







top
top 命令用于查看进程动态信息
格式:
top [-] [选项] [...]
| 参数 | 含义 |
|---|---|
| d | 改变显示的更新速度 |
| c | 显示整个命令行而不只是显示命令名 |
| p | 通过指定 PID 来监控某个进程的状态 |
| S | 累积模式,会将己完成或消失的子行程的 CPU time 累积起来 |
| s | 安全模式,将交互式指令取消, 避免潜在的危机 |
| i | 不显示任何闲置或者僵死进程 |
| n | 更新的次数,完成后将会退出 top |
示例:
#显示进程信息
top
#显示所有 CPU
top + 1
#显示完整命令
top -c
#以批处理模式显示程序信息
top -b
#以累积模式显示程序信息
top -S
#设置信息更新次数,更新两次后终止更新显示
top -n 2
#设置信息更新时间,更新周期为3秒
top -d 3
#显示指定的进程信息
top -p PID
#使用者将不能利用交谈式指令来对行程下命令
top -s
#按照内存占用从大到小排序
top -o %MEM
#按照CPU占用从大到小排序
top -o %CPU
ps
ps(process status)命令用于显示当前进程的状态
格式:
ps [options] [--help]
| 参数 | 含义 |
|---|---|
| -a | 显示当前终端下的所有进程信息,包括其他用户的进程。与“x”选项结合时将显示系统中所有的进程信息 |
| -u | 使用以用户为主的格式输出进程信息 |
| -x | 显示当前用户在所有终端下的进程信息 |
| -e | 显示所有进程 |
| -f | 使用完整的格式显示进程信息 |
| -l | 使用长格式显示进程信息 |
常用组合:
ps [-aux] [-ef] [-elf]
示例:
[root@c7-1 ~]#ps -aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.1 191004 3916 ? Ss 10:53 0:03 /usr/lib/systemd/systemd --switched-root --system --deserialize 22
root 2 0.0 0.0 0 0 ? S 10:53 0:00 [kthreadd]
root 4 0.0 0.0 0 0 ? S< 10:53 0:00 [kworker/0:0H]
root 5 0.0 0.0 0 0 ? S 10:53 0:01 [kworker/u256:0]
......
#上述输出信息中,第一行为列表标题,其中各字段的含义描述如下
USER:启动该进程的用户账号的名称
PID:该进程在系统中的数字 ID 号,在当前系统中是唯一的
%CPU:CPU 占用的百分比
%MEM:内存占用的百分比
VSZ:该进程使用的虚拟内存量(KB)
RSS:该进程占用的物理内存量(KB)
TTY:表明该进程在哪个终端上运行。不是从终端启动的进程则显示为?
STAT:该进程的状态
START:启动该进程的时间
TIME:该进程占用的 CPU 时间
COMMAND:启动该进程的命令的名称
#STAT 状态类型
-D:不可被唤醒的睡眠状态,通常用于 I/O 情况
-R:该进程正在运行
-S:该进程处于睡眠状态,可被唤醒
-T:停止状态,可能是在后台暂停或进程处于除错状态
-W:内存交互状态(从 2.6 内核开始无效)
-X:死掉的进程(通常不会出现)
-Z:僵尸进程。进程已经中止,但是部分程序还在内存当中
-<:高优先级(以下状态在 BSD 格式中出现)
-N:低优先级
-L:被锁入内存
-s:包含子进程
-l:多线程
-+:位于后台
-C:进程占用 CPU 的百分比
[root@c7-1 ~]#ps -elf
F S UID PID PPID C PRI NI ADDR SZ WCHAN STIME TTY TIME CMD
4 S root 1 0 0 80 0 - 47751 ep_pol 10:53 ? 00:00:03 /usr/lib/systemd/systemd --switched-root --system --deserialize 22
1 S root 2 0 0 80 0 - 0 kthrea 10:53 ? 00:00:00 [kthreadd]
1 S root 4 2 0 60 -20 - 0 worker 10:53 ? 00:00:00 [kworker/0:0H]
1 S root 5 2 0 80 0 - 0 worker 10:53 ? 00:00:01 [kworker/u256:0]
1 S root 6 2 0 80 0 - 0 smpboo 10:53 ? 00:00:00 [ksoftirqd/0]
......
