






写这篇文章,围绕以下几个问题来探讨:
- VQ-VAE为什么不能说是一个VAE,而更像一个AE呢?
- KL散度那一项去哪了?
- codebook是什么?
- 离散化是什么,为什么要有?
- 最终的loss形态是怎么样的?
参考主要来源以下:
https://zhouyifan.net/2023/06/06/20230527-VQVAE/
https://spaces.ac.cn/archives/6760/comment-page-6#comments
https://arxiv.org/pdf/1711.00937
需要熟悉AE知识,这个属于一看就懂的知识,没必要在介绍;
需要了解VAE,KL散度知识,其实和VAE关系真不大。
需要了解pixelcnn。
1. VQ离散编码思路
Autoencoder, AE做不了图像生成,因为他太过拟合了,但是他提供了一个思路,那就是图像压缩功能。为了解决这种过拟合,VAE的思路是引入噪声,让AE编码出来的结果是带有
σ
\sigma
σ噪声的压缩结果(也就是在一个正太分布上采样),每次解码输入都是带有噪声的,因此最终可以在一个分布上采样,实现图像生成。但是由于VAE通过平衡重构损失和KL散度来工作,这个平衡很难把握。如果过于强调重构,模型可能仅学会复制输入数据,失去生成新样本的能力;而如果过于放松,则可能生成模糊或不切实际的样本。
VQ-VAE为了做大做强,引入离散编码的概念,相比较VAE到底有什么好处呢?其实每个人都有不同的理解,我觉得最主要的好处是因为离散化编码更有意义,而让他更有意义的原因是使用pixelcnn网络让这个离散化编码有了意义,为什么这么说?我们知道作者做的一个假设是先验的离散分布p是均匀分布,但是实际上生成任务上并没有在均匀分布上采样,当然也可以,但是效果是很差的,所以引入了pixelcnn使得整个离散分布有了意义,这也是为什么说VQ-VAE是一个AE不是一个VAE的主要原因,后面在详细解释。
1.1 整体过程
论文我们可以不去深究里面的东西,因为这篇论文真的好多没解释清楚,包括他的loss怎么来的,也是简单带过,看过网上其他人说的,其实不太建议深究论文的内容。我们拿以下图来做解释:
- Encoder部分:通过CNN将图像编码到一个 m ∗ m ∗ D m*m*D m∗m∗D的维度上,卷积很大程度上保留了图像的空间信息,这个结果是 z e ( x ) z_e(x) ze(x),跟AE的Encoder过程是一样的,只不过这里仍然是保留空间信息的m*m个D维向量。
- z e ( x ) → z q ( x ) z_e(x)\rightarrow z_q(x) ze(x)→zq(x)通过embedding space映射:
- embedding space 维护了一组 K K K个可训练的参数向量 E = ( e 1 , e 2 , . . . , e k ) E=(e_1,e_2,...,e_k) E=(e1,e2,...,ek);
- 通过最近邻算法从E中找到最相近的下标,假设压缩后的维度是22D,并假设找到最近邻的下标是 [ 0 1 2 2 ] \begin{bmatrix} 0 & 1 \\ 2 & 2 \\ \end{bmatrix} [0212],则 z q ( x ) z_q(x) zq(x)为 [ e 1 e 2 e 3 e 3 ] \begin{bmatrix} e_1 & e_2 \\ e_3 & e_3 \\ \end{bmatrix} [e1e3e2e3]
- z z z就是由上一步最近邻得到的下标矩阵 [ 0 1 2 2 ] \begin{bmatrix} 0 & 1 \\ 2 & 2 \\ \end{bmatrix} [0212],也是离散化的结果。这里我们可以看出 z q ( x ) z_q(x) zq(x)并不是在 q ( z ∣ x ) q(z|x) q(z∣x)这个分布上采样得到,而仅仅是 z e ( x ) z_e(x) ze(x)的一个恒等映射。这恰恰说明了VQ-VAE为什么不能说是一个VAE,而更像一个AE,这也回答了我们第一个问题。
