







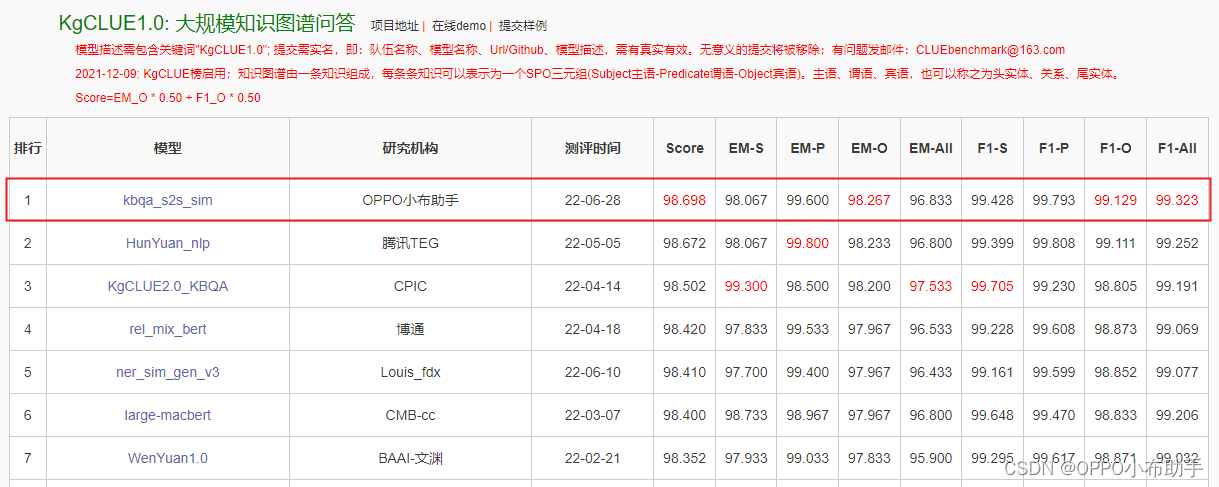
 OPPO小布助手团队推出十亿参数预训练模型OBERT,荣获KgCLUE1.0排行榜首。OBERT通过多种mask机制学习TB级语料,提升业务效果4%以上,参数量仅为百亿模型的1/10,展现大规模工业化潜力。
OPPO小布助手团队推出十亿参数预训练模型OBERT,荣获KgCLUE1.0排行榜首。OBERT通过多种mask机制学习TB级语料,提升业务效果4%以上,参数量仅为百亿模型的1/10,展现大规模工业化潜力。
大规模预训练模型的出现,为自然语言处理任务带来了新的求解范式,也显著地提升了各类NLP任务的基准效果。自2020年,OPPO小布助手团队开始对预训练模型进行探索和落地应用,从“可大规模工业化”的角度出发,先后自研了一亿、三亿和十亿参数量的预训练模型OBERT。
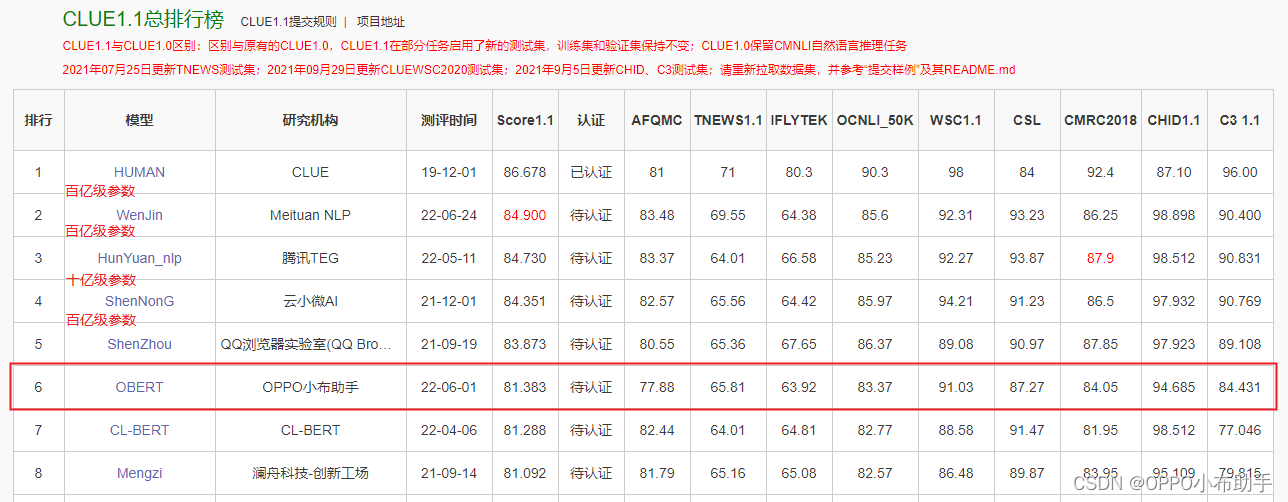
近期,OPPO小布助手团队和机器学习部联合完成了十亿参数模型“OBERT”的预训练,该模型通过5种mask机制从TB级语料中学习语言知识,在业务上取得了4%以上的提升;在行业对比评测中,OBERT跃居中文语言理解测评基准CLUE1.1总榜第五名、大规模知识图谱问答KgCLUE1.0排行榜第一名,在十亿级模型上进入第一梯队,多项子任务得分与排前3名的百亿参数模型效果非常接近,而参数量仅为后者的十分之一,更有利于大规模工业化应用。
背景
随着NLP领域预训练技术的快速发展,“预训练+微调”逐渐成为解决意图识别等问题的新范式,经过小布助手团队前期的探索和尝试,在百科技能分类、闲聊语义匹配、阅读理解答案抽取、FAQ精排等场景已经上线了自研一亿级模型并取得了显著的收益,并仍有提升的空间,验证了进一步自研十亿级模型并推广落地的必要性。
小布助手场景涉及意图理解、多轮聊天、文本匹配等NLP任务,结合工作[6,14]的经验,小布助手团队预训练到业务落地会按图3所示的方式进行,包括Pretraining、Futher-Pretraing、Fine-tuning&Deployment等阶段。主要有四个特点:
一是表征解耦,统一表征器适配不同下游任务,可以同时满足下游理解类任务和多轮聊天生成任务,更好地满足小布助手丰富的应用场景;
二是检索增强,检索对象包括知识图谱,以及目标任务相关的通用文本片段等;
三是多阶段,从数据、任务的维度逐步适应目标场景进行训练,平衡自监督训练和下游效果,定向获取目标场景相关的无监督、弱监督语料数据,进行进一步预训练调优;
四是模型量级以一亿、三亿、十亿级为主,更友好地支持大规模应用落地。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









