







 该文章介绍了一个Python爬虫程序,利用XPath解析HTML和线程池技术,从指定小说网站抓取所有章节,并按顺序保存到本地TXT文件。程序首先获取章节标题和链接,然后在每个章节页面提取文本信息,最后通过线程池并行处理提高效率。
该文章介绍了一个Python爬虫程序,利用XPath解析HTML和线程池技术,从指定小说网站抓取所有章节,并按顺序保存到本地TXT文件。程序首先获取章节标题和链接,然后在每个章节页面提取文本信息,最后通过线程池并行处理提高效率。
目录
5. 在主函数中添加线程池,遍历字典输入标题和子链接开始多线程任务
前言
本来是想实现抓取番茄小说的,但是它虽然免费,当我写完全部代码的时候才发现后面的部分只能下载APP看,真是坑人......还好我把函数都封装了,整体逻辑是不变的,最终选择了另一个免费小说网——笔趣阁作为案例。
老规矩,我还是把链接放在评论区,不然审核不过的
同时我也会把番茄小说的放到最后的完整代码部分供大家借鉴。
目的
给定小说URL,使用Xpath+线程池实现抓取任意完整小说,并分章节按顺序保存到本地txt文件。
思路
思路其实很清晰:
1. 从给定的URL中拿到所有章节的标题和子链接
2. 将标题和子链接形成一个字典,便于后续提取信息
3. 实现在单个章节详细页面提取所有文本信息
4. 保存到本地文件,在前面加上数字序号便于顺序保存
5. 在主函数中添加线程池,遍历字典输入标题和子链接开始多线程任务
代码实现
详细的过程我就不在这里赘述了,之前讲过类似的案例:用异步法获取完整的一部小说
XPath也讲过的:XPath解析入门 实战:XPath法抓取某网站外包信息
小白可以先看上面几篇再看下面的代码会好懂一些。
1. 从给定的URL中拿到所有章节的标题和子链接
def get_chapter():
chap_cnt = 1
chapter_dic = {}
for i in range(1, 100):
new_url = novel_url + f'index_{i}.html'
resp = requests.get(new_url, headers=headers)
resp.encoding = 'gbk'
resp_parser = etree.HTML(resp.text)
if not resp_parser.xpath('/html/body/div[4]/dl/dd'):
break
chaps = resp_parser.xpath('/html/body/div[4]/dl/dd')
for chap in chaps:
if not chap.xpath("./a/@href"):
break
url = novel_url + chap.xpath("./a/@href")[0]
title = f'{chap_cnt}_' + chap.xpath("./a/text()")[0]
print(title) 2. 将标题和子链接形成一个字典,便于后续提取信息
chapter_dic[title] = url
chap_cnt += 1
return chapter_dic3. 实现在单个章节详细页面提取所有文本信息
def get_novel(title, url):
resp = requests.get(url, headers=headers)
resp.encoding = 'gbk'
novel = etree.HTML(resp.text)
title = title
content = novel.xpath('//*[@id="content"]//text()')4. 保存到本地文件,在前面加上数字序号便于顺序保存
if not os.path.exists('./7_Free_Novel_Folder'):
os.mkdir('./7_Free_Novel_Folder')
with open(f'./7_Free_Novel_Folder/{title}.txt', mode='a', encoding='gbk') as f:
for cont in content:
cont = cont.replace('\xa0', ' ')
f.write(cont + '\n')
print(title + '\t下载完成!')5. 在主函数中添加线程池,遍历字典输入标题和子链接开始多线程任务
def main():
chapter_dic = get_chapter()
# 创建线程池
with ThreadPoolExecutor(50) as t:
for chapter in chapter_dic:
t.submit(get_novel, title=chapter, url=chapter_dic[chapter])
# 等待线程池中的任务全部执行完毕
# get_novel('1', 'https://www.bbiquge.net/book/132573/55226877.html')
print("Clear!!!")
