使用11T、14T、15T和28T全加器,在面积、延迟、能效和功效之间实现了较好的权衡。
在神经网络模型里,高数位的全加器(如处理高位数据的 FA)会频繁遇到特定输入模式,例如0/0/0和0/1/0。传统的14T和28T全加器为保证对所有输入模式都能输出标准结果,包含了冗余晶体管。然而,对于高概率出现的高数位输入模式,这些冗余晶体管增加了功耗和芯片面积。如图3所示,为优化这种情况,论文提出的模式感知11T和15T全加器,去除了这些冗余晶体管,从而减少了全加器的面积,并针对高概率输入模式优化了能耗。
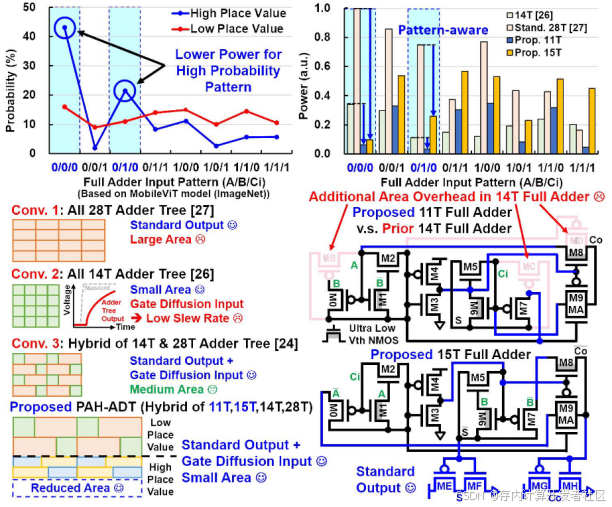
图3 PAH-ADT结构

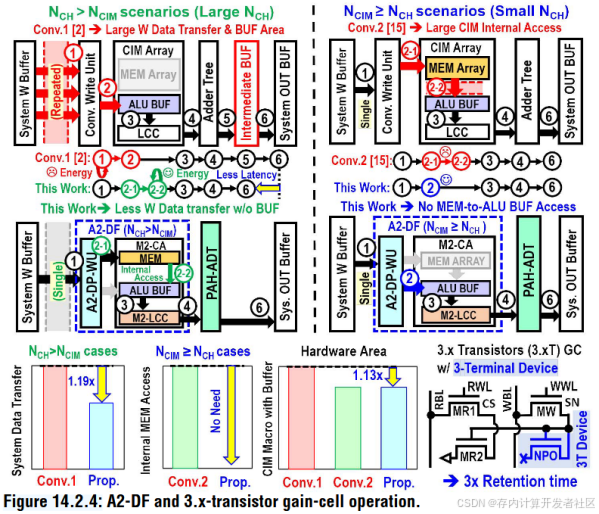
图4 A2-DF和3.xT
此外,文中提出改进存储节点设计,引入N-PODE三端器件,提升数据保留时间3×,无额外面积开销,增强了CIM的整体性能和可靠性。
- 实验数据
论文里的CIM基于16nm FinFET工艺打造了216kb宏单元。从图5芯片性能总结表能看出,它支持MXINT8、BF16和INT8输入格式,输出FP32格式数据。MXINT8的输入通道数是128,BF16为64,输出通道数都是24。工作电压范围在0.4 - 0.8V,这是综合考虑硬件性能和能耗后确定的,对CIM性能优化很关键。
在能效和性能方面,图5数据显示,MXINT8模式下,峰值能效达到133.5TFLOPS/W,平均能效为93.11TFLOPS/W;BF16模式的峰值能效是91.9TFLOPS/W,平均能效为63.14TFLOPS/W。MX模式在0.8V时,面积效率为11.4TFLOPS/mm²,与其他设计对比,凸显出它在有限芯片面积下能高效计算的优势。
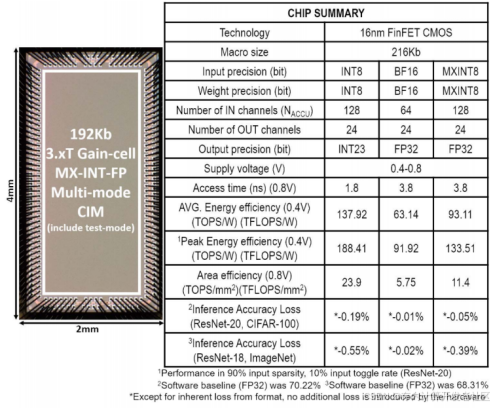
图5 芯片照片和性能汇总表
