






ComfyUI 是一个基于节点的图形用户界面(GUI),可以做很多事情。比如最常见的就是用它来做AI绘画。

ComfyUI我是越来越喜欢了,LTX Video刚推出,ComfyUI立马就跟上了。只要更新到最新版本,直接原生支持,惬意啊!
LTXVideo是一个新出的视频生成模型。
这份完整版的AI绘画(SD、comfyui、AI视频)整合包已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

第一个基于 DiT 的视频生成模型,可以实时生成高质量的视频,它可以以 768x512 的分辨率生成 24 FPS 视频,比观看它们所需的速度更快。该模型在多样化视频的大规模数据集上进行训练,可以生成内容逼真多样的高分辨率视频。
今天的核心任务是,跟大家说一下如何使用ComfyUI和LTXVideo来生成视频。
在这个项目出来之前,要在本地玩转AI视频生成,生成的视频还能看,基本是一件不太敢想的事情。
而现在只要准备一张RTX3060 12G显卡即可!
关于硬件我就说这一点,下面直接进入主题了。
使用ComfyUI调用LTX Video模型生成视频,可以分为两种方案,我一次性说完。
第一种:使用ComfyUI官方支持
第二种:使用LTXVideo官方插件
ComfyUI官方支持
ComfyUI 现在有源代码版本和桌面版了。因为之前刚好写过两遍桌面版文章,我这里就以桌面版为例。
更新
只要打开桌面版软件,会自动跳出更新提示。点一下确认,然后就会自动更新了。
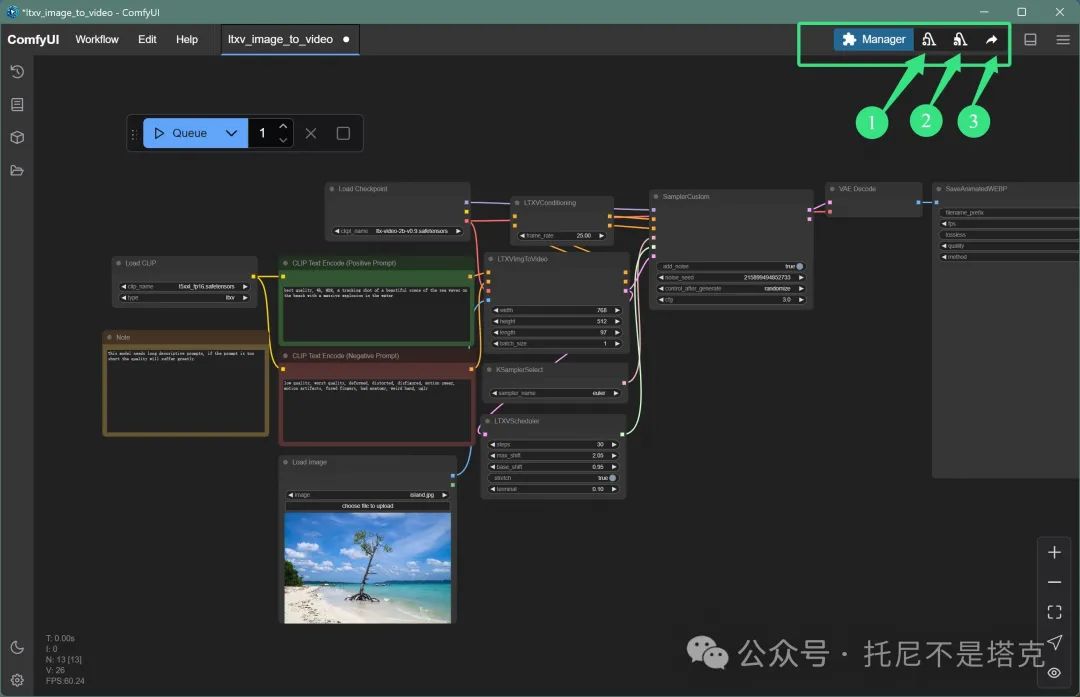
更新完重启一下就好了!
相比于之前的版本,更新完成之后右上角会有明显的变化。除了插件管理,之外还多了三个按钮。
1️⃣卸载模型
2️⃣清空模型和缓存
3️⃣分享流程图
软件更新完成之后,接下来就是下载模型,导入工作流,然后运行工作流。
下载模型
我们需要用到两个模型,一个是视频生成模型LTX-Video,一个是Clip模型。
这两个模型的完整名字如下:
Lightricks/LTX-Video
comfyanonymous/flux_text_encoders
可以根据模型名字直接去huggingface下载。我也会把所有模型放在网盘里,见文末。
flux_text_encoders里面只用到了t5xxl_fp16.safetensors 这个模型,所以可以只下载这一个。省点时间和空间!