if __name__ == '__main__':
main()
完整源码
import requests
from lxml import etree
from concurrent.futures import ThreadPoolExecutor
import os
novel_url = '见评论区'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36 Edg/109.0.1518.61'
}
def get_chapter():
chap_cnt = 1
chapter_dic = {}
for i in range(1, 100):
new_url = novel_url + f'index_{i}.html'
resp = requests.get(new_url, headers=headers)
resp.encoding = 'gbk'
resp_parser = etree.HTML(resp.text)
if not resp_parser.xpath('/html/body/div[4]/dl/dd'):
break
chaps = resp_parser.xpath('/html/body/div[4]/dl/dd')
for chap in chaps:
if not chap.xpath("./a/@href"):
break
url = novel_url + chap.xpath("./a/@href")[0]
title = f'{chap_cnt}_' + chap.xpath("./a/text()")[0]
print(title)
chapter_dic[title] = url
chap_cnt += 1
return chapter_dic
def get_novel(title, url):
resp = requests.get(url, headers=headers)
resp.encoding = 'gbk'
novel = etree.HTML(resp.text)
title = title
content = novel.xpath('//*[@id="content"]//text()')
if not os.path.exists('./7_Free_Novel_Folder'):
os.mkdir('./7_Free_Novel_Folder')
with open(f'./7_Free_Novel_Folder/{title}.txt', mode='a', encoding='gbk') as f:
for cont in content:
cont = cont.replace('\xa0', ' ')
f.write(cont + '\n')
print(title + '\t下载完成!')
def main():
chapter_dic = get_chapter()
# 创建线程池
with ThreadPoolExecutor(50) as t:
for chapter in chapter_dic:
t.submit(get_novel, title=chapter, url=chapter_dic[chapter])
# 等待线程池中的任务全部执行完毕
# get_novel('1', 'https://www.bbiquge.net/book/132573/55226877.html')
print("Clear!!!")
if __name__ == '__main__':
main()
下面我把番茄小说的也放上来,整体逻辑真的是一模一样,所以同样也适用其他的小说网,都大同小异:
import requests
from lxml import etree
