







目录
一、什么是防盗链?其作用/原理是什么?
概念:
防盗链是采用服务器端编程,通过URL过滤技术实现的防止盗链(防止获取真实链接)的技术。要显示的内容不在自己的服务器上,而是通过技术(JS等),绕过别人的最终页面,直接在自己的页面向用户提供内容。
作用:
1)防止内容被窃取
2)防止页面被攻击
原理:
从HTTP协议说起,在HTTP协议中,有一个表头字段:referer,采用URL的格式来表示从哪一个链接跳转到当前的网页或者文件。我的理解是:你(客户机)具体从哪里来,我(服务器)可以进行溯源。一旦检测来源不是网页所规定的,立即进行阻止或者返回指定的页面。
如何进行防盗链保护:
1)网站服务器是apache,可以使用apache自带的Url Rewrite功能进行保护,其原理是检查referer,如果referer的信息来自其他网站则重定向到指定的页面或者图片上;
2)网站服务器是IIS,需要使用第三方插件来实现防盗链功能,例如:ISAPI_Rewrite,可以实现类似apache的防盗链功能。
二、步骤分析
2.1、运行环境
电脑系统:win10家庭版
编辑器:pucharm edu
浏览器:我用的是搜狗、火狐(几乎任何搜索引擎都可以)
2.2、目标
视频网站,梨视频,获取该网站的部分视频;
2.3、页面分析
2.3.1、进入主页面,尝试分析源代码
