







 超级会员免费看
超级会员免费看
1、任务目标
目标网站:https://career.huawei.com/reccampportal/portal5/social-recruitment.html
要求:抓取该网页下,所有招聘岗位信息,将抓取的目标字段存入Excel表格
标题页:
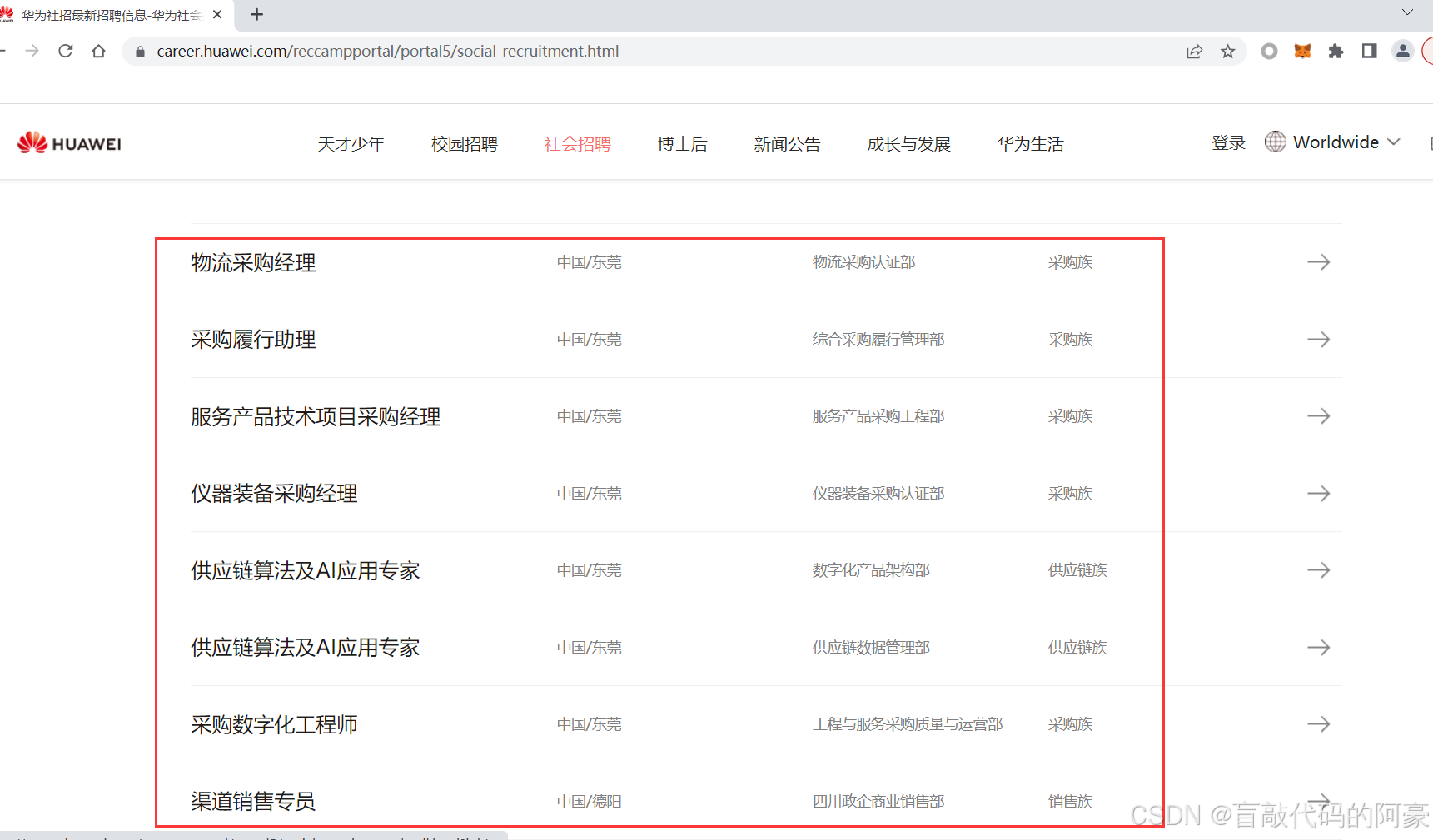
详情页:(将下面所有字段信息抓取下来,存入Excel表格)
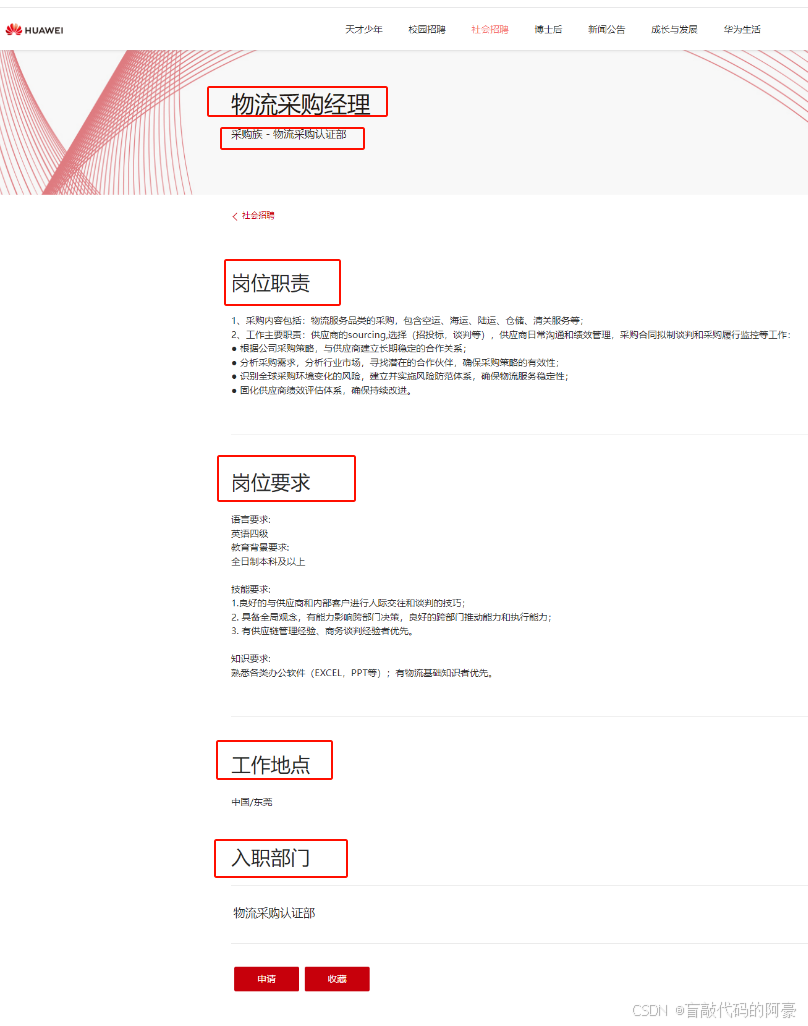
2、网页分析
-
进入网站,打开开发者模式,寻找数据接口,经过分析我们在
Network-Fetch/XHR下发现了第一页的接口文件,其源码中就包含了我们想要的数据信息
目标网站:https://career.huawei.com/reccampportal/portal5/social-recruitment.html
要求:抓取该网页下,所有招聘岗位信息,将抓取的目标字段存入Excel表格
标题页:
详情页:(将下面所有字段信息抓取下来,存入Excel表格)
进入网站,打开开发者模式,寻找数据接口,经过分析我们在Network-Fetch/XHR下发现了第一页的接口文件,其源码中就包含了我们想要的数据信息
 4152
9286
4152
9286

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





 订阅专栏 解锁全文
订阅专栏 解锁全文


























