







目录
前言 (目标链接放评论区了)
第二步,拉取视频网址,拿到contId,获取请求视频的json网址
前言
我们在上一节学习了一些Request的进阶用法和session会话的概念以及很多安全校验信息。那么这一节我们将以某视频网站(链接在评论区)为例,展示一下我们的学习成果。
目的
抓取某视频网站已知页面所包含的视频资源并保存到本地,绕过网站的反爬手段:防盗链。
思路
1. 首先打开想要抓取的页面,检查页面源代码,利用我们熟悉的开发者工具(F12)来检查视频资源所在的标签,可以通过下图所示源代码轻松找到:
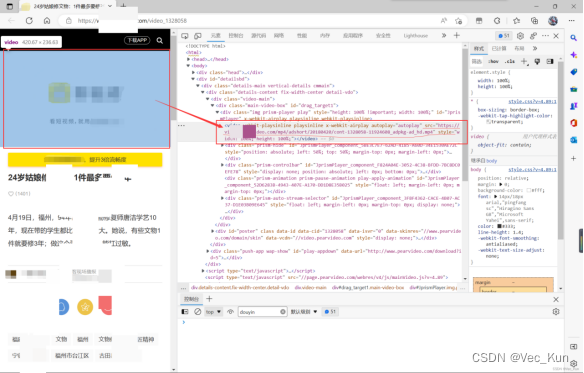
2. 把src里面包含的视频链接复制,访问页面观察是不是视频资源:
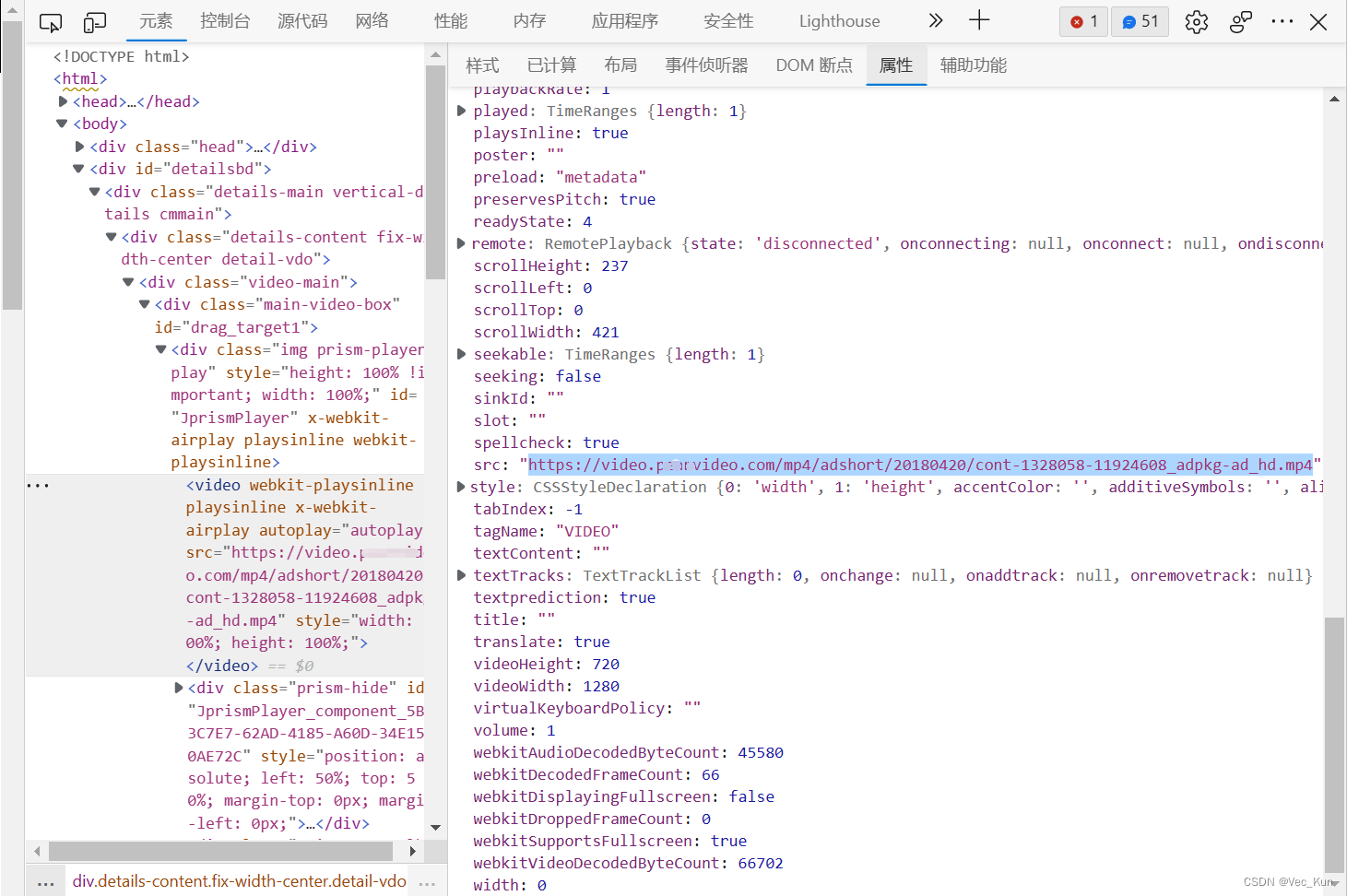
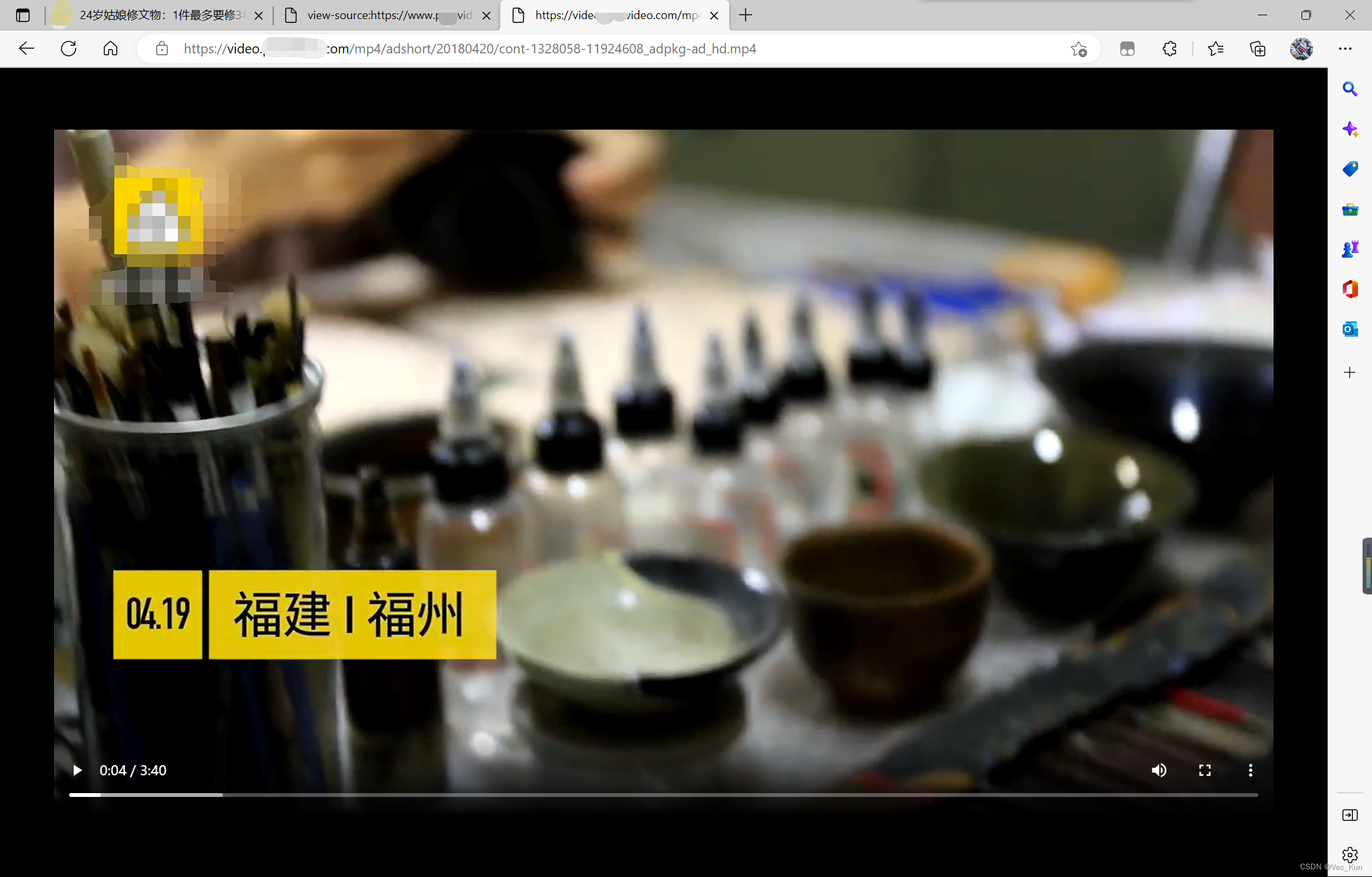 可以看到,我们成功拿到了视频资源。但是我们真的成功了吗?检查页面源代码,我们拿到的页面源代码里面有这样的<video>标签吗?或者是否在源代码中存在我们的视频链接呢?