#各列标题含义
F:内核分配给进程的系统标记
S:进程的状态
UID:启动这些进程的用户
PID:进程的进程 ID
PPID:父进程的进程号(如果该进程是由另一个进程启动的)
C:进程生命周期中的 CPU 利用率
PRI:进程的优先级(越大的数字代表越低的优先级)
NI:谦让度值用来参与决定优先级
ADDR:进程的内存地址
SZ:假如进程被换出,所需交换空间的大致大小
WCHAN:若该进程在睡眠,则显示睡眠中的系统函数名
STIME:进程启动时的系统时间
TTY:进程启动时的终端设备(pts 代表虚拟终端,一般是远程连接的终端;tty 代表本地控制台终端)
TIME:运行进程需要的累计CPU时间
CMD:进程的启动命令
#指定属性排序,CentOS6 以下版本不支持
ps axo pid,cmd,%cpu,%mem k -%cpu
#按内存倒序排序
ps axo pid,cmd,%cpu,%mem --sort -%mem
#使用watch实用程序执行重复的输出以实现对就程进行实时的监视,如下面的命令显示每秒钟的监视
watch -n 1 'ps -eo pid,ppid,cmd,%mem,%cpu --sort=-%mem | head'
#查看僵尸进程
ps -A -o stat,ppid,pid,cmd | grep -e '^[Zz]'
#查找僵死进程,然后将父进程杀死
ps -A -o stat,ppid,pid,cmd | grep -e '^[Zz]' | awk '{print $2}' | xargs kill -9
uptime
系统负载查询
格式:
uptime [options]
| 参数 | 选项 |
|---|---|
| -p | 显示系统运行了多长时间 |
| -s | 显示系统启动的日期/时间 |
示例:
[root@tengxun-02 ~]#uptime
00:04:06 up 222 days, 13:16, 1 user, load average: 0.05, 0.09, 0.07
#每一栏含义
系统当前时间
up 表示系统正在运行
222 days 在这期间系统没有重启过
当前上线人数
系统负载:1、5、15 分钟的平均负载,单核一般不会超过 1,单核超过 5 时建议警报
[root@tengxun-02 ~]#uptime -p
up 31 weeks, 5 days, 13 hours, 17 minutes
[root@tengxun-02 ~]#uptime -s
2021-12-29 10:47:25
vmstat
vmstat (Virtual Memory Statistics 虚拟内存统计) 命令用来显示 Linux 系统虚拟内存状态,也可以报告关于进程、内存、I/O 等系统整体运行状态。一般 vmstat 工具的使用是通过两个数字参数来完成的,第一个参数是采样的时间间隔数,单位是秒,第二个参数是采样的次数,例如:vmstat 2 2
安装
yum install -y sysstat
用法
vmstat [-a] [-n] [-t] [-S unit] [delay [ count]]
vmstat [-s] [-n] [-S unit]
vmstat [-m] [-n] [delay [ count]]
vmstat [-d] [-n] [delay [ count]]
vmstat [-p disk partition] [-n] [delay [ count]]
vmstat [-f]
vmstat [-V]
| 参数 | 选项 |
|---|---|
| -a: | 显示活跃和非活跃内存 |
| -f: | 显示从系统启动至今的 fork 数量 |
| -m: | 显示 slabinfo |
| -n: | 只在开始时显示一次各字段名称 |
| -s: | 显示内存相关统计信息及多种系统活动数量 |
| delay: | 刷新时间间隔。如果不指定,只显示一条结果 |
| count: | 刷新次数。如果不指定刷新次数,但指定了刷新时间间隔,这时刷新次数为无穷 |
| -d: | 显示磁盘相关统计信息 |
| -p: | 显示指定磁盘分区统计信息 |
| -S: | 使用指定单位显示。参数有 k 、K 、m 、M,分别代表 1000、1024、1000000、1048576 字节(byte)。默认单位为 K(1024 bytes) |
| -V: | 显示 vmstat 版本信息 |
示例
[root@tengxun-02 ~]#vmstat
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 0 276344 156392 2901680 0 0 1 16 0 1 0 0 99 0 0
[root@tengxun-02 ~]#vmstat 1 3
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 0 268416 156396 2907696 0 0 1 16 0 0 0 0 99 0 0
0 0 0 267492 156396 2907704 0 0 0 488 4329 8864 7 5 87 2 0
0 0 0 266428 156396 2907708 0 0 0 144 2549 4893 2 2 96 0 0
说明
| 类别 | 项目 | 含义 | 说明 |
|---|---|---|---|
| procs | r | 等待执行的任务数 | 展示了正在执行和等待cpu资源的任务个数。当这个值超过了cpu个数,就会出现cpu瓶颈。 |
| procs | b | 等待IO的进程数量 | |
| memory | swpd | 正在使用虚拟的内存大小,单位k | |
| memory | free | 空闲内存大小 | |
| memory | buff | 已用的buff大小,对块设备的读写进行缓冲 | |
| memory | cache | 已用的cache大小,文件系统的cache | |
| memory | inact | 非活跃内存大小,即被标明可回收的内存,区别于free和active | 具体含义见:概念补充(当使用-a选项时显示) |
| memory | active | 活跃的内存大小 | 具体含义见:概念补充(当使用-a选项时显示) |
| Swap | si | 每秒从交换区写入内存的大小(单位:kb/s) | |
| Swap | so | 每秒从内存写到交换区的大小 | |
| IO | bi | 每秒读取的块数(读磁盘) | 块设备每秒接收的块数量,单位是block,这里的块设备是指系统上所有的磁盘和其他块设备,现在的Linux版本块的大小为1024bytes |
| IO | bo | 每秒写入的块数(写磁盘) | 块设备每秒发送的块数量,单位是block |
