






论文《Membership Inference Attacks Against Retrieval Augmented Generation》研究了检索增强生成(Retrieval Augmented Generation, RAG)系统中,成员推测攻击的威胁。RAG系统结合了信息检索和语言生成技术,广泛用于提供高质量的文本生成服务。然而,随着RAG系统对外部检索数据库的依赖,其隐私安全风险日益凸显。MIA是一种常见的隐私攻击,通过观察系统输出推测某些数据是否存在于模型训练集或检索数据库中,从而泄露敏感信息。
攻击流程图:
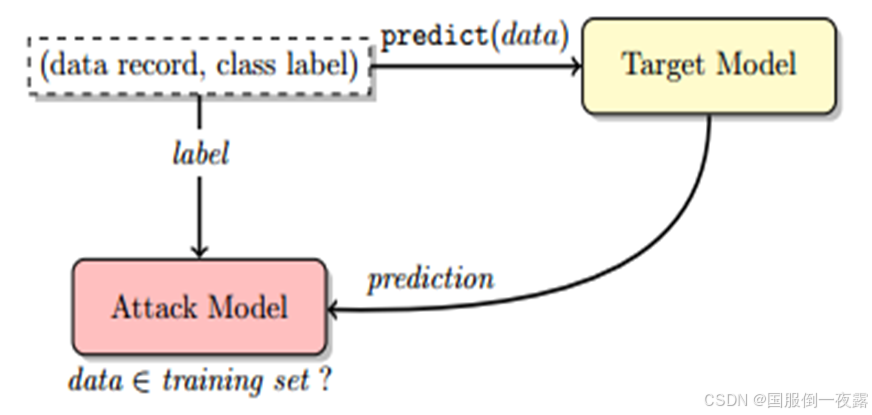
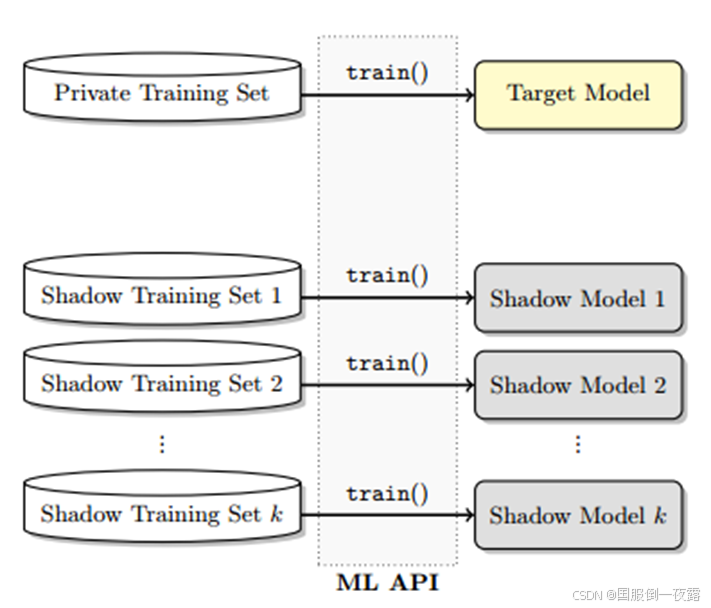
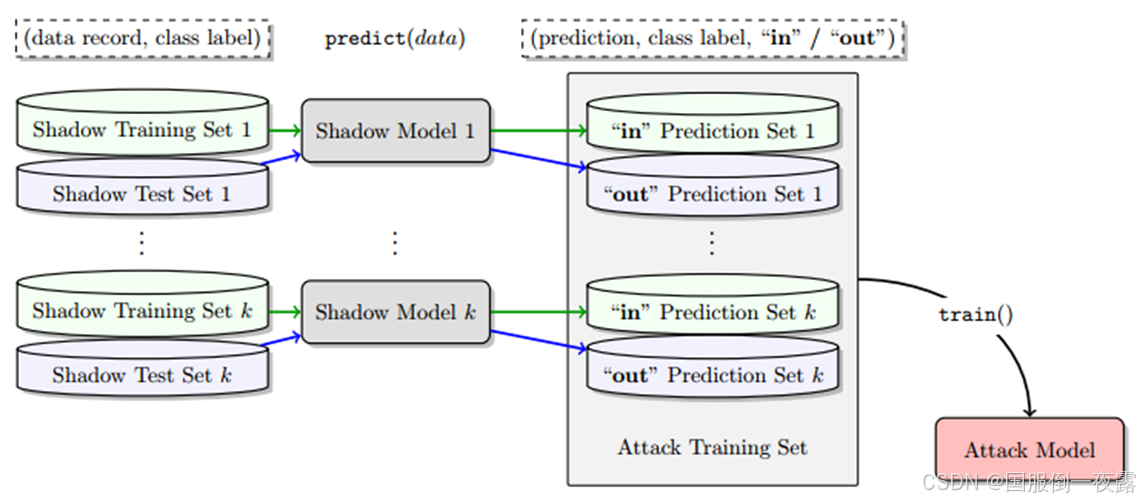
论文背景和问题:
- RAG系统概述:RAG通过检索外部文档数据库生成与用户查询相关的上下文,结合大语言模型(LLM)生成准确的答案。该技术在NLP中得到了广泛应用,尤其是用于动态知识查询的场景。
- 隐私威胁:攻击者可以利用系统输出,推测某个文本是否存在于RAG系统的检索数据库中,进而窃取数据库中的敏感信息或确认其包含某些特定数据。这种攻击不仅威胁个人隐私,还可能导致企业机密泄露。
- 研究目标:本文提出了一种高效的成员推测攻击方法,专门针对RAG系统,评估该攻击在不同场景下的威胁,提出了初步防御措施并讨论其有效性。
方法与实验:
论文通过黑盒和灰盒攻击场景对RAG系统的MIA进行了详细的分析。黑盒场景下,攻击者仅能访问用户输入和生成输出;灰盒场景下,攻击者还能获得生成模型的概率分布。实验中,作者使用了医疗Q&A数据集和Enron电子邮件数据集,并采用多种生成模型(如Flan、Llama、Mistral)进行攻击测试。通过定制攻击提示,攻击者能够成功推测某些文档是否存在于数据库中。
主要发现:
- 高效攻击策略:即使在黑盒场景下,攻击成功率也较高。特别是Flan模型在灰盒场景下几乎能完全推测文档是否存在。
- 初步防御措施:论文提出了一种基于模板修改的防御策略,要求RAG系统忽略对数据库内容的直接询问。这种防御措施在灰盒场景下对某些模型(如Llama、Mistral)较为有效,但对Flan模型效果有限。
重点
- RAG系统中的隐私威胁:论文重点讨论了RAG系统中,检索数据库暴露给外部用户后可能引发的隐私泄露问题。通过成员推测攻击,攻击者可以推断出特定数据是否存在于数据库中,从而造成敏感信息泄露。