可以看到,我们成功拿到了视频资源。但是我们真的成功了吗?检查页面源代码,我们拿到的页面源代码里面有这样的<video>标签吗?或者是否在源代码中存在我们的视频链接呢?
3. 源代码验证
我们查看页面源代码,CTRL+F查找,发现并没有上述资源:
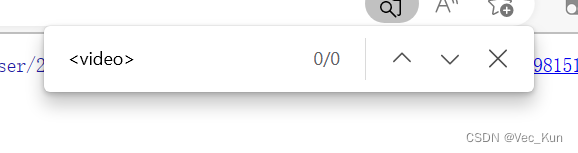
实际上,我们使用开发者工具检查页面时,它所显示的"源代码"并不是原本的,而是已经通过了一系列的解析,呈现给我们所看到整个页面的资源信息。如果我们用PyCharm直接访问的话,是拿不到经处理的<video>标签的,所以这样抓视频链接是行不通的。但至少我们已经知道了我们想拿到的目标链接是什么了。
4. 开发者工具检查网络请求
打开开发者工具,切换到网络(Network) ,筛选选项到Fetch/XHR上。所谓XHR就是XMLHttpRequest,是浏览器提供的JavaScript对象,通过它,可以请求服务器上的数据资源。所以我们切换到这个筛选项,因为源代码里面没有,一般就一定在js对象中请求。
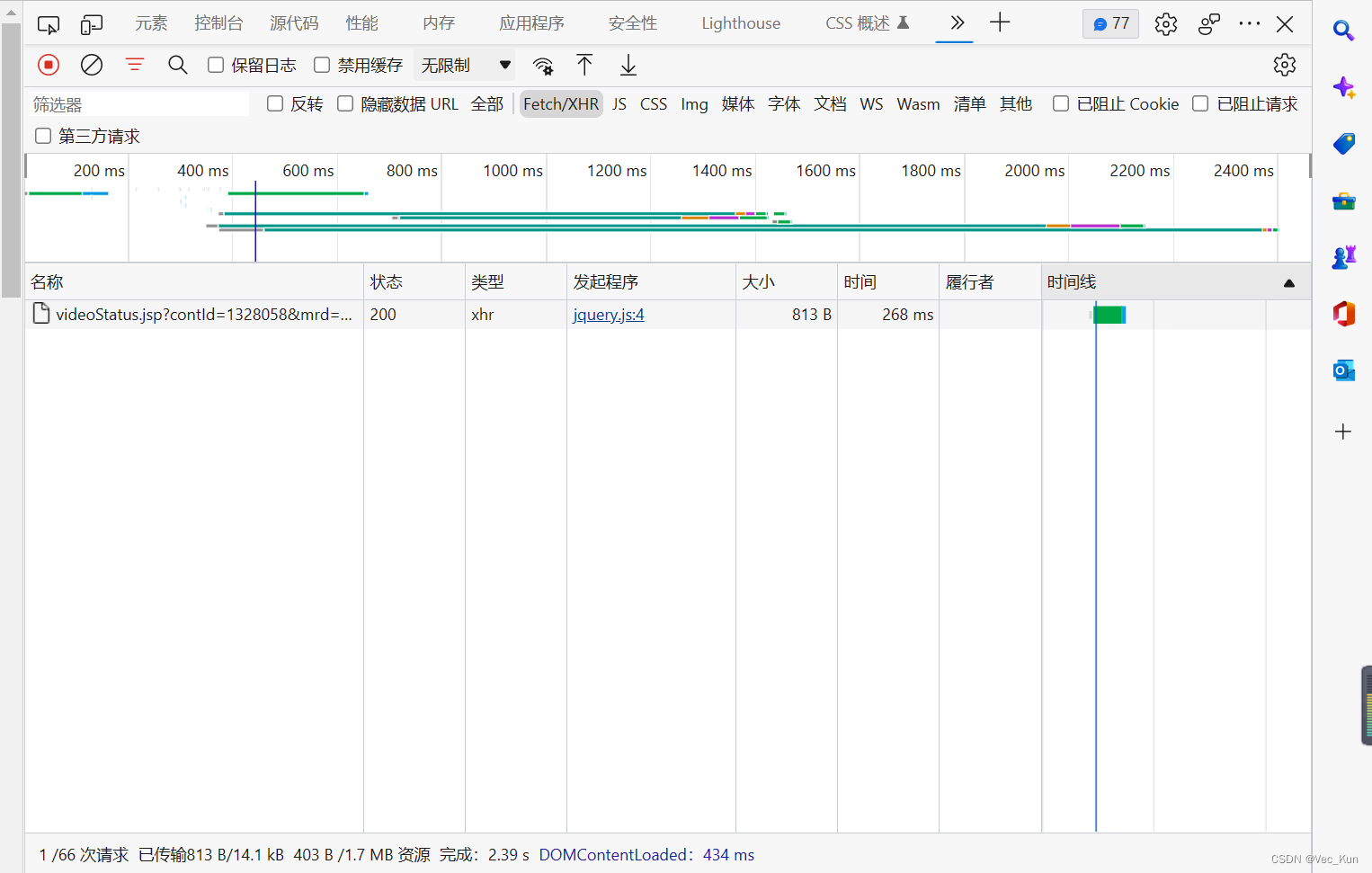
5. 打开上述请求进行检查,进行预览,一层层解开json数据,找到请求链接:
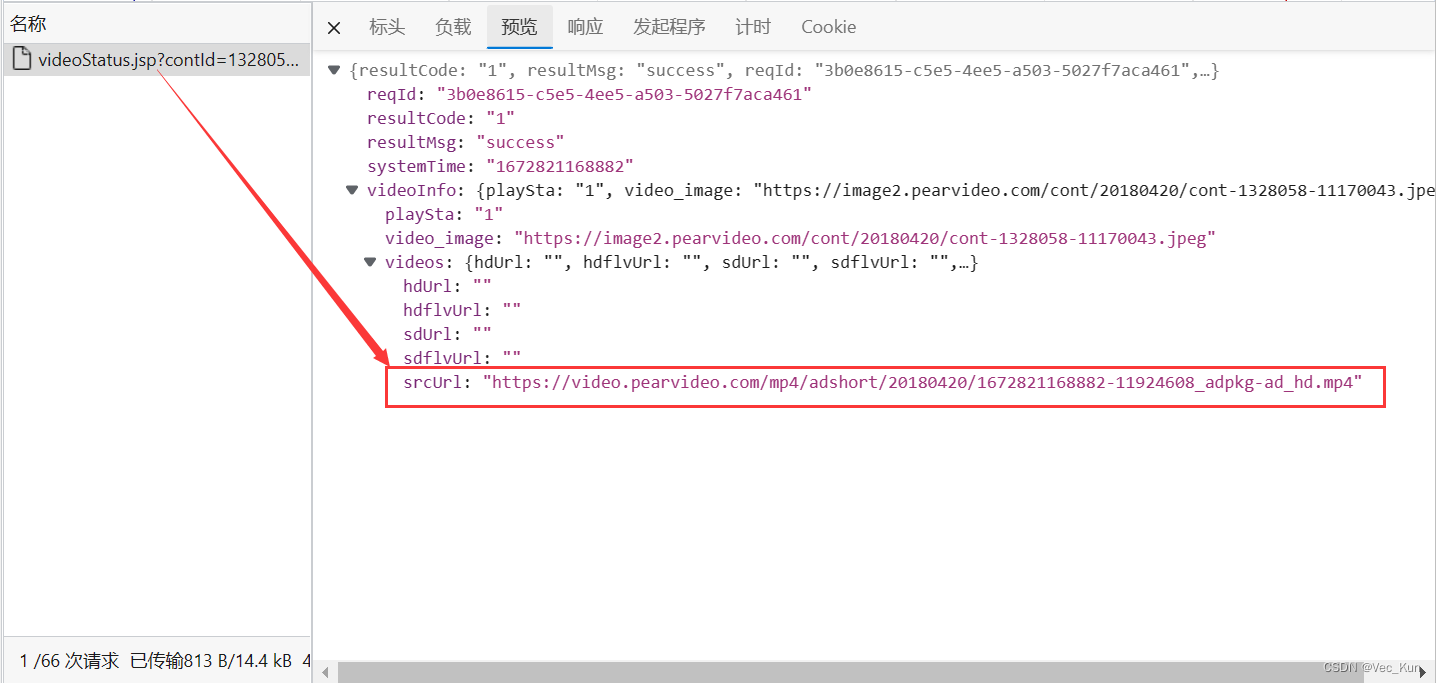
6. 访问此链接,查看是否能请求到视频资源:
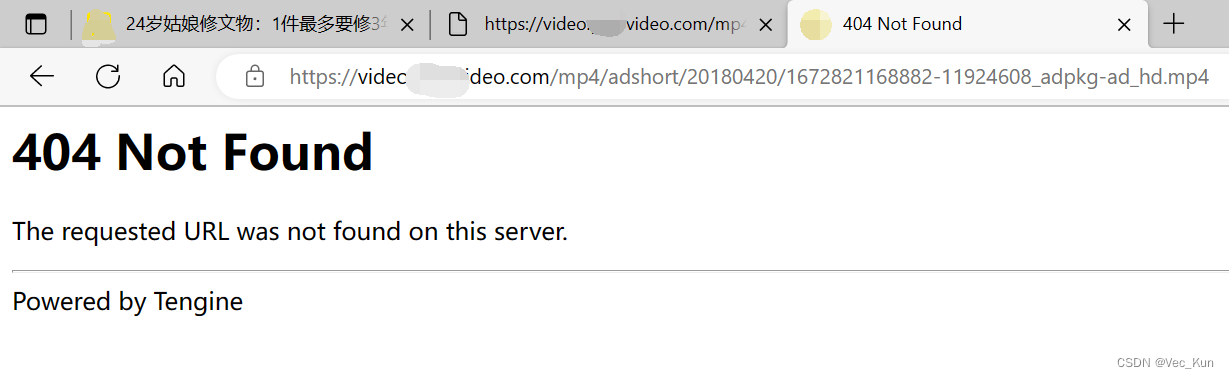
7. 发现无法访问,那么我们来对比两个链接的不同之处:
正确的:https://video.某某video.com/mp4/adshort/20180420/cont-1328058-11924608_adpkg-ad_hd.mp4
错误的:https://video.某某video.com/mp4/adshort/20180420/1672821168882-11924608_adpkg-ad_hd.mp4对比发现,只有‘cont-1328058’与‘1672821168882’的区别。那么我们只要搞清楚这两项分别是什么,再进行替换就OK了。
8. 查找两项的含义
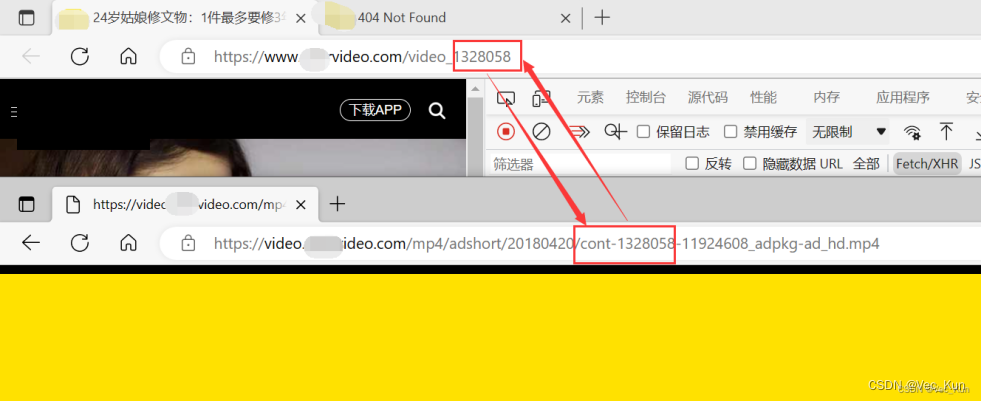
发现‘cont-1328058’后面的一串数字就是我们访问页面下划线后的那串数字!