| system | in | 每秒中断数,包括时钟中断 | 这两个值越大,会看到由内核消耗的cpu时间sy会越多 |
| system | cs | 每秒上下文切换数 | 每秒上下文切换次数,例如我们调用系统函数,就要进行上下文切换,线程的切换,也要进程上下文切换,这个值要越小越好,太大了,要考虑调低线程或者进程的数目 |
| CPU | us | 用户进程执行消耗cpu时间(user time) | us的值比较高时,说明用户进程消耗的cpu时间多,但是如果长期超过50%的使用,那么我们就该考虑优化程序算法或其他措施了 |
| CPU | sy | 系统进程消耗cpu时间(system time) | sys的值过高时,说明系统内核消耗的cpu资源多,这个不是良性的表现,我们应该检查原因。这里us + sy的参考值为80%,如果us+sy 大于 80%说明可能存在CPU不足 |
| CPU | Id | 空闲时间(包括IO等待时间) | 一般来说 us+sy+id=100 |
| CPU | wa | 等待IO时间 | wa过高时,说明io等待比较严重,这可能是由于磁盘大量随机访问造成的,也有可能是磁盘的带宽出现瓶颈。 |
| CPU | st | 来自于虚拟机偷取的CPU所占的百分比 |
iostat
iostat 是 I/O statistics(输入/输出统计)的缩写,iostat 工具将对系统的磁盘操作活动进行监视。它的特点是汇报磁盘活动统计情况,同时也会汇报出 CPU 使用情况。iostat 也有一个弱点,就是它不能对某个进程进行深入分析,仅对系统的整体情况进行分析。
[root@tengxun-02 ~]#yum install sysstat -y
......
[root@tengxun-02 ~]#iostat
Linux 3.10.0-1160.11.1.el7.x86_64 (tengxun-02) 08/09/2022 _x86_64_ (2 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
0.40 0.00 0.42 0.07 0.00 99.12
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
vda 3.50 1.78 31.81 34363446 614326717
scd0 0.00 0.00 0.00 854 0
说明
%user:CPU处在用户模式下的时间百分比
%nice:CPU处在带NICE值的用户模式下的时间百分比
%system:CPU处在系统模式下的时间百分比
%iowait:CPU等待输入输出完成时间的百分比
%steal:管理程序维护另一个虚拟处理器时,虚拟CPU的无意识等待时间百分比
%idle:CPU空闲时间百分比
tps:该设备每秒的传输次数
kB_read/s:每秒从设备(drive expressed)读取的数据量
kB_wrtn/s:每秒向设备(drive expressed)写入的数据量
kB_read:读取的总数据量
kB_wrtn:写入的总数量数据量
#--------------------------------------------------------
如果%iowait的值过高,表示硬盘存在I/O瓶颈
如果%idle值高,表示CPU较空闲
如果%idle值高但系统响应慢时,可能是CPU等待分配内存,应加大内存容量。
如果%idle值持续低于cpu核数,表明CPU处理能力相对较低,系统中最需要解决的资源是CPU。
示例
# 每隔 2 秒刷新显示,且显示 3 次
iostat 2 3
# 显示指定磁盘信息
iostat -d /dev/sda
# 显示 tty 和 cpu 信息
iostat -t
# 以 M 为单位显示所有信息
iostat -m
# 查看设备使用率(%util)、响应时间(await)
# -d 显示磁盘使用情况,-x 显示详细信息
iostat -d -x -k 1 1
# 查看 cpu 状态
iostat -c 1 1
iotop
iotop 是一款开源、免费的用来监控磁盘 I/O 使用状况的类似 top 命令的工具,iotop 可以监控进程的 I/O 信息。它是 Python 语言编写的,与 iostat 工具比较,iostat 是系统级别的 IO 监控,而 iotop 是进程级别 IO 监控。官方网址:http://guichaz.free.fr/iotop/
[root@tengxun-02 ~]#yum -y install iotop
......
[root@tengxun-02 ~]#iotop --help
......
[root@tengxun-02 ~]#iotop
Total DISK READ : 0.00 B/s | Total DISK WRITE : 0.00 B/s
Actual DISK READ: 0.00 B/s | Actual DISK WRITE: 0.00 B/s
TID PRIO USER DISK READ DISK WRITE SWAPIN IO> COMMAND
1 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % systemd --switched-~em --deserialize 22
2 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [kthreadd]
4 be/0 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [kworker/0:0H]
6 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [ksoftirqd/0]
7 rt/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [migration/0]
8 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [rcu_bh]
9 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [rcu_sched]
10 be/0 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [lru-add-drain]
11 rt/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [watchdog/0]
12 rt/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [watchdog/1]
......