- 黑盒与灰盒攻击对比:本文在黑盒和灰盒场景下分别进行了攻击测试,表明即使在攻击者无法直接访问系统内部信息的情况下,仍然可以通过巧妙设计的提示成功发起成员推测攻击。
- 防御措施的初步探索:虽然成员推测攻击对RAG系统构成了实质性威胁,作者也提出了一个初步的防御策略,即通过修改RAG模板来限制系统对数据库存在性问题的响应。然而,该防御机制在不同模型中的效果差异较大。
难点
- 复杂的攻击设计:为了发起有效的MIA,攻击者需要设计能够引发系统检索并明确返回文档存在性的攻击提示。黑盒攻击特别困难,因为攻击者无法直接访问系统的内部信息,需依赖系统生成的输出进行推测。
- 多样化的数据与模型:不同的数据集和生成模型对成员推测攻击的抗性各不相同。如何设计通用的攻击策略,能在多种场景和不同RAG系统中保持较高的攻击成功率,是一个技术难点。
- 防御的全面性:当前提出的防御策略对部分模型有效,但不能完全防御所有攻击,特别是在Flan模型上的防御效果有限。开发出既能有效阻挡攻击,又不会显著影响系统性能的防御机制,仍然具有挑战性。
聚焦点
- 数据隐私:随着RAG系统的广泛应用,论文聚焦于通过MIA对检索数据库隐私进行攻击的威胁。文中强调,MIA不仅可能用于个人隐私数据的推测,还可能对企业机密文件构成威胁。
- RAG系统的脆弱性:论文通过多个实验展示了RAG系统在处理外部数据库时的脆弱性。由于RAG系统依赖于外部数据的检索和生成,其隐私保护机制显得薄弱,容易受到成员推测攻击的威胁。
- 防御策略的有效性:尽管初步的防御措施对部分生成模型具有一定效果,论文聚焦于如何改进防御机制,以更好地应对不同场景下的MIA攻击。
前沿技术
- 检索增强生成技术(RAG):RAG系统通过外部数据源的实时检索来增强LLM的知识和生成能力,已成为现代NLP系统的重要组成部分。然而,这一技术的安全性问题尚未得到充分研究。
- 成员推测攻击(MIA):MIA是一种隐私攻击,利用系统输出推测训练数据或数据库中的文档是否存在。论文展示了如何在RAG系统中实施MIA,并提出了一些有效的攻击策略。
- 生成模型的安全性测试:通过黑盒和灰盒场景的测试,作者展示了多种生成模型(如Flan、Llama、Mistral)在不同场景下的抗攻击性能,为未来生成模型的安全性研究提供了实验依据。
当前存在的不足
- 防御机制不够健全:尽管论文提出了初步的防御策略,但其对所有生成模型的防御效果有限,尤其在Flan模型上效果不佳。未来需要开发更全面的防御机制,确保系统在不牺牲功能性的前提下提升安全性。
