






《 谒金门·萧瑟霜》
情眷恋 古往今来相看 几度流光人更远 伤离方寸乱
回梦空传幽怨 依旧尘缘未断 碧落黄泉寻觅遍 愁来天不管
最近有个轻小说改编动漫《在异世界迷宫开后宫》开播,看着还行,小说一般,流水账的感觉,而且目前国内暂时没有文库版的翻译,只有web版的个人翻译,不过对应的漫画画的很不错。
Note:这个是里番!






本文使用Python爬虫Requests和Selenium模块爬取这个漫画。
完整代码如下:
 https://github.com/tklk610/Python-Crawlies-for-369manhua
https://github.com/tklk610/Python-Crawlies-for-369manhua目录:
1.获取各话的url地址以及对用的标题(第几话);
2.得到每一话各个图片的url;
3.下载每张图片,并按第几话命名文件夹保存;
4.魔高一丈之反反扒
获取各话的url地址以及对用的标题(第几话)
漫画网页url:在异世界迷宫开后宫漫画免费阅读(下拉式)在线全集观看-369漫画网
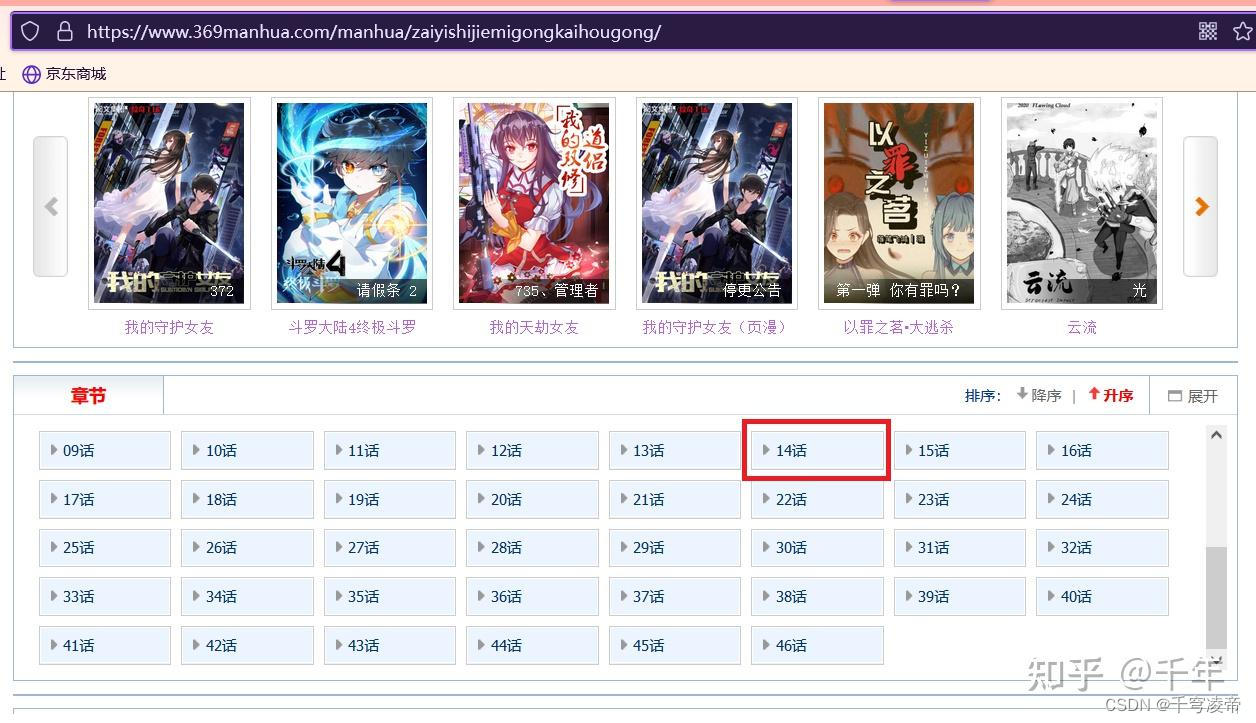
使用分析工具右键-检查或者F12,得到每一话的网页url和对应话数。
使用requests请求得到页面源码数据,使用xpath从中得到网页url和对应话数。
def get_page_path(url):
headers_path = {
"Accept" : "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8",
"Accept-Encoding" : "gzip, deflate, br",
"Accept-Language" : "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2",
"Connection" : "keep-alive",
# "Cookie" : "td_cookie=1374660017;ComicHistoryitem_zh=History=614,637984042562212870,101201,2,0,0,0,37&ViewType=0;MANGABZ_MACHINEKEY=deb97fc6-b460-45e1-b401-d74a6ac5931c;\
# _ga_1SQXP46N58=GS1.1.1662778212.1.1.1662779657.0.0.0;_ga=GA1.1.1637493032.1662778213;firsturl=http % 3A % 2F % 2/Fwww.mangabz.com%2Fm101201%2F;readhistory_time=1-614-101201-2;\