from concurrent.futures import ThreadPoolExecutor
import os
domain = '见评论区'
novel_url = '见评论区'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36 Edg/109.0.1518.61'
}
def get_chapter():
resp = requests.get(novel_url, headers=headers)
resp_parser = etree.HTML(resp.text)
modules = resp_parser.xpath('//div[@class="page-body"]/div[4]/div')
chapter_dic = {}
chap_cnt = 1
for module in modules:
chapters = module.xpath("./div[@class='chapter']/div")
for chapter in chapters:
url = domain + chapter.xpath("./a/@href")[0]
title = f'{chap_cnt}_' + chapter.xpath("./a/text()")[0]
chapter_dic[title] = url
chap_cnt += 1
return chapter_dic
def get_novel(title, url):
resp = requests.get(url, headers=headers)
novel = etree.HTML(resp.text)
title = title
content = novel.xpath('//div[@class="muye-reader-content noselect"]//text()')
if not os.path.exists('./7_Tomato_Novel_Folder'):
os.mkdir('./7_Tomato_Novel_Folder')
with open(f'./7_Tomato_Novel_Folder/{title}.txt', mode='a') as f:
for cont in content:
f.write(cont + '\n')
print(title + '\t下载完成!')
def main():
chapter_dic = get_chapter()
# 创建线程池
with ThreadPoolExecutor(50) as t:
for chapter in chapter_dic:
t.submit(get_novel, title=chapter, url=chapter_dic[chapter])
# 等待线程池中的任务全部执行完毕
print("Clear!!!")
if __name__ == '__main__':
main()
运行效果
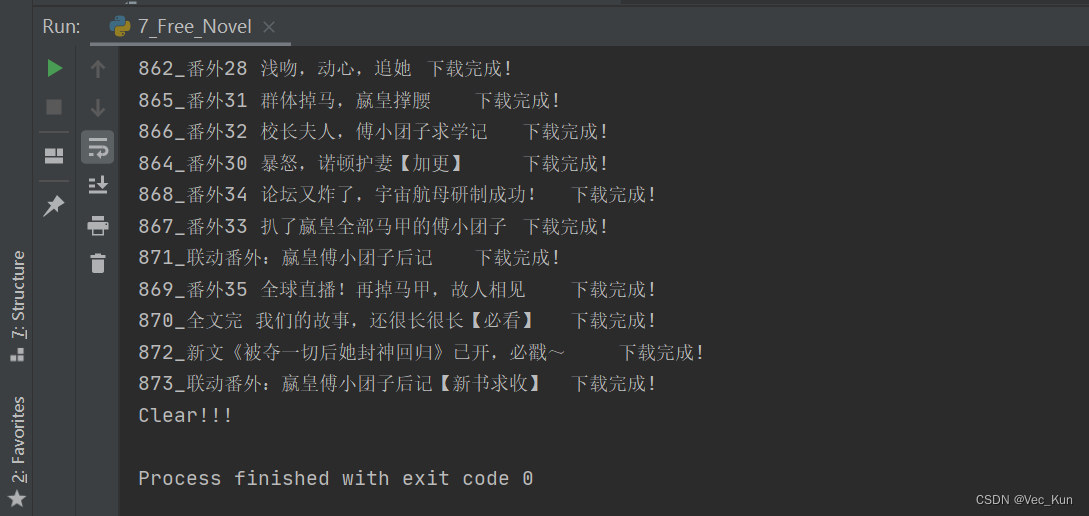
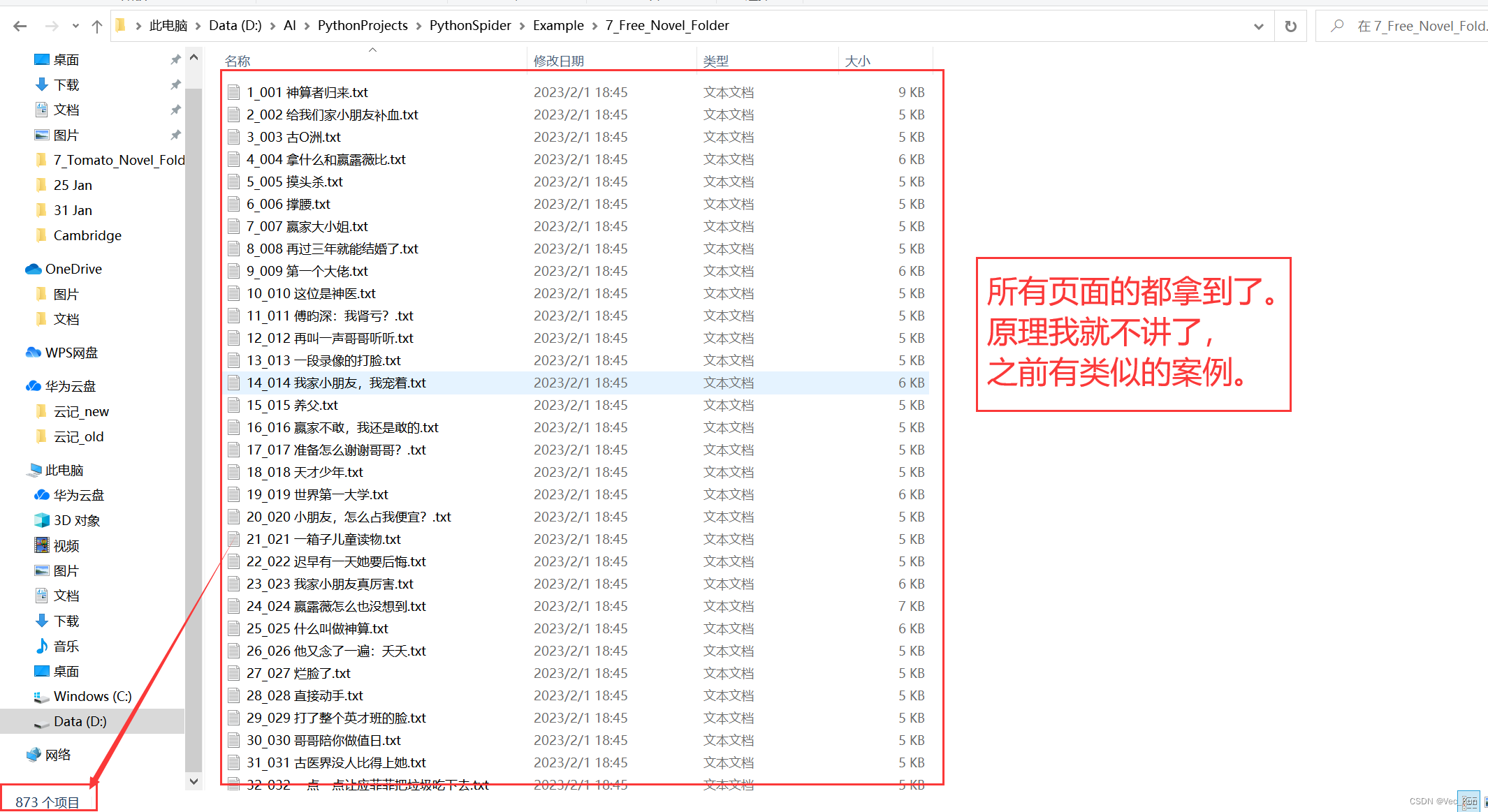
总结
本节实现了给定小说URL,使用Xpath+线程池实现抓取任意完整小说,并分章节按顺序保存到本地txt文件的任务。
如果想把所有小说放在同一个txt文件中只需要略微修改,把所有文本写到一个文件中遍历就好,相信看这篇文章的小伙伴有这个能力。如果想实现这个功能但是不会的也可以私信我,我帮你写一份。



















 16万+
16万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











