








建立CIPP评估模型
选取指标:
| 一级指标 | 二级指标 | 三级指标 | 单位 |
| 高等教育健康评价体系 A1 | 高等教育基础 B1 | 人均GDP现价美元 C1 | $/人 |
| 高等教育学生男女比例C2 | 指数 | ||
| 高等教育投入 B2 | 研究支出占GDP百分比 C3 | % | |
| 大学生人均教育支出(政府)占人均GDP比重 C4 | % | ||
| 高等教育发展过程 B3 | 高等教育教师总人数 C5 | 人 | |
| 高等教育毛入学率 C6 | % | ||
| 高等学历学生总人数 C7 | 人 | ||
| 高等教育产出 B4 | 每百万人中研究人员数量 C8 | 人 | |
| 居民专利申请数 C9 | 个 | ||
| 科技期刊文章 C10 | 篇 | ||
| 高科技出口(占制成品出口的百分比) C11 | % |
数据来源:世界银行,
毕达留学 泰晤士
缺失值处理:
我们最终希望得到的衡量数据是最近三年可获得数据的平均值。
如果最近三年数据都有,那么很显然直接用其均值;
如果该国家近10年某指标(如每百万人中研究人员数量)都没有数据,则认为该数据空值,暂记为0,代表该国没有研究人员(这一指标表现差);
对于中断值采取分段三次Hermite插值法,由于该插值法至少需要2个数据点,所以对10年来只有1个数据点的直接取该值;超过一个的,用插值法。
Hermite插值法(埃尔米特)介绍:
{Hermite插值法是解决数学建模中预测类问题的最常用的方法,可以有效的解决“已知数据”数量不够的问题。
但是,直接使用Hermite插值得到的多项式次数较高,也存在着“龙格现象(Runge phenomenon)”。因此,在实际应用中,往往使用分段三次Hermite插值多项式(PCHIP),来提高“模拟数据的准确性”。}
参考博客:Hermite(埃尔米特)插值法_Rayme629的博客-CSDN博客_埃尔米特插值
Matlab有内置函数pchip可直接实现分段三次埃尔米特插值。
p = pchip(x,y, new_x)
%x是已知的样本点的横坐标(至少两个);y是已知的样本点的纵坐标;new_x是要插入处对应的横坐标缺失值处理主要代码如下:
%clc,clear
%data=xlsread('',1);
%% 缺失值处理
data=data(:,end-10:end);
L=size(data,2); %矩阵长度,时间跨度
M=size(data,1); %矩阵宽,样本国家个数
A=mean(data(:,L-2:L),2); %按行求平均数
for i=1:M
for j=1:L
if sum(isnan(data(i,:)))==L
A(i)=0;
data(i,L-2:L)=[0 0 0];
elseif sum(isnan(data(i,:)))==L-1
A(i)=nansum(data(i,:));
data(i,L-2:L)=[A(i) A(i) A(i)];
elseif isnan(A(i))==1 % 是NAN,isnan返回1
x=1:L;
y=data(i,x);
new_x=L-2:L;
p=pchip(x,y,new_x);
data(i,L-2:L)=p;
A(i)=mean(p);
end
end
end
xlswrite('近3年数据.xlsx',data(:,L-2:L),'高等学历学生总数','B2'); %改参数3
xlswrite('指标数据.xlsx',A,3,'C2'); %改参数3, UIS=3
%参数4
得到各指标数据后,发现:
有的国家指标空缺过多,直接删去不予考虑;
指标出现负值,这主要是由于插值产生的偏差(也说明该国这一指标往年数据缺失太多),对于选取的11个指标来说,其物理意义都应在正值下考量,因此直接归0处理;
有的数据其含义为百分比,却超过了100,查看后发现,是由于个别国家该指标源数据即出现错误(猜测可能是数据填错等原因),导致数据过大,而插值后往往也会求得过大的异常值。又因国家选取数有217之众,体量丰富,直接删去这些国家的数据。
topsis排名
1.对各指标正向化处理:
效益型指标:属性值越大,该属性对决策的重要程度越高。
费用型指标:属性值越大,该属性对决策的重要程度越小。
中间型指标:属性值越靠近某一特定值,越好。
将三种类型的指标统一正向化处理,即换成效益型。
在我们选取的11个指标中,只有高等教育学生男女比例C2是中间型指标,其余都是效益型指标。
对中间型指标做如下处理:
首先我们认为高等教育学生男女比例越接近1,越说明男女教育平等,即教育体系越健康。
即最优值best=1
令
%中间型属性
z=1;%中间型属性列数
best=1;%男女比例最优为1
M =max(abs(dnew{1,2}(:,1)-best));
dnew{1,2}(:,1) = 1 - abs(dnew{1,2}(:,1)-best) / M;2.将已全部正向化的指标标准化,这里用归一化的方法。
令标准化后的决策矩阵,记为r,其列向量分量之和为1.