# image_time_cookie=109286|637984038221919904|0,40443|637984038335211502|0,40444|637984038452627191|0,101201| 637984042564044762 | 1;\
# mangabzimgpage=109286|1:1,40443|1:1,40444|1:1,101201|2:1;\
# mangabzcookieenabletest=1;mangabzimgcooke=109286%7C2%2C40443%7C2%2C40444%7C2%2C101201%7C6",
# "Host" : "www.mangabz.com",
# "Referer" : "http://www.mangabz.com/614bz/",
# "Upgrade-Insecure-Requests" : "1",
"User-Agent" : random.choice(user_agent)
}
response_path = requests.get(url, headers=headers_path) # 发送请求,获取响应
if response_path.status_code == 200:
print('Path Request success.')
response_path.encoding = 'utf-8' # 重新设置编码解决编码问题
html_path = etree.HTML(response_path.text)
# xpath定位提取想要的数据 得到图片链接和名称
# //从匹配选择的当前节点选择文档中的节点,而不考虑他们的位置
# @选取属性
# /是从根节点选取。
page_path = html_path.xpath('/html/body/div[5]/div[5]/div[2]/div[3]/ul/li/a/@href')
page_path = ['https://www.369manhua.com' + x for x in page_path]
page_name = html_path.xpath('/html/body/div[5]/div[5]/div[2]/div[3]/ul/li/a/text()')
print(page_path)
print(len(page_path))
print(page_name)
for page_index in range(0, len(page_path)) :
page_url = page_path[page_index]
image_name = page_name[page_index]