(目的是为了看我们所需的视频链接是否在页面源代码),右键页面空白处,点击审查元素(要先知道视频的标签名称是什么才好在页面源代码找);

2.3.2、分析页面视频标签元素
(此时已经进入审查元素)
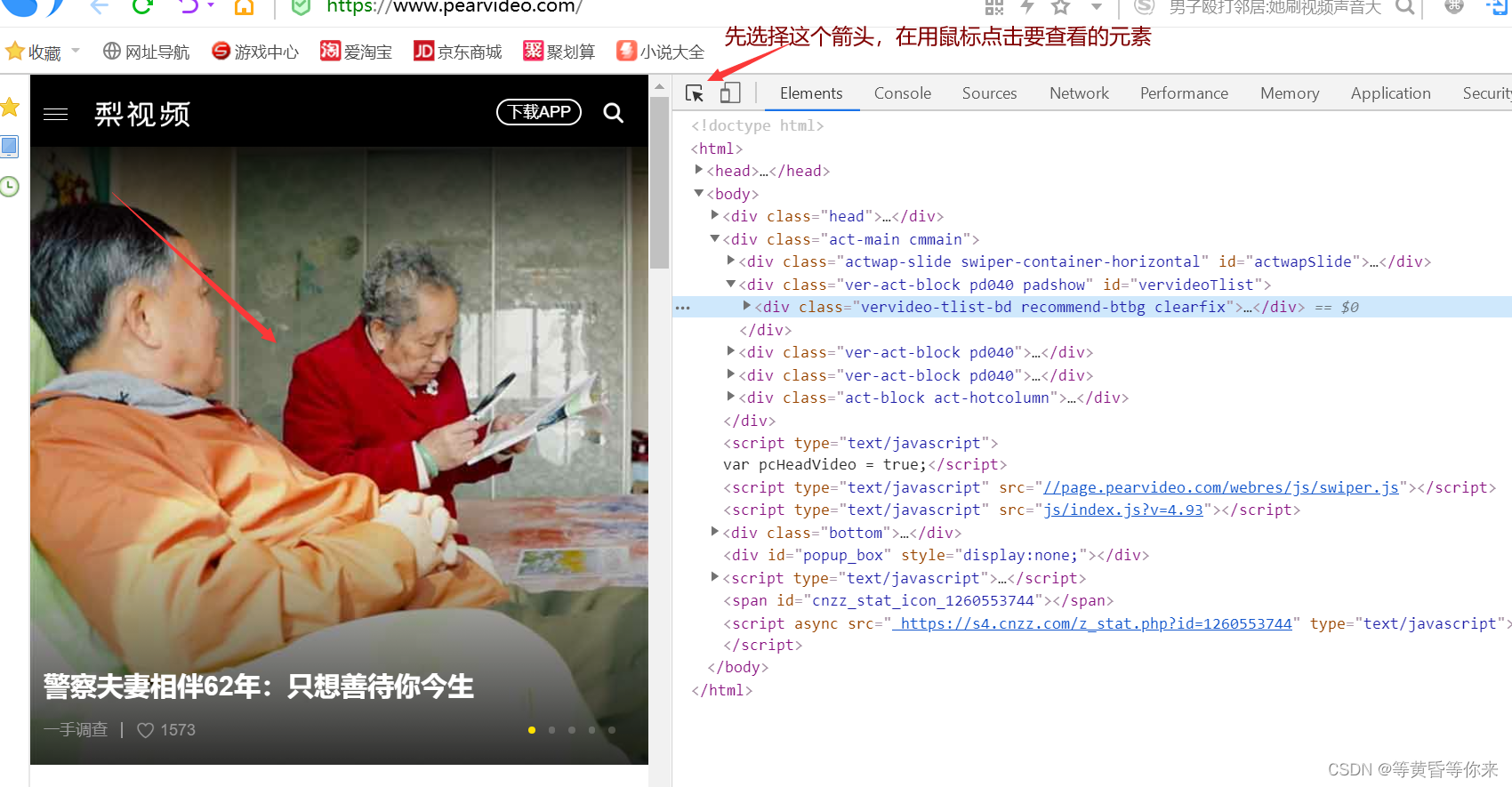
发现视频被包含在有阴影的标签,我们尝试打开
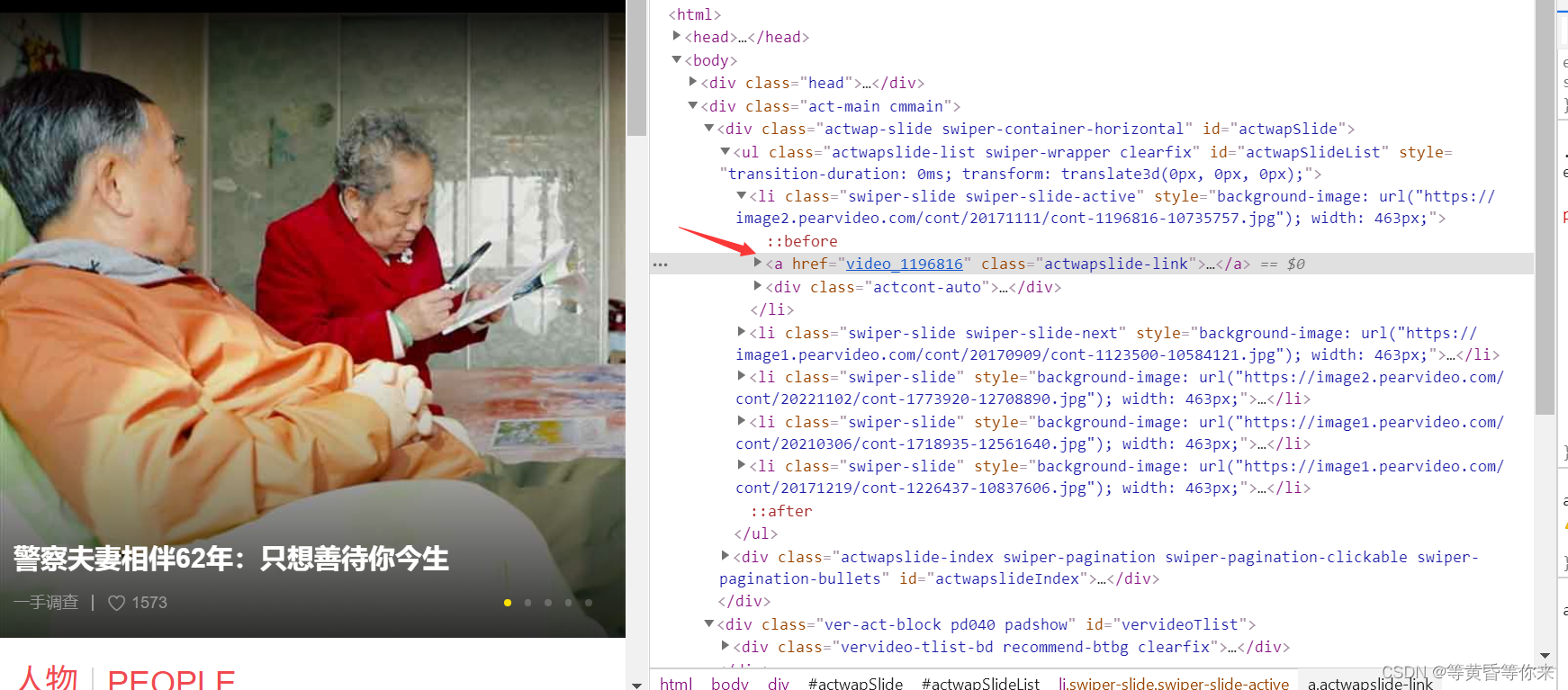
跳转到播放视频界面,我们按照之前的步骤,继续审查元素,查看视频具体的标签内容包含在一部分
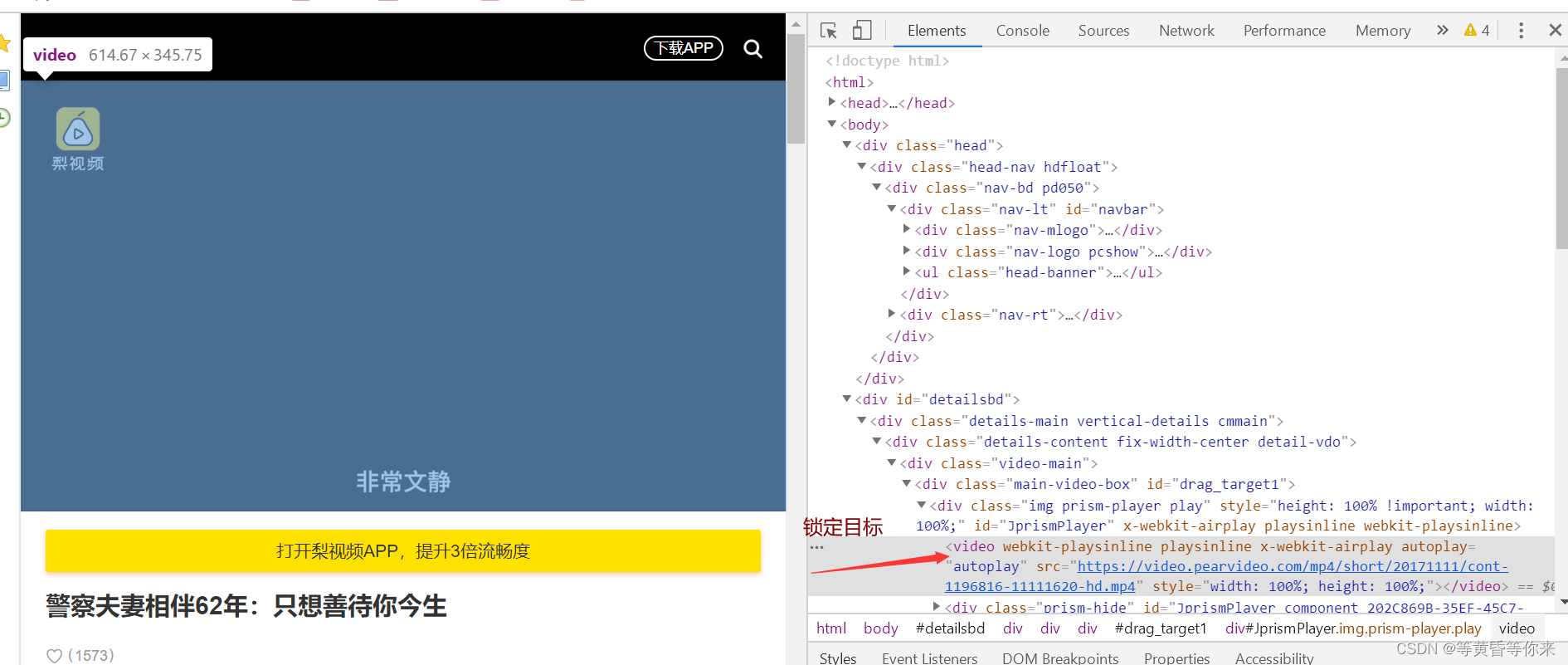
可以知道,视频是被video标签包含着的,我们需要的是src的播放链接;
2.3.3、分析页面源文件
鼠标右键打开当前播放视频页面源文件,查找video标签;
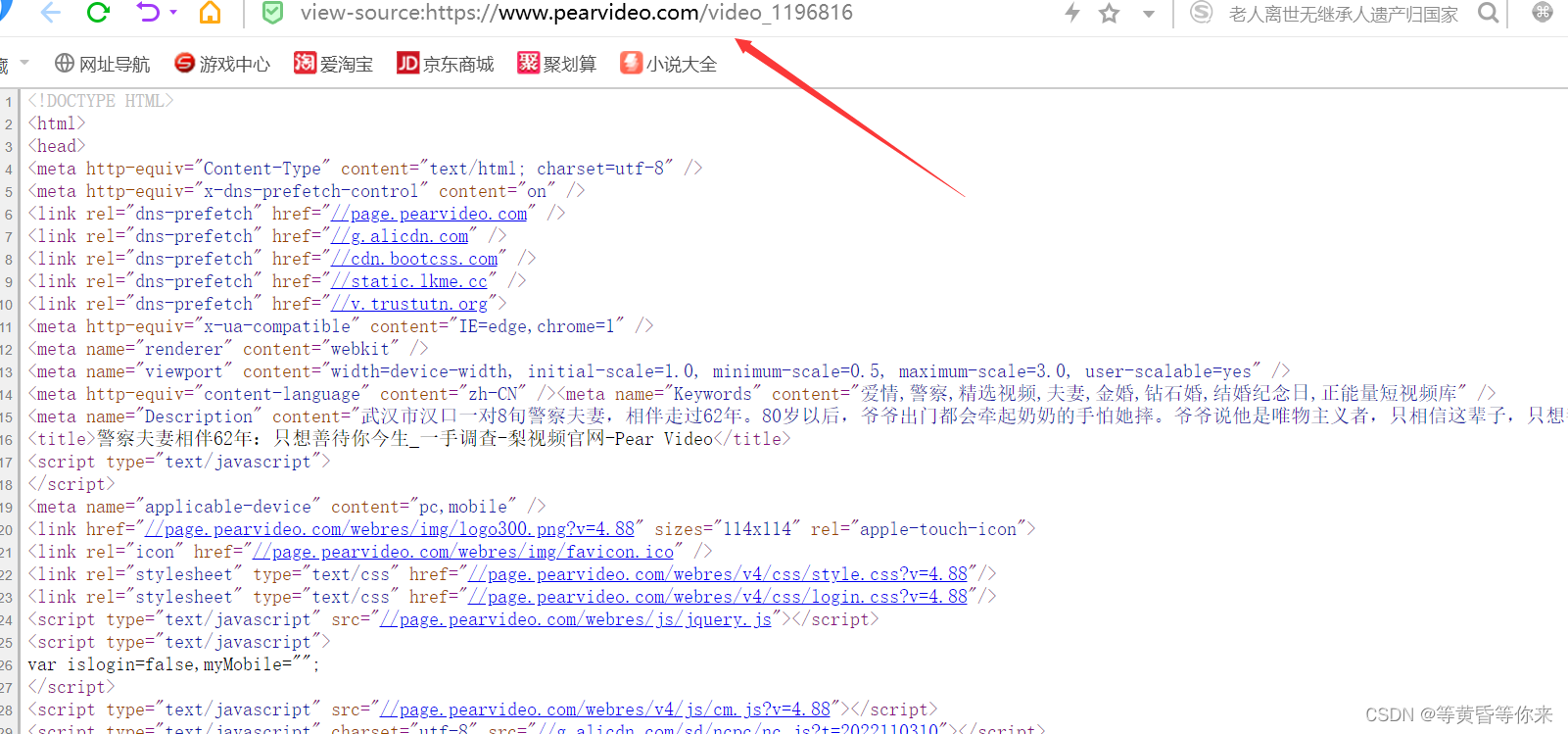
按下快捷查找,Ctrl+F ,输入<video,为啥不直接输入video呢?因为我们要找的是video标签,而标签的左边一定是“<”这个符号,可以看到搜索结果是0;
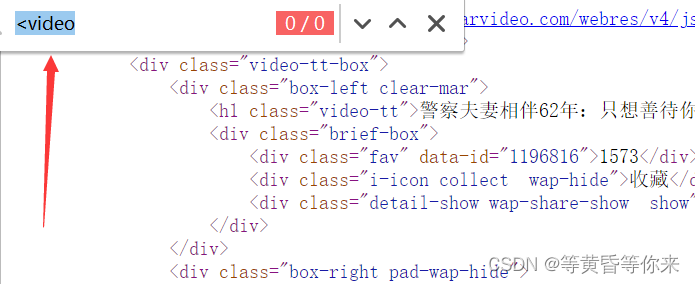
那我们在页面源代码找不到标签,我们就可以合理的推测,这个页面显示出来的东西(起码说视频的实际播放链接),应该是js经过二次处理,渲染出来的内容;