- 攻击场景的局限性:论文主要在两个数据集上测试了攻击策略,虽然得到了较好的实验结果,但在更多的实际场景中,RAG系统的表现和抗攻击能力仍需进一步验证。
- 攻击复杂性较高:虽然论文设计了多种有效的攻击提示,但对于普通攻击者而言,实施这些攻击可能需要较高的技术门槛。如何简化攻击流程并验证其在更多应用场景中的有效性,是未来需要解决的问题。
相关研究论文
1.
"Membership Inference Attacks against Machine Learning Models"
(2017)
:这篇论文首次提出了成员推测攻击的概念,并展示了如何针对不同的机器学习模型进行攻击。
2.
"Is My Data in Your Retrieval Database? Membership Inference Attacks Against Retrieval Augmented Generation"
(2024)
:专注于
RAG
系统,提出了一种新的
MIA
方法,并通过实验验证了攻击的有效性。
3.
"Machine Against the RAG: Jamming Retrieval-Augmented Generation with Blocker Documents"
(2024)
:研究了针对检索增强生成(
RAG
)系统的
MIA
,探讨了如何通过操纵检索数据库来影响模型输出。
4.
"Do Membership Inference Attacks Work on Large Language Models?"
(2024)
:探讨了
MIA
在大型语言模型中的可行性,并提出了一些防御策略。
5.
"Certifiably Robust RAG against Retrieval Corruption"
(2024)
:提出了一种防御
MIA
的方法,通过认证的鲁棒性来保护
RAG
系统免受检索腐败的影响。
攻击示例

防御模板

总结
这篇论文探讨了RAG系统中成员推测攻击的威胁,展示了攻击者如何通过巧妙设计的提示推测特定文档是否存在于检索数据库中。尽管论文提出了初步的防御机制,但其防御效果在不同模型中存在差异,未能提供全面的解决方案。未来的研究应继续探索更有效的防御机制,并在更多真实场景中验证攻击和防御策略的有效性。

















 410
410

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