......
| 参数 | 长参数 | 参数描述 |
|---|---|---|
| –version | 显示版本号 | |
| -h | –help | 显示帮助信息 |
| -o | –only | 只显示正在产生I/O的进程或线程,运行过程中,可以通过按o随时切换 |
| -b | –batch | 非交互模式下运行,一般用来记录日志。 |
| -n | NUM –iter=NUM | 设置监控(显示)NUM次,主要用于非交互模式。默认无限 |
| -d | SEC –delay=SEC | 设置显示的间隔秒数,支持非整数 |
| -p | PID –pid=PID | 只显示指定进程(PID)的信息 |
| -u | USER –user=USER | 显示指定的用户的进程的信息 |
| -P | –processes | 只显示进程,不显示所有线程 |
| -a | –accumulated | 累积的I/O,显示从iotop启动后每个进程累积的I/O总数,便于诊断问题 |
| -k | –kilobytes | 显示使用KB单位 |
| -t | –time | 非交互模式下,加上时间戳。 |
| -q | –quiet | 只在第一次监测时显示列名. 去除头部一些行:这个参数可以设置最多3次来移除头部行:-q列头部只在最初交互显示一次;-qq列头部不显示;-qqq,I/O的总结不显示 |
快捷键
r:反向排序
o:切换至选项--only
p:切换至--processes选项
a:切换至--accumulated选项
q:退出
i:改变线程的优先级
示例
# 只显示正在产生I/O的进程
iotop -o
# 使用非交互模式将iotop命令输出信息写入日志
nohup iotop -b -o -n 10 -d 5 -t > /tmp/iotop.log &
# 借助iotop命令找到消耗I/O最高的进程,然后通过进程找到其正在执行的SQL语句
iotop -oP
# 压力测试
dd if=/dev/zero of=/home/1.txt count=1024 bs=1G
iotop -o
slabtop
slabtop 实时显示详细的内核slab缓冲区的细节信息。
[root@tengxun-02 ~]#yum install procps-ng
......
[root@tengxun-02 ~]#slabtop
Active / Total Objects (% used) : 1217601 / 1359715 (89.5%)
Active / Total Slabs (% used) : 51359 / 51359 (100.0%)
Active / Total Caches (% used) : 91 / 114 (79.8%)
Active / Total Size (% used) : 249784.67K / 292796.38K (85.3%)
Minimum / Average / Maximum Object : 0.01K / 0.21K / 8.00K
OBJS ACTIVE USE OBJ SIZE SLABS OBJ/SLAB CACHE SIZE NAME
506688 469182 92% 0.19K 24128 21 96512K dentry
432315 391055 90% 0.10K 11085 39 44340K buffer_head
100416 99049 98% 0.06K 1569 64 6276K kmalloc-64
79792 55006 68% 1.00K 4987 16 79792K ext4_inode_cache
43918 36938 84% 0.57K 3137 14 25096K radix_tree_node
......
参数
--delay=n | -d n:每n秒更新一次显示的信息,默认是每3秒
--sort=S | -s S:指定排序标准进行排序(排序标准,参照下面或者man手册)
--once | -o:显示一次后退出
--version | -V:显示版本
--help:显示帮助信息
htop
htop 是 Linux 系统中的一个互动的进程查看器,一个文本模式的应用程序(在控制台或者 X 终端中),需要 ncurses。与 Linux 传统的 top 相比,htop 更加人性化。它可让用户交互式操作,支持颜色主题,可横向或纵向滚动浏览进程列表,并支持鼠标操作。
安装
# yum 安装
yum install htop -y
# 编译安装
wget https://github.com/hishamhm/htop/archive/refs/tags/2.2.0.tar.gz
tar zxvf 2.2.0.tar.gz
cd htop-2.2.0/
yum -y install ncurses-devel gcc
./autogen.sh && ./configure && make
cp htop /usr/local/bin/
使用
[root@tengxun-02 ~]#htop
dstat
| 参数 | 解释 |
|---|---|
| -c,–cpu | 开启cpu统计 |
| -d, --disk | 开启disk统计 |
| -D | 改选跟具体的设备名(多个用逗号隔开)如:total,hda,hdb表示分别统计total、hda、hdb设备块 |
| -i, - -int | 开启中断统计 |
| -l, --load | 开启负载均衡统计,分别是1m,5m,15m |
| -m, --mem | 开启内存统计,包括used,buffers,cache,free |
| -n, --net | 开启net统计,包括接受和发送 |
| -N | 该选项可以跟网络设备名多个用逗号隔开,如eth1,total |
| -g, --page | 开启分页统计 |
| -p, --proc | 开启进程统计,包括runnable, uninterruptible, new |
| -r, --io io | 开启请求统计,包括read requests, write requests |
| -s, --swap | 开启swap统计,包括used, free |
| -S | 该选项可以跟具体的交换区,多个用逗号隔开如swap1,total |
| -t, --time | 启用时间和日期输出 |
| -y, --sys | 开启系统统计,包括中断和上下文切换 |
| –fs | 开启文件系统统计,包括 (open files, inodes) |
| –ipc | 开启ipc统计,包括 (message queue, semaphores, shared memory) |
| –output file | 输出结果到cvs文件中 |
| -a, --all | 是默认值相当于 -cdngy (default) |
| -f, --full | 相当于 -C, -D, -I, -N and -S |
示例
[root@harbor ~]#yum -y install dstat
......