解决办法:
打开搜索引擎自带的抓包工具(自己下载的抓包工具也行,本次使用的是搜索引擎自带的),抓XHR类型的包(这个包是js处理的),注意要再次发起请求(所以要在url栏按下回车);
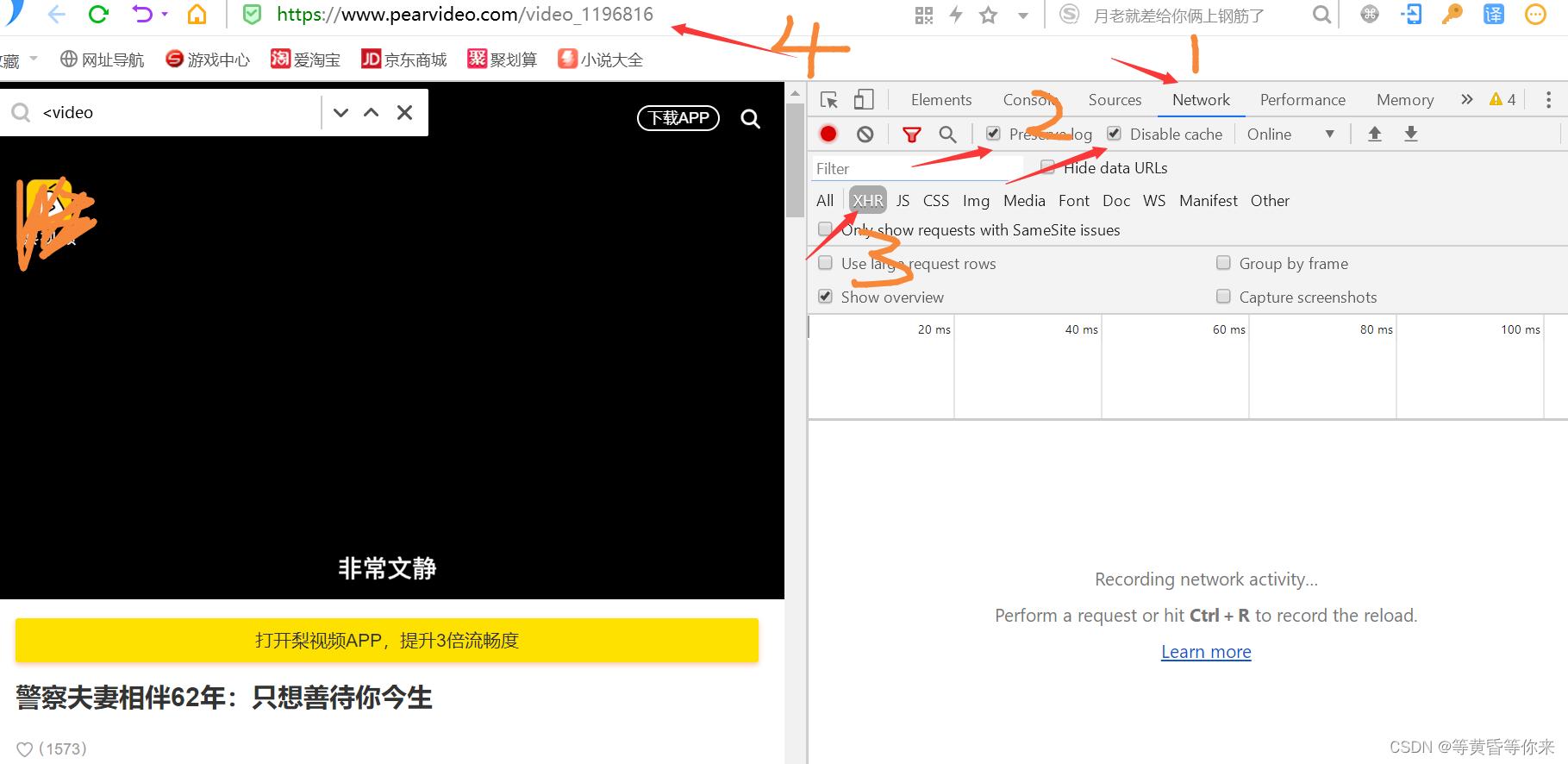
2.3.4、解决js渲染-->抓包
进入搜索引擎的开发者模式,按照图片所示的数字依次完成;
抓到这个包,进行分析

headers(请求头),Preiview(映射) ,Response(响应),一般来说是分析这三个,在Rreview发现有一个链接,好像和我们之前在标签video看到的链接有一点点像;

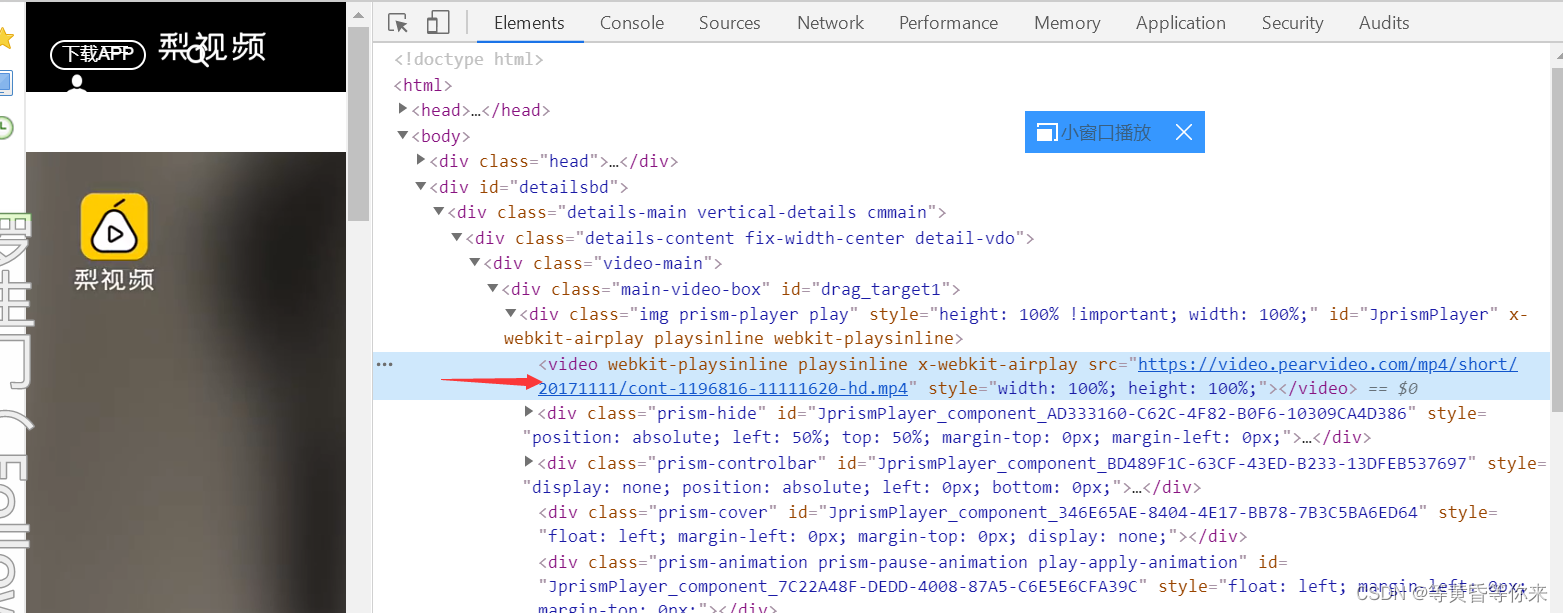
把这两个链接都复制出来进行比较;
# 这个是审查元素看到的链接
src="https://video.pearvideo.com/mp4/short/20171111/cont-1196816-11111620-hd.mp4"
# 这个是我们抓包看到的链接
srcUrl: "https://video.pearvideo.com/mp4/short/20171111/1667454066881-11111620-hd.mp4"
# 抓包看到的
systemTime: "1667454066881"