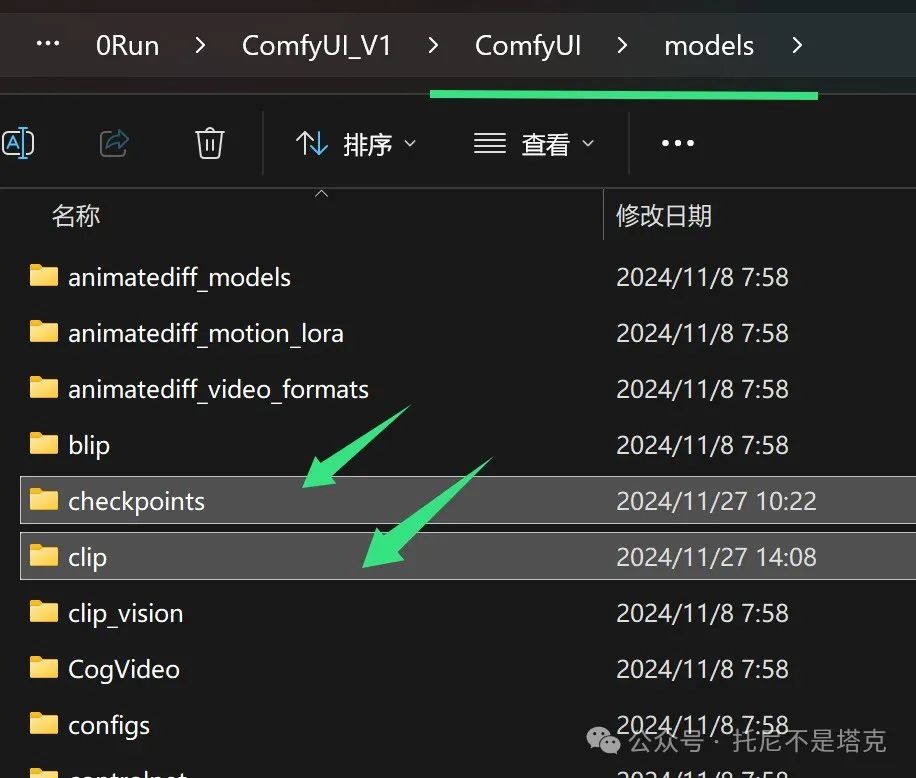
下载完成之后:
LTX里面的ltx-video-2b-v0.9.safetensors放到checkpoints文件夹。
flux_text_encoders里面的t5xxl_fp16.safetensors放到clip文件夹。
工作流
ComfyUI的演示页面中,有一个关于LTX Video例子,分享了两个工作流。
文生视频:ltxv_text_to_video.json
图生视频:ltxv_image_to_video.json
下载这两Json文件,直接把其中一个拖动到软件里面就可以了。
下面以图生视频为例,做一下说明。