[root@harbor ~]#dstat
You did not select any stats, using -cdngy by default.
----total-cpu-usage---- -dsk/total- -net/total- ---paging-- ---system--
usr sys idl wai hiq siq| read writ| recv send| in out | int csw
0 0 99 0 0 0| 74k 676k| 0 0 | 0 0 | 641 980
0 1 99 0 0 0| 0 0 |9278B 11k| 0 0 | 948 1438
4 4 92 0 0 0| 0 240k|7514B 8974B| 0 0 |5684 9713
0 0 100 0 0 0| 0 0 |2678B 2904B| 0 0 | 370 575
0 0 100 0 0 0| 0 0 |2678B 2904B| 0 0 | 302 472
0 0 100 0 0 0| 0 2912k| 56k 57k| 0 0 | 505 629
0 0 100 0 0 0| 0 0 |2678B 2904B| 0 0 | 293 467
0 0 100 0 0 0| 0 0 |2678B 2904B| 0 0 | 287 449
0 0 100 0 0 0| 0 0 |2664B 2964B| 0 0 | 290 459
0 0 100 0 0 0| 0 0 |2678B 2904B| 0 0 | 332 494
字段
usr:用户空间的程序所占百分比
sys:系统空间程序所占百分比
idel:空闲百分比
wai:等待磁盘I/O所消耗的百分比
hiq:硬中断次数
siq:软中断次数
read:磁盘读带宽
writ:磁盘写带宽
recv:网络收包带宽
send:网络发包带宽
-- 内存分页统计:值较大表明系统正在使用大量的交换空间,通常情况下当系统已经开始用交换空间的时候,就说明你的内存已经不够用了,或者说内存非常分散,理想情况下page in(换入)和page out(换出)的值是0 0。
in: page in(换入)
out:page out(换出)
-- 其他系统信息:这一栏中较高的统计值通常表示大量的进程造成拥塞,需要对CPU进行关注。服务器一般情况下都会运行运行一些程序,所以这项总是显示一些数值。
int:中断次数
csw:上下文切换
nmon
- nmon 是一种在 AIX 与各种 Linux 操作系统上广泛使用的监控与分析工具
- 它能在系统运行过程中实时地捕捉系统资源的使用情况,记录的信息比较全面
- 它可将服务器系统资源耗用情况收集起来并输出一个特定的文件,并可利用 excel 分析工具(nmon analyser)进行数据的统计分析
安装
yum -y install nmon
nmon 快捷命令
q : 停止并退出 nmon
h : 查看帮助
c : 查看 CPU 统计数据
m : 查看内存统计数据
d : 查看硬盘统计数据
k : 查看内核统计数据
n : 查看网络统计数据
N : 查看 NFS 统计数据
j : 查看文件系统统计数据
t : 查看高耗进程
V : 查看虚拟内存统计数据
v : 详细模式
参数
| 参数 | 作用 |
|---|---|
| -f | 监控结果以文件形式输出,**默认:**机器名_日期_时间.nmon |
| -F | 和 -f 一样作用,不过要指定输出文件名 |
| -s | 采样频率,单位秒 |
| -c | 采样次数 |
| -m | nmon 文件保存的目录 |
| -t | 显示资源占用率高的进程 |
nmon;分别按 c、m、k、d 等查看统计数据
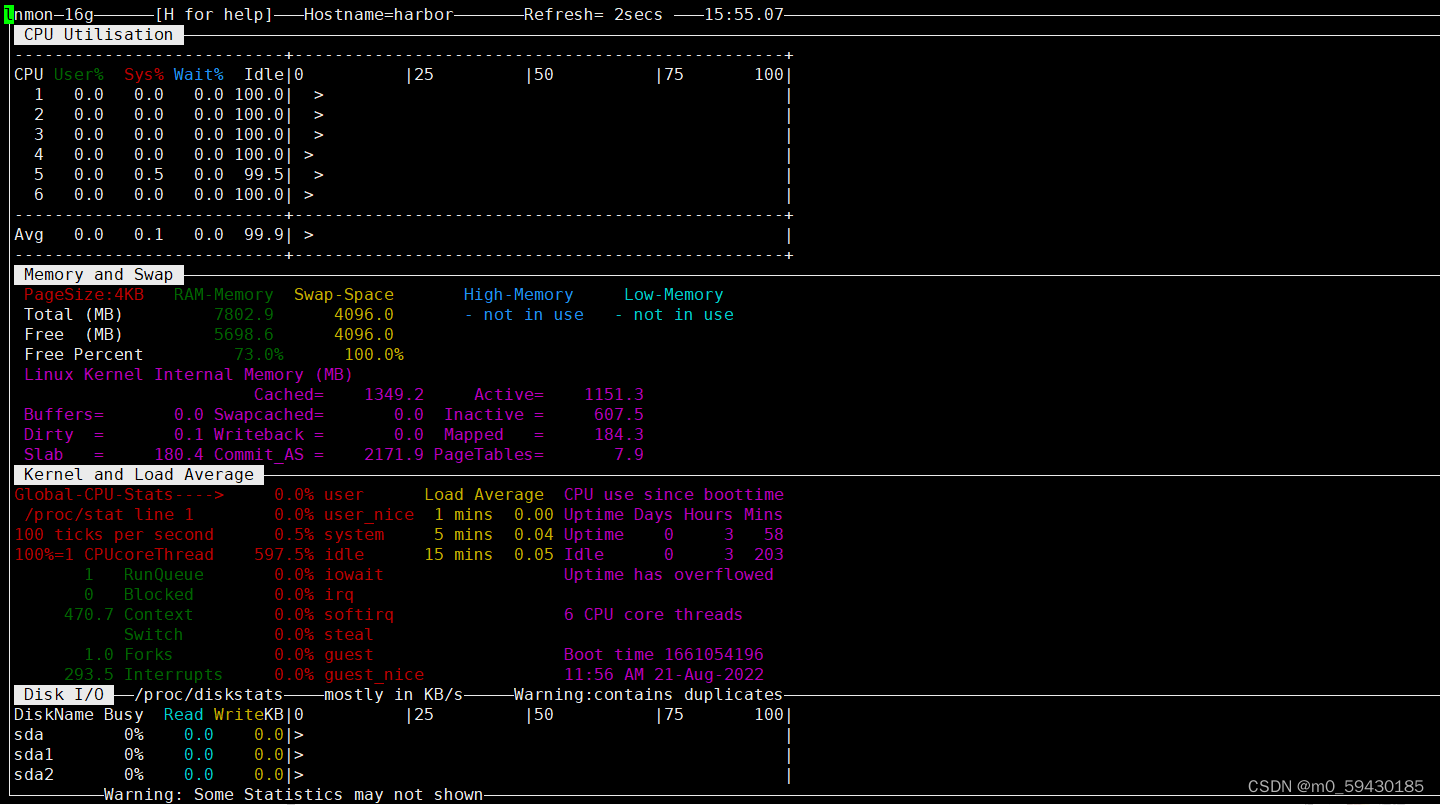
将统计文件保存到本地
#每 10s 采集一次系统资源数据,共采集 6 次(1 min 内收集 6 次),将最终 nmon 文件生成在当前目录