发现‘1672821168882’就是我们抓取到json数据中的‘systemTime’!
现在思路就十分清晰了,直接进入代码部分。
代码实现
第一步,理清思路,导包
# 1. 从链接拿到contId
# 2. 拿到videoStatus返回的json找到srcURL
# 3. 对srcURL里面的内容进行替换
# 4. 下载视频
import requests第二步,拉取视频网址,拿到contId,获取请求视频的json网址
# 拉取视频的网址
url = "见评论区"
contId = url.split("_")[1]熟悉Python基础的同学应该知道split()是把目标字符串分成两部分,我们要的是下划线的后半部分,所以拿[1]。
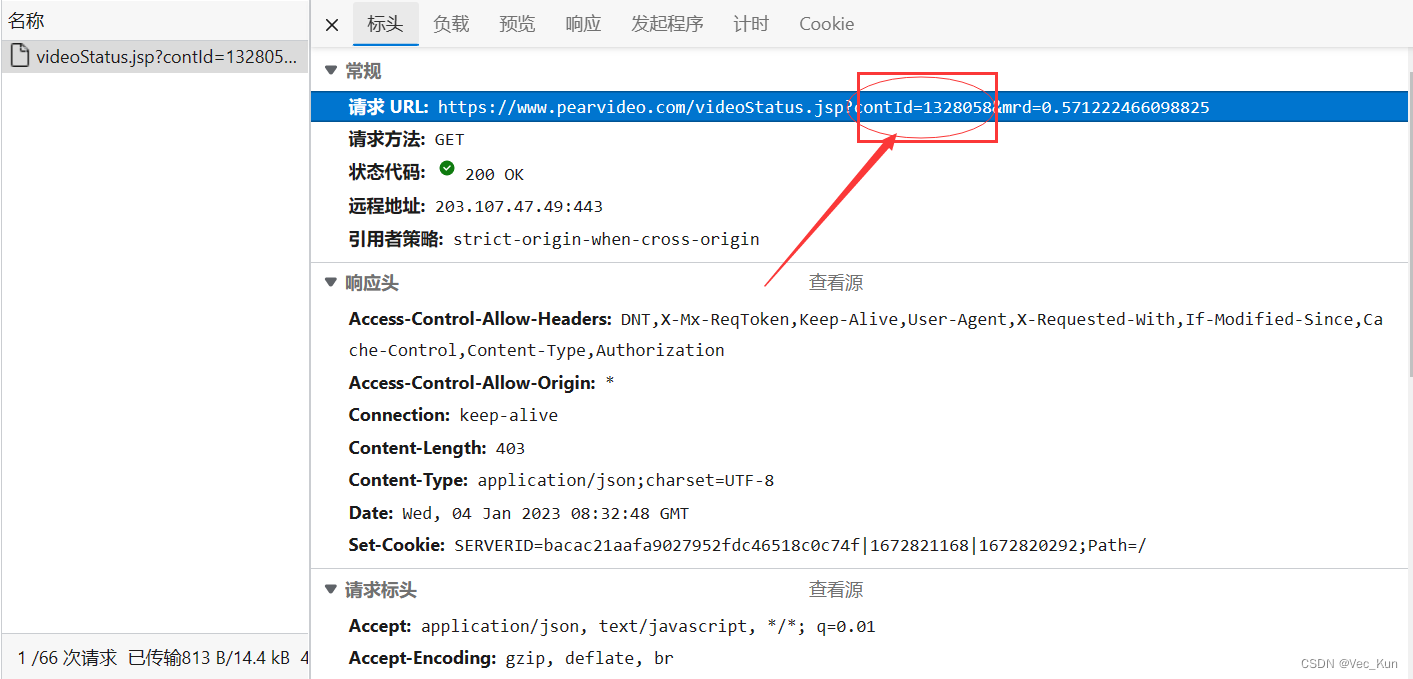
现在我们拿到了这部分,后面的mrd应该是一个自动生成的随机数,不用管它也可以。
生成普适的视频资源请求:
videoStatusUrl = f"https://www.某某video.com/videoStatus.jsp?contId={contId}"第三步,尝试访问页面,添加安全信息
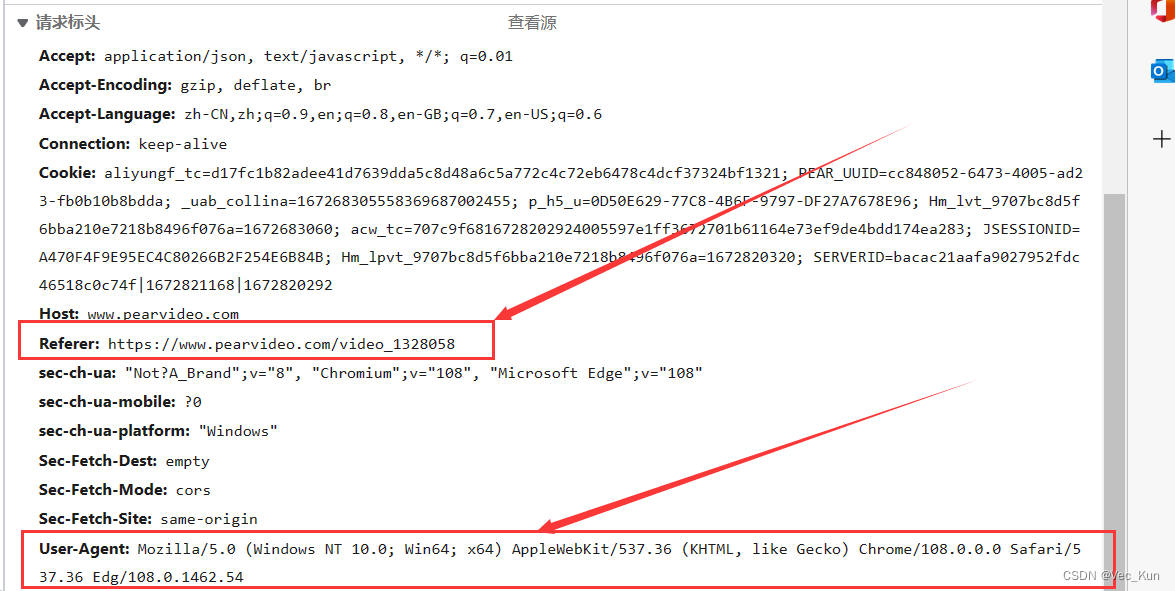
从请求标头中可以拿到UA,而我们只将UA放入headers中时是访问不到页面的,这是由于Referer的原因。
本章重点:Referer
它就是我们一直在说的防盗链:,功能就是溯源,告诉服务器当前请求的上一级是谁?也就是从哪个页面跳转访问的。服务器会拒绝非页面跳转的访问,既然他要,那我们在headers里面也声明一下就好了。
第四步,装饰请求头,获取信息
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.192 Safari/537.36",
# 防盗链: 溯源, 当前本次请求的上一级是谁
"Referer": url
}
resp = requests.get(videoStatusUrl, headers=headers)
dic = resp.json()观察到防盗链就是我们最初的页面,那么直接把防盗链设置成它就好。
由于返回的是json文件,我们对它进行resp.json()的处理。
第五步,获取获取视频资源的Url并对关键信息进行替换