和现有CIM相比,从图6可知,借助M2 - IPU和A2 - DF等架构,该设计的数据传输量减少72 - 85%。在EEF - AEF综合指标上,比现有CIM提升1.4 - 2.7 倍。在推理精度损失方面,MXINT8模式用于CIFAR - 100数据集和ResNet - 20 模型时,精度损失为0.05%;BF16 模式用于ImageNet数据集和ResNet - 18模型时,精度损失为0.02%,能在高效计算的同时保证精度。
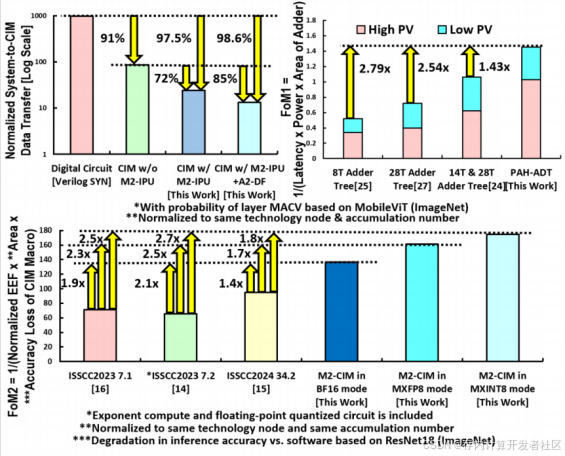
图6 所提方案的模拟性能
Shmoo图7验证了设计的稳定性和高效性。0.8V电压下,MX - MAC和FP - MAC的计算延迟均为3.8ns;电压降到0.7V时,延迟变为4.0ns;降至0.6V时,延迟为4.1ns。从延迟随电压变化曲线可知,0.8V工作电压下该设计运行稳定高效,为实际应用提供了可靠保障。
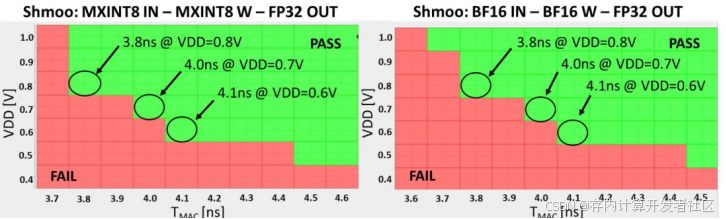
图7 测量结果
- 总结与改进
本研究的核心贡献在于成功设计并验证了一款首创的支持MX-INT-FP多模式CIM架构,显著提升了硬件的灵活性和能效。为实现这一目标,研究深入探索了软硬件协同优化的途径。
在架构层面,创新性地提出了多模式CIM架构,使其能够兼容MX、INT及FP多种数据格式,从而大幅扩展了CIM硬件的应用范围,并使其能够更好地适应多样化的人工智能工作负载需求。
在软硬件协同优化方面,研究团队提出了SS-VAF技术,通过在CIM内部实现FP2MX和SS处理,并结合方差信息提升输入尾数的稀疏性,有效降低了数据传输开销和计算能耗,克服了传统CIM设计中系统到CIM数据传输的瓶颈难题;同时,创新设计的PAH-ADT混合加法器树结构,针对高概率输入模式优化了ADT的面积和能耗,显著提升了ADT的效率和能效;此外,A2-DF累加感知数据流技术的提出,实现了动态可重配置的数据写入路径和计算流,增强了写入路径的灵活性,并能根据工作负载动态调整数据流,进一步降低了数据传输能耗。
实验结果清晰地证实,所提出的架构在能效、面积效率以及推理精度等多项关键指标上,均表现出显著优于现有CIM解决方案的性能,充分验证了本研究设计方法的有效性。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









