







网址URL
网址的组成分为: 协议(如http协议)、域名、pathname、querystring、hash组成。
由于TCP/IP协议,域名会被DNS解析为IP+Port(端口)
以百度的一条新闻网址为例具体说明:
www.baidu.com为域名,就是百度服务器的IP地址+访问端口
/s为pathname,访问的路径名
后面那一长串就是 querystring,用?号开头,查询字符串,是访问服务器传的参数。
这里没有hash,它是以#号开头,hash的数据不会传到后端。
url模块
url模块是我们下载node.js它所自带的模块,我们直接在js文件中直接导入即可使用,
var url=require("url")
这里的url是一个对象,我们运行js文件打印看一下它的结构。
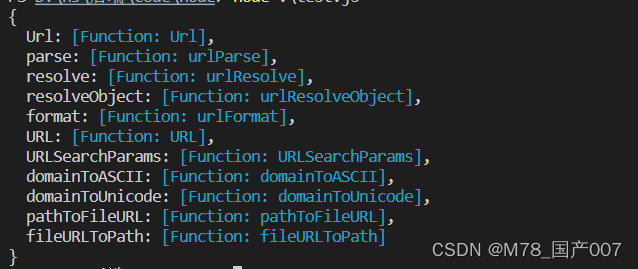
可以看到它对象属性是函数,我们在这里只学习它的parse()方法,其他的可以自行了解。
我们将上面那个百度新闻的网址传入parse()方法,打印看一下

可以看到这个方法,可以解析得到一个包括网址各个部分的对象,因为我们就可以对象点语法获取需要的部分数据。
具体操作,最后与querystring模块和mime模块一起展示。
querystring模块
我们导入的querystring模块也是一个对象,也有对象的各种方法,这里我们只学会parse()和stringify()这两个方法。
querystring.parse():可以将querystring字符串解析为一个对象,
如"name=zs&age=20"=>{name:"zs",age:"20"}
querystring.stringify(): 则是将对象解析为querystring字符串。
看到这里是不是觉得很熟悉,因为我们在之前学习JOSN字符串时,JOSN也有这两个方法,我们可以打印对比一下两者是否有区别:
const querystring=require("querystring")
var str2=querystring.stringify({name:"jack",age:20})
var str3=JSON.stringify({name:"jack",age:20})
console.log(str2,str3)终端结果:

可见完全不同的结果,大家可以区别记忆。
mime模块
这个模块是第三方模块,我们需要导入才能使用。
我们直接在npm官网搜mime,点击mime就可以看到如何安装即使用方法。
我们学习它的两个方法,getType()和getExtension()方法,
mime.getType(path):获取给定路径或扩展名的 mime 类型,例如"test.html"返回"text/html",我们就可以在解决在服务器端给客户端发送数据包时,不知道数据类型的问题。
直接代码展示:
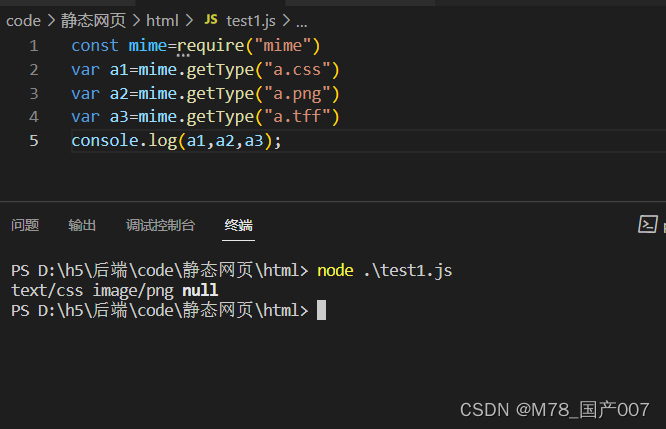
可以看到通过后缀名,它可以解析除对应的数据类型,当解析不到时返回空。
mime.getExtension(类型):获取给定 mime 类型的扩展名。
代码展示:
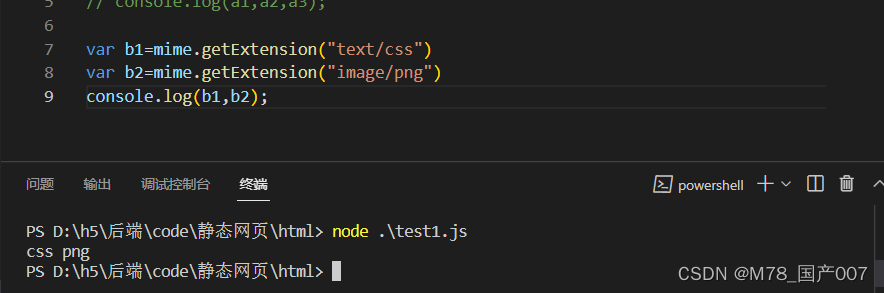
结合综上,练习实现静态网站。
专门建一个文件夹写项目,里面创建一个首页,一个第二页面,一个css文件设置页面样式,一个js文件当作服务器,一个img文件夹存放照片。
首页代码:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<link rel="stylesheet" href="./jtweb.css">
</head>
<body>
<h1>这是我的首页</h1>
<!-- 我们需要知道的是当服务器将这个html文档传回给客服端时,浏览器就开始加载,当遇到src和href时又会向该服务器发生网络请求 -->
<!-- 这里网络请求的路径相对网络路径,我们看到的是"./img/jj2.jpg" 但是实际上这里发生的是"localhost:8088/img/jj2.jpg" -->
<img src="./img/jj2.jpg" alt="">
<a href="./second.html">点击去往第二页</a>
</body>
</html>第二个页面:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<link rel="stylesheet" href="./jtweb.css">
</head>
<body>
<h1>
我是第二个页面
</h1>
<img src="./img/jj5.jfif" alt="">
</body>
</html>css文件:
img{
width: 300px;
}js文件:
const http=require("http")
const fs=require("fs")
const mime=require("mime")
const url=require("url")
const querystring=require("querystring")
const { fstat } = require("fs")
//创建服务器
var app=http.createServer((req,res)=>{
//req.url是获取浏览器地址栏用户输入的字符
//我们需要querystring参数的时
let querys=url.parse(req.url).query
var queryobj=querystring.parse(querys)
console.log(queryobj);
//可以有效解决网址中有querystring参数和hash值,req.url是取得是端口号后面的所有字符,而读文件时只需要访问字段
let path=url.parse(req.url).pathname
//优化用户在输入网址的时候不知道我们的首页访问地址,我们应该设置一下当访问地址为"/"时也能访问到首页
if(req.url=="/"){path="/jtweb.html"}
fs.readFile(__dirname+path,(err,data)=>{
if(!err){
//我们返回给客户端的数据包有时要指定数据格式,但是我们为了简洁方便,不可能给设置很多if elseif else语句,所以这里需要用到mime了
var type1=mime.getType(path)
res.setHeader("content-Type",type1)
res.end(data)
}else{
res.end("404 not found")
}
})
})
//绑定监听
app.listen(8088)到此这个简单的服务器功能就已经实现。















 1151
1151











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