image_name = image_name.replace(' ', '')
get_page_url(page_url, image_name)
time.sleep(random.randint(5, 20))
print("下载了一画")2.得到每一话各个图片的url
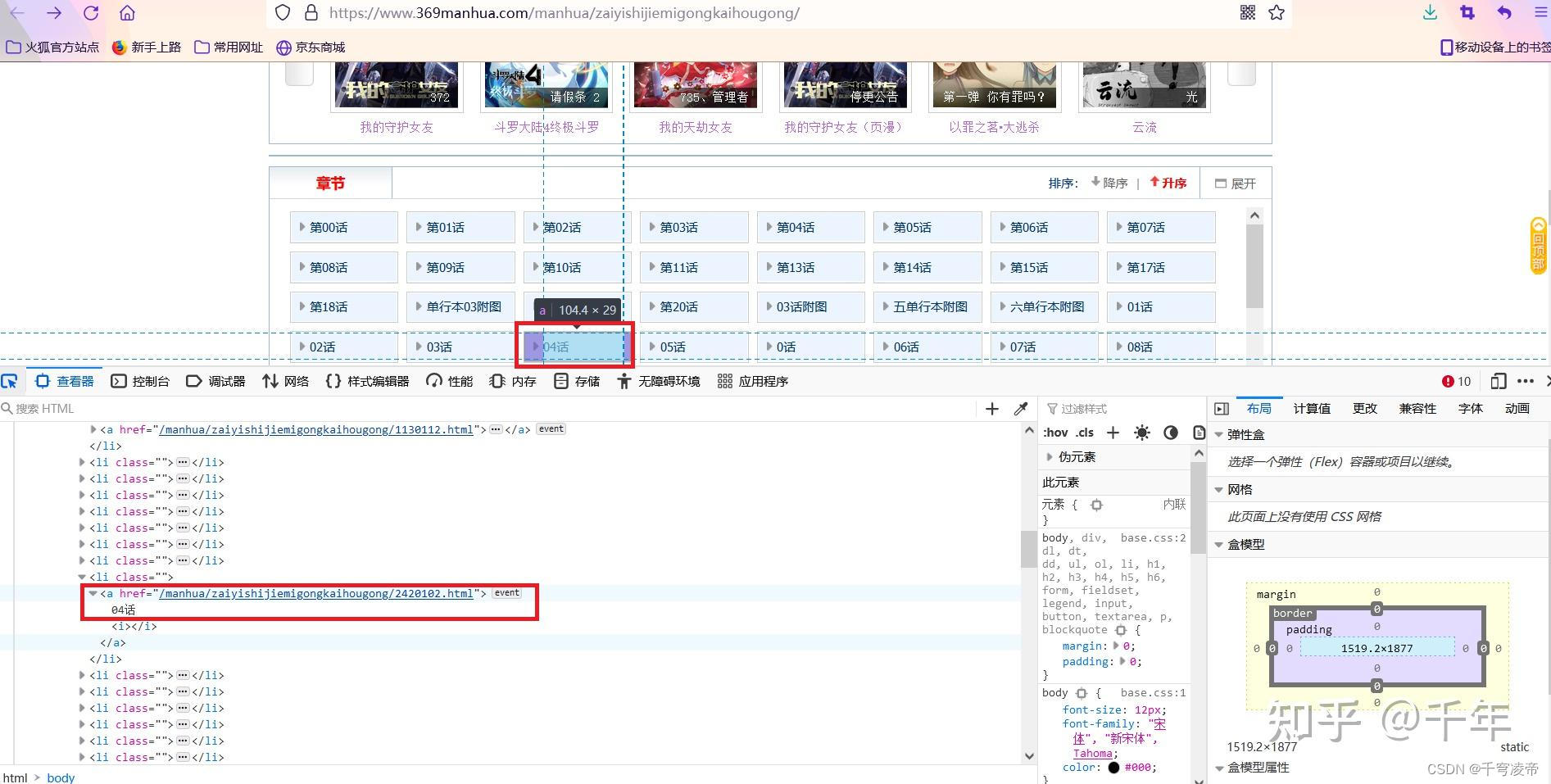
在以上每一话的页面中,使用分析工具右键-检查或者F12,得到每张图片的url。
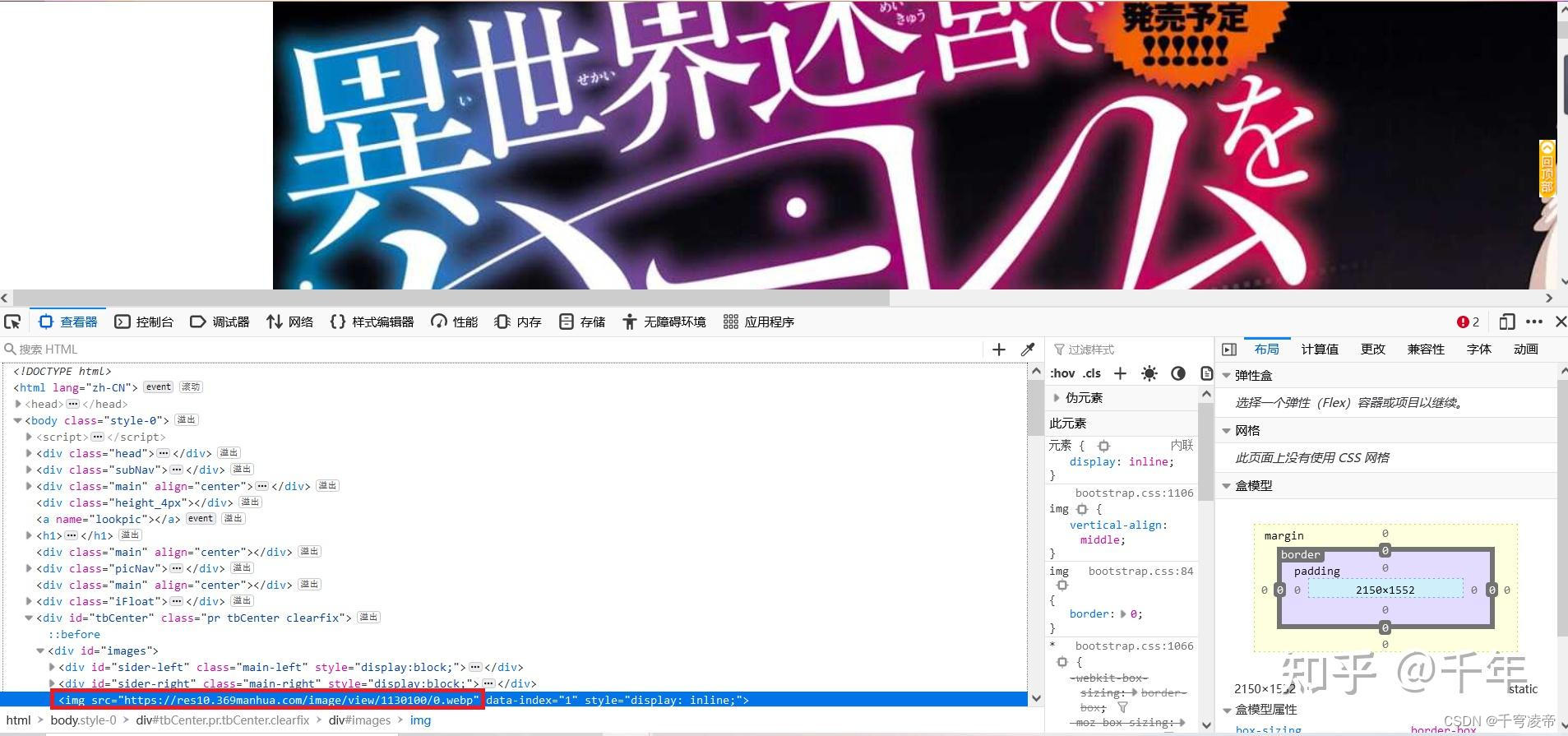
直接使用requests发起get请求,得到的源码数据经过了修改,需要进行处理,因此改用Selenium模块。
这个模块主要功能有两个:1.使用代码进行浏览器操作;2.自动处理AJAX请求;相当方便。
需要下载对应版本浏览器驱动程序,本文使用Chrome浏览器,需要下载一个chromedriver.exe文件;
headers_page = {
"Accept" : "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8",
"Accept-Encoding" : "gzip, deflate, br",
"Accept-Language" : "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2",
"Connection" : "keep-alive",
"User-Agent" : random.choice(user_agent)
}
save_path = save_dir + '/' + str(name)
if not os.path.exists(save_path):
os.makedirs(save_path)
bro = webdriver.Chrome(executable_path='./chromedriver', chrome_options=chrome_options, options=option)
bro.get(url)
response_img = bro.page_source
html_page = etree.HTML(response_img)
image_url = list(html_page.xpath('/html/body/div[9]/div[1]/img/@src'))
for page_num in range(0, len(image_url)) :
get_image(image_url[page_num], page_num, name, save_path)
time.sleep(random.randint(5, 20))