- codebook是什么,还记得我们维护一个embedding Space和生成的离散化 z z z矩阵吗?我们可以通过embedding Space,把 z z z中离散化的下标整数翻译成一个个embedding Space空间中的向量,是不是很像一个密码本,这就是为什么叫embedding Space为codebook的原由,这也回答了我们第三个问题。
- 再来看Decoder部分,这部分在通过CNN把 z q ( x ) z_q(x) zq(x)原有成图像,跟AE的Decoder过程是一样的。
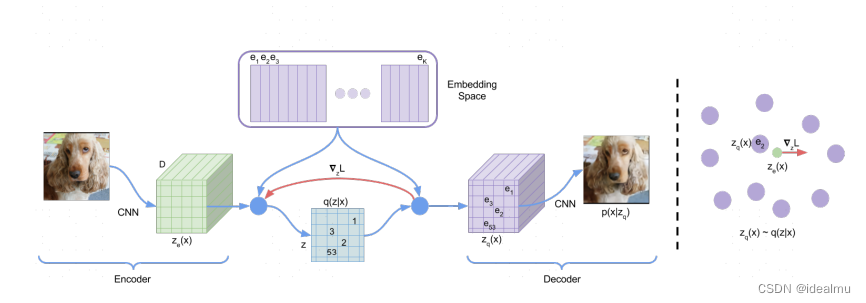
我们再来把以上过程简单画个示意图。

你会看到,离散化的编码z似乎并没参与,好像有没有无所谓,但是为什么要做这一步呢,事实上离散化编码并不会参与到训练的计算图中,也就谈不上参与梯度的计算。前面我们都说了
z
e
(
x
)
→
z
q
(
x
)
z_e(x)\rightarrow z_q(x)
ze(x)→zq(x)本身就是一个恒等映射的关系,你可以认为离散编码z只不过在求这个映射的额外产物而已。但是为什么要有呢,你可别忘了,最终我们在生成图像的时候,只是用到decoder,要有一个采样过程,而这个采样就是在z上随机采样。那你会问在z上采样不就是在embedding上采样吗,完全可以不用z啊?如果你能问出这样的问题,VQ-VAE你是真的懂了。理论上是这样,完全没错。理论上我们可以随机在z上也就是在embedding上通过均匀分布(作者假设先验分布是均匀分布)采样得到
z
q
(
x
)
z_q(x)
zq(x),但是效果很差,原因是什么,原因就是VQ-VAE是一个AE啊,本身就不具备生成的能力,即使离散化的z也是有一定的意义的。那怎么办的,还需要请出pixelcnn模型,既然z是有意义的,巧了pixelcnn专门干这事的,通过训练一个pixelcnn自然就得到一个有意义的z,自然就得到
z
q
(
x
)
z_q(x)
zq(x),就可以decoder生成图像了。这也解释了第四个问题。可以看到整个过程根本就没有在z上随机采样,但是作者为什么起名VQ-VAE呢,非要和VAE撤上关系,这要从作者构建loss来说,可能为了写论文多一点理论推导吧,非要和ELBO扯上关系。这也增加了我们看论文的难度。
1.2 为什么要和VAE撤上关系
直接把VAE中的loss拿过来,可以看上一篇我写的VAE相关理论。
L
(
θ
,
ϕ
;
x
(
i
)
)
=
−
K
L
(
q
ϕ
(
z
∣
x
(
i
)
)
∣
∣
p
θ
(
z
)
)
+
E
q
ϕ
(
z
∣
x
(
i
)
)
[
l
o
g
(
p
θ
(
x
(
i
)
∣
z
)
]
L(\theta,\phi;x^{(i)})=-KL(q_{\phi}(z|x^{(i)})||p_{\theta}(z))+E_{q_{\phi}(z|x^{(i)})}[ log(p_{\theta}(x^{(i)}|z)]
L(θ,ϕ;x(i))=−KL(qϕ(z∣x(i))∣∣pθ(z))+Eqϕ(z∣x(i))[log(pθ(x(i)∣z)]
我们拿VAE的loss说,作者做了两个假设第一个是先验分布
p
θ
(
z
)
=
1
/
K
p_{\theta}(z)=1/K
pθ(z)=1/K是一个均匀分布,第二个是编码网络得到结果
q
ϕ
(
z
∣
x
(
i
)
)
q_{\phi}(z|x^{(i)})
qϕ(z∣x(i))为one-hot。关于one-hot是什么意思呢,做过分类任务都知道,one-hot编码有一个特点,就是等于这个编码结果概率为1,否则为0,不清楚自行查一查。
那么我们再来看KL散度这一项,里面的字母我稍微简化一些
K
L
(
q
ϕ
(
z
∣
x
(
i
)
)
∣
∣
p
θ
(
z
)
)
=
∑
z
q
ϕ
(
l
o
g
q
ϕ
−
l
o
g
p
θ
)
=
0
+
0
+
0
+
.
.
.