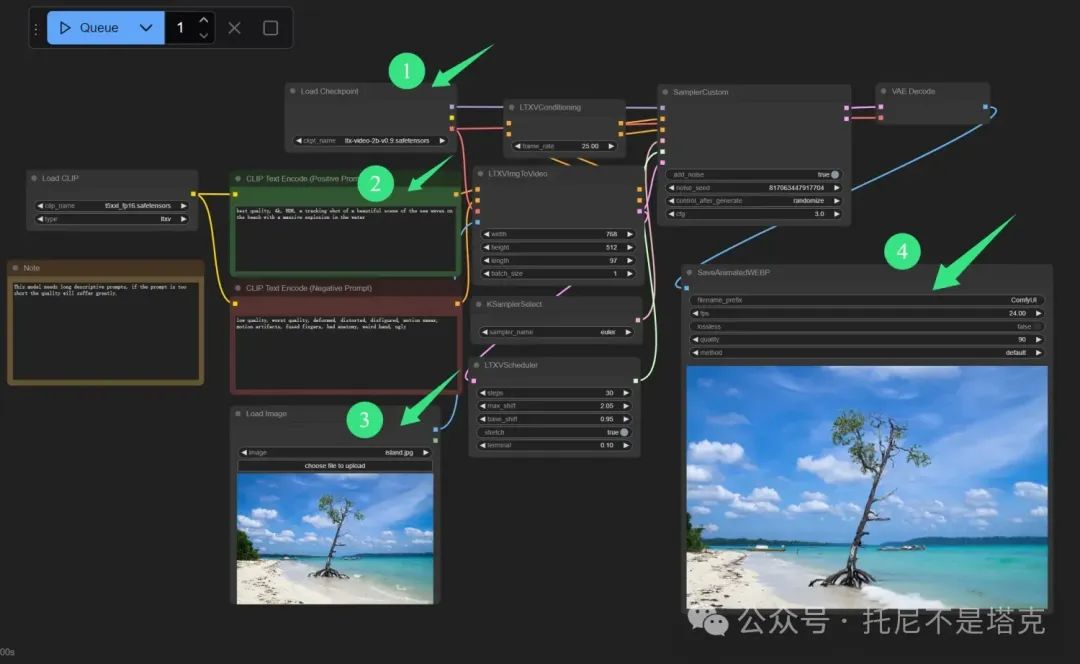
整个工作流有不少节点。但是只要调整或者关注其中四个就够了。
1️⃣选择视频模型
2️⃣输入文字描述
3️⃣选择参考图片
4️⃣查看视频结果
要生成其他主题的视频,只要修改提示词里面文字,以及参考图片就可以了。
运行
上面的工作都做好了,就可以生成视频了。
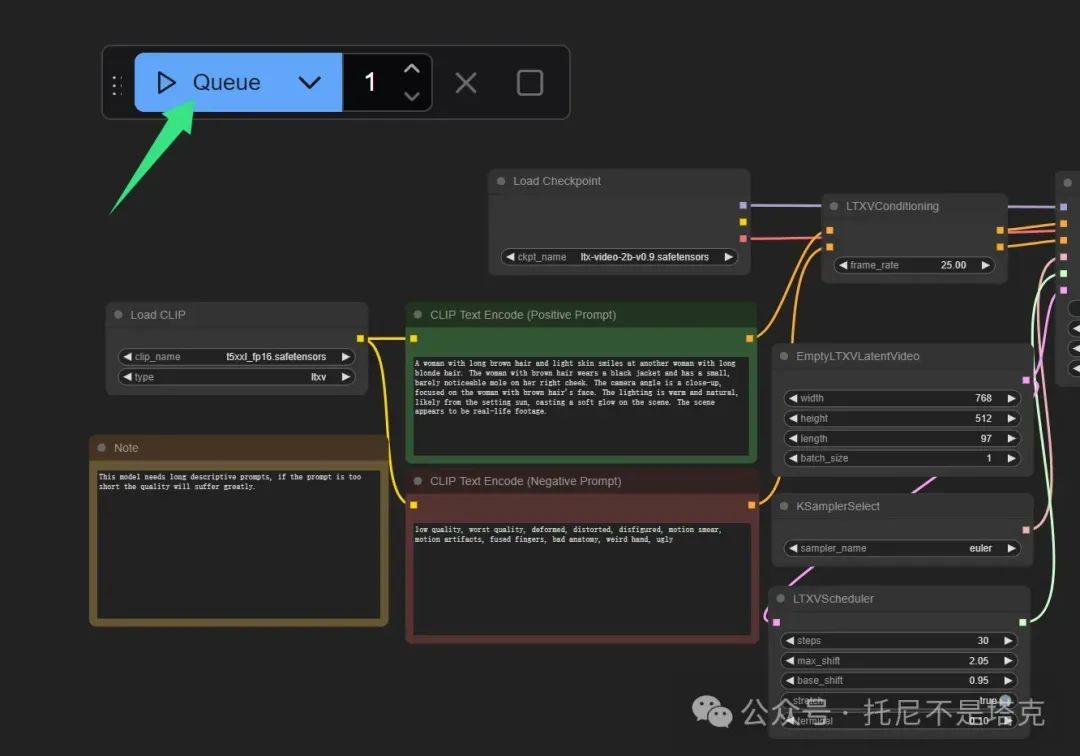
直接点击Queue按钮开始运行**。**首次运行会花费一些时间加载模型。加载完成之后就开始生成视频了,如果你显存足够,这个过程不会太久。
RTX3060上面大概66秒!