srcUrl = dic['videoInfo']['videos']['srcUrl']
systemTime = dic['systemTime']
srcUrl = srcUrl.replace(systemTime, f"cont-{contId}")第六步,下载视频
# 下载视频
with open("3_result.mp4", mode="wb") as f:
f.write(requests.get(srcUrl).content)完整代码
# 1. 拿到contId
# 2. 拿到videoStatus返回的json. -> srcURL
# 3. srcURL里面的内容进行修整
# 4. 下载视频
import requests
# 拉取视频的网址
url = "见评论区"
contId = url.split("_")[1]
videoStatusUrl = f"https://www.某某video.com/videoStatus.jsp?contId={contId}"
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.192 Safari/537.36",
# 防盗链: 溯源, 当前本次请求的上一级是谁
"Referer": url
}
resp = requests.get(videoStatusUrl, headers=headers)
dic = resp.json()
srcUrl = dic['videoInfo']['videos']['srcUrl']
systemTime = dic['systemTime']
srcUrl = srcUrl.replace(systemTime, f"cont-{contId}")
# 下载视频
with open("3_result.mp4", mode="wb") as f:
f.write(requests.get(srcUrl).content)
总结
我们对requests的进阶用法进行了实践,并且熟悉了网页开发者工具的使用功能,“破解”了网站的防盗链,进行了一个反反爬操作。

















 879
879











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