# 我们在播放视频时,页面url栏的地址
https://www.pearvideo.com/video_1196816
# 比较
https://video.pearvideo.com/mp4/short/20171111/cont-1196816-11111620-hd.mp4(可以播放)
https://video.pearvideo.com/mp4/short/20171111/1667454066881-11111620-hd.mp4(不能播放)
很容易就能得出结论:经过js处理,把实际链接的cont-1196816部分替换成了1667454066881(systemTime)
那么我们进行处理,把抓包的链接进行拼接,就能得到真正可以进行播放的链接,进而进行下载
代码:
import requests
def down_src():
url = "https://www.pearvideo.com/video_1160135"
video_id = url.split("_")[-1] # 把cont-后面的数字提取出来
video_url = f"https://www.pearvideo.com/videoStatus.jsp?contId={video_id}" # 拼接请求url
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.87 Safari/537.36 SE 2.X MetaSr 1.0",
}
resp = requests.get(video_url, headers=header)
print(resp.text)说明:我们要请求到的url很明显是抓包里的headers的url,然后把要拼接的url请求出来(简单处理反爬,加上一个请求头),因为我们要这个包的内容,当然要请求到这个请求里的url;
以上代码调用并运行结果:
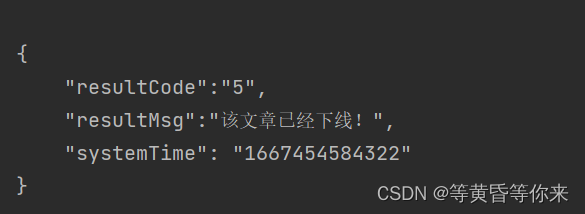
很明显,我们能播放视频,但是显示的内容是文章已经下线,很明显是被反反爬了;
下面进行处理:
2.3.5、防盗链解决并解析
如下流程图1、2、3
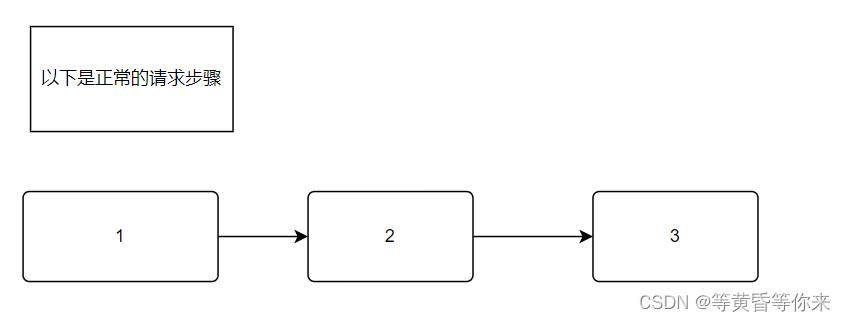
图1
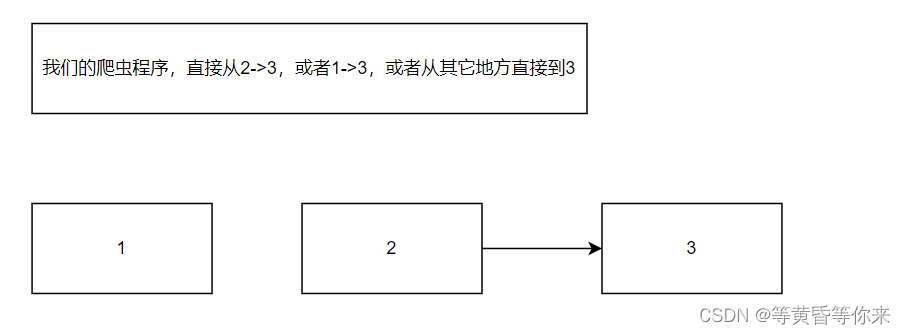
图2
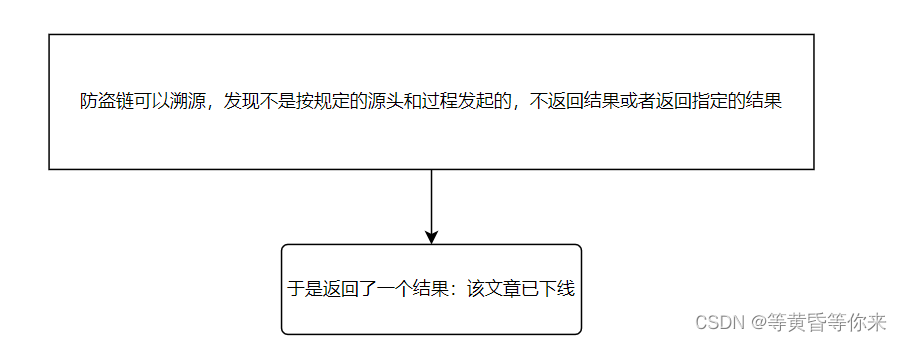
图3
解决办法,
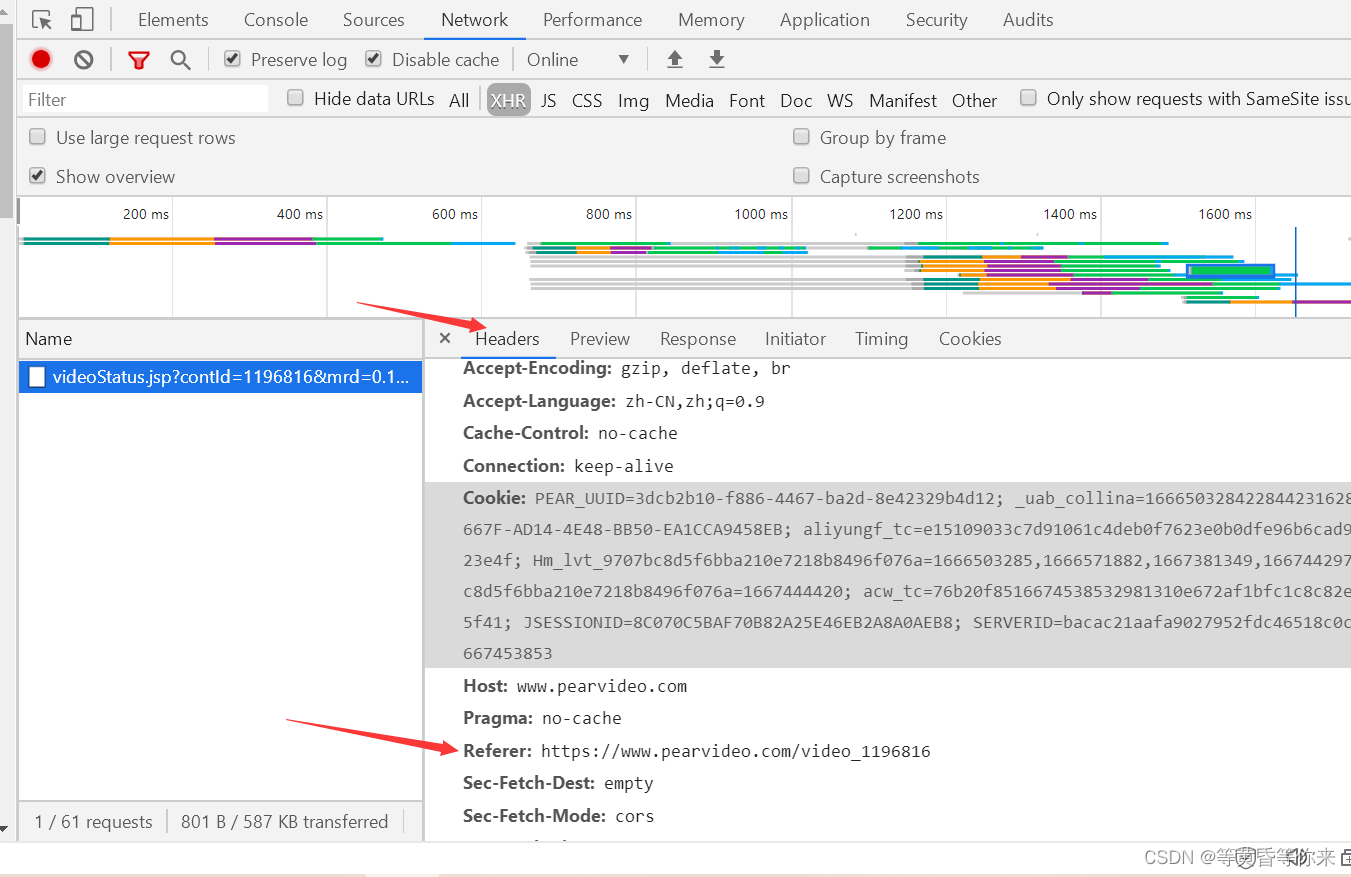
很多网页的防盗链,是加入了一个Referer,进行溯源;我们把这个参数加到请求中进行尝试;