[root@harbor ~]#nmon -f -t -s 10 -c 6 -m ./
[root@harbor ~]#ls
harbor_220821_1556.nmon
sar
获取系统的 CPU、运行队列、磁盘读写(I/O)、分区(交换区)、内存、CPU 中断和网络等性能数据。yum -y install sysstat
日志目录:按日期分类
[root@harbor ~]#cd /var/log/sa/
[root@harbor /var/log/sa]#ls
sa21
格式
sar [options] [-o filename] interval [count]
###------------------------------------------------------
-o filename:其中,filename 为文件名,此选项表示将命令结果以二进制格式存放在文件中
interval:表示采样间隔时间,该参数必须手动设置
count:表示采样次数,是可选参数,其默认值为 1
options:命令行选项
命令选项
| sar命令选项 | 功能 |
|---|---|
| -A | 显示系统所有资源设备(CPU、内存、磁盘)的运行状况。 |
| -u | 显示系统所有 CPU 在采样时间内的负载状态。 |
| -P | 显示当前系统中指定 CPU 的使用情况。 |
| -d | 显示系统所有硬盘设备在采样时间内的使用状态。 |
| -r | 显示系统内存在采样时间内的使用情况。 |
| -b | 显示缓冲区在采样时间内的使用情况。 |
| -v | 显示 inode 节点、文件和其他内核表的统计信息。 |
| -n | 显示网络运行状态,此选项后可跟 DEV(显示网络接口信息)、EDEV(显示网络错误的统计数据)、SOCK(显示套接字信息)和 FULL(等同于使用 DEV、EDEV和SOCK)等,有关更多的选项,可通过执行 man sar 命令查看。 |
| -q | 显示运行列表中的进程数、进程大小、系统平均负载等。 |
| -R | 显示进程在采样时的活动情况。 |
| -y | 显示终端设备在采样时间的活动情况。 |
| -w | 显示系统交换活动在采样时间内的状态。 |
每 3 秒统计一次,统计 5 次
[root@harbor ~]#sar -u 3 5
Linux 3.10.0-1062.el7.x86_64 (harbor) 08/21/2022 _x86_64_ (6 CPU)
04:05:54 PM CPU %user %nice %system %iowait %steal %idle
04:05:57 PM all 1.29 0.00 1.63 0.00 0.00 97.08
04:06:00 PM all 0.11 0.00 0.28 0.00 0.00 99.61
04:06:03 PM all 0.11 0.00 0.22 0.00 0.00 99.67
04:06:06 PM all 0.00 0.00 0.06 0.00 0.00 99.94
04:06:09 PM all 0.11 0.00 0.34 0.00 0.00 99.55
Average: all 0.32 0.00 0.50 0.00 0.00 99.17
查看系统磁盘的读写性能
[root@harbor ~]#sar -d 3 2
Linux 3.10.0-1062.el7.x86_64 (harbor) 08/21/2022 _x86_64_ (6 CPU)
04:07:07 PM DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util
04:07:10 PM dev8-0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