3.确定各指标权重,采取熵权法
信息熵法:一个信息量的(概率)分布越趋向一致,所提供信息的不确定越大,用熵作为衡量不确定的指标。在多属性决策中,将标准化决策矩阵R的各个列向量看作每个属性信息量的概率分布。按照Shannon对熵的定义,各方案关于属性Xj的熵为

熵值越大,代表信息不确定性越大(信息量概率分布越趋向一致),属性Xj对于辨别方案优劣的作用越小。
定义

为属性Xj的区分度。(Fj越大,Xj的区分度越大,属性Xj越重要)
将归一化的区分度取作属性Xj的权重wj,即

权重结果如下:
| C1 | C2 | C3 | C4 | C5 | C6 | C7 | C8 | C9 | C10 | C11 |
| 0.070 | 0.038 | 0.068 | 0.058 | 0.121 | 0.045 | 0.126 | 0.077 | 0.200 | 0.132 | 0.066 |
C9居民专利申请数,C10科技期刊文章 ,C7高等学历学生总人数,C5高等教育教师总人数。
4. 进行topsis排序
topsis法(接近理想解的偏好排序法)
理论上的最优方案(称正理想解)由所有可能的加权最优属性值构成,最劣方案(称负理想解)由可能的加权最劣属性值构成。定义距正理想解尽可能近、距负理想解尽可能远的数量指标——相对接近度,备选方案的优劣顺序按照相对接近度的大小确定。
1)定义各方案在空间的欧氏距离,先将指标矩阵模一化:
模一化方法:

再模一化后的rij×属性权重wj,构成矩阵V。
2)取出正理想解(由每列向量中最大元素构成),记为v+
负理想解(由每列向量中最小元素构成),记为v-
V_max=max(V,[],1); %正理想解,max函数参数3表示取每列的最大值
V_min=min(V,[],1); %负理想解,min函数参数3表示取每列的最小值
3)计算方案Ai与正理想解的欧式距离:
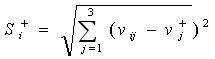
与负理想解的欧式距离 :
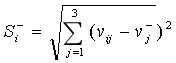
4)定义方案Ai与正理想解的相对接近度为
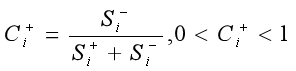
之后对进行归一化处理,
越大,表示方案越好。
topsis排序完毕,
在排序时对指标进行处理异常值如负值归0,百分比却超过100删去,对某国家指标缺失过多的删去完整代码如下:
clc,clear
[~,~,d1]=xlsread('指标数据.xlsx','总表','A2:A218'); %每行为一个方案,每列为一种属性
d2=xlsread('指标数据.xlsx','总表','B2:L218');
d=cell(1,2);
d{1,1}=d1;
d{1,2}=d2;
m=size(d2,1); %m种方案
n=size(d2,2); %n种属性
% 如有过大异常值,删去,比如属性2,3,4,11,皆为百分比,超过100就将该国家删去
%可能原因为原始数据记录出错,超过100,而插值后往往也会变得更大。
del=[];%要删除国家的集合
for i=1:m
for j=[2,3,4,11]
if d{1,2}(i,j)>100
del=[del,i];
end
end
end
%负指标归0
for i=1:m
for j=1:n
if d{1,2}(i,j)<0
d{1,2}(i,j)=0;
end
end
end
%零值指标超过4个,删除
zero=sum(d{1,2}==0,2);
ID=[];
for i=1:m
if zero(i)<3
ID=[ID,i]; %ID保留
end
end
fin_ID=setdiff(ID,del);
dnew=cell(1,2);
dnew{1,1}=d{1,1}(fin_ID,:); %国名
dnew{1,2}=d{1,2}(fin_ID,:); %指标
%% 原始决策矩阵标准化
%% 各指标正向化
% l=1; %费用型属性
% d(:,l)=1./d(:,l);%将费用型属性变换为效益型
%中间型属性
z=1;%中间型属性列数
best=1;%男女比例最优为1
M =max(abs(dnew{1,2}(:,1)-best));
dnew{1,2}(:,1) = 1 - abs(dnew{1,2}(:,1)-best) / M;
%%
%归一化
r=dnew{1,2}./sum(dnew{1,2},1)+0.0001; %sum函数参数2表示按照每列相加
%最大化
%r=d./max(d,[],1); %max函数参数3表示取每列的最大值
%模一化
rm=dnew{1,2}./sum(dnew{1,2}.^2,1).^0.5; %sum函数参数2表示按照每列相加
%% 属性权重的确定
E=(-1/log(m))*sum(r.*log(r),1); %E熵值,sum函数参数2表示按照每列相加
F=1-E; %F区分度
w=F/sum(F); %w各属性的权重
%% topsis法确定方案优劣顺序(决策矩阵需用模一化方法处理,但权重的确定仍可使用归一化等方法)
V=rm.*w;
V_max=max(V,[],1); %正理想解,max函数参数3表示取每列的最大值
V_min=min(V,[],1); %负理想解,min函数参数3表示取每列的最小值
S_plus=sum((V-V_max).^2,2).^0.5; %求各方案与正理想解的欧式距离,sum函数参数2表示按照每行相加
S_minus=sum((V-V_min).^2,2).^0.5; %求各方案与正理想解的欧式距离,sum函数参数2表示按照每行相加
C=S_minus./(S_plus+S_minus); %C,各方案与正理想解的相对接近度
C=C./sum(C,1); %C归一化处理
[Y,index]=sort(C,1,'descend'); %参数2按列排序,参数3降序,Y排序后的结果,对应index原矩阵下标
%% print
dprint=cell(1,2);
dprint{1,1}=dnew{1,1}(index,:);
dprint{1,2}=dnew{1,2}(index,:);
xlswrite('topsis排名.xlsx',dprint{1,1},1)衡量高等教育效率——数据包络分析DEA
取投入x1研究支出占GDP百分比(C3 ),x2大学生人均教育支出(政府)占人均GDP比重 (C4 ), x3高等教育教师总人数( C5),
输出指标y1高等学历学生总人数 ( C7),y2每百万人中研究人员数量 ( C8),y3居民专利申请数 (C9),y4科技期刊文章 C10,y5高科技出口(占制成品出口的百分比) C11.
待续















 3315
3315











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