代码如下:
import requests
def down_src():
referer = "https://www.pearvideo.com/video_1160135"
video_id = referer.split("_")[-1] # 把cont-后面的数字提取出来
video_url = f"https://www.pearvideo.com/videoStatus.jsp?contId={video_id}" # 拼接请求url
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.87 Safari/537.36 SE 2.X MetaSr 1.0",
"referer": referer
}
resp = requests.get(video_url, headers=header)
print(resp.text)调用并运行的结果:

可以看到,已经成功拿到了要使用的srcUrl,接下来可以进行拼接;
思路:因为现实出来的内容是json格式,我们可以把这些内容赋值给一个字典,然后在字典里进行提取需要的内容,进行拼接即可
拼接部分的代码:
resp = requests.get(video_url, headers=header)
dit = resp.json()
src_url = dit['videoInfo']['videos']['srcUrl']
systime = dit['systemTime']
src_url = src_url.replace(systime, f"cont-{video_id}")
print(src_url)三、完整代码
import requests
def down_src():
referer = "https://www.pearvideo.com/video_1160135" # url栏的链接
video_id = referer.split("_")[-1] # 把cont-后面的数字提取出来
video_url = f"https://www.pearvideo.com/videoStatus.jsp?contId={video_id}" # 拼接请求url
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.87 Safari/537.36 SE 2.X MetaSr 1.0",
"referer": referer
}
resp = requests.get(video_url, headers=header)
dit = resp.json()
src_url = dit['videoInfo']['videos']['srcUrl']