04:07:10 PM DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util
04:07:13 PM dev8-0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Average: DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util
Average: dev8-0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
查看系统内存使用
[root@harbor ~]#sar -r 5 3
Linux 3.10.0-1062.el7.x86_64 (harbor) 08/21/2022 _x86_64_ (6 CPU)
04:07:51 PM kbmemfree kbmemused %memused kbbuffers kbcached kbcommit %commit kbactive kbinact kbdirty
04:07:56 PM 5836504 2153628 26.95 8 1383324 2221084 18.23 1176408 623088 0
04:08:01 PM 5835912 2154220 26.96 8 1383328 2221084 18.23 1176600 623092 0
04:08:06 PM 5835788 2154344 26.96 8 1383328 2221084 18.23 1176592 623092 0
Average: 5836068 2154064 26.96 8 1383327 2221084 18.23 1176533 623091 0
查看网络运行状态
[root@harbor ~]#sar -n DEV 5 3
Linux 3.10.0-1062.el7.x86_64 (harbor) 08/21/2022 _x86_64_ (6 CPU)
04:08:35 PM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s
04:08:40 PM vethabaebea 0.80 1.20 0.29 0.10 0.00 0.00 0.00
04:08:40 PM vethe9a8e12 4.80 3.00 0.40 0.57 0.00 0.00 0.00
04:08:40 PM veth3fdbc54 12.00 20.20 0.95 12.62 0.00 0.00 0.00
04:08:40 PM vethcab8912 0.60 0.60 0.04 0.11 0.00 0.00 0.00
04:08:40 PM veth62eb71b 1.00 1.20 0.08 0.10 0.00 0.00 0.00
04:08:40 PM veth681127a 0.00 0.00 0.00 0.00 0.00 0.00 0.00
04:08:40 PM vethbb509ef 0.20 0.40 0.02 0.03 0.00 0.00 0.00
04:08:40 PM br-7452d777f8eb 0.60 0.60 0.03 0.11 0.00 0.00 0.00
04:08:40 PM lo 3.60 3.60 0.26 0.26 0.00 0.00 0.00
04:08:40 PM ens33 0.80 0.00 0.05 0.00 0.00 0.00 0.00
04:08:40 PM veth16bf1aa 0.80 1.20 0.08 0.10 0.00 0.00 0.00
04:08:40 PM vethfb76974 19.80 12.20 12.68 0.98 0.00 0.00 0.00
04:08:40 PM docker0 0.00 0.00 0.00 0.00 0.00 0.00 0.00
......