+
1
∗
(
l
o
g
(
1
)
−
l
o
g
(
1
/
K
)
)
=
l
o
g
K
KL(q_{\phi}(z|x^{(i)})||p_{\theta}(z))=\sum_zq_{\phi}(logq_{\phi}-logp_{\theta})=0+0+0+...+1*(log(1)-log(1/K))=logK
KL(qϕ(z∣x(i))∣∣pθ(z))=z∑qϕ(logqϕ−logpθ)=0+0+0+...+1∗(log(1)−log(1/K))=logK
从上式我们发现KL散度竟然是常数,loss那一项就剩下后面
L
(
θ
,
ϕ
;
x
(
i
)
)
=
E
q
ϕ
(
z
∣
x
(
i
)
)
[
l
o
g
(
p
θ
(
x
(
i
)
∣
z
)
]
=
l
o
g
(
p
θ
(
x
(
i
)
∣
z
)
L(\theta,\phi;x^{(i)})=E_{q_{\phi}(z|x^{(i)})}[ log(p_{\theta}(x^{(i)}|z)]= log(p_{\theta}(x^{(i)}|z)
L(θ,ϕ;x(i))=Eqϕ(z∣x(i))[log(pθ(x(i)∣z)]=log(pθ(x(i)∣z)
这大概就是作者为什么要这样强行跟VAE撤上关系本质原因。这也解释了第二个问题,看过VAE的都知道,上面的结果是等价于重建的损失的。但是只有一个重建loss似乎不够,别忘了我们还训练了一个codebook。接下来我们继续看完整的损失。
2. 完整的损失函数
我们知道,VAE中也推导也用了最大释然对数等价于均方差构建的重建损失,原因在于假设了高斯分布的情况下,因此可以用重建损失来代替,这也是为什么跟VAE扯上关系的原因,如果认为他是一个AE,那么直接用AE的重建损失就完事了:
L
=
∣
∣
x
−
d
e
c
o
d
e
r
(
z
q
(
x
)
)
∣
∣
2
2
L=||x-decoder(z_q(x))||_2^2
L=∣∣x−decoder(zq(x))∣∣22
猛一看这个损失没有什么问题,细看,你会发现,它没办法优化encoder和codebook,原因是因为
z
e
(
x
)
→
z
q
(
x
)
z_e(x)\rightarrow z_q(x)
ze(x)→zq(x)是通过codebook映射过去的,没法反向传播。于是作者提出了一个直通的概念,反向传播的时候直接让
z
e
(
x
)
z_e(x)
ze(x)的梯度等于
z
q
(
x
)
z_q(x)
zq(x)的梯度,也是途中红色箭头所示,具体怎么做呢,如果是pytorch,可以用detach来从计算图中分离出来,具体如下:将
(
z
q
−
z
e
)
.
d
e
t
a
c
h
(z_q-z_e).detach
(zq−ze).detach即可
L
=
∣
∣
x
−
d
e
c
o
d
e
r
(
z
q
(
x
)
)
∣
∣
2
2
=
∣
∣
x
−
d
e
c
o
d
e
r
(
z
e
+
s
g
(
z
q
−
z
e
)
)
∣
∣
2
2
=
∣
∣
x
−
d
e
c
o
d
e
r
(
z
e
+
(
z
q
−
z
e
)
.
d
e
t
a
c
h
)
∣
∣
2
2
L=||x-decoder(z_q(x))||_2^2=||x-decoder(z_e+sg(z_q-z_e))||_2^2 \\=||x-decoder(z_e+(z_q-z_e).detach)||_2^2
L=∣∣x−decoder(zq(x))∣∣22=∣∣x−decoder(ze+sg(zq−ze))∣∣22=∣∣x−decoder(ze+(zq−ze).detach)∣∣22
这样的话,重建损失有了,encoder和decoder也可以优化了,但是codebook那一项没法优化。那该怎么优化codebook呢,我们知道
z
q
z_q
zq是来源于
z
e
z_e
ze在codebook中最近邻球得的,因此好的codebook必然是
z
q
z_q
zq与
z
e
z_e
ze越近越好,自然而然就是下面损失:
L
e
=
∣
∣
z
q
−
z
e
∣
∣
2
2
L_e=||z_q-z_e||_2^2
Le=∣∣zq−ze∣∣22
这样的话
z
q
z_q
zq可以更新codebook的参数,
z
e
z_e
ze可以更新encoder的参数,但是作者觉得编码器和codebook学习速度应该不一样快。于是,他们再次使用了停止梯度的技巧,把上面那个误差函数拆成了两部分。用
β
\beta
β来平衡,常取0.1~2.0。作者取值为0.25。于是整体损失变为以下:
L
=
∣
∣
x
−
d
e
c
o
d
e
r
(
z
e
+
s
g
(
z
q
−
z
e
)
)
∣
∣
2
2
+
∣
∣
z
q
−
s
g
(
z
e
)
∣
∣
2
2
+
β
∣
∣
s
g
(
z
q
)
−
z
e
∣
∣
2
2
L=||x-decoder(z_e+sg(z_q-z_e))||_2^2 +||z_q-sg(z_e)||_2^2+\beta ||sg(z_q)-z_e||_2^2
L=∣∣x−decoder(ze+sg(zq−ze))∣∣22+∣∣zq−sg(ze)∣∣22+β∣∣sg(zq)−ze∣∣22
至此,我们整个VQ-VAE就讲完了,看完之后是不是很舒服。包括我们如何去训练也一目了然。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