systime = dit['systemTime']
src_url = src_url.replace(systime, f"cont-{video_id}")
print(src_url)
# 下载视频
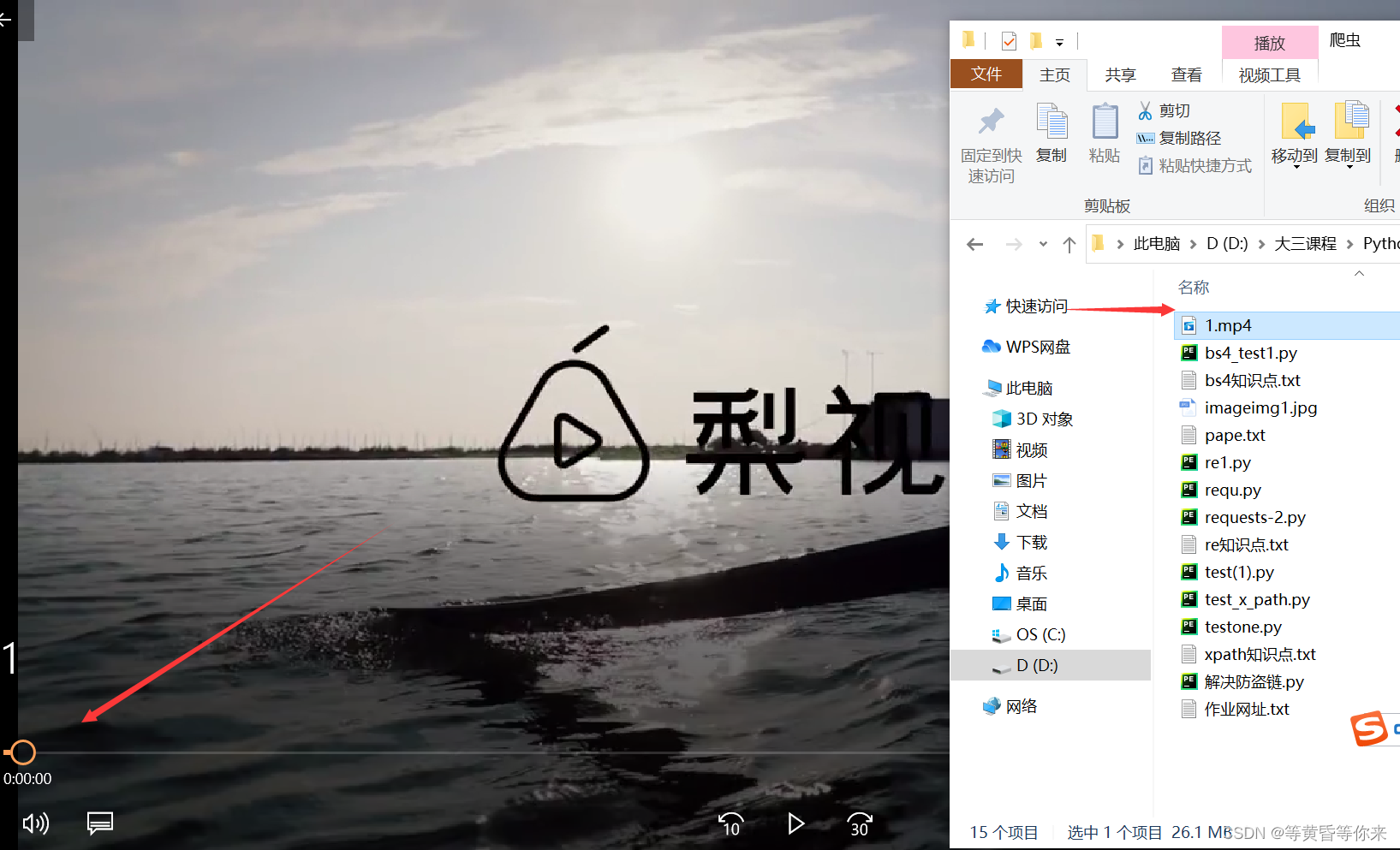
with open("1.mp4", mode="wb") as f:
f.write(requests.get(src_url).content)
if __name__ == '__main__':
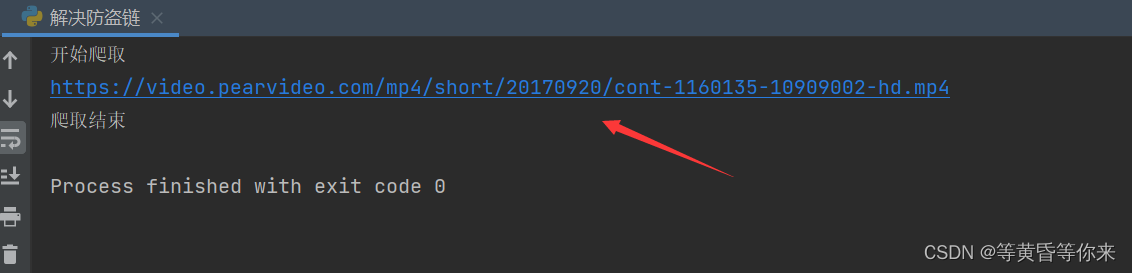
print("开始爬取")
down_src()
print("爬取结束")
四、结果
爬取到的链接可以播放,并且把该链接的内容保存到当前文件夹下(也可播放);

五、总结与改进
总结:
5.1、需要的内容不在页面源代码里怎么解决?
5.2、遇到防盗链怎么解决?
5.3、一次性爬取很多视频内容怎么解决呢(因为页面源代码没有这些链接)?
改进:
5.4、规范代码
5.5、爬取速度慢要解决

















 4097
4097

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









