






目录
习题7-1 在小批量梯度下降中,试分析为什么学习率要和批量大小成正比
习题7-2 在Adam算法中,说明指数加权平均的偏差修正的合理性
习题7-9 证明在标准的随机梯度下降中,权重衰减正则化和编辑正则化的效果相同.并分析这一结论在动量法和Adam算法中是否依然成立
习题7-1 在小批量梯度下降中,试分析为什么学习率要和批量大小成正比
在迷你批量梯度下降法中,批量大小(Batch Size)对网络优化的影响也非常大。
一般而言,批量大小不影响随机梯度的期望,但是会影响随机梯度的方差。
批量大小越大,随机梯度的方差越小,引入的噪声也越小,训练也越稳定,因此可以设置较大的学习率。
而批量大小较小时,需要设置较小的学习率,否则模型会不收敛。学习率通常要随着批量大小的增大而相应地增大。
习题7-2 在Adam算法中,说明指数加权平均的偏差修正的合理性
Adam算法在训练的最开始需要初始化梯度的累积量和平方累积量。
假设在训练的第t轮训练中,我们首先可以计算得到Momentum和RMSProp的参数更新:
由于移动指数平均在迭代开始的初期会导致和开始的值有较大的差异,所以我们需要对上面求得的几个值做偏差修正.
习题7-9 证明在标准的随机梯度下降中,权重衰减正则化和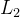 正则化的效果相同.并分析这一结论在动量法和Adam算法中是否依然成立
正则化的效果相同.并分析这一结论在动量法和Adam算法中是否依然成立

L2正则化梯度更新的方向取决于最近一段时间内梯度的加权平均值。
当与自适应梯度相结合时(动量法和Adam算法),
L2正则化导致导致具有较大历史参数 (和/或) 梯度振幅的权重被正则化的程度小于使用权值衰减时的情况。
第七章总结















 567
567











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