另外,你有可能会遇到如下错误。
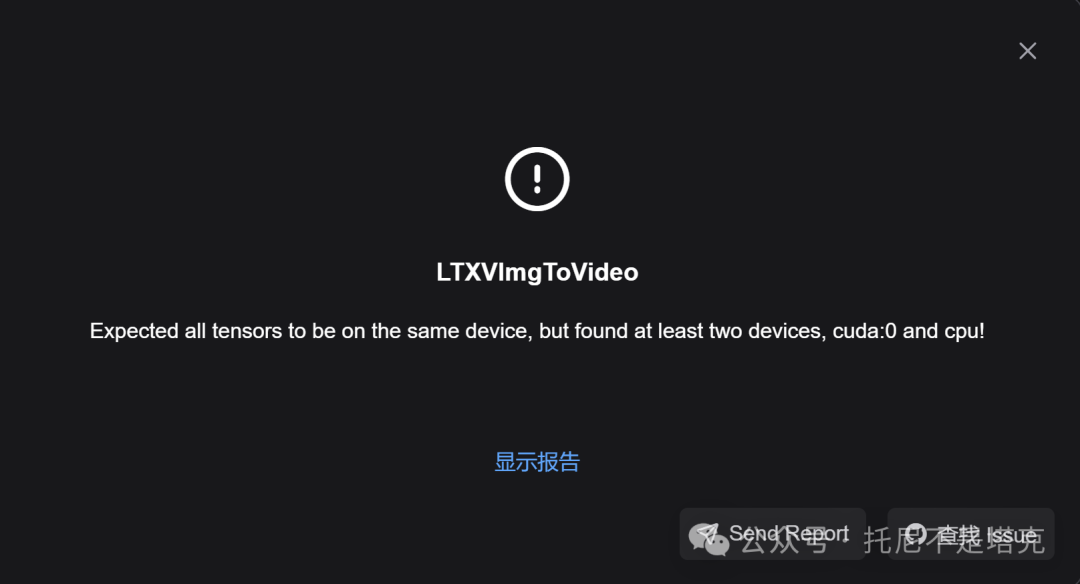
如果首次运行正常,多次运行出现这个提示。
那么,只要点击一下右上角的卸载模型按钮,就可以解决这个问题。
如果首次运行直接蹦出这个,那就就显存不够。
LTXVideo官方插件
LTXVideo除了发布模型之外,还专门制作了ComfyUI的插件。官方发布的插件自然是要用一下,下面就完整的演示下插件的安装和使用。
安装