bro.quit()以下代码是将Chrome浏览器设置成无头浏览器,即运行爬虫程序时屏幕上不会开启浏览器页面,不然电脑屏幕上自动进行浏览器操作,大半夜还是怪吓人的。另外加一些Selenium反扒策略。
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
option = ChromeOptions()
option.add_experimental_option('excludeSwitches', ['enable-automation'])
3.下载每张图片
得到每一张图片的url后就可以使用requests直接下载了,由于这个网站的漫画很多webp格式的,所以需要处理一下。
try:
image_data = requests.get(url=url, headers=headers_image).content
except:
image_data = requests.get(url=url, headers=headers_image, verify=False).content
if str(url).endswith('.webp') :
byte_stream = BytesIO(image_data)
im = Image.open(byte_stream)
# im.show()
if im.mode == "RGBA":
im.load() # required for png.split()
background = Image.new("RGB", im.size, (255, 255, 255))
background.paste(im, mask=im.split()[3])
im.save(save_path + '/' + str(num+1) + '.png', 'PNG')
# with open(save_path + '/' + str(num+1), 'wb') as fp:
# fp.write(im)
else :
with open(save_path + '/' + str(num+1) + '.png', 'wb') as fp:
fp.write(image_data)4.魔高一丈之反反扒
1.headers,GET请求不能写全;
2.随机休息,时间可以长一点;
time.sleep(random.randint(5, 20))3.headers里随机更换浏览器;
![]()
4.使用代理IP;
推荐一下吴军博士的书,《数学之美》,《浪潮之巅》,技术工程人员值得一读!


















 721
721

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