总结
默认监控: sar 1 1 # CPU和IOWAIT统计状态
(1) sar -b 1 1 # IO传送速率
(2) sar -B 1 1 # 页交换速率
(3) sar -c 1 1 # 进程创建的速率
(4) sar -d 1 1 # 块设备的活跃信息
(5) sar -n DEV 1 1 # 网路设备的状态信息
(6) sar -n SOCK 1 1 # SOCK的使用情况
(7) sar -n ALL 1 1 # 所有的网络状态信息
(8) sar -P ALL 1 1 # 每颗CPU的使用状态信息和IOWAIT统计状态
(9) sar -q 1 1 # 队列的长度(等待运行的进程数)和负载的状态
(10) sar -r 1 1 # 内存和swap空间使用情况
(11) sar -R 1 1 # 内存的统计信息(内存页的分配和释放、系统每秒作为BUFFER使用内存页、每秒被cache到的内存页)
(12) sar -u 1 1 # CPU的使用情况和IOWAIT信息(同默认监控)
(13) sar -v 1 1 # inode, file and other kernel tablesd的状态信息
(14) sar -w 1 1 # 每秒上下文交换的数目
(15) sar -W 1 1 # SWAP交换的统计信息(监控状态同iostat 的si so)
(16) sar -x 2906 1 1 # 显示指定进程(2906)的统计信息,信息包括:进程造成的错误、用户级和系统级用户CPU的占用情况、运行在哪颗CPU上
(17) sar -y 1 1 # TTY设备的活动状态
(18) 将输出到文件(-o)和读取记录信息(-f)
tsar
tsar 是淘宝自己开发的一个监控工具,可用于收集和汇总系统信息,例如 CPU,负载,IO 和应用程序信息,例如 nginx,HAProxy,Squid 等。结果可以存储在本地磁盘或发送到 Nagios。tsar 可以通过自己开发模块轻松扩展,这使得它成为一个强大的监控工具。
安装
wget -O tsar.zip https://github.com/alibaba/tsar/archive/master.zip --no-check-certificate
unzip tsar.zip
cd tsar-master
make -j 4 && make install
目录文件说明
/etc/tsar/tsar.conf #这是tsar的主要配置文件
/etc/cron.d/tsar #用于每分钟运行tsar收集信息
/etc/logrotate.d/tsar #将每个月轮询tsar的日志文件
/usr/local/tsar/modules #是所有模块库(* .so)所在的目录
/usr/local/man/man8/ #帮助文件
参数
$tsar -h
Usage: tsar [options]
Options:
-check 查看最后一次的采集数据
--check/-C 查看最后一次tsar的提醒信息,如:tsar --check / tsar --check --cpu --io
--cron/-c 使用crond模式来进行tsar监控
--interval/-i 指明tsar的间隔时间,默认单位分钟,带上--live参数则单位是秒
--list/-L 列出启用的模块
--live/-l 查看实时数据
--file/-f 指定输入文件
--ndays/-n 指定过去的数据天数,默认1天
--date/-d 指定日期,YYYYMMDD或者n代表n天前
--detail/-D 能够指定查看主要字段还是模块的所有字段
--spec/-s 指定字段,tsar –cpu -s sys,util
Modules Enabled:
--cpu 列出cpu相关的监控计数
--mem 物理内存的使用情况
--swap 虚拟内存的使用情况
--tcp TCP 协议 IPV4的使用情况
--udp UDP 协议 IPV4的使用情况
--traffic 网络传出的使用情况
--io Linux IO的情况
--pcsw 进程和上下文切换
--partition 磁盘使用情况
--tcpx TCP 连接相关的数据参数
--load 系统负载情况
监控系统的cpu
[root@RedHat_test ~]# tsar --cpu
Time -----------------------cpu----------------------
Time user sys wait hirq sirq util
08/02/20-16:50 0.02 0.02 0.00 0.00 0.00 0.04
08/02/20-16:55 0.28 0.13 0.01 0.00 0.00 0.40
08/02/20-17:00 0.01 0.02 0.00 0.00 0.00 0.04
08/02/20-17:05 0.02 0.03 0.01 0.00 0.00 0.05
08/02/20-17:10 0.03 0.07 0.01 0.00 0.00 0.11
08/02/20-17:15 0.02 0.06 0.01 0.00 0.00 0.09
MAX 0.28 0.13 0.00 0.00 0.00 0.40
MEAN 0.07 0.06 0.01 0.00 0.00 0.14
MIN 0.02 0.02 0.00 0.00 0.00 0.04
----------------------------------------------------------------------------------------
user : 表示用户空间cpu
sys : 内核空间cpu使用情况
wait : 是IO对应的cpu使用情况
hirq,sirq : 分别是硬件中断,软件中断的使用情况
util : 是系统使用cpu的总计情况
监控虚存和load情况
[root@RedHat_test ~]# tsar --swap --load
Time ---------------swap--------------------------------load-----------------
Time swpin swpout total util load1 load5 load15 runq plit
08/02/20-16:50 0.00 0.00 2.0G 0.00 0.00 0.01 0.05 0.00 128.00
08/02/20-16:55 0.00 0.00 2.0G 0.00 0.06 0.04 0.05 0.00 126.00
08/02/20-17:00 0.00 0.00 2.0G 0.00 0.01 0.03 0.05 1.00 129.00
08/02/20-17:05 0.00 0.00 2.0G 0.00 0.00 0.01 0.05 0.00 127.00
08/02/20-17:10 0.00 0.00 2.0G 0.00 0.00 0.01 0.05 5.00 130.00
08/02/20-17:15 0.00 0.00 2.0G 0.00 0.00 0.01 0.05 0.00 130.00
08/02/20-17:20 0.00 0.00 2.0G 0.00 0.00 0.01 0.05 0.00 130.00
MAX 0.00 0.00 2.0G 0.00 0.00 0.01 0.05 5.00 130.00
MEAN 0.00 0.00 2.0G 0.00 0.01 0.02 0.05 1.00 128.67
MIN 0.00 0.00 2.0G 0.00 0.00 0.01 0.05 0.00 126.00
详细使用参考:
https://blog.csdn.net/yunweimao/article/details/106688059
















 500
500











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