LTXVideo官方插件,对ComfyUI来说属于第三方插件。所以需要安装一下。
安装很简单。只要点击右上角的插件管理图标。
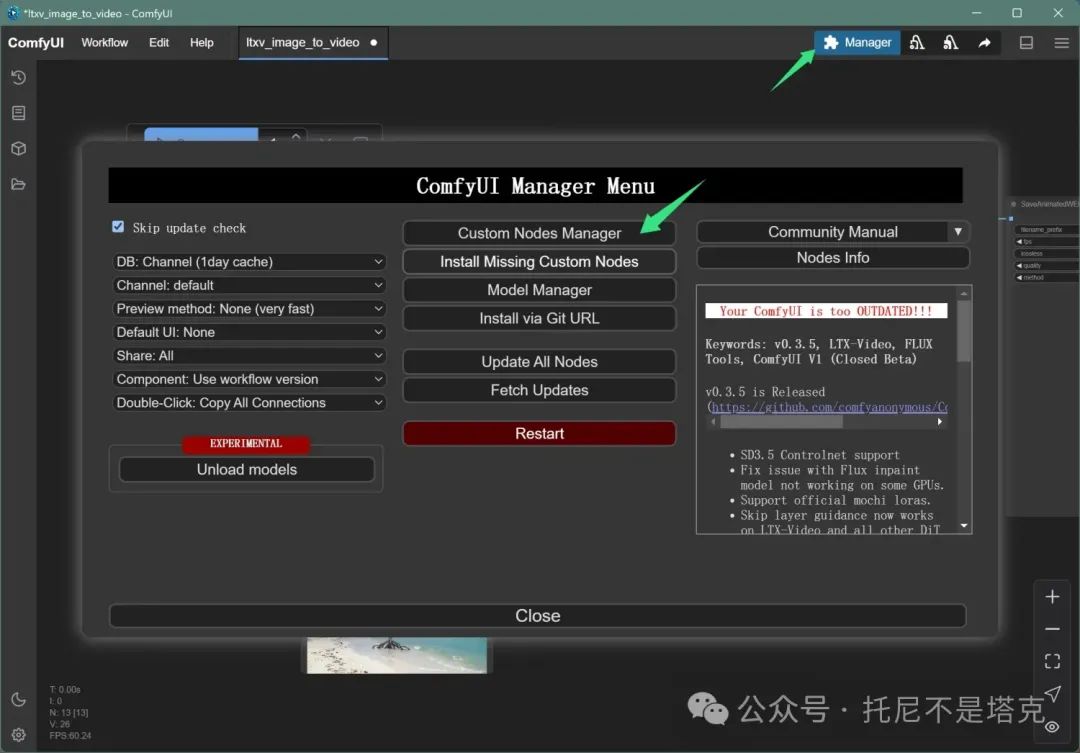
在弹出的窗口中输入ltx,根据搜索结果找到comfyUI-LTXVideo这个插件。点击Install进行安装。
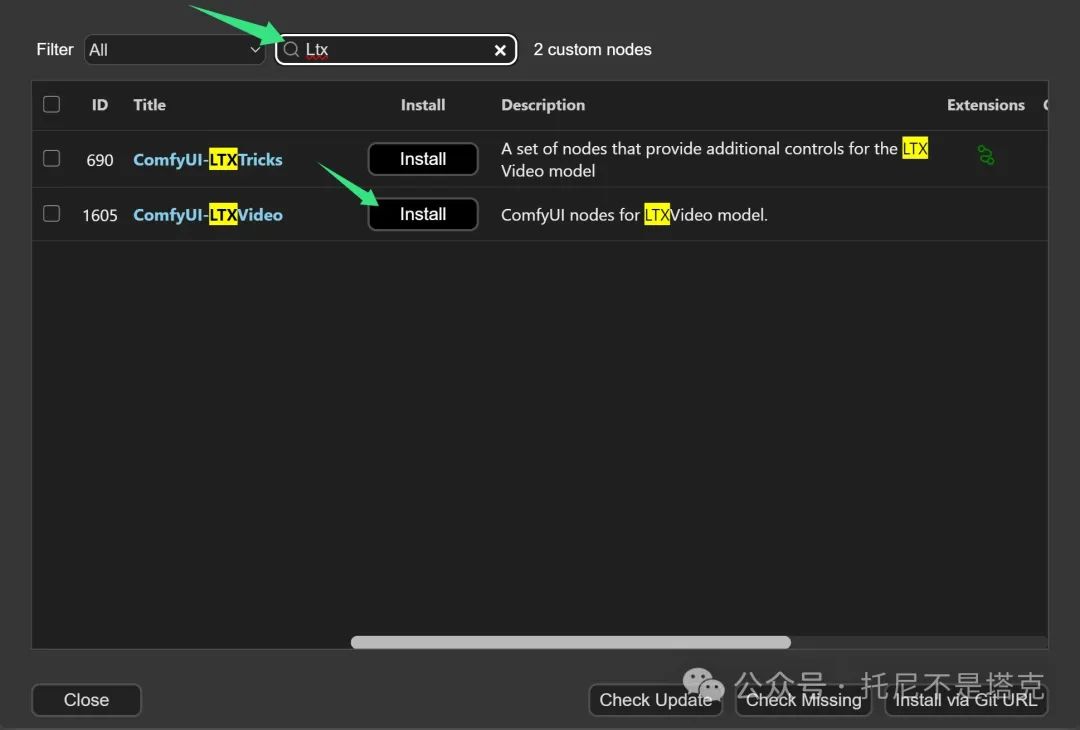
安装完成之后,会有红色的文字提示。提醒你需要重启软件!
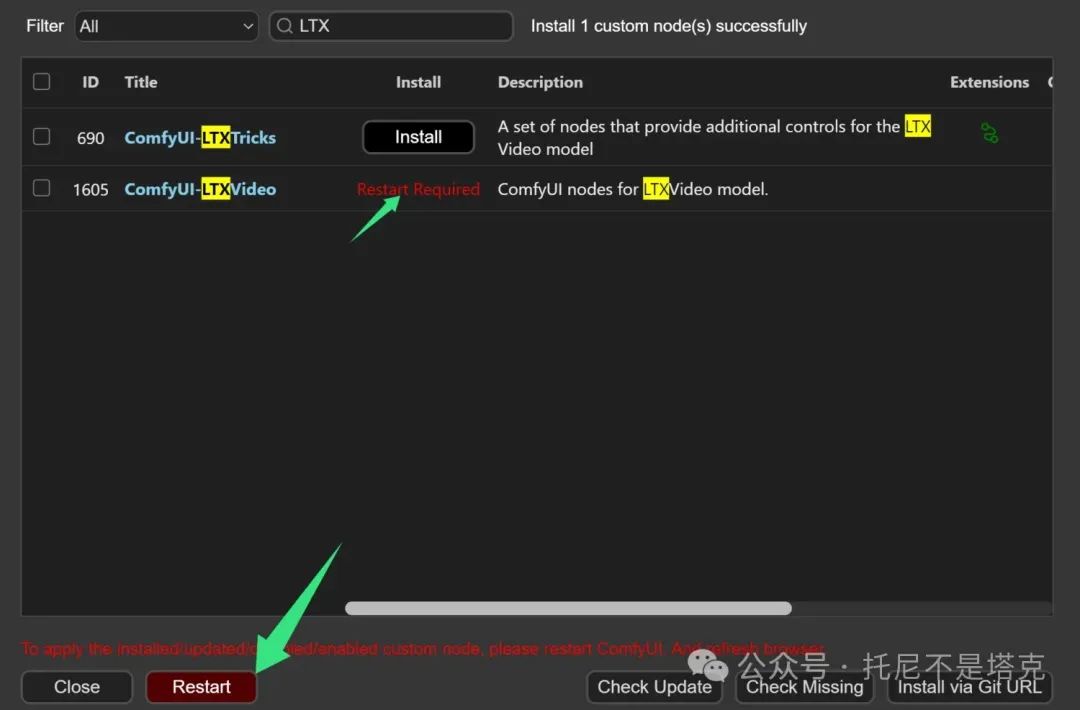
根据提示,点击Restart重启软件,然后插件就可以使用了。
另外,为了加载和合成视频,还需要用到一个辅助插件。
辅助插件的名字叫ComfyUI-VideoHelperSuite ,可以用同样的方式安装。
模型
LTXVideo官方的工作流,也是用到了两个模型。
分别是:
Lightricks/LTX-Video
PixArt-alpha/PixArt-XL-2-1024-MS
LTX-Video自然是主模型,上面也用到了,就不用多讲了。
PixArt是华为诺亚方舟实验室发布的项目,这是一个文生图的模型,直接拿来出图效果也不错。

我们这次的工作流里面主要是用了他的text_encoder。
同样可以去huggingface下载。
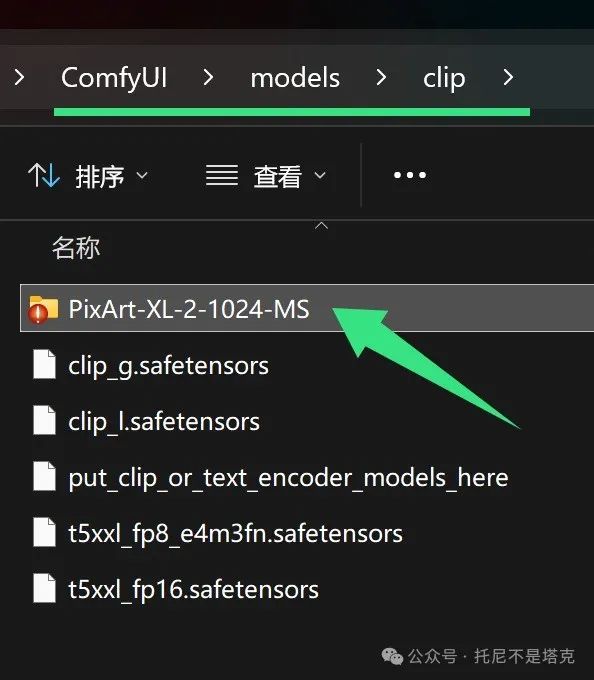
下载完成之后,将PixArt-XL-2-1024-MS这个文件夹整个放到Clip文件下面。
工作流
LTXVideo官方插件提供了三个工作流:
文生视频 ltxvideo-t2v.json
图生视频 ltxvideo-i2v.json
视频生视频 ltxvideo-v2v.json
下图为图生视频的工作流:
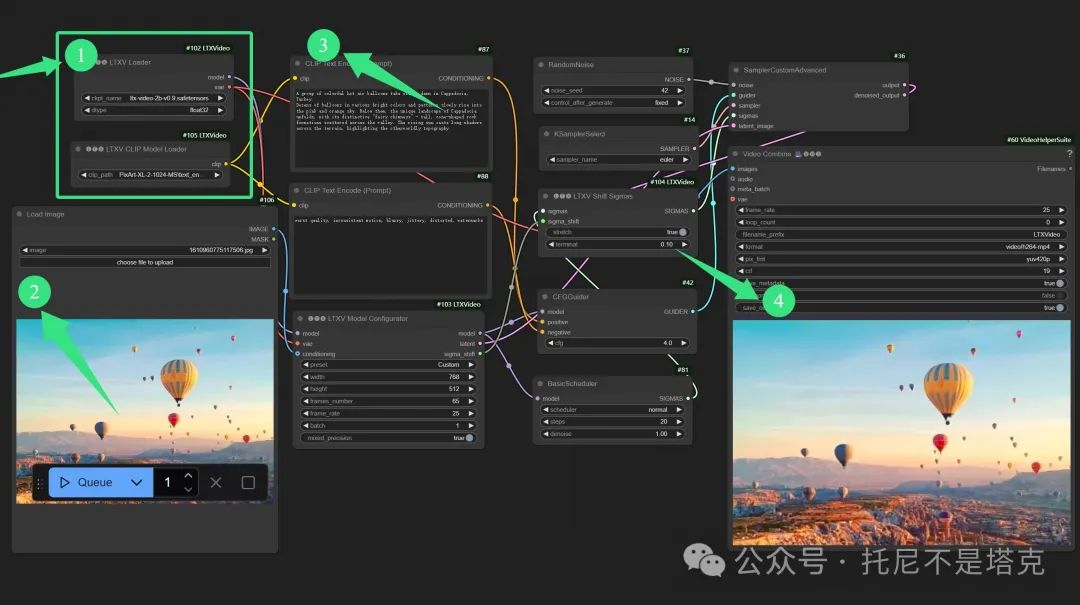
1️⃣选择模型
2️⃣选择图片
3️⃣输入文字
4️⃣查看结果
这里1️⃣里面需要注意下,必须手动选择一下LTXV CLIP Model。不选的话,直接运行会报错。
其他环节都很好理解了。
另外4️⃣是直接生成MP4格式,上一个流程图生成的是WEBP文件。
中间部分的参数:
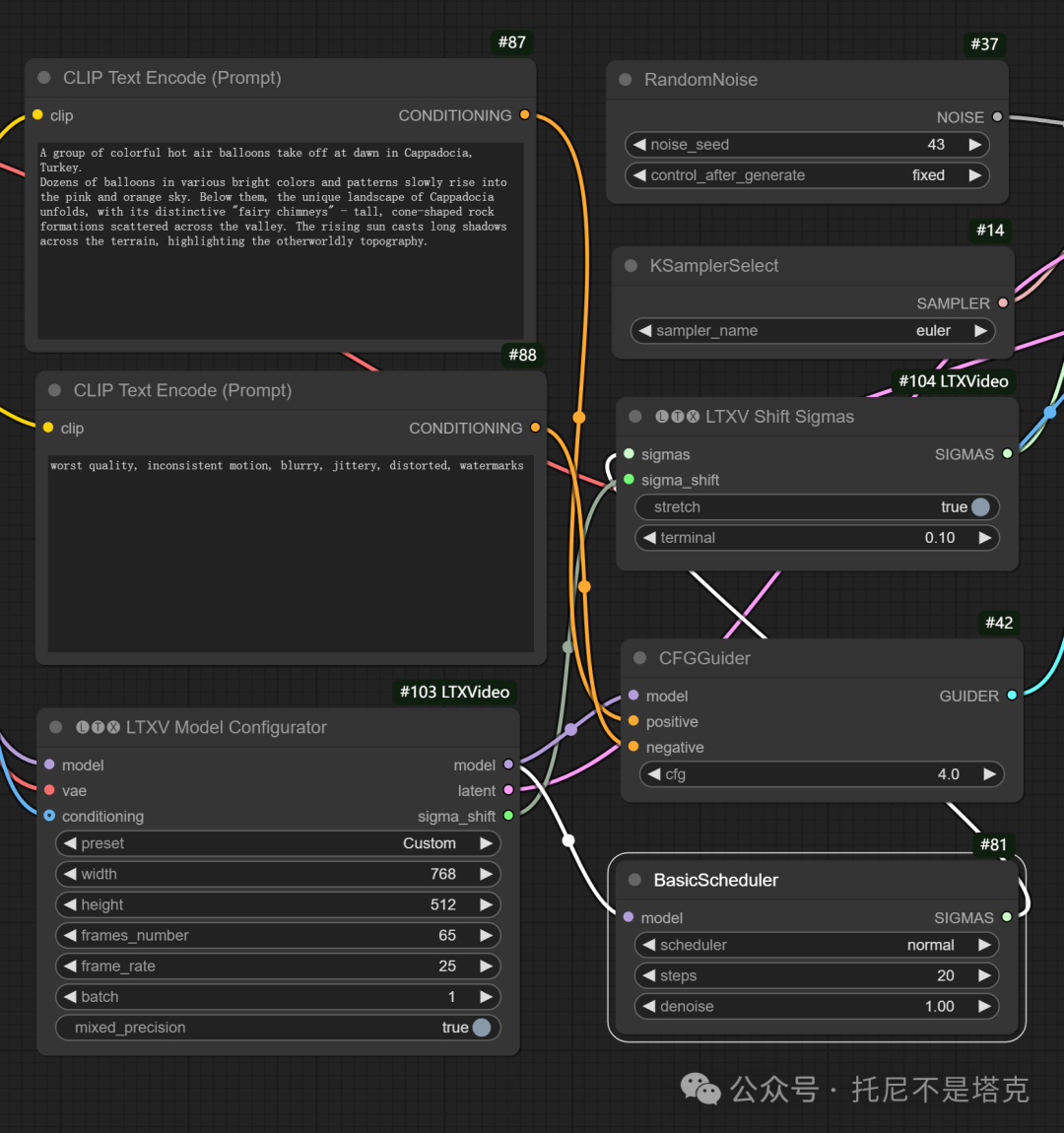
可以自己调整宽度(width),高度(height),长度(frames_number),帧率(frame_rate) 。
另外RandomNoise这里要注意下,默认是固定种子。种子没变的情况下,运行结果一样(其实完全不会运行)。
要用同样的内容,抽卡,就需要手动改这个种子。或者把fixed改成randomize。
其他东西没必要改,除非你知道为什么要改!
运行
万事俱备,运行就很简单了,点一下Queue等着就好了。
这样纯本地电脑生成视频的工作流就搞定了!
使用指南
最后上一下官方提供的提示词指南和参数指南。
提示工程指南(Prompt Engineering)
在编写提示时,注重对动作和场景的详细、按时间顺序的描述。包括具体的动作、外貌、镜头角度和环境细节,并将这些内容写成一个流畅的段落。直接从动作开始,确保描述准确、文字直白。想象自己是一位摄影指导在描述镜头清单。字数限制在200字以内。为了获得最佳效果,请按照以下结构组织提示:
-
以一句话概括主要动作
-
加入具体的动作和手势细节
-
精确描述角色/物体的外貌
-
包括背景和环境的细节
-
指定镜头角度和运动方式
-
描述光线和色彩
-
记录任何变化或突发事件
参数指南(Parameter Guide)
- 分辨率预设:
-
高分辨率适用于细节丰富的场景,低分辨率适用于快速生成或简单场景。
-
模型支持的分辨率应为32的倍数,帧数为8的倍数加1(例如257)。
-
如果分辨率或帧数不符合要求,输入将用-1填充,然后裁剪到所需分辨率和帧数。
-
模型最佳工作分辨率:不超过720 x 1280;帧数不超过257。
- 种子(Seed):
-
保存种子值以重现您喜欢的特定风格或构图。
- 引导尺度(Guidance Scale):
-
推荐值为3-3.5。
- 推理步数(Inference Steps):
- 更多步数(40+)提高质量,较少步数(20-30)提升速度。
总的来说,就是提示词要写得丰富一点,效果才会好。这个和图片生成的初级阶段差不多。模型理解理力还没有那么强的时候,就只能靠你耐心指导,循循善诱。
这份完整版的AI绘画(SD、comfyui、AI视频)整合包已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

















 4666
4666

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









